これの話をします
https://twitter.com/olt_yt/status/1126409785916571649
Yt-olt @olt_yt
こんな感じに横に条件列で抜き出して、下にフィルすることは俺的によくやるし、やりたい人が多い動きじゃないかなー #PowerQuery
午後5:53 · 2019年5月9日·Twitter Web App
https://www.amazon.co.jp/dp/B07WVZXVLY
いちばんやさしいExcelピボットテーブルの教本 チャプター7 レッスン37と同等の内容です
Power Query ステップ名 逆引き(未完成版)
https://qiita.com/olt_yt/items/679605009b6a180b9cda
こんな感じで
ひらがな頭文字を下位のの行に入れ込みたい時
表のタイトルを表の各行に持たせたい
という場合はの簡単な解説をします
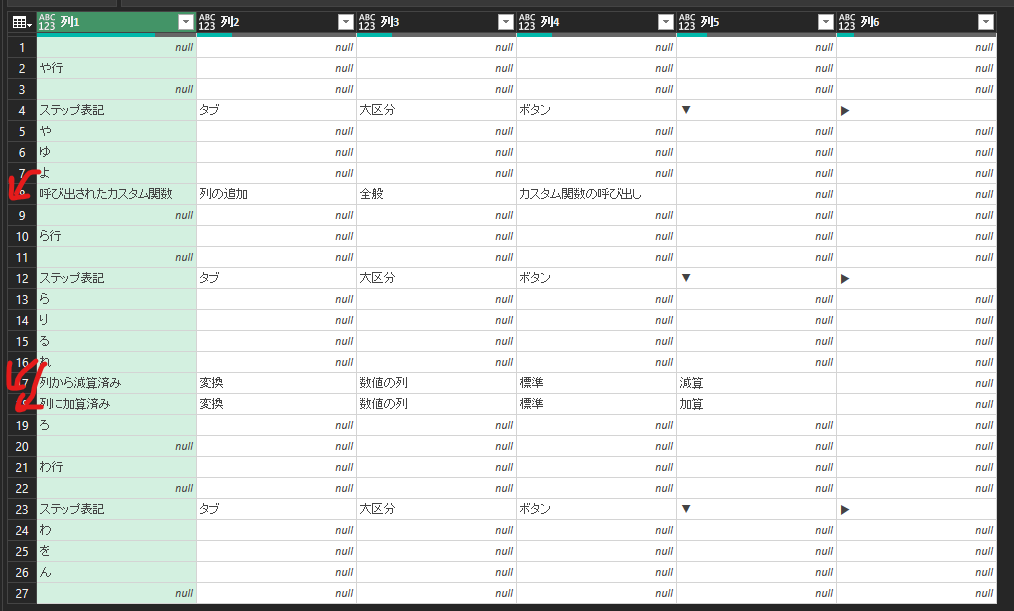
これをこんな感じを目標

元データ

頭文字
表の中に入ってるひらがなの頭文字を
並べ替えに使うために各行に配布する場合を考えます
let
X0 = "7VS9bgMhDH4X5gz82UBfpdcB7o4p6nZT1XcvhlzhaKR0IW2kLJZtwDb29/n1g00bSGEEe3nfzufTxZRHUx1NfTThaGIxP09N7KQpbvW0WatnNirL8B8ER3LGLBXJxdCf0CbphW1/Vh7EfAlZUwdpTqZ3oJQnL6/H+vJumevrqFhTZ9IkhNpD3F3IrnV8WK9LfBwc346MD9rkNps0SRDRkw6Q82Y/5Pb7UCdfBrLyaXPg5bQhGN7NnDS6hGuCRIwLeTzv5y8yYqScf0z+Vro99tXiDftPbLHuyfc7890N5qMfHD8Mjj8Oiw31ddjRj6tIugnOkM5tJmzsN4bjdFUtoUNNoTtwqb9Jn8467KAXOZHDDjU1N/tl3RjKsvqrimvuWxWn7i6Pu1VsfO7FO+/FOHavODk4vnoYrLx9AQ==",
//テーブル変換部
X1 = Binary.FromText(X0),
X2 =Binary.Decompress(X1,Compression.Deflate),
X3 =Table.FromRecords(Json.Document(X2,932)),
//エラー処理
フィルターされた行 = Table.SelectRows(X3, each ([列1] <> null)),
//コア部
//他の行に移動したいデータを新列に抜き出す
//抜き出す物以外をnullにするのが重要
追加された条件列 = Table.AddColumn(フィルターされた行, "条件列", each if Text.Contains([列1], "行") then "頭文字" else if [列2] = null then [列1] else null),
//フィルを使って移動
下方向へコピー済み = Table.FillDown(追加された条件列,{"条件列"}),
//不要部削除他
フィルターされた行1 = Table.SelectRows(下方向へコピー済み, each ([列2] <> null)),
昇格されたヘッダー数 = Table.PromoteHeaders(フィルターされた行1, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"ステップ表記", type text}, {"タブ", type text}, {"大区分", type text}, {"ボタン", type text}, {"▼", type text}, {"▶", type text}, {"頭文字", type text}}),
並べ替えられた列 = Table.ReorderColumns(変更された型,{"頭文字", "ステップ表記", "タブ", "大区分", "ボタン", "▼", "▶"}),
フィルターされた行2 = Table.SelectRows(並べ替えられた列, each ([頭文字] <> "頭文字"))
in
フィルターされた行2
処理の流れををてきとうに図にした物が下の物になります
条件列(赤線)の操作で列1の必要な内容だけ抜き取り
抜き取った物をフィルの力で下方向へ配布する(青線)
そういった操作になります

行名
今回は表のタイトルを各行に持って行くことを考えます
月ごとに分かれた表、担当ごとに分かれた表
などでタイトルを各行に振り分けるということはよく使います

let
X0 = "7VS9bgMhDH4X5gz82UBfpdcB7o4p6nZT1XcvhlzhaKR0IW2kLJZtwDb29/n1g00bSGEEe3nfzufTxZRHUx1NfTThaGIxP09N7KQpbvW0WatnNirL8B8ER3LGLBXJxdCf0CbphW1/Vh7EfAlZUwdpTqZ3oJQnL6/H+vJumevrqFhTZ9IkhNpD3F3IrnV8WK9LfBwc346MD9rkNps0SRDRkw6Q82Y/5Pb7UCdfBrLyaXPg5bQhGN7NnDS6hGuCRIwLeTzv5y8yYqScf0z+Vro99tXiDftPbLHuyfc7890N5qMfHD8Mjj8Oiw31ddjRj6tIugnOkM5tJmzsN4bjdFUtoUNNoTtwqb9Jn8467KAXOZHDDjU1N/tl3RjKsvqrimvuWxWn7i6Pu1VsfO7FO+/FOHavODk4vnoYrLx9AQ==",
//テーブル変換部
X1 = Binary.FromText(X0),
X2 =Binary.Decompress(X1,Compression.Deflate),
X3 =Table.FromRecords(Json.Document(X2,932)),
//エラー処理
フィルターされた行 = Table.SelectRows(X3, each ([列1] <> null)),
//コア部
//他の行に移動したいデータを新列に抜き出す
//抜き出す物以外をnullにするのが重要
追加された条件列 = Table.AddColumn(フィルターされた行, "条件列", each if Text.Contains([列1], "行") then [列1] else null),
//フィルを使って移動
下方向へコピー済み = Table.FillDown(追加された条件列,{"条件列"}),
//不要部削除他
フィルターされた行1 = Table.SelectRows(下方向へコピー済み, each ([列2] <> null)),
追加された条件列1 = Table.AddColumn(フィルターされた行1, "カスタム", each if [列1] = "ステップ表記" then "行名" else [条件列]),
削除された列 = Table.RemoveColumns(追加された条件列1,{"条件列"}),
昇格されたヘッダー数 = Table.PromoteHeaders(削除された列, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"ステップ表記", type text}, {"タブ", type text}, {"大区分", type text}, {"ボタン", type text}, {"▼", type text}, {"▶", type text}, {"行名", type text}}),
フィルターされた行2 = Table.SelectRows(変更された型, each ([ステップ表記] <> "ステップ表記")),
並べ替えられた列 = Table.ReorderColumns(フィルターされた行2,{"行名", "ステップ表記", "タブ", "大区分", "ボタン", "▼", "▶"})
in
並べ替えられた列
注意点
このように

ヘッダとして使う行に「や行」「ら行」といった変化する文字が入ったまま
ヘッダに格上げしてしまうと列名の変化によるエラーが多発します
そのため今回のように
・元の条件列の時にヘッダ用の文字を生成する
・2段目の条件列でヘッダ列が別の文字に置き換える
といった方法で回避することがおすすめです
フォルダ読み込み時に、ファイル名が列名に入りエラー起こすというのは頻出なので
列名のように条件列でヘッダ列だけ書き換えるのをおすすめします
条件列

実はこの条件列、簡略化するためにこんな内容ですが
列1の表の中に「行」の文字が入っていると全部「頭文字」になるため
「削除された空白行」などの入る「さ行」はグチャグチャな結果になります
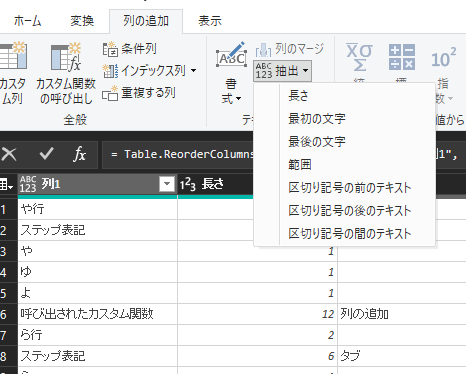
今回の場合は列1が文字数2になるのは目的の所だけなので
列の追加⇒抽出⇒長さ
でも時長さを出してそこを種にするという作業列を増やす方法などがあります
ペシャルサンクス
テーブルをバイナリ(JSON)化したり、テーブルに戻したり
https://qiita.com/tanuki_phoenix/items/5f9991ac2712f91f5fda