はじめに
お休みのため時間あったので、初歩的な学習モデル(分類)で、以下のような質問応答ページを作っていました。うまくいかない点も多々あり、備忘禄用にやったことをアウトプットしておこうと思います。
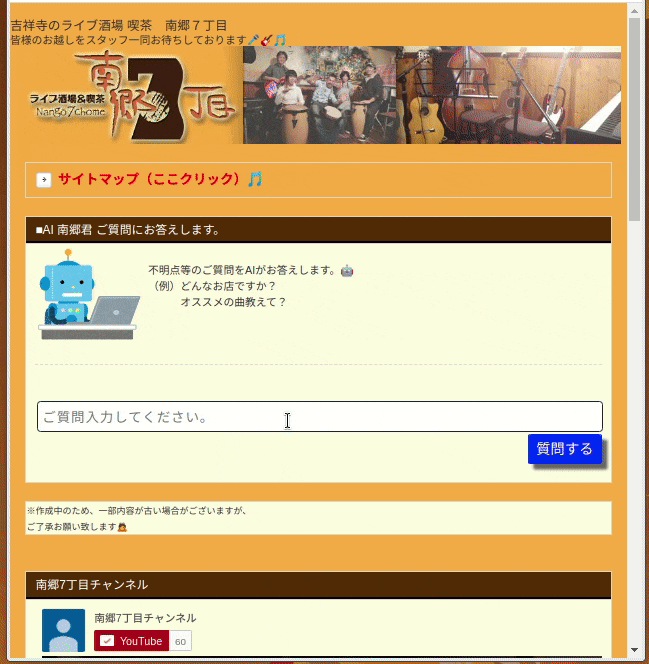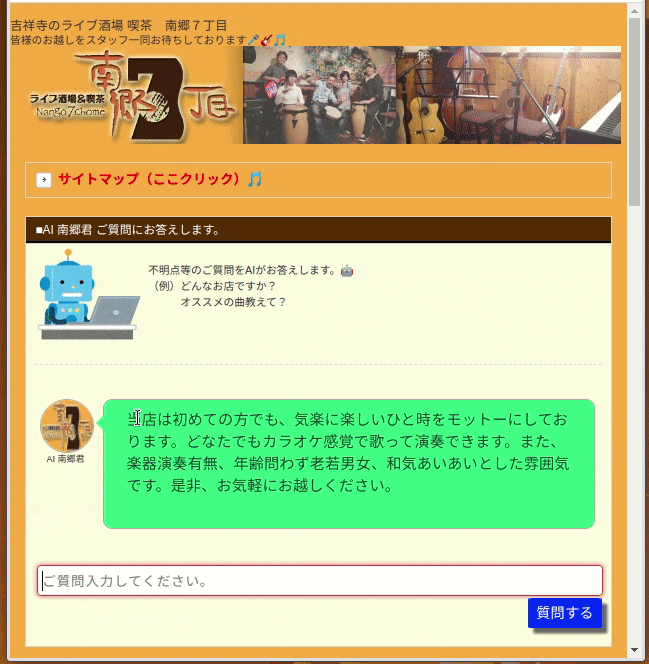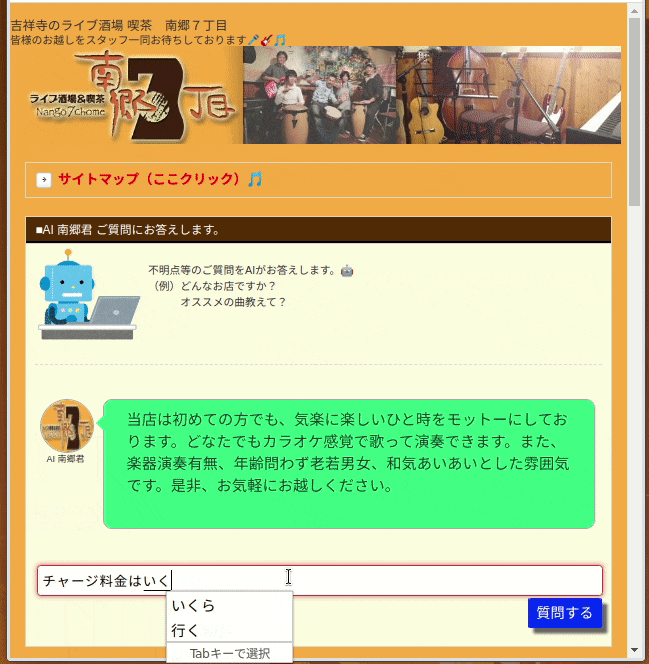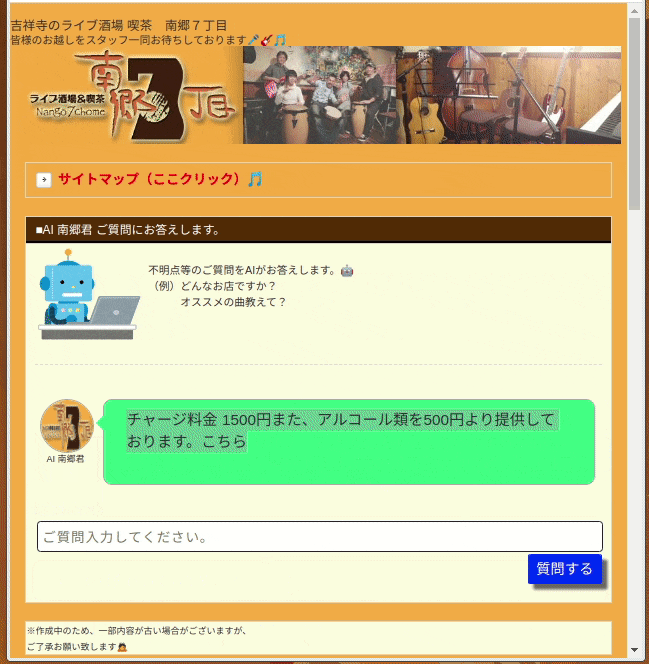
この方法は、学習用モデルに以下のような教師データを与え、単語毎に分離してTF-IDFで文書をベクトル化してます。
学習モデルはほぼこちらを流用しております。
import pandas as pd
df_study = pd.read_csv('ans_studyInput_qa.txt', names=['id', 'truth_val', 'ラベル(教師データ)', '入力'])
df_study
id truth_val ラベル(教師データ) 入力
0 1 T チャージ料金 1500円また、アルコール類を500円より提供しております。[こちら](htt... 料金はいくら?
1 2 T チャージ料金 1500円また,アルコール類を500円"より提供しております。[こちら](ht... 金額はどのくらいかかる?
2 3 T チャージ料金 1500円また、アルコール類を500円より提供しております。[こちら](htt... いくらあれば足りる?
3 x T チャージ料金 1500円また、アルコール類を500円より提供しております。[こちら](htt... 料金を教えてください
4 x T チャージ料金 1500円また、アルコール類を500円より提供しております。[こちら](htt... 料金について
... ... ... ... ...
134 x T どなたでもカラオケ感覚で歌って演奏できます。お店の楽器は自由に演奏できます。また、視聴のみで... 何ができる?
135 x T どなたでもカラオケ感覚で歌って演奏できます。お店の楽器は自由に演奏できます。また、視聴のみで... 楽しみ方は?
136 x T どなたでもカラオケ感覚で歌って演奏できます。お店の楽器は自由に演奏できます。また、視聴のみで... 楽しみ方法?
137 x T どなたでもカラオケ感覚で歌って演奏できます。お店の楽器は自由に演奏できます。また、視聴のみで... 他のお店との違いは?
138 x T どなたでもカラオケ感覚で歌って演奏できます。お店の楽器は自由に演奏できます。また、視聴のみで... 普通のお店との違いは?
139 rows × 4 columns
この方法では、入力文書をTF-IDFでベクトル化しているため、単語の重要度(珍しさ)は分かるのですが、単語の並び順や意味的な近さを考慮できていません。そのため、学習モデルが分類ということもありますが、上図のGifのように「チャージ料金はいくらですか?」の問いに「チャージ料金 1500円また、アルコール類を500円より提供しております。」という回答をしています。
本当は、余計な部分はいらず「1500円です」と回答したいところです。
そこで、改善方法がないか探しました。調べた結果を記載します。
学習済みモデルについて
色々調べた所、自力で質問応答の学習済みモデルを作るのは自分のスキル、資源、時間的にも無理そうでした![]()
どうしようか悩んでいた所、こちらの記事でBERTを使った自然言語処理について分かりやすく解説頂いてましたので活用できないか試みました。
ファインチューニングという方法で実現可能なようでしたが、学習データ構造と質問応答への流用方法が理解できていないため、ファインチューニング済みの学習モデルを探すことにしました。
Hugging Faceが学習済みモデルを提供下さってました。
Hugging Faceについては、わかり易い記事ありましたので引用させて頂きます。
引用元:文章を理解するAIの開発を目指すHugging Face
情報を分類、理解、抽出、文章を生成するのにもすぐに活用できるのです。例えば、カスタマーサポートのメールや、TwitterやFacebookなどソーシャルメディア、新聞、書籍の投稿からも、特定のトピックについての情報抽出をしたい時にいつでもできるのです。
BERTの学習済みモデル(英語版)を使って結果確認
まずは、上記Hugging Faceの学習済みモデルを使ってどうなるか確認しました。
但し、Hugging Faceには日本語QAモデルが見当たらなかった(一つあったのですが、動かし方悪いのかエラーとなり動きませんでした)ので、英語版のモデルで無理やり試しました![]()
試したモデルはdistilbert-base-uncased-distilled-squadです。
!pip install transformers
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "distilbert-base-uncased-distilled-squad"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
# model = AutoModelForQuestionAnswering.from_pretrained(model_name)
# tokenizer = AutoTokenizer.from_pretrained(model_name)
QA_input = {
'question': "チャージ料金はいくらですか?",
'context': 'チャージ料金 1500円また、アルコール類を500円より提供しております。'
}
res = nlp(QA_input)
print(res)
print('答え: ' + res['answer'])
{'score': 0.07764814049005508, 'start': 0, 'end': 11, 'answer': 'チャージ料金 1500'}
答え: チャージ料金 1500
QA_input = {
'question': "アルコール類はいくらですか?",
'context': 'チャージ料金 1500円また、アルコール類を500円より提供しております。'
}
res = nlp(QA_input)
print(res)
print('答え: ' + res['answer'])
{'score': 0.027067013084888458, 'start': 15, 'end': 28, 'answer': 'アルコール類を500円より'}
答え: アルコール類を500円より
料金以外の文章が残ってしまってます。
Bertの日本語QAモデルを使って結果確認
Hugging Faceには見当たりませんでしたが、日本語QAモデルの記事があり、既に学習済みモデルを作成して下さってました。
こちらの記事となります。大変勉強になりました![]()
作成済みの学習モデルをダウンロードさせて頂き、結果を確認しました。
context = """
チャージ料金 1500円また、アルコール類を500円より提供しております。
"""
quesion = "チャージ料金はいくらですか?"
prediction, score = predict(quesion, context)
print('答え: ' + prediction)
print(score)
答え: 1500円
13.75549030303955
チャージ料金のみとれています。
context = """
チャージ料金 1500円また、アルコール類を500円より提供しております。
"""
quesion = "アルコール類はいくらですか?"
prediction, score = predict(quesion, context)
print('答え: ' + prediction)
print(score)
答え: 500円
7.591254949569702
参考文献
この記事を作るにあたって参考にさせて頂きました![]()