概要
レイトレ Advent Calendar 2018 12/17の記事です。
タイトルは流行りの言葉(?)をとりあえず散りばめてみればキャッチーになるかな、と思って適当に付けただけです。
私にはバズワード的に使われている「AI」を皆がどのような意味を込めて使っているのか分からないですが、この記事では「Deep Neural Networks (DNN) を用いた、noisyなレイトレーサー(パストレーサー)の出力結果をデノイズする論文の紹介」を行います。
わかりやすく画像で示すと以下のようなことです。[2]

それぞれの画像の左半分がレンダラで描画途中のnoisyな画像で、それをDNNを使ってデノイズした画像が右半分です(左半分が16sppだけでこの量のノイズに収まってるというのも驚きですが...)
今回、DNNを用いたデノイズの基礎的な部分と、以下の論文について簡単に紹介したいと思います。
論文の内容も紹介文もかなりのボリュームになってしまったので、[1] のみ今回は紹介します。いずれ...いずれ [2] も紹介したいです。
- [1] Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder, 2017
- [2] Denoising with Kernel Prediction and Asymmetric Loss Functions, 2018
また、今後、特に明記しない限り、レンダラ/レイトレと書いている場合、いわゆる「パストレーサー(パストレ)」のことを指します。パストレがそもそも何か、というのはShockerさんがとてもわかりやすくブログにまとめられておられるので参照ください。その他でも調べればたくさん出てきます。
memoRandom - パストレーシング (Path Tracing)
DNN の基礎
まず、そもそも Deep Neural Networks (DNN) とはなんぞや?という人もおられると思います。
そんなこと知っとるわ!という方はこの章を丸ごと飛ばして論文紹介の章まで進んでください。
DNNは巷でAIブームが巻き起こる火付け役になったものです。ディープラーニング(Deep Learning: DL)とも言われていますね。
ですが、これを全て説明しているとキリがありません。論文紹介に必要な部分をかいつまんで解説します。
教師あり学習 (Supervised Learning)
今回挙げた2つの論文は、2つとも教師あり学習を用いています。
教師あり学習とは、「デノイズしたいnoisyな画像」に対し、「きちっとデノイズされたらこうなる綺麗な画像(リファレンス画像、真値画像)」がペアとして存在する機械学習の手法です。
限られた画像ペアのセットから、如何に汎用的に、未知のnoisyな画像もデノイズ後画像に変換できるか、これを工夫するのが勝負になります。
ちょっとだけ数式でかくと以下のようになります。
\begin{aligned}
&TrueImage = f(NoisyImage) \\
&f: \mbox{a function converts a noisy image to a clear image}
\end{aligned}
この$f$を、手元の「入力画像/真値画像」のペアセットから頑張って求めてやろう、というものになります。
損失関数
じゃあどうやって$f$を求めるの??という話になります。
ここで Deep Neural Networks が出てきます。$f$をニューラルネットワークで表現してやろう、そしてニューラスネットワークの層を深くすれば表現力も上がるしより正確に $f$ をモデル化できるはずだ、というものです。($f$ のモデル化にはニューラルネットワーク以外にも色々あります。あくまでニューラルネットワークは数多ある手法のうちの1つでしかありません)
ニューラルネットワークの仕組みは割愛します。ググってください。
じゃあ $f$ をニューラスネットワークで表現するのはわかったが、どのようにしてネットワークの各パラメータを決めればいいんだ?という問題になります。ここで出てくるのが損失関数 (loss function) になります。
「この関数の値が小さくなるように、データに基づいてパラメータを最適化してくれ」というのが損失関数になります。
多少語弊があるかもしれませんが、損失関数とは「行いたいタスクそのもの」に相当します。今回は画像のデノイズを行いたいので、超一般的に書くとこのような損失関数が考えられますね。
L = |TrueImage - f(NoisyImage)|
もっと具体的な損失関数は手法によって変わりますし、ここを如何にうまくデザインするかもDNNの肝になります。
この損失関数が決定したら、それに基づいて「逆誤差伝搬法(Back-propagation)」という方法でパラメータを最適化していきます。
こちらもググってください。山ほど解説記事が出ると思います。
Convolutional Neural Networks
ディープラーニング!ニューラルネットワーク!と言いながら以下のような図を見たことがあるかと思います。
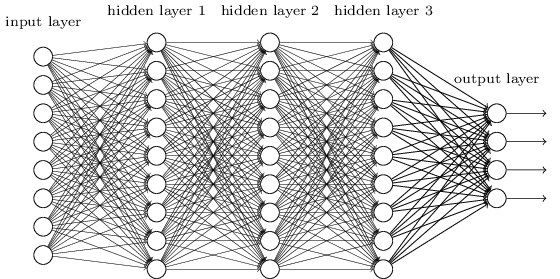
([3]より引用)
これは確かにニューラルネットワークです。隠れ層が3層あるニューラルネットワークです。
この層の数を増やしていけば Deep Neural Networks になります。なりますが、性能が出ません。
上図のように、層間で全てのニューロンが接続されているのは「全結合層(Fully Connected Layer: FC layer)」と呼ばれます。
FC層はパラメータが非常に多くなる上、計算時間も長くなります。さらに、FC層が連続すると勾配消失問題という問題が非常に発生しやすくなります。このFC層だけではディープラーニングは爆発的性能を上げることはできませんでした。
そこで、Convolutional Neural Networks (CNN) が出現しました。これと pooling という手法の組み合わせにより、爆発的に性能が向上し始めました。
CNNは、ガウシアンフィルタやガボールフィルタ等の、画像の周辺領域の情報に重みをつけて足し合わせる「畳み込みフィルタ」と同類のものです。故に、CNNを構成する層は畳み込み層(Convolution Layer)と呼ばれます。
昔からあるものとの違いは、「畳み込む際の全ての重みを学習するパラメータとして可変にした」という点です。
例えば、ガウシアンフィルタの場合、下図のように対象ピクセルを中心として周囲のピクセルにも重みを掛け、足し合わせた結果がフィルタを掛けた結果となります。この時の重みはフィルタサイズに応じて決まっています。

CNNの場合、これらの重みが全てデータから決定されます。3x3の畳み込み層の場合以下のようになります。

このフィルタのサイズが画像全体のサイズと同等になるとFC層になります。
FC層のように画像全体ではなく、フィルタサイズを小さい領域に限定し、それを何個も繋げて深さを増すことで性能&収束性をあげたのが Convolutional Neural Networks になります。
パストレのデノイズに限りませんが、最近では可能な限りFC層を使わないようにネットワークを構成することが多くなっています。
また、Poolingというのも重要な要素になります。超大雑把にいうと、Poolingは画像のダウンサンプリングに相当します。
2x2の範囲で値が最大のものを採用して1ピクセルの値とする 2x2 max-pooling, もしくは平均値をとる 2x2 average-pooling などがあります。今回は max-pooling のみ出てきます。
以上がDNNの基礎的な部分になります。(間違っている内容があったら申し訳ありません...直します)
正直なところ、今回紹介する論文のために必要な基礎的な部分はまだまだあります。が、細かく書いていくとキリがないので、さらに細かいことを知りたい場合は都度調べてもらえると助かります。説明していないものも調べて出てくる範囲かと思います。
論文紹介
1. Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder
NVIDIA が2017年にSIGGRAPHにて発表した論文です。
NVIDIAらしく(?)「リアルタイムで動作するパストレのデノイズ」を目的としています。
つまり、1枚のCG画像を綺麗に出すことだけを目的としておらず、リアルタイムにレンダリング対象が変化する場合でも綺麗に出るよ、と主張しています。
また、こちらの論文に関しては、shikihuikuさんも日本語で紹介されています。私の記事は詳細を省いた雰囲気解説ですが、こちらは細かいパラメータ等について考察されています。是非ご覧ください。
Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoderについて
ネットワーク構造
まず図で示します。論文からの引用です ([1] Fig.2 より一部引用)
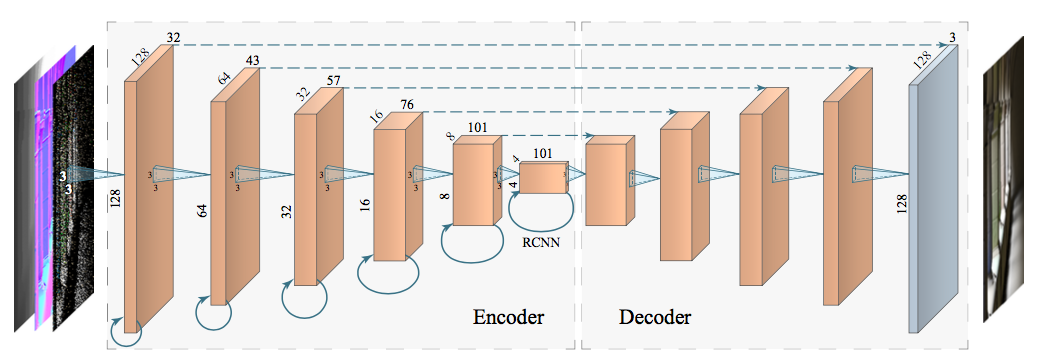
図の若干背景が灰色になっている部分がニューラルネットワークの部分になります。
左から右へと処理が進みます。各層はニューラルネットワークで処理した後の3次元のテンソルのサイズを示しています。
例えば、一番左の層の場合、縦128x横128x奥行き32のサイズをもつテンソルが最初の処理結果として出力される、ということを示しています。
図中ではネットワークが Encoder と Decoder の2つに分けられています。「Encoder-Decoder Model」と呼ばれ、画像処理の世界ではノイズ除去に限らず極めて広く使われています。
また、Encoder-Decoder Model において入力データと出力データが同じものを「AutoEncoder(自己符号化器)」と言います。今回は入力データと出力データが完全に同じわけではないので、原理的な意味でのAutoEncoderではないですが、AutoEncoderはノイズ除去に使われることが多いので恐らくこのような名前にしたのでしょう。
このネットワークについて、Encoder, Decoder, Skip-Connection, RCNN, Encoder層再まとめ、の順で紹介していきます。最初の2節はDNNを知っておられる方に関しては極めて当たり前のことだけ書かれていますので、詳しい方はSkip-Connection, もしくはRCNNの節から読まれると良いかと思います。
また、この論文の新規性は「RCNN」を追加したという部分です。新規性が知りたいという方はRCNNの部分だけ読まれると良いと思います。
Encoder について
各層のテンソル処理部分に3x3の四角錐が書かれているのがわかるかと思います。
これは各層のネットワークの畳み込み(Convolution)のサイズを示しています。つまり、各層は3x3の畳み込みを行い、周辺ピクセルの情報を得ながらチャネル(奥行き)サイズを変更していきます。このネットワークの場合、各層ごとで 4/3 倍にチャネル数を増やしています。
また、Encoderの中では層が進むごとにテンソルの縦横が半分になってるのがわかると思います。
Encoderの部分では畳み込みを行なった後に最大プーリング(Max-Pooling)を行い、縦横の解像度を毎回半分に落としています。
画像処理系ではよくあるやり方ですが、このようにConvolution+Poolingによって縦横の解像度を落としつつ奥行き(チャネル数)を増やしていくことで「このタスクに適した特徴量」が取り出せる、と考えられています。
また、EncoderにはRCNNとDecoder部分に繋がる点線(Skip-Connection)があります。
後に紹介しますが、実際には、上記のConvolution+Poolingの前にこれらの処理が入っています。
- Encoder まとめ
- RCNNブロックの処理を行う(後述)
- Skip-Connection(点線部分)のために結果を保存(後述)
- 3x3の畳み込みを行い、チャネル方向のサイズを増やしていく(4/3倍にしている)
- 最初の層(入力データが直接入る部分)を除き、畳み込み後にMax-Poolingによって縦横解像度を層ごとに半分にしていく
- 上記を6回(6層)行うことによって、タスクに対する特徴量が取り出せる
Decoder について
Decoder は Encoder によって抽出された特徴量から「ノイズが除去された画像」を復元する部分です。
なんだかすごそうに思えるかもしれませんがやっていることは Encoder の逆で、実質ただのアップサンプリング+αです。
まず 2x2 の nearest neighbor upsampling を行なって縦横解像度を倍に増やします。その後 3x3 の畳み込みを2回行い、チャネル数を削減していきます。Encoder では 4/3 倍にしていました。Decoder では逆に、各畳み込みごとに 3/4 倍にします。2回行なっている理由は後述します。
これによって元の入力縦横解像度 (128x128) に戻すことで出力を得ます。
これだけ聞くと、「2x2のアップサンプリングを5回もやったらボケボケの画像が出てくるだけでは???」と思われると思います。
いくらチャネル方向に豊富な情報が入っていて畳み込みを行なっていても直感的にはそう感じますよね。そこで出てくるのが Encoder の紹介時に飛ばした、EncoderとDecoderを結ぶ点線です。通称「Skip-Connection」と呼ばれます。次節で紹介します。
- Decoder まとめ
- 各層ごとに2x2の nearest neighbor upsampling を行う(縦横解像度を2倍にする)
- Skip-connection によって入力されたデータを結合する(次節詳細)
- 3x3 の畳み込みを2回行い、チャネルサイズを(3/4)^2にする
Skip-Connection について
図で点線で表記されている部分です。
Skip-Connectionの目的は、Encoderによって失われた細かい部分を復元することです。
処理としては、Encoder の各層の出力結果を保存しておき、Decoder でアップサンプリングを行なった後に解像度が対応している部分に保存しておいた結果を結合する、という処理になります。
この「結合する」というのは、チャネル方向にそのままくっつけるだけになります。
大雑把に例を書くと以下のようになります。
UpSampledTensor[x,y] = [0.1, 0.2, 0.3]
SkipInputTensor[x,y] = [0.6, 0.2, 0.4]
ConcatResult[x,y] = [0.1, 0.2, 0.3, 0.6, 0.2, 0.4]
この結合処理によって、チャネルサイズが2倍になります。
そのため、Decoder では Skip-Connection 結合後に畳み込みを2回行うことで出力解像度(チャネル方向)が Encoder の対応する部分と同じになるようにしています。
Encoder でダウンサンプリングしていくと、どうしても画像上の細かい情報は失われていきます。
これはノイズ除去に限らず、Encoder-Decoder Model を使ったもの全般に言えます。DNNが猛威を振るっている物体検出等のジャンルでも、細かい物体を逃さないようにするために Skip-Connection はよく用いられるようになっています。
RCNN&Encoder層全体について
このRCNNを加えた部分がこの論文で特に新規性高い部分です。
RCNNを加える目的は「時間方向の一貫性を持たせる」ことです。
連続して複数の画像を出力していくので、画像1枚単位で品質が高いデノイズを行うだけでなく、時間方向にもエイリアスやノイズが出ないことが重要です。一時停止したら綺麗に見えるけど、リアルタイムにしたらチカチカして見るに耐えない、となってしまっては意味がないですからね。
RCNNは「Recurrent Convolutional Neural Network」の略です。図や「Recurrent」という単語から想像がつくと思いますが、各層のEncoderが出力した結果を保存しておき、次フレームの入力が来た時に利用する、というものになります。
このRCNN自体は目新しいものではなく、教科書に載っているレベルでスタンダードなものです。時系列処理が必要なもので広く使われています(動画、音声、自然言語等)。
前置きが長くなってしまいましたが、本論文で採用しているRCNNの構造は下図のようになります(論文より引用)
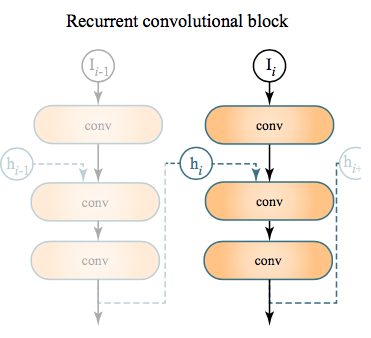
非常にシンプルな構成です。
$I_i$ は $i$ フレーム目の前の層からの入力になります。$h_i$ がフレーム間を跨いで情報を受け継ぐ隠れ層になります。convとは畳み込み(Convolution)のことを意味します。
入力データに畳み込みを行い、前フレームの情報を結合し、その後さらに2回畳み込みを行い、その結果をRCNNブロックの出力兼次フレームへ引き継ぐ$h_{i+1}$としています。
ただ、この構成で論文を読んでも分からなかった部分が、「$h_i$をどのように結合しているのか」「この各convのチャネルサイズ」の2つです。
Skip-Connectionと同様にconcatしているのであれば、チャネル方向のサイズが倍になるので、concat後にチャネルを削減するよう畳み込みを実施しているを思われます。
また、結合の方法として、「テンソルの要素ごとに足し算をする」という方法もあります。これも珍しくない方法です。その場合、チャネルサイズは変わらないので後の畳み込みではチャネルサイズを変えない畳み込みを行なっているかと思われます。
どちらにしろ、このような方法でフレーム方向の一貫性を担保しようとしています。
また、このブロックの出力結果が、最初に説明したEncoderによるConvolution+Poolingの入力になります。
これらをまとめ、RCNNブロック、Skip-Connectionも含めたEncoderの1つの層を図示すると以下のようになります。

以上で、本論文で提案されているネットワーク構造の解説は以上になります。
続いて、入力データについて紹介していきます。
入力データ内容
ネットワーク全体の図を見た時にピンと来た人もおられると思います。
入力データとして、noisyな画像(RGBの3チャネル)を入れるのに加えて、他の情報も入れています。
本論文においては、ゲームではG-Bufferの内容としてよく使われている「法線(スクリーンスペース上。xyの2チャネル画像)」「Depth(1チャネル)」「マテリアルのラフネス(1チャネル)」の4チャネルを追加情報として入力情報にしています。
これらの情報は、事前にラスタライザを走らせることによって得ているようです。これぐらいの情報であればラスタライザを使わずとも、各ピクセル毎にレイマーチングすれば簡単に取れると思うのですが、ラスタライザの方が高速だからそうしているのでしょうか。
noisyな画像も含めると、合計で3+4=7チャネルの画像(テンソル)が入力になります。
また、入力画像の縦横解像度は、ネットワーク構成図にも書かれていますが128x128となっています。
128x128??? 処理対象の画像はもっと大きいのでは??? と思われると思います。
そこまで含めた全体の流れを次節で紹介いたします。
推論(デノイズ)時の全体の処理の流れ
ネットワークの学習は完了しているものとして、どのようにこのネットワークを使ってデノイズを行うかのフローを紹介します。
ネットワーク自体は入力画像サイズを128x128としているので、最終的な描画解像度がそうで無い場合は前処理が必要です。また、ラスタライザを走らせる必要もあります。これらを図示すると以下のようになります。
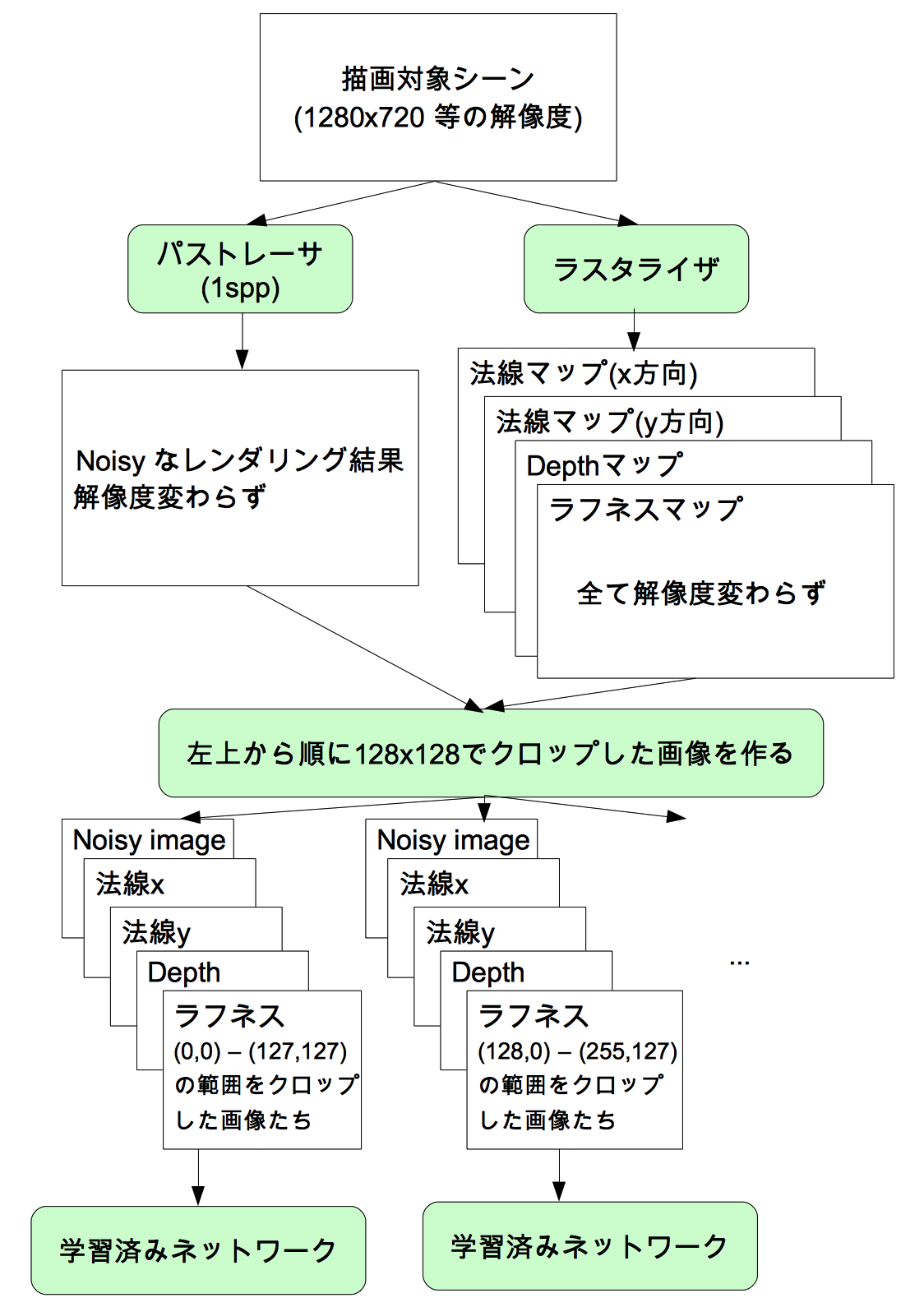
ネットワークに入力する前に、128x128になるようにクロップして入力しています(以後、「パッチ」と呼びます)。図示はしていませんが、最終的には各ネットワークの出力結果を結合して元の解像度と同じ画像を得ています。
そのため、レンダリング対象の解像度が大きくなればなるほどネットワークを動かす回数が増えるため、比例して処理時間が増えるようになります。
※厳密には、推論時にこのように処理をしているのかは不明です。論文にその詳細は書かれていません。ただし、学習時に1024x1024の画像から128x128の画像をクロップして使っているという記述があるため、推論時もおそらくこのようにしていると思われます。実際にはぴったり128ピクセルずつクロップするのではなく、対象のオーバーラップがあるかもしれません。
また、各パッチは1回だけネットワークへ入力するのではなく、何回も入力しています。
ネットワークから出てきた「ノイズ除去済み画像」を「noisy画像」とし、再度ネットワークに入れることでより綺麗になるようです。その検証結果が以下のようになります(論文より引用)

以上が、学習済みネットワークを用いたデノイズ全体の処理の流れになります。
ネットワークの学習について
学習についてはあまり特筆すべき事項はありません。
学習時のデータ前処理と、損失関数について簡単に紹介するだけにさせていただきます。
学習時のデータ処理
- レンダリング画像全体としては1024x1024の解像度を使用
- ランダムに128x128の領域をクロップして入力データとして利用
- 時間方向の学習のため、連続した7フレームを学習時に入力(以下、シーケンスと呼ぶ)
- ロバスト性を上げるための前処理(Data Augmentation)
- シーケンス全体に対し、ランダムで0/90/180/270度の中のいずれかの回転をかける
- シーケンス全体に対し、ランダムで入力画像のRGBをシャッフルする
- シーケンスの順番を逆にしたものも入力
損失関数
数式による詳細記述は省略しますが、学習時の損失関数(loss function)$L$ は以下のようになります。
\begin{aligned}
L &= w_sL_s + w_gL_g + w_tL_t \\
L_s&: average( |真値 - 推定値| ) \\
L_g&: average( |真値Edge - 推定値Edge| ) \\
L_t&: average( |真値時間方向変化 - 推定値時間方向変化| ) \\
\end{aligned}
$w$ はそれぞれの重みです。これらの値は決められており、本論文では $w_{s/g/t} = 0.8/0.1/0.1$ としています。
また、RCNNブロック内では、「シーケンスの後半ほど損失関数の寄与を大きくする」とより良い(何が良くなるのか書かれていませんでした...。おそらく収束速度が上がるのだと思います)らしく、シーケンスの最終フレームを損失関数をそのまま適用する$1$として、次のように損失関数に倍率をかけているようです。 $(0.011, 0.044, 0.135, 0.325, 0.607, 0.882, 1)$
この値はガウシアンカーブから計算されています。
実験結果
細かい数値検証などは割愛します。動画を見ましょう。一番わかりやすいです。
実験結果動画(GoogleDriveへのリンクです)
2. Denoising with Kernel Prediction and Asymmetric Loss Functions
今記事では論文名のみ紹介させていただきます...
Disney Research が2018年にSIGGRAPHにて発表した論文です。
最初の説明で使っている図の論文ですね。
Disneyは映画を作るのが目的なので、「オフライン処理でいかにノイズを除去するか」に焦点を当てています。これが1の論文とは大きく異なる点です。詳細は後述しますが、時間方向の安定性を担保するため、リアルタイム処理では不可能な「未来のフレームの画像」を使ったり、大きな物体・小さな物体共に問題なくデノイズできるような工夫(multi-resolution)が入っています。
かなりボリュームがある論文なので、気合い入れて読む必要がありました。
いつか...いつかちゃんとした紹介記事を別途書きます.....
まとめ
今回は、DNNを用いたパストレのデノイズの基礎と論文を2つ1つ紹介いたしました。
今回挙げた2つの論文は目的が異なりますが(リアルタイム用途、オフライン用途)、それぞれDNNを用いています。
また、パストレではありませんが、NVIDIAが提唱しているDNNを用いたアンチエイリアスの手法、DLSSが Final Fantasy XV に実装されて公開されたようです(現在はベータ版で4k出力時のみ使えるようです)。
Final Fantasy XV with DLSS Beta Support
将来的にデノイズが不要なぐらい高速収束するアルゴリズムが出てくるのかどうかは分からないですが、少なくとも現状ではデノイズを併用することが必須(特にリアルタイムでは)であり、DNNを用いたデノイズ手法はどんどん研究レベルから製品レベルへ移って行くのは確実でしょう。
References
[1] Chakravarty R. Alla Chaitanya, Anton Kaplanyan, Christoph Schied, Marco Salvi, Aaron Lefohn, Derek Nowrouzezahrai, Timo Aila, "Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder", SIGGRAPH 2017
[2] Thijs Vogels, Fabrice Rousselle, Brian McWilliams, Gerhard Röthlin,
Alex Harvill, David Adler, Mark Meyer, Jan Novák, "Denoising with Kernel Prediction and Asymmetric Loss Functions", SIGGRAPH 2018
[3] https://nnadl-ja.github.io/nnadl_site_ja/chap6.html