はじめに
化合物中の特定の部分構造(官能基など)の数を数えていきたいと思います。その①(カルボキシル基編)の続編となりますので、その①をお読みになっていな方はその①も参考にしてください。今回は自ら用意した化合物中のエステル結合の数を数えてみたいと思います。
この記事に関してはインフォマジシャン研究所の藤様にいろいろとアドバイスを頂いた内容を投稿しています。(掲載の許可はいただいております)。インフォマジシャン研究所ではインフォマティクスを専門としている方と議論することができます!
※マテリアルズインフォマティクス関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
SMILESとSMARTS
本題に入る前に「SMILES」と「SMARTS」について整理していきましょう。一般的な内容は次のサイトなどを参考にしてください。
SMILESは分子の表記方法でDr. David Weiningerが考案した分子記述言語です。
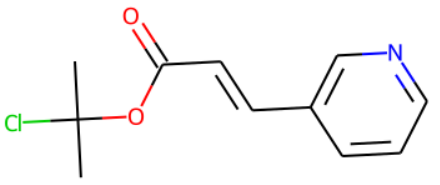
上記の分子は次のSMILESで表現されます。
ClC(C)(C)OC(/C=C/C1=CN=CC=C1)=O
SMARTSはSMILES言語を検索クエリ用に拡張した構造検索のための表記方法です。例えば[C,N]は脂肪族炭素または脂肪族窒素を表し、SMILESよりもより曖昧な表現が可能です。SMARTSに関する詳細はDAYLIGHT社のHPが参考になります。こちらのリンクにも詳しく記載があります。
またSMARTSはSMARTS PLUSで確認することが可能です。SMARTSはSMILESよりも曖昧に表記できて検索性が高い分、使いこなすのはかなり難しい印象です。
環境
- python 3.7.13
- rdkit 2022.03.4
化合物中のエステル結合を数えていく
化合物の準備(実際にデータがある場合は不要)
まずは自分でサンプルとなる化合物を作っていきます。
from rdkit import Chem
# それぞれのエステル結合は0,1,2,1,2個
m0 ="CC(OC)OC"
m1 ="CC(OCC(C)=O)=O"
m2 ="COC(C1=CC=CC=C1C(OC)=O)=O"
m3 ="O=C(OC)OC"
m4 ="O=C(OO1)C2=CC=CC=C2C1=O"
それぞれの化合物を可視化します。
Chem.MolFromSmiles(m0)
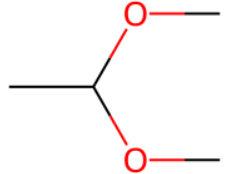
Chem.MolFromSmiles(m1)
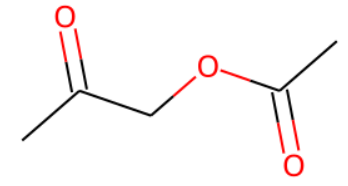
Chem.MolFromSmiles(m2)
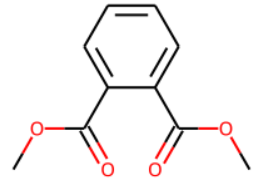
Chem.MolFromSmiles(m3)
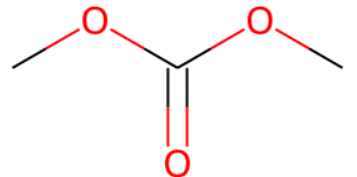
Chem.MolFromSmiles(m4)
それぞれの化合物を一括で処理できるようにデータフレームに格納します。
import pandas as pd
df = pd.DataFrame(
data={"compound": ["m0", "m1", "m2", "m3", "m4"],
"smiles": [m0, m1, m2, m3, m4]}
)
df

実際にデータがある場合はこのようなデータフレームを読み込んでここから実行していくことが想定されます。次にsmilesをMolに変換してリストで保持します。
mol_list = [Chem.MolFromSmiles(x) for x in list(df["smiles"]) if x is not None]
部分構造の探索(その1)
検索する部分構造をSMARTS表記で定義します。
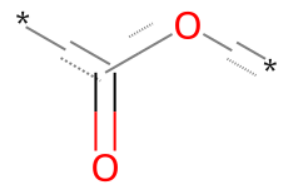
q1 = Chem.MolFromSmarts("*[CX3](=O)[OX2H0]*")
q1
GetSubstructMatchesは指定した部分構造がマッチする原子インデックスが返ってくるので、これをlenで取り出して部分構造の数を数えます。今回は一括で処理します。
[len(x.GetSubstructMatches(q1)) for x in mol_list]
[0, 1, 2, 2, 0]
m3のエステル構造が2、m4のエステル構造が0と認識されている点が問題です。m3についてはC=Oの左右にOがあるので、ダブルカウントされていることが考えられます。まずはm4でエステル構造が0と認識れている問題について考察していきます。
芳香族性の認識
m4のSMILESを確認してみます。
Chem.MolToSmiles(mol_list[4])
'O=c1ooc(=O)c2ccccc12'
このことからm4の左右の環状構造はともに芳香族として認識されていることが分かります。左側の環状構造はベンゼン環ではないなの、なぜ芳香族として認識されるのでしょうか?これはRDKitの芳香族の認識のルールに起因します。こちらに詳細は載っていますが、「芳香族性は単純であると同時にどうしようもなく複雑な不愉快な話題の一つです。」との記載があり、化学者の直感的な理解とは異なるようです。
部分構造の探索(その2)
上記の内容を踏まえて、例えば炭素原子はC(脂肪族中の炭素)ではなく#6で定義することで芳香族の問題をクリアしてみようと思います。
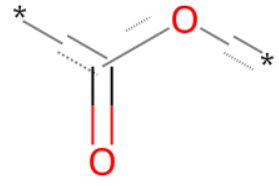
q2 = Chem.MolFromSmarts("*[#6;X3](=O)[#8]*")
q2
[len(x.GetSubstructMatches(q2)) for x in mol_list]
[0, 1, 2, 2, 2]
これでm4のエステル構造が認識されないという問題はクリアしました。次はm3のエステル結合のダブルカウントに関してです。
部分構造の探索(その2)
m3のエステル結合を1つとしてカウントするためには、C=Oだけを数えるとケトンもカウントされてしまうので、-O-C(=O)-O-もカウント対象として対処します。
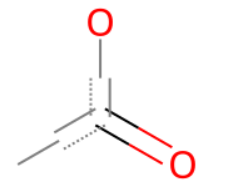
Chem.MolFromSmarts("[#6;X3](=O)([#6])([#8])")
Chem.MolFromSmarts("[#6;X3](=O)([#8])([#8])")
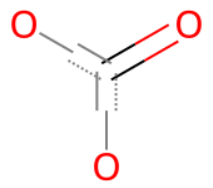
この2つをorでカウントできるように、以下のように部分構造を定義します。
q3 = Chem.MolFromSmarts("[$([#6;X3](=O)([#6])([#8])),$([#6;X3](=O)([#8])([#8]))]")
[len(x.GetSubstructMatches(q3)) for x in mol_list]
[0, 1, 2, 1, 2]
これで上手く化合物中のエステル結合の数をカウントすることができました。
まとめ
今回はエステル結合を例として化合物中の部分構造を数える方法を紹介いたしました。