今回はもっと実践的なものを対象にしてみたいと思います
https://www.template-soko.com/business/kensaseiseki.htm
ここから下側のファイルの
適度に複雑な品質検査成績表をデータ化してみたいと思います
対象
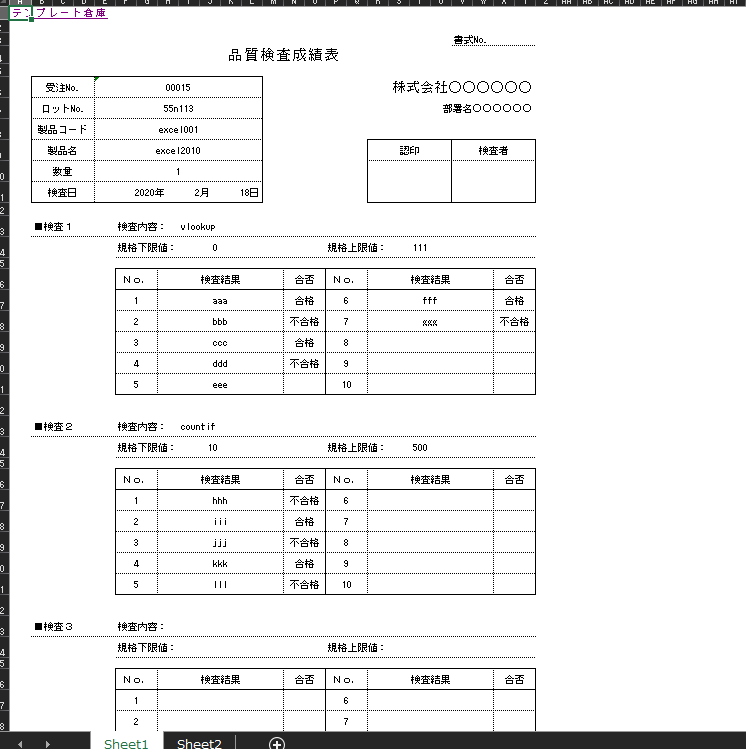
ここから
これを取り出します
表形式で出すと複雑すぎるので
下記の狸さんのjsonデータ変換を使って
https://qiita.com/tanuki_phoenix/items/5f9991ac2712f91f5fda
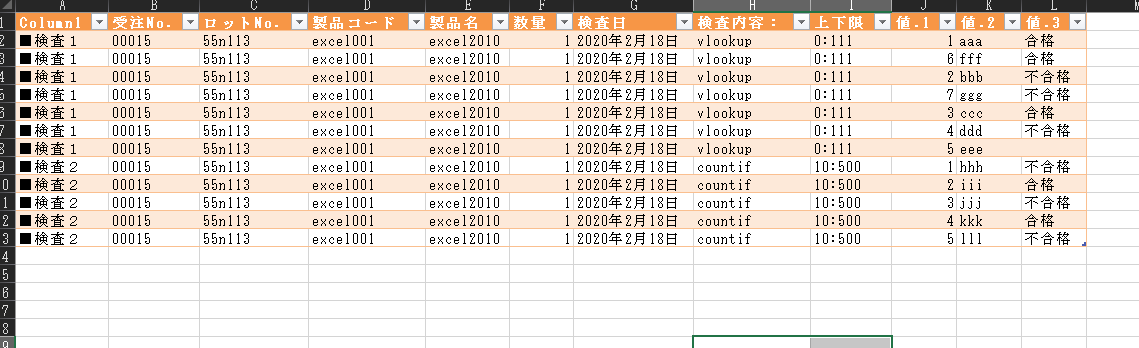
Power Query取り込み後の状況を再現しています
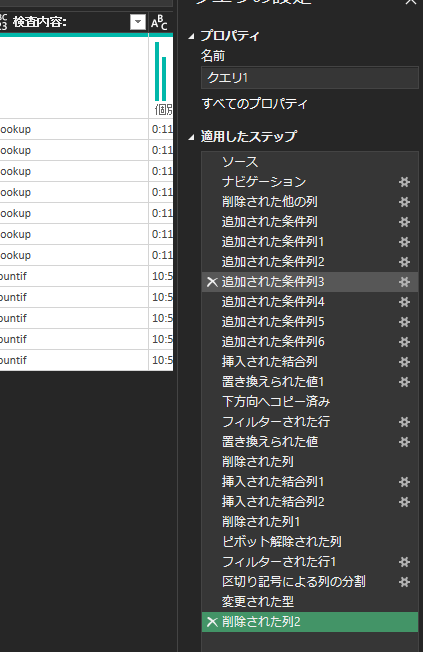
ナビゲーション以下のがコード的に同じになります
適当に「横抜き」と呼んでる、条件列で必要なデータを新列に抜き出して下フィルで必要な行に配布している
という単純な操作ですが、
繰り返せばそれだけで神エクセルに対抗できたりするのが見ていただければ幸いです
ソース
PowerQuery
let
ソース = "7ZjPjtsgEMbfhfOqmsHG4F577ws0PdgY8s+b9FBXlaq+eyHdtoFtSJyNYxxzQRk5IsP8/A3z5dMP8mHfds87JO93Xds+vYTUDTM3zN2QuWHhhtwNhRuWbojgxV5e6CWGXmbopYZebuglh1526KWHXn7Uy4+a/MiiKwotFh3ToD/u35G/D71kqZcsfUn259MRBbMbyyUuOiFVZXYuUZqV69qsFGHRcZUp81QUgiRa/Wk58TWAkkxGKrxVRtZwowOphKOzcxQIAJgjThSE7S+CVr/7y6LLNZrPvLRdgDJZh1cSG8IMVGNXmR3WniAZMyXOJkyyBGVuCq45tX0emkkyFEI3f66pDOoDSS0PPMseMNV3qVqjzKnijLFDHqOx71dfHBRM5R6Ehy1HJWw5Mv7vUNeOeEeDmABgb57yCsbNNGd21ZczwgchE4NSnMmaKdZDKRSoQccUz23PAzheqd0TxOsHKLzfSQzfxtD5wjlmx2Eq/JvFQ1kFroS0RrzakHpyZCiYWeu6POxbkYtRkW/tfr/tvpDE6zZCsXdoKbS1IJnhkyswfMqC2f4HNO/Lx5MSDMnldepVIPVryCFitOBShxtPMVpTZddc2xVUQB9e5+ONfT0LXkoyHJ7DX4x2RGE5LUgIVOgsJybuM6cZAuf/z3NzsBigWFXVPYDZThYEVgTpaK3vA8LJ8+YgaABEXdfDgjDXSHMxDh7EsVwuh8ZxMtubQ8kCUKS8Szs7i0M87KWTB6rfNE1EkigflgELMFBKDcjg3LyF8LBFPw7TmNuz8KeMPI3AyMt9t/u61snIT8LI48SdPAOIllxqceNJJjn5uTn51WoV0bQc9POTFlfIxK/X6yj8YtC+T7r6Ibe+2WwiUsA8Pft2u41CAfN0623bRqSA5N4HweDEUxxtT7n3bHz3nlBNxbgPjWZ46x41vNTgxlNN8u4z8+7jymmWVn3cks/Sn49b8lna8XFLPksPPm7JI7Tcn38B",
カスタム1 = Binary.FromText(ソース),
カスタム2 = Binary.Decompress(カスタム1,Compression.Deflate),
ナビゲーション = Table.FromRecords(Json.Document(カスタム2,932)),
削除された他の列 = Table.SelectColumns(ナビゲーション,{"Column1", "Column4", "Column5", "Column7", "Column8", "Column9", "Column13", "Column15", "Column16", "Column17", "Column19", "Column21", "Column23"}),
//4~9行を行のデータをのデータを別の列に引き抜く
追加された条件列 = Table.AddColumn(削除された他の列, "受注No.", each if [Column1] = "受注No." then [Column4] else null),
追加された条件列1 = Table.AddColumn(追加された条件列, "ロットNo.", each if [Column1] = "ロットNo." then [Column4] else null),
追加された条件列2 = Table.AddColumn(追加された条件列1, "製品コード", each if [Column1] = "製品コード" then [Column4] else null),
追加された条件列3 = Table.AddColumn(追加された条件列2, "製品名", each if [Column1] = "製品名" then [Column4] else null),
追加された条件列4 = Table.AddColumn(追加された条件列3, "数量", each if [Column1] = "数量" then [Column4] else null),
追加された条件列5 = Table.AddColumn(追加された条件列4, "検査日", each if [Column1] = "検査日" then [Column4] else null),
追加された条件列6 = Table.AddColumn(追加された条件列5, "検査内容:", each if [Column5] = "検査内容:" then [Column8] else null),
//上限下限を結合して引き抜く
挿入された結合列 = Table.AddColumn(追加された条件列6, "上下限", each Text.Combine({Text.From([Column9], "ja-JP"), Text.From([Column19], "ja-JP")}, ":"), type text),
置き換えられた値1 = Table.ReplaceValue(挿入された結合列,"",null,Replacer.ReplaceValue,{"上下限"}),
//下側にフィル
下方向へコピー済み = Table.FillDown(置き換えられた値1,{"受注No.", "ロットNo.", "製品コード", "製品名", "数量", "検査日", "検査内容:", "Column1", "上下限"}),
フィルターされた行 = Table.SelectRows(下方向へコピー済み, each ([Column5] <> null and [Column5] <> "検査内容:" and [Column5] <> "規格下限値:" and [Column5] <> "No.")),
置き換えられた値 = Table.ReplaceValue(フィルターされた行," ","",Replacer.ReplaceText,{"検査日"}),
// データの入ってない行を削除
削除された列 = Table.RemoveColumns(置き換えられた値,{"Column4", "Column8", "Column9", "Column16", "Column19", "Column21"}),
// 1~5の「No.」「検査結果」「合否」を結合
挿入された結合列1 = Table.AddColumn(削除された列, "1列", each Text.Combine({Text.From([Column5], "ja-JP"), [Column7], [Column13]}, ":"), type text),
// 6~10の「No.」「検査結果」「合否」を結合
挿入された結合列2 = Table.AddColumn(挿入された結合列1, "2列", each Text.Combine({Text.From([Column15], "ja-JP"), [Column17], [Column23]}, ":"), type text),
// 元データの残りを削除
削除された列1 = Table.RemoveColumns(挿入された結合列2,{"Column5", "Column7", "Column13", "Column15", "Column17", "Column23"}),
// ピボット解除で1~10まで1列に並べ替える
ピボット解除された列 = Table.UnpivotOtherColumns(削除された列1, {"Column1", "受注No.", "ロットNo.", "製品コード", "製品名", "数量", "検査日", "検査内容:", "上下限"}, "属性", "値"),
// 列の追加で増えた物はデータがなければ区切りの「:」がつかないので
// それを使ってフィルタ処理
フィルターされた行1 = Table.SelectRows(ピボット解除された列, each Text.Contains([値], ":")),
// 結合データを分解し直す
区切り記号による列の分割 = Table.SplitColumn(フィルターされた行1, "値", Splitter.SplitTextByDelimiter(":", QuoteStyle.Csv), {"値.1", "値.2", "値.3"}),
変更された型 = Table.TransformColumnTypes(区切り記号による列の分割,{{"値.1", Int64.Type}, {"値.2", type text}, {"値.3", type text}}),
// 不要な属性列を削除
削除された列2 = Table.RemoveColumns(変更された型,{"属性"}),
// 狙った順番に並べ替える
// excelのフィルタと逆で、先に並べ替えた順番が優先される
並べ替えられた行 = Table.Sort(削除された列2,{{"Column1", Order.Ascending}, {"値.1", Order.Ascending}}),
#"名前が変更された列 " = Table.RenameColumns(並べ替えられた行,{{"値.1", "No."}, {"値.2", "検査結果"}, {"値.3", "合否"}})
in
#"名前が変更された列 "
コードの使用法
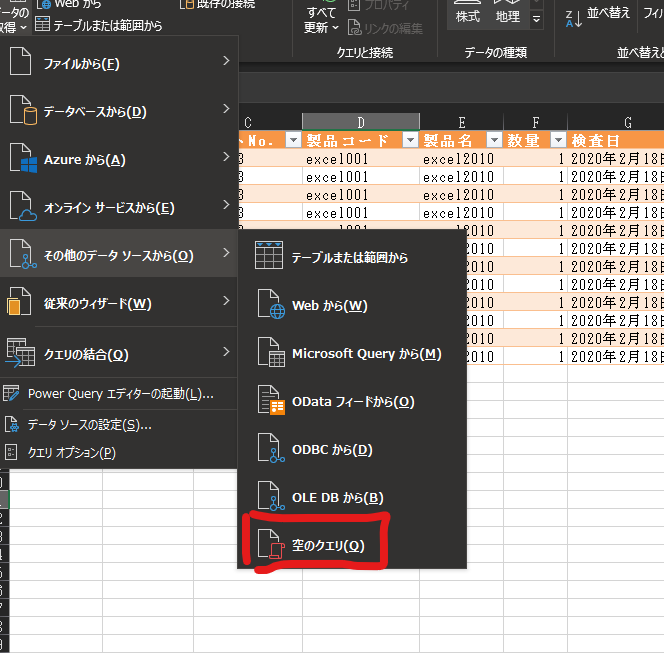
空クエリの作成を選択し
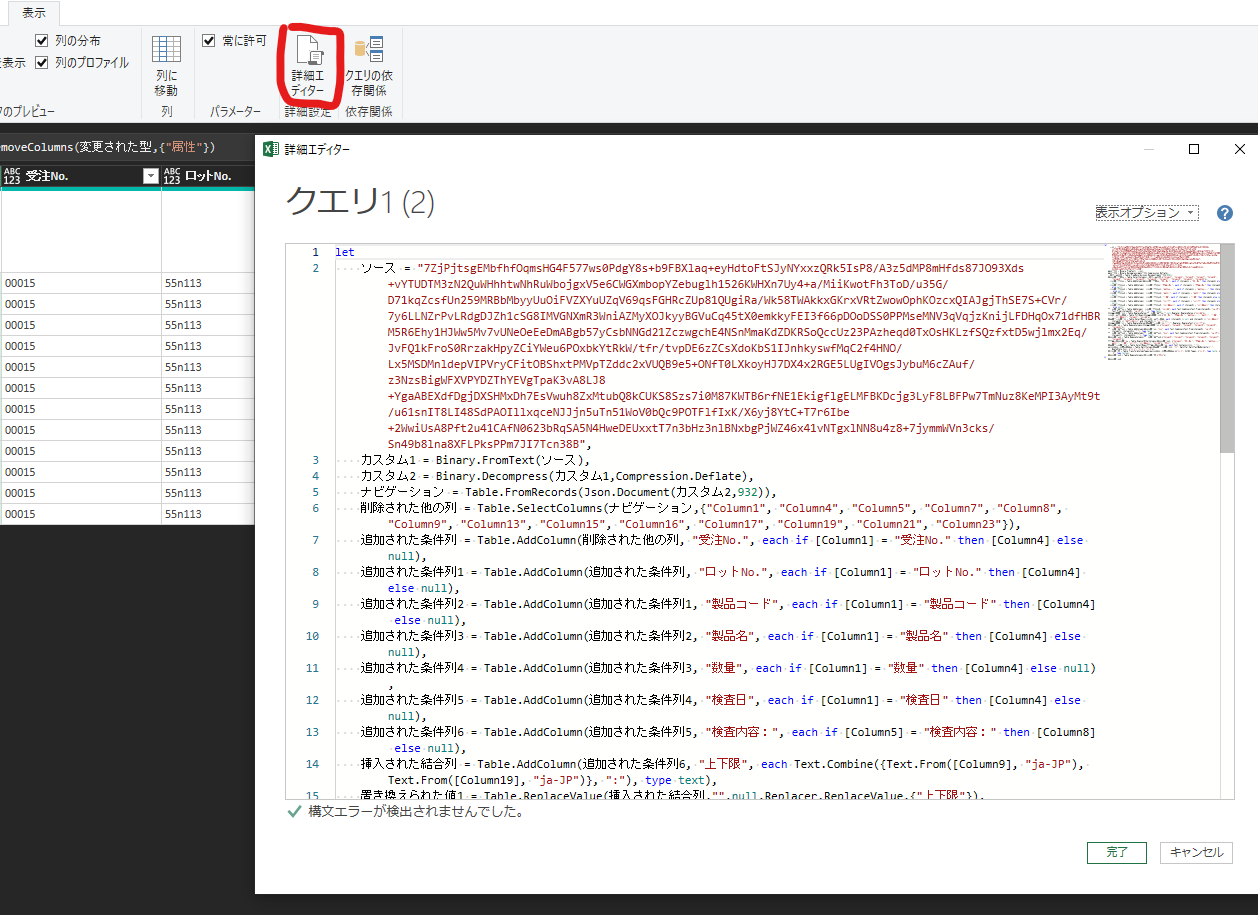
Power Query開いて「表示>詳細エディタ」を開いてコードをすべて上記のものに入れ替えると動きます