はじめに
アトラシアンのサポートエンジニアの岡本(ひげの人)です。普段はその肩書き通り JIRA を初めとする、様々なアトラシアン製品の テクニカルサポートを行っています。今年も Advent Calendar をやってくださっていると聞いて、アトラシアン製品のサポートならではな感じのことを書いてみようと思い、現在この記事を書いています。
本記事で扱うテーマ
数あるアトラシアン製品の中でも、私個人としては JIRA のサポートを行う機会が多いのですが、JIRA の、特に課題検索に関する問題を扱う場合、まずはお客さんにインデックスの再作成をお試し頂くケースが少なくありません。JIRA の管理者をされている方ならば、管理画面右上に以下のようなポップアップが表示されるのを見たことのある方もいらっしゃるのではないかとは思いますが、その際に実施して頂く例のアレです。
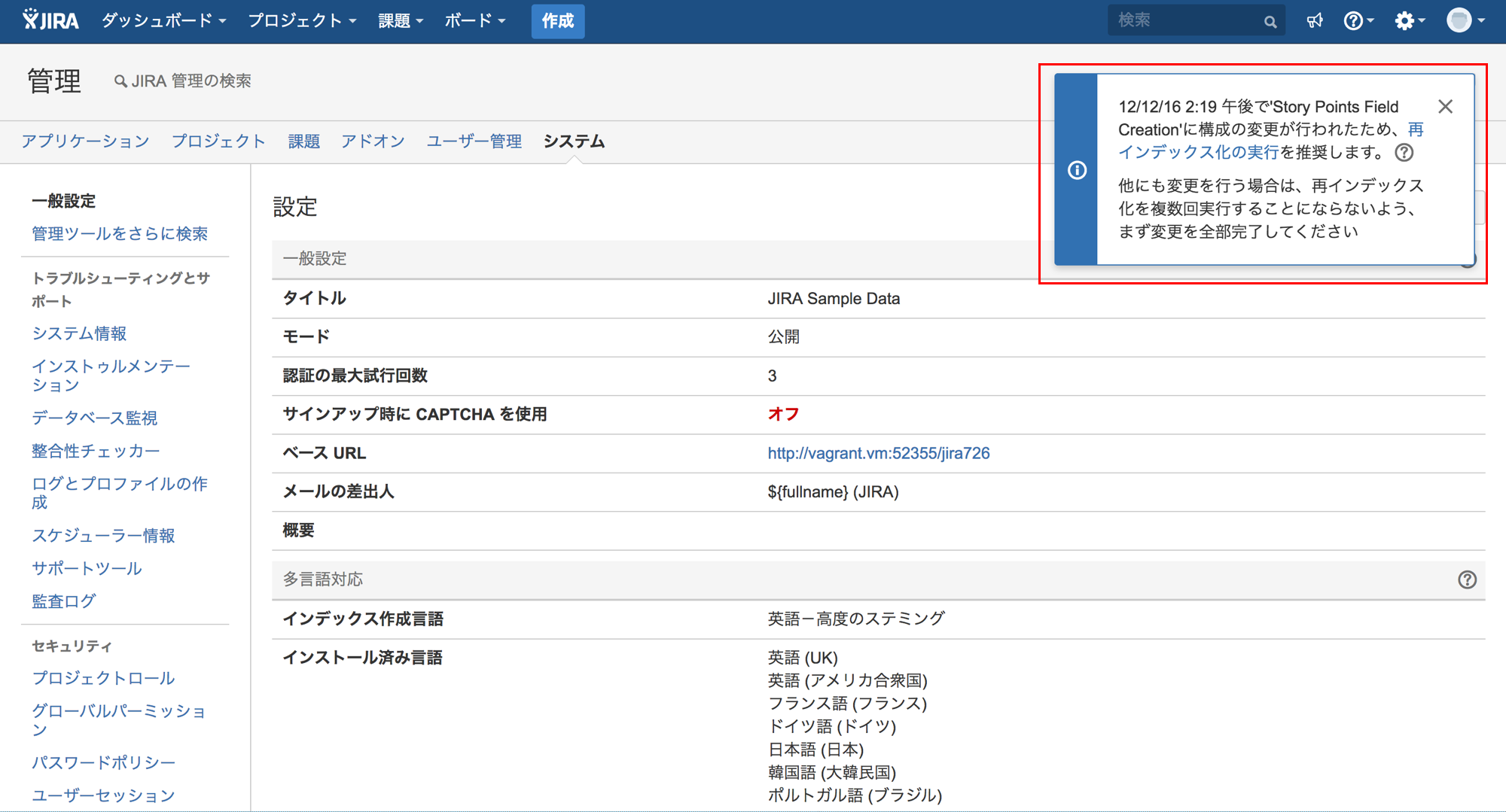
この「インデックスの再作成」は、基本的にはこちらのページでも説明されているように、JIRAの課題フィールドに影響を与える設定変更が行われた際に必要となるものです。必要なタイミングでこちらを実施していない場合、インデックスに不整合が生じ、課題が正しく検索できない問題が発生する可能性があります。
ところで、JIRA で使われている「インデックス」とは実のところ何者なのでしょうか? RDBMS なんかのインデックスのことを言っているのでしょうか?
実は違います。今回の投稿では、この JIRA の「インデックス」について簡単にまとめてみようと考えています。
JIRA のインデックスとは?
実は JIRA の検索機能のバックエンドには Apache Lucene という検索エンジンが使用されており、JIRA のインデックスはこの Lucene によって作成されるものとなっています。この Lucene ですが、皆さんご存知の Elasticsearch のバックエンドとしても利用されていることで有名です。
JIRA 上での課題検索は、連携している DB の情報ではなく、インデックス情報を使用して行われます。インデックスは、JIRA の課題が作成・更新される度にそれに合わせて構築されていくものなので、特に前述したような設定変更が無い限りは再作成を行う必要はありません。ただ、新規アドオンの追加や新たなフィールドの追加等の変更が行われた際には、過去に作成されたインデックスにも影響が生じることから、再作成が必要となります。
JIRA のサポートをしていると、よくお客さんから「JIRA のインデックスの再作成は、定期的にやった方がいいですか?」という質問を受けるのですが、上記の理由からも通常の運用であれば行う必要はありません。ただ、例えば一日のうちに何度も新規のカスタムフィールドが作られるような運用を行っているケースでは、その度にインデックスの再作成を行っていると、常に JIRA に負荷がかかっている状態となりパフォーマンス問題につながる恐れがあるため、一日に一回まとめて再作成するような運用を行われているユーザーさんもいるようですね。
さて、ここまで JIRA のインデックスの話をしてきましたが、概念だけの話であまりピンと来ていない方もいらっしゃるのではないでしょうか?そんな方々のために、以降では実際に JIRA のインデックスを Hack する方法を書いておきます。
JIRA のインデックスに触れてみる
JIRA のインデックスは、$JIRA_HOME/caches/indexes 配下にファイルとして保存されます。
具体的には以下のようなファイルが作成されます。(以降の話は、2016/12/14 現在における最新版の JIRA Software 7.2.6 にて確認を行っています。)
$ tree $JIRA_HOME/caches/indexes/
caches/indexes/
├── changes
│ ├── segments.gen
│ ├── segments_rv
│ ├── _ut.fdt
│ ├── ...
├── comments
│ ├── _pp.fdt
│ ├── ...
│ ├── segments.gen
│ └── segments_ng
├── entities
│ ├── portalpage
│ │ ├── _0.fdt
│ │ ├── ...
│ │ ├── segments_2
│ │ └── segments.gen
│ └── searchrequest
│ ├── segments_1
│ └── segments.gen
├── issues
│ ├── _n9.fdt
│ ├── ...
│ ├── segments.gen
│ └── segments_ld
└── worklogs
├── segments_1
└── segments.gen
流石にちょっと、これだけ見ても何のことかわかりませんよね。どのファイルが何の JIRA 課題に紐付いているかもさっぱりです。
という訳で、ちょっとした裏技を使います。ブラウザから JIRA にアクセスし、JIRA 管理画面 > システム > トラブルシューティングとサポート > ログとプロファイルの作成 を開いてみてください。既定のロガー という項目から、アプリケーションログのログレベルを Java のパッケージ毎に変更することが可能です。ここで以下のように com.atlassian.jira.issue.search.providers というパッケージのログレベルを TRACE もしくは DEBUG にしてみてください。
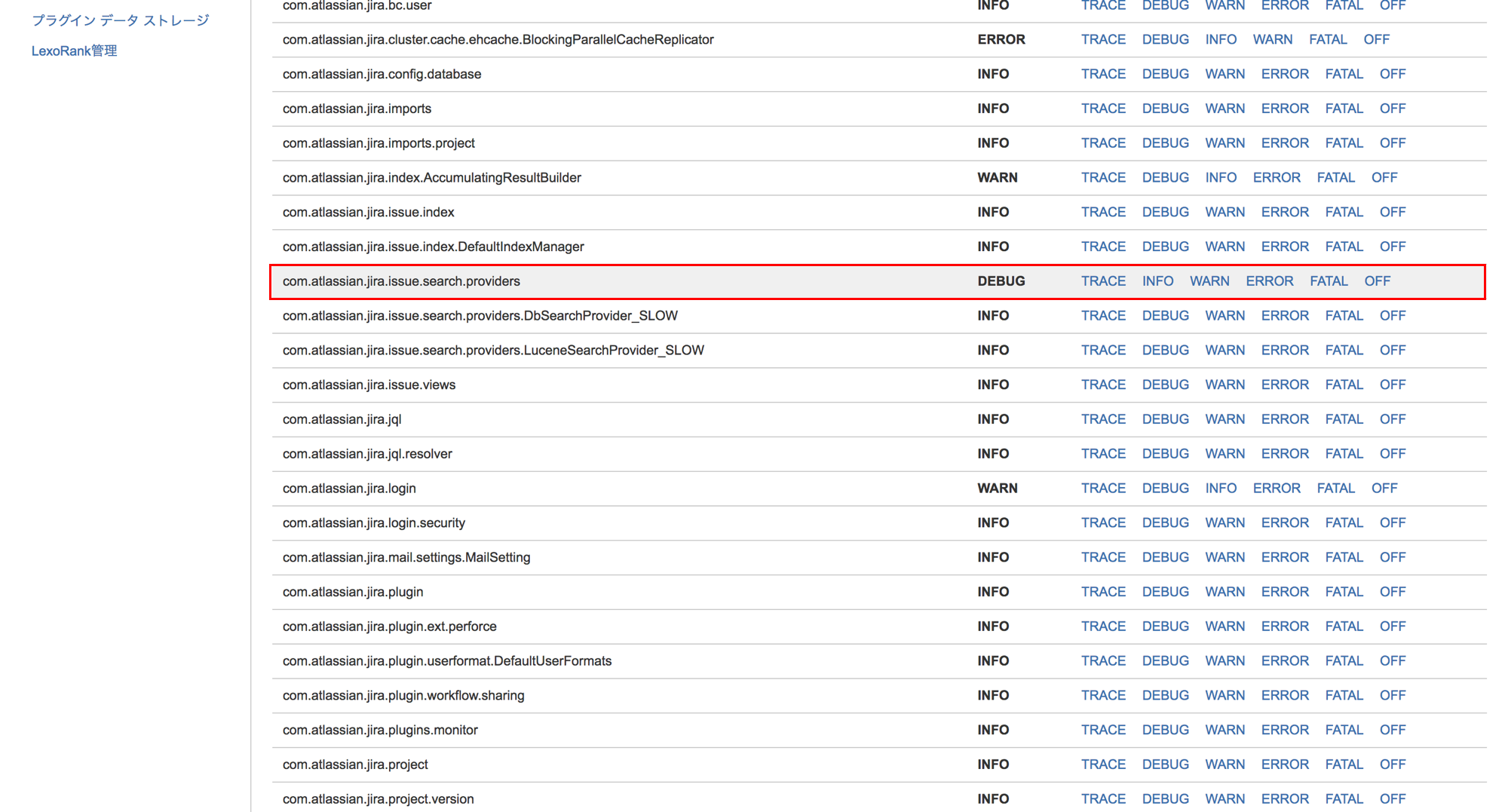
こうすることで、JIRA 課題を検索する際にどのような JQL が実行されたかが、アプリケーションログに出力されるようになります。また、Lucene 自体も独自のクエリ言語を持っており、適宜 JQL が Lucene のクエリに置き換えられることでインデックスの中身の検索を行いますが、この時に実行された Lucene クエリの情報についても上記の設定によってアプリケーションログに出力されるようになります。
実際にどのような情報が出力されるかを確認してみましょう。上記の設定を行った状態で、課題ナビゲーターにて、以下のような条件で課題の検索を行ってみます。
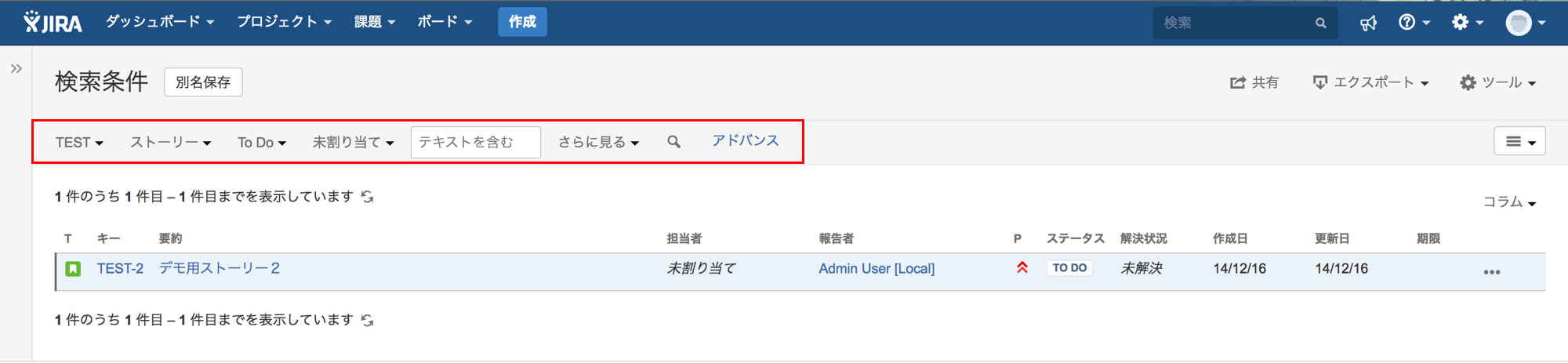
こちらのスクリーンショットは 「TEST」というプロジェクトに属している課題のうち、課題タイプが 「ストーリー」、ステータスが 「To Do」であり、且つ担当者が決まっていないものを検索しているところになります。このタイミングで、JIRA のアプリケーションログ <JIRA_HOME>/log/atlassian-jira.log を見てみると、以下のような情報が出力されているのが確認できます。
2016-12-14 17:16:48,944 http-nio-52355-exec-2 DEBUG admin 1036x429x1 52rs9r 192.168.33.1 /issues/ [c.a.j.i.search.providers.LuceneSearchProvider] JQL query: {project = "TEST"} AND {issuetype = "Story"} AND {status = "To Do"} AND {assignee in (EMPTY)}
2016-12-14 17:16:48,944 http-nio-52355-exec-2 DEBUG admin 1036x429x1 52rs9r 192.168.33.1 /issues/ [c.a.j.i.search.providers.LuceneSearchProvider] JQL lucene query: +projid:10100 +type:10001 +status:10000 +issue_assignee:unassigned
2016-12-14 17:16:48,944 http-nio-52355-exec-2 DEBUG admin 1036x429x1 52rs9r 192.168.33.1 /issues/ [c.a.j.i.search.providers.LuceneSearchProvider] JQL sorts: [<custom:"projkey": com.atlassian.jira.issue.search.parameters.lucene.sort.StringSortComparator@103b2804>!, <custom:"keynumpart_range": com.atlassian.jira.issue.search.parameters.lucene.sort.StringSortComparator@4a7600d6>!]
2016-12-14 17:16:48,945 http-nio-52355-exec-2 DEBUG admin 1036x429x1 52rs9r 192.168.33.1 /issues/ [c.a.j.i.search.providers.LuceneSearchProvider] Lucene boolean Query:+projid:10100 +type:10001 +status:10000 +issue_assignee:unassigned
{project = "TEST"} AND {issuetype = "Story"} AND {status = "To Do"} AND {assignee in (EMPTY)} という JQL が +projid:10100 +type:10001 +status:10000 +issue_assignee:unassigned という Lucene クエリに変換されて実行されているのがわかるかと思います。
要するに、先程の <JIRA_HOME>/caches/indexes 配下のデータに対して、何らかの手段にて上記の Lucene クエリを実行できさえすれば、JIRA が内部的に行っているのと同様に課題データを取り出せることになりますが、ここで一つ良い方法があります。
結論から言うと、Lukeというツールを使用します。位置づけとしては、Lucene インデックスの可視化ツール、といったところかと思います。このツールは Java で書かれているので、Java がインストールされている環境であればどこでも動きます。(私は macOS Sierra にて動作確認を行っています。)
JIRA Software 7.2.6 で使用している Lucene のライブラリのバージョンに対応する Luke をダウンロードし、以下のコマンドを実行することで、先程の JIRA のインデックスの中身を可視化することが可能です。
$ java -classpath path/to/lukeall-3.3.0.jar -jar path/to/lukeall-3.3.0.jar $JIRA_HOME/caches/indexes
以下のような GUI が起動するので、Search タブを開き、Enter search expression here: という箇所に先程の Lucene クエリを入力した上で、Search ボタンを押下します。ここで一つ、どうでも良い話なのですが、Lucene クエリを入力する際に、恐らく文字数が多いためコピペをすることになると思いますが、Luke のアプリ上だと Mac を使用している場合でもペーストは Cmd + c ではなく Ctrl + c のようなので気をつけましょう。(ちょっとハマりましたw)
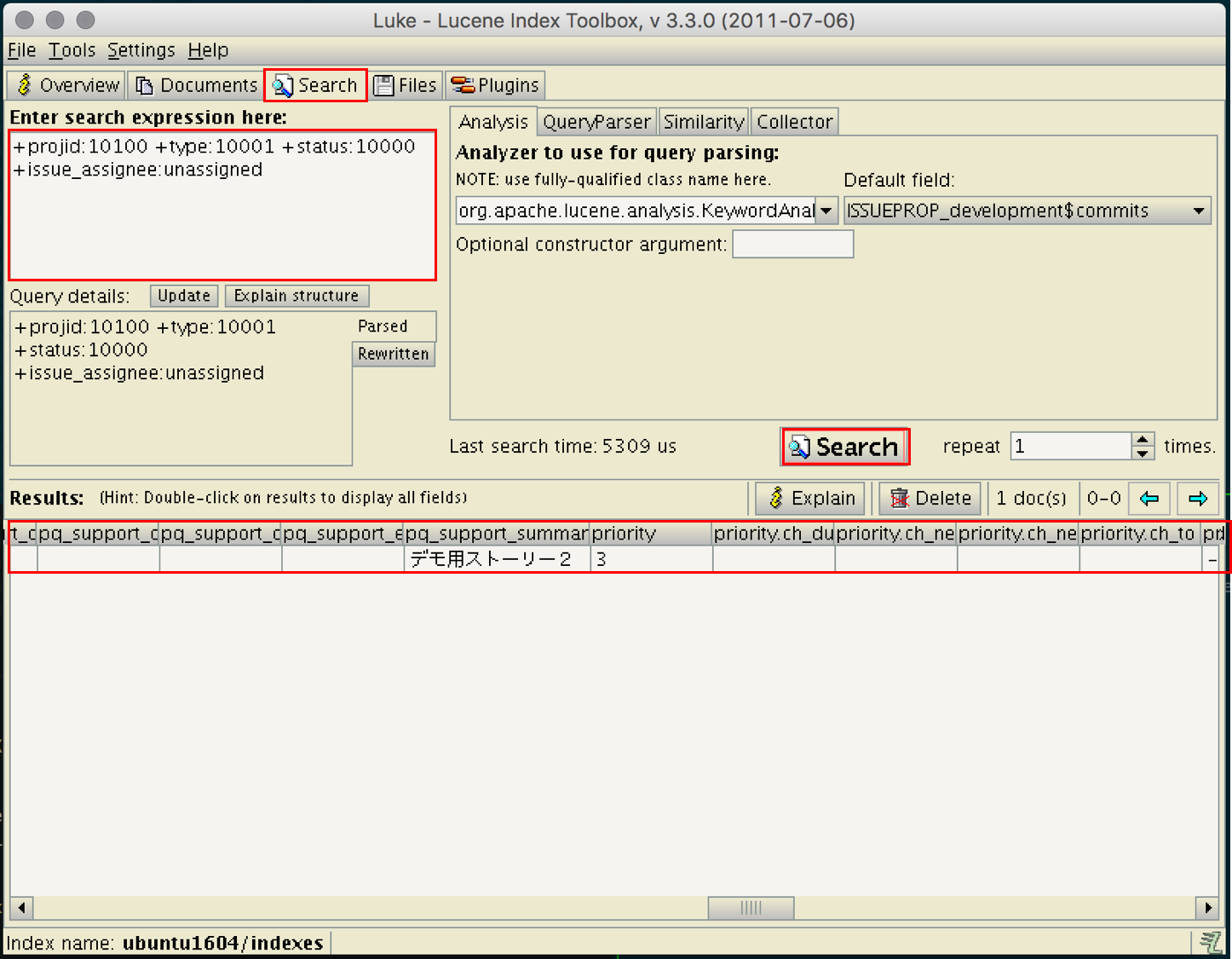
検索が完了すると、上記の画像の Results のところに検索結果が表示されます。JIRA の UI から検索を行った時と同一の課題「デモ用ストーリー2」の情報が表示されているのがわかりますね。priority というプロパティについては「3」となっていて何のこっちゃと思うかもしれませんが、この値は DB の値とマッピングされています。JIRA と接続している DB 上で以下のように SQL を実行することで、この「3」という数字が実際には何の優先度を表しているかを確認することが可能です。(以下は MySQL で実行した結果となります。)
mysql> select * from priority;
+----+----------+----------+----------------------------------------------------------------------------+---------------------------------------+--------------+
| ID | SEQUENCE | pname | DESCRIPTION | ICONURL | STATUS_COLOR |
+----+----------+----------+----------------------------------------------------------------------------+---------------------------------------+--------------+
| 1 | 1 | Blocker | Blocks development and/or testing work, production could not run. | /images/icons/priorities/blocker.png | #cc0000 |
| 2 | 2 | Critical | Crashes, loss of data, severe memory leak. | /images/icons/priorities/critical.png | #ff0000 |
| 3 | 3 | Major | Major loss of function. | /images/icons/priorities/major.png | #009900 |
| 4 | 4 | Minor | Minor loss of function, or other problem where easy workaround is present. | /images/icons/priorities/minor.png | #006600 |
| 5 | 5 | Trivial | Cosmetic problem like misspelt words or misaligned text. | /images/icons/priorities/trivial.png | #003300 |
+----+----------+----------+----------------------------------------------------------------------------+---------------------------------------+--------------+
5 rows in set (0.00 sec)
上記の結果の通り、「3」は優先度「中(Major)」を表していました。
という訳で、無事に JIRA のインデックスの中身を見ることができましたね。めでたしめでたし。
おわりに
今回は Luke を使って JIRA のインデックス情報を可視化する方法を紹介しましたが、実際に我々がサポートを行う際にも、課題検索のパフォーマンス問題や、そもそも課題が検索にひっかからない等の問題の時には、この方法でインデックスを直接見てみることがあります。皆さんもそういった問題に遭遇した場合には、是非一度お試し頂ければ幸いです。(もちろんすぐに Atlassian の日本語サポート にお問い合わせ頂いても OK です!)
明日は nabe3 さんから「はじめての Bitbucket」についてだそうです。Bitbucket も最近 Pipeline なんかの機能が加わって、面白くなってきていますね。期待しちゃいましょう!