はじめに
自然言語処理の様々なタスクでSOTAを更新したBERTですが、2019年12月に日本語のpretrainedモデルがpytorch版BERTに追加されました。これにより日本語のBERTが以前より簡単に試せるようになりました。しかし、依然としてBERTの日本語QAモデルに関する記事が存在しなかったため、この記事では日本語pretrainedモデルをfinetuningすることで日本語QAモデルを作成する方法について説明します。モデル作成の大まかな流れは以下のようになっているので、この流れを頭に入れて記事を読むと理解しやすいと思います。
モデル作成の流れ
1.モデルの学習データを用意する(これができれば、ほぼ完了です)
2.すでに用意された、run_squad.pyと言うスクリプトを実行する
3.モデル完成
この記事で扱う内容
-
事前知識
・BERTとは
・squadの形式 -
学習データの用意
・学習データの構造の説明
・squadを25025問翻訳する
・Squad2形式に変更
・オリジナルデータを使う場合 -
finetuningの仕方
・使用する事前学習モデルの選択
・変更する必要のあるスクリプトについて
・finetuningに必要なデータ量の目安、学習時間 - モデルの使用方法
-
結果
・モデルの精度
・モデルの出力
事前知識
この記事で紹介する方法でfinetuningをする場合、BERTへの理解よりもSQuADの形式の理解の方が大切になってくるため、SQuADの説明を重点的にします。
BERTとは
BERTに関する説明はすでに多くの方が説明しているのでここでは詳細は省きますが、BERTは2018年にgoogleが発表した自然言語処理モデルで現在googleの検索エンジンなどに使われています。BERTの大きな特徴はfinetuningすることでQA、感情分析など様々なタスクに適用することができることです。
詳しいことが気になる方は下記のリンクをご覧ください。
https://qiita.com/Kosuke-Szk/items/4b74b5cce84f423b7125
squadの形式
Stanford Question Answering Dataset(SQuAD)は質疑応答に関するタスクで、問題文とそれに関する質問・回答で構成されるデータセットです。すべての質問に対する回答は、対応する問題文の一部になっています(国語の抜き出し問題に似ています)。SQuADにはバージョンが二つあり(v1.1、v2.0)、v1.1は全ての質問が回答可能でv2.0では答えられない質問が含まれています。今回は答えられない質問などにも対応したいため、SQuAD 2.0形式のデータを使ってBERTをfinetuningします。
SQuAD 1.1
SQuAD 2.0
実際のSQuAD 2.0のデータ形式は以下のようになります。
{
"version": "v2.0",
"data": [
{
"title": "りんご",
"paragraphs": [
{
"qas": [
{
"question": "りんごは何色?",
"id": "56be85543aeaaa14008c9063",
"answers": [
{
"text": "赤",
"answer_start": 4
}
],
"is_impossible": false
},
{
"plausible_answers": [
{
"text": "美味しい",
"answer_start": 7
}
],
"question": "バナナは美味しい?",
"id": "5a8d7bf7df8bba001a0f9ab1",
"answers": [],
"is_impossible": true
}
],
"context": "りんごは赤くて美味しい。"
}
]
}
]
}
それぞれの項目の説明
| キー | 値 |
|---|---|
| version | バージョンを示している(今回は SQuAD 2.0を使うため v2.0) |
| data | 問題文ごとにデータをリスト形式で保持 |
| title | 問題文のタイトル |
| paragraphs | 問題文の段落一つとそれに関連する複数の質問、回答を保持 |
| qas | 質問と回答をリスト形式で保持 |
| question | 質問 |
| answers | 問題文から抜き出した答えとその位置のデータをリスト形式で保持。 train-v2.0では答えは0個または1個、dev-v2.0では答えは4つ存在する。 |
| text | 問題文から抜き出した答えのテキスト |
| answer_start | 問題文中の答えの位置情報、pythonの 問題文.find(答え) の値と一致する。(問題文内に答えが一回しか登場しない場合) |
| id | 質問固有のid |
| is_impossible | 答えられない質問の時にtrue、それ以外の時はfalse |
| plausible_answers | 質問が答えられないの時のみ存在する項目、問題文から答えになりうる部分を抜き出している |
| context | 答えが存在すると考えられる文章(問題文に当たる) |
学習データの用意
すでにQAのデータを持っている場合、データをSQuAD2.0の形式に成形するだけで学習データができるのですが、おそらく多くの方はこれらのデータを用意できないと思うので、今回はデータがない状態からSQuAD 2.0形式のデータを2万問分用意した方法も説明します。
データ作成
SQuAD 2.0形式のデータを作成するためには以下の情報が必要です。
1.context(問題文)
2.question(質問)
3.answer(回答)
日本語のQAデータにはNIILC Question Answering Dataset、NTCIR-6 QAC4、Yahoo! 知恵袋データ(第3版)などがありますが、上記の情報が含まれデータ数が多いデータセットが存在しません。(もし知っていれば教えてください)
そのため今回はSQuAD 2.0自体ををgoogle翻訳で翻訳してデータを作成します。
finetuningの仕方
はじめにでも言ったようにfinetuningはrun_squad.pyを少し変更して実行するだけでできます。
事前学習モデルの選択
この記事で使用しているTransformersのバージョン(2.8.0)では4つのモデルが使用できます。
- bert-base-japanese
- bert-base-japanese-whole-word-masking
- bert-base-japanese-char
- bert-base-japanese-char-whole-word-masking
詳細はcl-tohoku repositoryを見てください。
今回試したところbert-base-japanese-whole-word-maskingが一番性能がよかったのでこれを使用しますが、もし他のモデルも試してみたい場合はこのノートブックで簡単に試せるので試してみてください。
run_squad.pyの変更点
run_squad.pyの変更点は以下の3つだけです。すでに必要なところを変更したスクリプトをgithubに公開しているのでこちらを見るとわかりやすいと思います。
https://github.com/kuma807/bert_qa/blob/master/run_squad.py
1.mecabをimportする
import MeCab
mecabは形態素解析器で、BERTに与える日本語を分割するために使用します。
2.transformersレポジトリから新たに
- BertForQuestionAnswering
- AutoTokenizer
- AutoConfig
をimportする。これらは事前学習モデル、tokenizer、設定になっています。
from transformers import (
WEIGHTS_NAME,
AdamW,
AlbertConfig,
AlbertForQuestionAnswering,
AlbertTokenizer,
...省略...
XLNetTokenizer,
get_linear_schedule_with_warmup,
squad_convert_examples_to_features,
BertForQuestionAnswering,
AutoTokenizer,
AutoConfig,
)
3.MODEL_CLASSESに
- bert-base-japanese-whole-word-masking
を追加する。このクラス名はのちにfinetuningするときに使います。
MODEL_CLASSES = {
"bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
"camembert": (CamembertConfig, CamembertForQuestionAnswering, CamembertTokenizer),
"roberta": (RobertaConfig, RobertaForQuestionAnswering, RobertaTokenizer),
"xlnet": (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer),
"xlm": (XLMConfig, XLMForQuestionAnswering, XLMTokenizer),
"distilbert": (DistilBertConfig, DistilBertForQuestionAnswering, DistilBertTokenizer),
"albert": (AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer),
"bert-base-japanese-whole-word-masking": (AutoConfig.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking"), BertForQuestionAnswering.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking"), AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")),
}
MODEL_CLASSESに追加する形式は
"モデルのクラス名": モデルの設定, 事前学習モデル, tokinizerの設定
となっています。
run_squad.pyの実行
run_squad.pyの実行は以下のコマンドでできます。以下のコマンドはノートブック形式で実行されることを想定しているため、ターミナルから実行する場合は一番最初の!を取り除いてください。
!python bert_qa/run_squad.py\
--model_type モデルのクラス名 \
--model_name_or_path モデルの名前 \
--predict_file テストデータへのパス \
--train_file 学習データへのパス \
--do_train \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--fp16 \
--do_eval \
--save_steps 3000 \
--version_2_with_negative \
--output_dir 学習したモデルの保存場所/
今回の例でいくとモデルのクラス名がbert-base-japanese-whole-word-masking、モデルの名前がcl-tohoku/bert-base-japanese-whole-word-maskingになっています。
| オプション | 意味 |
|---|---|
| fp16 | 浮動小数点の精度を落とすことで学習を高速化する、これがないとcolaboratoryで実行できない |
| version_2_with_negative | squad 2.0で学習する場合必要 |
モデルの使用方法
こちらもノートブックの ”モデルの使用方法” にモデルを使用するためのスクリプトが乗っているので確認してください。qiitaではモデルを使用するためのスクリプトについて説明します。さらに詳しいことがきになる方はこちらへ。
モデルの読み込み
1.設定をmodel_directoryから読み込む
config = AutoConfig.from_pretrained(model_directory + "/config.json")
tokenizer_config = AutoConfig.from_pretrained(model_directory + "/tokenizer_config.json")
名前から分かるようにconfigはモデルの設定、tokenizer_configはtokenizerの設定になっています。
2. 1.の設定でモデル読み込む
model = BertForQuestionAnswering.from_pretrained(pretrained_model, config=config)
model.load_state_dict(torch.load(model_directory + "/pytorch_model.bin", map_location=torch.device('cpu')))
tokenizer = AutoTokenizer.from_pretrained(pretrained_model, config=tokenizer_config)
2行目のmap_location=torch.device('cpu')となっているところをmap_location=torch.device('cuda')と変更することでgpuでの実行ができるようになります。
モデルへの入力
モデルへの入力は
- input_ids
- token_type_ids
の二つになります。
question = "りんごは何色?"
context = "りんごは赤くて美味しい。"
input_ids = tokenizer.encode(question, context)
token_type_ids = [0 if i <= input_ids.index(3) else 1 for i in range(len(input_ids))]
input_ids
tokenizer.encode(question, context)で行われてる処理を説明します。
まずquestionとcontextをmecabで分割します。この時一つの単語が分割された場合、 ##を前につけることでもとは一つの単語であったことを表しています。分割したものを特別なトークン(CLSとSEP)を使って、[CLS] + question + [SEP] + context + [SEP] のように連結します。この特別なトークンについてはそのようなものがある程度の認識でいいと思います。
実際の値
['[CLS]', 'りん', '##ご', 'は', '何', '色', '?', '[SEP]', 'りん', '##ご', 'は', '赤く', 'て', '美味', '##しい', '。', '[SEP]']
[CLS]は文章の始まり、[SEP]は文章の終わりに追加される特別なトークンです。
これを単語ごとにidに変換したものがinput_idsになります。
実際の値
[2, 9768, 29066, 9, 1037, 1232, 2935, 3, 9768, 29066, 9, 22628, 16, 18178, 485, 8, 3]
対応関係
{'[CLS]': 2, 'りん':9768, '##ご':29066, 'は':9, '何':1037, '色':1232, '?':2935, '[SEP]':3, '赤く':22628, 'て':16, '美味':18178, '##しい':485, '。':8, '[SEP]'}
ここで注意する点としては日本語のBERTでは[CLS]が2、[SEP]が3に対応していることです。(英語版では[CLS]:101, [SEP]:102に対応しています)
token_type_ids
token_type_idsは一つ目の文章には0, 二つ目の文章には1を割り当てたリストです。
実際の値
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
また一つ目の[SEP]は一つ目の文章として扱われます。
モデルの出力
モデルの出力のされ方は、「start_scores」「end_scores」のスコアで表現され、それぞれ「答えが始まる位置のスコア」「答えが終わる位置のスコア」にあたります。
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
start_scores,end_scores共にtensorflowのtensor型(softmax前)です。
実際の値
start_scores
tensor([[-5.4366, -3.2602, -8.1666, -8.0910, -3.1464, -5.3078, -6.6031, -5.4042,
-1.6283, -6.9755, -7.4763, 2.0868, -6.4028, -3.1525, -6.1728, -6.0557,
-5.2687]], grad_fn=)
end_scores
tensor([[-4.9398, -9.0989, -7.0649, -8.9144, -3.7368, -2.6993, -4.5407, -0.1127,
-7.2395, -5.5424, -7.2156, 1.9255, -1.7737, -4.3648, -0.3700, -1.0993,
0.0879]], grad_fn=)
この時のstart_scoresの最大値のindexから、end_scoresの最大値のindexまでがモデルの予想する答えになります。(例は "モデルの出力を日本語に変換" に記載)
モデルの出力を日本語に変換
input_idsは全て日本語に対応する数値だ表されているため、これを日本語に直しall_tokensと言う変数に格納します。
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
実際の値
all_tokens
['[CLS]', 'りん', '##ご', 'は', '何', '色', '?', '[SEP]', 'りん', '##ご', 'は', '赤く', 'て', '美味', '##しい', '。', '[SEP]']
このall_tokoensとstart_scores、end_scoresを使うことでモデルの出力を見ることができます。
prediction = ''.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1])
prediction = prediction.replace("#", "")
prediction = prediction.replace(" ","")
上のstart_scoresとend_scoresの例で言うとstart_scoresの最大値のindexが11、end_scoresの最大値のindexが11となっているため、モデルの予想はall_tokens[11:11 + 1]の"赤く"になります。またpredictionには無駄なスペースや"#"が含まれるためこれを取り除きます。
結果
作成したモデルの精度
20,216問学習させたところ答えが存在しない問題に対して精度は約97.09%の確率で答えがないと、答えが存在する問題に対して完全一致する答えを約57.46%の確率で文章中から抜き取ることができました。
| テストデータの詳細 | |
|---|---|
| 答えがある問題 | 2329問 |
| 答えがない問題 | 2295問 |
| 全体 | 4624問 |
| モデルの予想精度 | 答えと出力が完全一致したパーセント |
|---|---|
| 答えがある問題 | 57.46% |
| 答えがない問題 | 97.09% |
| 全体 | 77.11% |
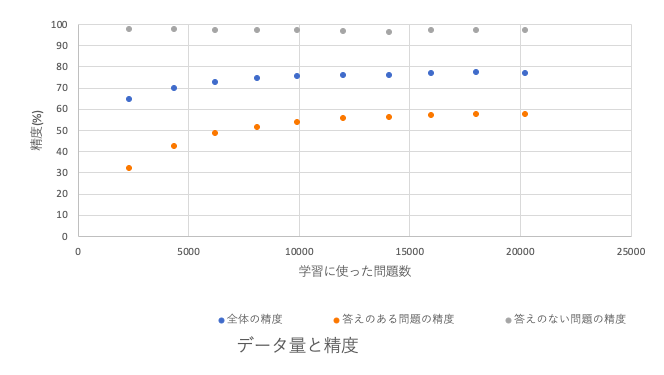
また学習に使った質問数とモデルの精度の関係は以下のグラフのようになりました。このグラフから分かるようにモデルの性能が14,000問を超えたあたりから全体の精度・答えのある問題の精度が共に収束してきているので、おそらく14,000問ほどデータを用意できれば十分だと思います。答えのない問題だけに関しては学習に使った問題数が2,000問の時点で97%を超える精度で予想できてるので、人間の作成したデータのみでの学習も比較的容易だと思います。
モデルの出力
実際にモデルを動かせるノートブックを作成したのでよかったら動かしてみてください。ノートブックを使うには学習済みモデルを事前にダウンロードしておいてください。
テストデータの一部に対するモデルの予想は以下のようになっており、答えられない問題のanswerは[CLS]となっています。
モデルの精度評価に利用した4624問に対する全ての予想をみたい方はこちらを。questionが質問、answerは正しい答え、predictionはモデルの予想結果になっています。
問題文
他のほとんどの大学と同様、ノートルダムの学生は多くのニュースメディアを運営しています。学生が運営する9か所のアウトレットには、3つの新聞、ラジオ局とテレビ局、いくつかの雑誌と雑誌があります。 1876年9月に1ページの雑誌として始まり、Scholastic誌は月に2回発行され、米国で最も古い継続的な大学出版物であると主張しています。もう1つの雑誌The Jugglerは年に2回発行され、学生の文学とアートワークに焦点を当てています。ドーム年鑑は毎年発行されます。新聞にはさまざまな出版物の関心があり、オブザーバーは毎日発行され、主に大学やその他のニュースを報告し、ノートルダムとセントメアリー大学の両方の学生がスタッフを務めています。 ScholasticやThe Domeとは異なり、The Observerは独立した出版物であり、教授陣や大学からの編集上の監督はありません。 1987年、一部の学生がThe Observerが保守的な偏見を示し始めたと信じたとき、リベラルな新聞、Common Senseが出版されました。同様に、2003年に、他の学生がこの論文がリベラルな偏見を示していると信じたとき、保守的な論文Irish Roverが生産に移行しました。どちらの論文もThe Observerほど頻繁には出版されていません。ただし、3つはすべての生徒に配布されます。最後に、2008年春、政治学研究のための学部ジャーナルBeyond Politicsがデビューしました。
| question | answer | prediction |
|---|---|---|
| 学生論文Common Senseがノートルダムで出版を開始したのは何年ですか? | 1987 | 1876 |
| 聖十字会の本部はどこですか? | ローマ | ローマ |
| ポーランド文学におけるショパンの最も早い目撃は何ですか? | [CLS] | [CLS] |
| ノートルダム寺院で最も古い建物は何ですか? | オールドカレッジ | オールドカレッジ |
| 建設技術者は誰として知られていましたか? | [CLS] | [CLS] |
| 世界の文化の中心地と呼ばれているのはどの都市ですか? | [CLS] | [CLS] |
| ビヨンセは誰と結婚していますか? | [CLS] | [CLS] |
| ノートルダム大学工学部は何年に設立されましたか? | 1920 | 1920 |