求められる知識
IPAのページより抜粋。何を求められているかは知っておいたほうが良いんでしょうね。
高品質なデータベースを企画、要件定義、開発、運用、保守するため、次の知識・実践能力が要求される。
No. 求める技術水準 (1) データベース技術の動向を広く見通し、目的に応じて適用可能な技術を選択できる。 (2) データ資源管理の目的と技法を理解し、データ部品の標準化、リポジトリシステムの企画・要件定義・開発・運用・保守ができる。 (3) データモデリング技法を理解し、利用者の要求に基づいてデータ分析を行い、正確な概念データモデルを作成できる。 (4) データベース管理システムの特性を理解し、情報セキュリティも考慮し、高品質なデータベースの企画・要件定義・開発・運用・保守ができる。
午後の出題範囲
IPAの試験要綱より抜粋。
- データベースシステムの企画・要件定義・開発に関すること データベースシステムの計画,要件定義,概念データモデルの作成,コード設計,物理デー タベースの設計・構築,データ操作の設計,アクセス性能見積り,セキュリティ設計 など
- データベースシステムの運用・保守に関すること データベースの運用・保守,データ資源管理,パフォーマンス管理,キャパシティ管理,再 編成,再構成,バックアップ,リカバリ,データ移行,セキュリティ管理 など
- データベース技術に関すること リポジトリ,関係モデル,関係代数,正規化,データベース管理システム,SQL,排他制御, データウェアハウス,その他の新技術動向 など
全体像
まず[こちら]([サルが書く]DB設計を達人に学んだのでまとめてみた - Qiita https://qiita.com/hajime_shoji/items/ad5ff1dc96f50287bc00)でも読んで全体像を把握しよう。
間違えやすい用語集
-
候補キー
- 関係のタプルを一意に識別できる属性または属性の組のうち極小のもの
- スーパーキーはタプルを識別できるすべての組なので、区別すること
- 代理キー(別名:サロゲートキー)は主キーに選ばれなかった候補キーのこと
- 連番など人工的に?振ったキーもこれに該当する
- 関係のタプルを一意に識別できる属性または属性の組のうち極小のもの
-
非キー属性
- 候補キーに該当しない属性
-
等結合と自然結合
-
等結合
- 直積から結合条件(例えばR.A=S.A)によりタプルを抽出したもの
- 結合条件は結合後の表に重複して残る
-
自然結合
-
等結合において結合条件として用いた属性の重複をなくしたもの
-
内部結合との違いは、自然結合が結合条件を指定しないのに対し、内部結合は条件を指定して結合する
-
-
ER図のカーディナリティ(多重度)
自分が苦手なので。[こちら](「一対一」「一対多」「多対多」のリレーションを分かりやすく説明する - akiyoko blog https://akiyoko.hatenablog.jp/entry/2016/07/31/232754)がとてもわかり易い。
正規形
第3正規形までは難しくないので割愛。
ボイスーコッド正規形
- 概要:非キーからキーへの関数従属をなくす
- 正規化の方法:非キーからキーへの関数従属の関係にある列を、別のテーブルに分割する
- 正規化の注意点:「多対多」の関連になるケースが発生しうるため、「1対多」の関連を生むようにテーブルを分割すること。また、業務用件的に登録できてはならない組み合わせのレコードを登録することができるため、アプリケーション側で制御する必要がある
第四正規形
- 概要:関連エンティティに含まれる関連が一つだけにする
- 対象:非キー属性を持たない、キーだけのテーブル
- 正規化の方法:独立な多値従属性が複数存在するテーブルを「A→→B|C」を、「A→→B」「A→→C」という2つの多値従属性に分割する
- 多値従属性:Aが決まるとBの集合が決まる関係「A→→B」のこと
※ 関連 = 「テーブル同士の関連」のこと, エンティティ = 「テーブル」のこと
第五正規形
- 概要:第四正規化すると稀に元に戻せなくなるが、それが元に戻せる
- 正規化の方法:関連エンティティを作成し、一つの関連に付き一つのテーブルがある状態にする
ボイスコッド正規形については[こちら](ボイスコッド正規化 - Qiita https://qiita.com/gooddoog/items/f40a7f0602bbe6afa1cf#comments)がわかりやすい。
第四と第五は[こちら](第四正規化・第五正規化・ボイスコッド正規化がややこしいので、備忘録として自分なりにまとめてみた(データベーススペシャリストの勉強) | メサイア・ワークス https://www.messiahworks.com/archives/3399)、もしくは[こちら](わかりやすい第四正規形、第五正規形 - making for the future https://noanohakobune.hatenablog.com/entry/2014/04/14/124806)を参照。でもたぶん試験にはでない(特に第五)。
ちなみに、上述したが、「非キー」という言葉は候補キー以外の列のことをいう。よって、候補キーは非キー列ではなく、上述の従属性を見る際の対象ではないため注意が必要である。
結合
自然結合
内部結合や外部結合を行う際に自然結合を指定すると、同じ名前とデータ型をもつ属性を、システムが自動的に結合キーと判断し、結合する。(列に重複がない)
- 結合キーを自動決定するため、USINGにおける指定はできません
- 同じ名前の属性が複数あるいは複数組が存在する場合、全て結合キーとなります
- 表示列を「*」で指定した場合、表示列は「結合キーの属性」「結合キー以外の社員テーブルの属性」「結合キー以外の部門テーブルの属性」の順に表示されます
- 「INNER」「OUTER」は省略可能です
内部結合
内部結合には以下の3種類の方法がある。
USINGで連結キーを指定する方法(構文3)は連結キーの名称が等しい場合のみ利用可能。
WHEREで結合する方法は内部/外部が明示されないため、非推奨。
SELECT 社員.社員コード, 社員.社員名, 部門.部門コード, 部門.部門名
FROM 社員, 部門
WHERE 社員.部門コード=部門.部門コード
SELECT 社員.社員コード, 社員.社員名, 部門.部門コード, 部門.部門名
FROM 社員 INNER JOIN 部門
ON 社員.部門コード=部門.部門コード
SELECT 社員.社員コード, 社員.社員名, 部門.部門コード, 部門.部門名
FROM 社員 INNER JOIN 部門
USING (部門コード)
外部結合とかはそんなに難しくないと思うので割愛
結合アルゴリズム
-
ネスト・ループ結合アルゴリズム
- テーブルAの各レコードについてテーブルBのすべてのレコードと比較する
-
マージ結合アルゴリズム
- あらかじめソートした2つのテーブルのそれぞれについてポインタを進めながら比較
-
ハッシュ結合アルゴリズム
- テーブルBに対してハッシュ・テーブルを作成し、それを利用してテーブルAの各レコードについて検索を実行する
午前Ⅱくらいにしか出題されないと思いますが、[こちら]([SQL実践入門]結合のアルゴリズム Nested Loops, Hash, Sort Merge - SIS Lab https://www.meganii.com/blog/2015/06/01/how-to-move-join-nestedloops-hash-sortmerge/)もわかりやすいので参考までに。
集合演算
-
集合同士の重なる部分の集合についてはINTERSECTを用いて抽出する
-
表を縦につなげるときはUNION
-
UNIONとUNION ALLの違い
- UNIONは重複行を取り除くがUNION ALLは取り除かない
ビュー
ビューは基の表を結合したり演算処理したりして見やすい形の新たな仮想表として作成したもの。以下の構文で作成できる。CREATE VIEW ビュー名(列名1, 列名2, …) で作成可能。
ビューを作ることの目的は以下のようなところ。
- 見せたいデータだけを見せたい形でみせることができる
- 逆に、見せたくないデータは隠すことができる
- ユーザ毎に実行可能な処理を決めることができる
ビューからデータを追加・更新・削除する場合、あたかもテーブルのデータを操作するように記述することができるが、条件によっては追加・更新・削除できない場合がある。
追加・更新・削除できないビューの条件
| No. | 条件内容 |
|---|---|
| 条件1 | ビューの定義に集約関数を含む。(集約値なので直接変更できない) |
| 条件2 | ビューの定義にGROUP BY句、HAVING句を含む。(同上) |
| 条件3 | 複数の表を結合している。(複数表の結合なので直接変更はできない) |
| 条件4 | 副問合せで同一の表を参照している。(変更する行を特定できない) |
| 条件5 | DISTINCTを利用している。(変更する行を特定できない) |
| 条件6 | ビュー定義時にWITH READ ONLYの指定をしている。(読み取り専用) |
条件4以外は集約に関係していて、そりゃ元の行を特定できないよね!と納得感があると思いますが、条件4は見落としがち(自分だけ?)なので注意。
権限付与
[こちら](SQLで「権限の付与」を行う:「データベーススペシャリスト試験」戦略的学習のススメ(18) - @IT https://www.atmarkit.co.jp/ait/articles/1703/01/news191.html)を参照。あまり出題されないので思い切って捨てるのもあり。GRANT 権限1, 権限2、…ON テーブル のようにして権限付与できる。
以下の例では、ユーザ「USER1」に「発注テーブルの更新権限」と「発注テーブルの更新権限を他ユーザに与える権限」を同時に与えています。
GRANT UPDATE ON 発注 TO USER1 WITH GRANT OPTION
REVOKE文により、ユーザに与えた権限を取り消すことができます。
以下の例では、全てのユーザから「発注テーブルの参照権限、行追加権限、列削除権限、更新権限」を取り消しています。
REVOKE ALL PRIVILEGES ON 発注 FROM PUBLIC
ロール
[こちら](SQLで「ロール作成と付与」を行う (1/4):「データベーススペシャリスト試験」戦略的学習のススメ(19) - @IT https://www.atmarkit.co.jp/ait/articles/1703/01/news192.html)を参照。**CREATE ROLE文**でロールを作る。
作成したロールに権限を設定した後、ユーザにロールを与える。ロールの削除はDROP ROLE文で行う。
ロールに設定した権限を取り消すときはREVOKE文を使う。
以下にロールの作成~利用者に付与するまでの流れを示します。
(1)ロールの作成
最初にロールを作成します。以下の構文で、上記の図における「一般社員用ロール」を作成します。
CREATE ROLE 一般社員用ロール(2)ロールへの権限設定
次に、ロールに権限を設定します。構文は、ユーザに権限を与えるときと同じ構文を使います。
GRANT SELECT, UPDATE ON社員 TO 一般社員用ロール GRANT SELECT ON 社員評価 TO 一般社員用ロール(3)ユーザへのロール付与
最後に、ロールをユーザに付与します。
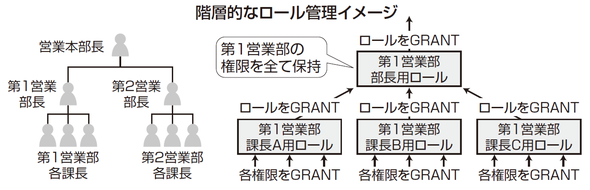
GRANT 一般社員用ロール TO 新入社員階層的なロール管理
下図左側の図のような階層的な権限管理を行う場合、右側のようにロールに対してロールを付与すると、運用が効率的になります。この例では、課長が持つ権限を変更する場合、課長用のロールを修正すれば、その修正内容が部長用のロールにも自動的に反映されます。
カーソル
ロール同様参照。
カーソルを利用した処理では、まずカーソル(最初に取り出すSELECT文)を定義し、取り出した表についてループ処理で1行ずつ条件を判定し、条件に応じてデータを更新することができます。
カーソルを利用した処理の全体像は以下の通りです。午前問題では「DECLARE カーソル名 CURSOR FOR」や「WHERE CURRENT OFカーソル名」の穴埋めをさせる問題が非常によく出題されます。
No. 処理 <1>カーソルの宣言 DECLARE カーソル名 CURSOR FOR (SELECT 文) <2>カーソルを開く OPEN カーソル名 <3>データの取得 FETCH NEXT FROM カーソル名 INTO 変数リスト <4>ループ処理の実行 WHILE 条件式 BEGIN ~処理内容~ WHERE CURRENT OF カーソル名 END <5>カーソルを閉じる CLOSE カーソル名

WAL
WALはWrite Ahead Log(ログ先行書き出し)の略。データベースの更新前にログをディスクに書き込む。
ちなみにcommit=更新後情報の実ファイルへの書き出しではない。commitはデータベースが「この処理が完了したことを保障する。」もので、実ファイルへの書き出しはまた別のタイミングで非同期(チェックポイント)で行われる。つまりcommit後は、メモリ上のみに更新データが存在する状態で、ディスクとメモリでデータに違いが発生している。(データがダーティな状態となる。)
そのタイミングで障害が発生した場合(電源が落ちた等)、実ファイルは更新前情報のみが残っており、メモリ上にあった更新後情報は消失してしまいます。
そこから更新後情報をログから取り出しロールフォワードすることにより、データベースのACID特性のひとつである耐久性が保障される。
ロック
専有ロック
文字通り、一人でロックを専有します。ロックされている間は、他の人が書き込むことはもちろん、読むこともできません。複数人による操作でデータの不整合を無くすために、データに書き込みをする場合は、専有ロックがかかります。
共有ロック
データを読むときに使用します。複数人が同時にロックをかけることができます(つまり、ロックを共有できるので、「共有ロック」と言います)。誰かがが共有ロック中に、他の人も読むことはできます(書き込みはできません)。
専有ロックと共有ロックの関係
他のTRからの共有ロック 他のTRからの専有ロック
共有ロック中 ◎ ×
専有ロック中 × ×
※TR=トランザクション
直列可能性
直列可能性とは、複数のトランザクションが同時実行される際にトランザクションが交互にどのような順序で実行されても、1つずつを順次処理したときと同じ結果になることを言います。
一般的なDBMSではロックを用いて直接可能性の確保を行います。それぞれのトランザクションが2相ロック方式、すなわちデータを読書きする前にはそのデータをロックする、必要なデータを全てロックした後のみアンロックができる、に従えば直列可能性が保証されます。したがって選択肢の各トランザクションが2相ロック方式に則ったものであるかが判断基準になります。
[こちら](平成24年春期問19 直列可能性を保証できるもの|データベーススペシャリスト.com https://www.db-siken.com/kakomon/24_haru/am2_19.html)参照
※2相ロック方式とは、すべてのトランザクションにおいて、読み書きに必要なすべてのロックが完了するまでアンロックを行わない方式のこと
トランザクション分離レベル
以下あがりがたぶんわかりやすい。
- データベース: トランザクション分離レベルについてまとめてみる|TechRacho(テックラッチョ)〜エンジニアの「?」を「!」に〜|BPS株式会社 https://techracho.bpsinc.jp/kotetsu75/2018_12_14/66410
- [RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita https://qiita.com/PruneMazui/items/4135fcf7621869726b4b
| ダーティ リード | ファジー/ノンリピータブル リード | ファントム リード | 対策例 | |
|---|---|---|---|---|
READ UNCOMMITTED |
発生する | 発生する | 発生する | |
READ COMMITTED |
発生する | 発生する | ダーティリードを防ぐため更新時には対象の行に専有ロックを行う | |
REPEATABLE READ |
発生する | ノンリピータブルリードを防ぐため参照時に対象の行に共有ロックを行う | ||
SERIALIZABLE |
ファントムリードを防ぐため参照時に対象のテーブルに共有ロックを行う |
トランザクションT1がデータを読み出し、T2がそのデータをロールバックすることなどにより、T1のREAD後に値が変えられてしまうダーティリードという現象が起こり得る。
これはT2が対象データに専有ロックを掛けることでT1の読み出しを防ぐことが出来る。
T1が値を読み込んだ後にT2がUPDATE&COMMITし、更にその後にT1が値を読み込んだ場合にT1の読み込んだ値が変わっているファジー/ノンリピータブルリードという現象が起こり得る。
これはT1が2回読み込む際に対象データに共有ロックを掛ければ防ぐことができる。
T1がREADした後に、TR2が何らかの値をINSERTしてコミットし、その後にTR1が読み込むと以前にはなかった行が挿入されている、ファントムリードという現象が起こり得る。
これはSERIALIZABLEにして完全に直列処理にすれば防ぐことができるが、処理速度の点から現実的でない。
デッドロック
複数のトランザクションが異なる更新順序でレコードを更新する際に、互いにロックの解放待ちとなることで発生する。
対策としては、複数のトランザクションが同じ順序でレコードを更新(ロックを獲得)する。
また、デッドロックが発生してしまった場合、一方のトランザクションをロールバックすることで解決する。
デッドロックの検出には、待ちグラフを使う。この待ちグラフに閉路(ループ)が発生したらデッドロックが発生したと判断する。
注意:2相ロックプロトコルでは、ロックをすべて行ってからアンロックを行うため、一見、デッドロックが発生しないように感じるが、本プロトコルだけではロックをかける順番を制御することはできないため、デッドロックが発生する可能性がある。
障害対応
ジョブシステムにおいて、メモリリークなどでジョブが失敗する場合、RDBMSによってロールバック(またはアボート)処理が行われ、異常終了することになる。ロールバック処理では、チェックポイント時にデータベースに対する更新が行われていれば、更新前ログによってデータベースを直前のコミット発行時点まで回復する。更新がなければ、単に、バッファ上の更新データを廃棄し、データベースをジョブの開始前に戻すだけとなる。ジョブのデータ処理量が増えると、更新前ログの量が増え、ロールバック処理の時間が長くなる。
インデックス
ユニーク/非ユニークインデックス
単純に一意性を保証するか否か。
単一列/複合列インデックス
その名のとおりなので説明略。
複合列インデックス作成の考慮点
CREATE INDEXで指定する索引列の最初の列は、最もユニーク性が高く、検索条件として使
用頻度が最も高い列を指定する
複合列索引に含まれる列は、検索条件で頻繁に一緒に使用される列の組合わせであること
複合列索引(列1、列2、列3)が、アクセス・パスの候補になりうる例
WHERE 列1=値 and 列2=値 and 列3=値
WHERE 列1=値 and 列2=値
WHERE 列1=値
複合列索引(列1、列2、列3)が、アクセス・パスの候補にならない例
WHERE 列2=値 and 列3=値
WHERE 列2=値
WHERE 列3=値
クラスター化/非クラスター化インデックス
こちらから抜粋
クラスター化インデックス
テーブルのデータをインデックスで指定した列の値で並べ替えて格納する。値が同じ場合は2つ目に指定した列の値で並び替えて格納する。データを並び替えて格納するため、1つのテーブルにはクラスター化インデックスは1つしか作成できない。最もよく使われるソート順の列や範囲検索を多用する列のインデックスに適している。
メリット
- データが並び替えられて保存されているため、インデックス列のソートが高速
- データが並び替えられているため、インデックス列の範囲検索 (between, <, > 演算)が高速
デメリット
- テーブル1つに対して1つしかクラスター化インデックスを作成できない
非クラスター化インデックス
テーブルのデータの並び替えは実施せず、インデックスで指定した列の値に対応するレコードへのポインタがインデックスファイルに格納される。範囲検索などを実行するケースが少なく。キーが一意の列のインデックスに適している。
メリット
- キーに対応するレコードの検索は高速
- 1つのテーブルに複数のインデックスを作成できる
デメリット
- 範囲検索(between, <, > 演算)ではクラスター化インデックスと比べると速度が遅い
- データが並び替えられて格納されていないため、インデックスの列でソートをした場合、クラスター化インデックスと比べると速度が遅い
作成手順
非クラスター化インデックスの作成手順はこちらの記事を参照
クラスタと低クラスタな索引
- 高クラスタな索引:キー値の順番と, キー値が指す行の物理的な並び順が一致しているか, 完全に一致していなくても, 隣接するキーが指す行が同じページに格納されている割合が高い
- 低クラスタな索引;キー値の順番と, キー値が指す行の物理的な並び順が一致している割合が低く, 行へのアクセスがランダムになる
インデックス設定が適しているケース
[こちら](データベース性能を向上させる「インデックス」を理解する:「データベーススペシャリスト試験」戦略的学習のススメ(26) - @IT https://www.atmarkit.co.jp/ait/articles/1703/01/news199.html)にインデックスの種類とともに整理されている。
| インデックス設定が適しているケース | 適している理由 |
|---|---|
| 検索対象表の行数が多い | インデックスによる性能向上が見込める |
| 検索対象表において、検索項目の属性値 (キー値)に重複・偏りが少ない | |
| 検索対象の表の更新が少ない | 検索対象表の更新速度低下が少ない |
| 検索対象の表の追加・削除が少ない | インデックスの性能低下が起きにくい |
クラスタ化インデックスとページの概念
こちら参照。クラスタ化インデックスはインデックスの並び順とレコードの並び順が一致するため、1ページ読み込めば近接するレコードを一気に読み込める(バッファヒットする)。そのため、シーケンシャルリードの場合にはI/Oが頻発せず、性能が良い。
ページはRDBMSがディスク領域を管理する際に基本となる単位で…
(一部省略)
テーブルを構成するレコードや,インデックスのエントリを複数格納します。RDBMSはメモリーとディスクの間の入出力をページ単位で管理し,キャッシュ・バッファへの入出力もページごとに行います。
(一部省略)
ページ・サイズの決定は,RDBMSのパフォーマンスに影響を与えます。扱うデータやアクセスの特性に合わせて決める必要があります。例えば,1回の入出力で扱う平均的なデータ量が少ない場合には,ページ・サイズが小さいほうが有利です。レコードを一つだけ読み込めばいいような場合でも,ページ全体を読み込むことになり無駄が多くなるからです。一方,1回の入出力で扱うデータ量が多い場合は,ページ・サイズを大きくしたほうが良いでしょう。ページ・サイズが小さいとディスクとの入出力の回数が増えて,効率が悪くなります。
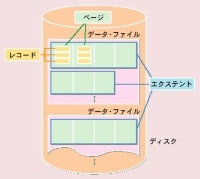
[こちら](DBパフォーマンスチューニングの基礎:インデックス入門 https://www.slideshare.net/simosako/rdb)もとてもわかりやすいので目をとおしておくとよい。
ちなみに、アクセスパスを決定する際にインデックスが使われないと表探索、使われると索引探索となる。必ずしも索引探索が早いとは限らず、行数が少なかったりカーディナリティが少なかったりする場合は表探索の方が優れいている場合もある。
インデックスの更新による性能劣化について
こちらのP4くらいまで見るとリーフページにフリースペースを設ける目的がわかりやすく書かれている。
インデックス自体もテーブルに格納されており、上述のページに格納される。ページに空き領域(余裕)をもたせておくと、インデックスの追加等が発生しても最構成のためのパフォーマンス劣化が抑えられる。
基本的なインデックス候補の検討
- ユニーク索引が必要か
- 外部キーに索引をつける
- 結合列になる可能性が高い列に索引があると、処理効率は良い
まずユニーク索引が必要かどうかを検討する。ユニーク性を維持しなければならない列が存在するのであれば、ユニーク索引が必要。外部キーがある場合、検索条件の結合列となる可能性が高いため、索引の候補になる。
インデックスの貼りすぎはデータ更新時のインデックス更新負荷を上げるため注意が必要。また、可変長列へのインデックスの設定や小さい表へのインデックスの設定は避けたほうが良い。インデックス用の表スペースは、I/Oの観点から、表データとは別の物理ディスクに配置する。
インデックス表をメモリー上にバッファすることで処理を早くすることもできる。
断片化
稼働後数カ月たち,データベースの応答性能が徐々に悪くなってきた | 日経クロステック(xTECH) https://xtech.nikkei.com/it/members/NOS/TROUBLE/20021115/1/
一部、引用。インデックスの再編成については上述したことと重複する。
データの断片化を起こさないようにするために,各ブロックに空き領域を用意する方法があります。例えばOracleでは,ブロックの空き領域の割合を設定する「PCTFREE」や,空き領域を再利用する際の割合を設定する「PCTUSED」などのパラメータ値によって空き領域を制御できます。アプリケーションの特性などを考慮すれば,空き領域を十分にとっておくことで,できるだけデータの断片化が起きないようにすることは可能です。しかし更新主体のシステムにおいて,データの断片化を完全に防ぐことはできないでしょう。
データの断片化やインデックスのバランスの崩れを解消するには,それらを再編成することです。テーブルやインデックスの再編成とは,ディスク上のデータを整然と並べ直す処理のことです。Oracleのテーブルの再編成は,EXPORT/IMPORTコマンドを使います。テーブルのデータをディスクから取り出し(EXPORT),テーブルを削除し,ディスク上に整然と並べ直します(IMPORT)。インデックスの再編成は,インデックスを削除して作り直す処理になります。オンライン処理中に再編成処理が実施できるRDBMS製品もありますが,多くのRDBMS製品ではシステムを停止して実施する必要があります。
統計情報取得
[こちら](基礎から理解するデータベースのしくみ(4) | 日経クロステック(xTECH) https://xtech.nikkei.com/it/article/COLUMN/20060111/227102/)参照
基本的には,ほとんどの場合にコスト・ベース・アプローチに基づくオプティマイザは最適な実行計画を選択してくれると考えてさほど問題はありません。ただ,コスト・ベースの基になるコストの計算は,テーブルのフィールドの値が均等に分布していると仮定して行います。そのため,データの分布に極端な偏りがある場合などは,実際には全件走査のほうが処理は早く終わるのに,インデックス検索を選択してしまうような場合もあり得ます。
コスト・ベース・アプローチを使って効率の良い実行計画を立てるには,定期的に統計情報を更新することが重要なポイントとなります。統計情報は,あくまでもそれを作成したときのデータベースの状態を反映しています。したがって,統計情報を作成した後にデータを大量に追加したり,更新したりするとデータベースの正確な内容を反映していないものになってしまいます。
適切なインデックスを定義しても,統計情報が不正確では,オプティマイザは最適な実行計画を選択してくれません。例えば,実際はレコードが100万件あったとしても,レコード件数100件の時点で統計情報の作成/更新を行ったままだと,オプティマイザはレコード件数が100件であることを前提に実行計画を決定してします。つまり,本来ならインデックスを使ってアクセスしたほうが高速なのに全表走査を選択し,100万件のレコードを順にアクセスしてしまう,といったことになるわけです。Oracleの場合であれば,ANALYZEコマンドやDBMS_STATSパッケージなどを使って定期的に統計情報を更新することを心がけてください。
結合アルゴリズムを使い分ける
ここまで述べてきたことからおわかりのように,オプティマイザによる最適化は万能ではありません。データの分布が偏っていたり統計情報が不正確だったり,といったさまざまな原因で,最適でないアクセス・パスを選択してしまい,期待通りのパフォーマンスが出ないこともあります。
こうしたことによるパフォーマンスの低下を防ぐには,明示的にヒントをつけるなどプログラマがSQL文の書き方を工夫する必要があります。以下では,そうした点の中から,特に速度に影響が出やすいものを取り上げましょう。
まずは,テーブルを結合(JOIN)するアルゴリズムについてです。SQL文の処理には,大きく分けて,選択,射影,結合の3種類がありますが,最も負荷が大きいのがこの結合処理です。結合処理の最適化の優劣が,SQL文の高速化のカギを握っている,といっても過言ではありません。
RDBMSがテーブルを結合する際に利用するアルゴリズムには,「ネスト・ループ結合」「マージ結合」「ハッシュ結合」の三つがあげられます。
バックアップ&リストア手法
ホットバックアップとコールドバックアップ
バックアップを実行する際のシステムの状態に着目して2つに分けられる。
ホットバックアップ
- 無停止でバックアップを取得可能
- トランザクションの仕組みを利用してバックアップを取得
- ロックを利用してバックアップを取得
- OSやHWのスナップショットを利用してバックアップを取得
- その他、独自の方法でバックアップを取得
コールドバックアップ
- 停止状態でバックアップを取得
- ディレクトリ以下のディレクトリとファイルをすべてコピー
論理バックアップと物理バックアップ
論理バックアップはテーブルデータだけを抜くイメージ、物理バックアップはDBファイル自体をがっつり抜くイメージ
論理バックアップ
- データベースからデータだけを抜き出してバックアップ
- 利点
- バックアップファイルを編集可能
- 他のDBMSへ移植が容易
- 欠点
- 物理バックアップに比べサイズが大きくなる
- バックアップ、リストアに時間を要する(バイナリーテキスト変換が入るため)
物理バックアップ
- 物理的なファイルのバックアップ
- 利点
- 最小限のサイズで取得可能
- バックアップ、リストアの速度が早い
- 欠点
- バックアップ、リストアの単位はツール次第
- 異機種間、バージョン間で互換性がない場合が多々ある
増分バックアップと差分バックアップ
| バックアップの種類 | 説明 |
|---|---|
| 増分バックアップ | その日、増加した分だけ取得 |
| 差分バックアップ | 毎日、フルバックアップとの差分を取得 |
分散データベース
2相コミットとは、
-
調停者がコミット要求を受付け、それを他のDBMSに投げる(第1相)
-
他のDBMSからコミットOKが帰ってきたら、調停者は改めてコミット指示を投げる(第2相)
-
DBMSが第1相のコミット要求に返答してから第2相のコミット指示が来るまでの間は**コミットもロールバックもできない状態(セキュア状態)**となる
設計のテクニック
[こちら](DB論理設計のノウハウ - Qiita https://qiita.com/kiyodori/items/5083ad8bbfc232d01827#%E7%89%A9%E7%90%86%E8%A8%AD%E8%A8%88)参照
多対多の対処方法
- 多対多が問題となる理由:両者のエンティティが共通のキーとなる列を保持していないため、両エンティティを結合した情報を得ることができないため
- 解決方法:関連エンティティを作成することで、二つの1対多の関連に分解する
パフォーマンス系
正規化のメリット・デメリット
- メリット:データの整合性を保持できる
- デメリット:検索時にテーブルの結合が必要なため、パフォーマンスが低下する
非正規化とパフォーマンス
大きく次の二種類の非正規化によって検索を高速化することができる
- サマリーデータを冗長に保持する
- 選択条件を冗長に保持する
冗長性とパフォーマンスのトレードオフ
非正規は検索を高速化する一方で、更新不整合のリスクを増やす他、下記のようなリスクが増える
- 検索のパフォーマンスを向上させるものの、更新のパフォーマンスを低下させる
- データのリアルタイム性を低下させる
- 後続の工程で設計変更すると、手戻りが大きい
非正規化はこのように多くのリスクがあるため、パフォーマンス向上のすべての戦略をやり尽くした後に、様々なトレードオフを考慮した上で、最終手段として使用すること
インデックスの設計
B-treeインデックスを例に、インデックスの設計方針についてみていきます。
- 大規模なテーブルに対して作成する
- レコード数が1万件以下など、データ量が少ない場合はインデックスの効果は低い
- カーディナリティの高い列に作成する
- カーディナリティとは、特定の列の値が、どのくらいの種類を多さを持つかということを表す概念
- カーディナリティが高い列ほどインデックスの効果が高い
- ただし、値が平均的に分散しているのがベスト
- SQL文でWHERE句の選択条件、または結合条件に使用されている列に作成する
B-treeインデックスに対するその他の注意事項
- 主キーおよび一意制約の列にはインデックスは作成不要
- B-treeインデックスは更新性能を劣化させる
- 定期的にインデックスの再構築を行うことが望ましい
インデックスの断片化 ※再編成と再構築の差異に注意
データの更新を繰り返すうちに断片化がおこりパフォーマンスが低下する。解消するにはインデックスの再編成と再構築という2つの手法がある。
インデックスの再編成は、既存の領域を使ってデータを並べ替えて断片化を解消する処理を行う。他方の再構築は、新規領域を使ってデータを並べ替える処理を行う。一般的に、再編成より再構築の方が断片化を解消できる。目安としては、断片化率が30%以上だったならば再構築を、それ以下だったならば再編成が推奨される。
統計情報の設計
一般的にエンジニアがSQLの実行計画立案に直接関与することはなく、統計情報を介した間接的な関わり方になります。
そのため、統計情報の設計において考慮すべきは、主に次の二点になります。
- 統計情報収集のタイミング
- オプティマイザが正しい道を選べるよう、データが大きく更新 (INSERT / UPDATE / DELETE) された後、なるべく早く
- 一方で、統計情報収集はリソースを消費するため、システム利用者の少ない夜間帯に実施する
- 統計情報収集の対象
- 大きな更新のあったテーブル (およびインデックス)
論理設計のバッドノウハウ
バッドノウハウとは言えないものの、開発や運用に支障をきたすこともあるノウハウについて
代理キー
主キーが決められないパターンが存在する
パターン1. そもそも入力データに主キーにできるような一意キーが存在しない
パターン2. 一意キーはあるが、サイクリックに使いまわされる
パターン3. 一意キーはあるが、途中です対象が変化する
このような問題を解決する手段として、代理キーが利用される
- 代理キーとは、入力データに最初から存在しているキーの代理として新たに追加するキー
- 原則としては、代理キーによる解決は避けて、自然キーによる解決を図るべき
- 代理キーが論理的には不要なキーで、論理モデルをわかりにくくしてしまうため
自然キーだけで解決するためには、次のような方法を取る
パターン1. 業務仕様を調整するか、DBに投入される前にアプリケーションでデータが一意になるように整形する
パターン2. 履歴管理のための時間を表す列 (タイムスタンプとインターバル) を追加する
パターン3. パターン2と同じ
それでも代理キーを使わざる得ない場合、一意性と連続性が保証されるように、オートナンバリングを用いて実装する
列持ちテーブル
配列を模倣するために、列持ちテーブル (繰り返し項目テーブル) を使用しているケースがあります。
- 拡張性の高い行持ちテーブルでデータを保持することが基本
- パフォーマンス上の問題でどうしても列持ちテーブルが必要になった場合に、列持ちテーブルを作成する
アドホック (場当たり的)な集計キー
アドホックな集計キーを追加することで、集計を簡単にできる一方、追加の度にテーブルが巨大になり、パフォーマンスが悪化します。そこで以下のような対策を取る
-
キーを別テーブルに分離する
-
ビューを使う
-
GROUP BY句の中でアドホックなキーを作成する
多段ビュー
ビューは有効な道具である一方、短所として、パフォーマンスへ悪影響を与えることと、濫用するとかえって設計と実装を複雑なものにしてしまうことが挙げらる
- ビューにSQLからアクセスが行われたとき、ビュー定義のSELECT文を実行して、オリジナルのテーブルにアクセスしている
- そのため、多段ビューを構築すると、パフォーマンスが悪化し、かつテーブルとビューの依存関係をわかりにくくするため、仕様が複雑になり管理が困難になる
- ビューの使用は、原則として一段にとどめておく
データクレンジングの重要性
業務で利用されていたデータをデータベースに登録できる状態にする「データクレンジング」を行うことで、適切にデータを保存することができる
代表的なデータクレンジングは以下の通り
- 一意キーの特定
- 一意キーの確定を疎かにすると、不適切なキーを生み出す
- 名寄せ
- 名寄せをサボると、ダブルマスタを生み出す
こうきたらこう答える
[こちら](情報処理試験まとめ/データベーススペシャリスト試験の勉強法まとめ/午後1&2対策 - まとめwiki - アットウィキ https://w.atwiki.jp/matowiki/pages/108.html#id_9c70c436)参照
| パターン | 解き方 |
|---|---|
| この帳票を出力するためになぜ外部結合が必要か? | 「外部結合を使わないと結合元の一方のテーブルのみにある行が出力されない」「それにより出力結果のレイアウトがどうなる」旨の文を本文の具体例を使って構成。 |
| この帳票を出すのになぜCOALESCEを使用するのか? | 「ある結果がNULL だと出力結果のレイアウトが○○になるため、NULL でなく0 として扱いたい」旨の文を本文の具体例を使って構成。 |
| 内部結合の結果と、IN句やEXISTS句を利用した同様の処理結果で、なぜ件数が異なるのか? | 内部結合ではDISTINCTを用いない限り重複行を複数件カウントするが、IN句やEXISTS句では重複行を1 件としてカウントするため。 (参考) DISTINCTはNULLも1行として集約する COUNTはNULLをカウントしない |
| [スーパータイプ/サブタイプの問題において]○○は△△にも××にも属することがある。この場合、現状の設計では表現できない。 | スーパータイプにサブタイプ数分のフラグ列を作り、両方に属するものについては両方のフラグを立てる。 |
| なぜビューを使うのか | ①複雑なSQLを何度も書く必要がない(ビューは毎回演算を行うので、最新の情報を反映させることが可能。だがそれではパフォーマンスが気になる場合は、データベースにデータを格納した体現ビューを作成することもできる[ただし、予めデータを格納するので、更新頻度等によってはデータ不整合が起こる]) ②セキュリティを確保するため |
| 更新可能なビュー | 次の機能を使っていないビューは更新可能(次の機能で行を集約すると、ビューで更新した行が基底表のどの行に該当するか追えなくなる) ①GROUPBY ②HAVING句 計算列 ④集約関数 ⑤DISTINCT句 |
| なぜストアドプロシージャーを使うのか | 処理の高速化と通信量の削減のため |
| なぜ正規化を行うのか | 整合性を担保し、更新時異常を排除するため |
| 所属や売上明細など、当時の記録が追えない | 履歴管理をするために配属開始日や売上発生日時を主キーとしてもたせる、もしくは(正規化を崩すことになるが)当時の情報を明細行などにもたせる(例えば当時の単価など)。 |
| 結合が多いSQLのパフォーマンスを向上させたい | 複数回の結合により属性を得る必要があるためにコストが高くなっている。そのため、導出属性をもたせてやることで結合コストを下げることができる。デメリットとしては定期的に更新しないと導出属性の情報が古くなる。 |
| スーパータイプ/サブタイプの関係にあるテーブルにおいて、サブタイプを共存的サブタイプにしたい | スーパータイプに各サブタイプのフラグを持てるよう属性を追加する。 |
| 多対多のリレーションができてしまう | 間に関連エンティティを追加し、それぞれのキーを関連エンティティに持たせることで1対多の関係にする。 |
| DBのデータ暗号化によるセキュリティ向上とのトレードオフ | 暗号化したデータの索引が機能しなくなり、検索等の性能が劣化する。また、あいまい検索を行う場合、データが暗号化されたままでは検索ができない(完全一致ならハッシュ同士の比較で検索可能)。 |
| 出荷業務について、複数の受注であっても、同じ納品予定年月日に、同じ送り先の場合は1つにまとめて出荷する。また、1つの受注の受注明細が別の出荷となる場合がある(在庫が不足する場合など)。 | この場合、出荷と受注は多対多になる。そして出荷と出荷明細は1対多、受注と受注明細も1対多になり、出荷明細行と受注明細行が1対1で紐づくことになる。 複数の受注について、同日の出荷をまとめるような処理をする場合の出荷テーブルを答えさせるような問題においては、一度、出荷・出荷明細テーブルを1つのテーブルに非正規化し、そこから、テーブルを再度、組み立てると良い。 |
| 区画と区画内探索 | この問題が出題された場合、基本的に対象となるテーブルはレコードの発生順に並んでおり、まずは区画として年月で区切ることが多い。区画を年月で区切り、それがSQLの探索条件となる場合、区画を特定できるが、探索条件とならない場合は区画を特定できない。また、区画を特定した後、索引が区分内のクラスタ索引となる場合、連続するページにアクセスできることになり効率的な探索となる。 |
| ○○開始年月のような列が主キーの一部となっていないことによる不具合 | 該当列を保持するテーブルに対し、どのような不具合が生じるか、という問題がよく出題されるが、この場合、多くの場合で履歴が保持されていないことによる当時のレコードを追えないことに起因する。 |
| 最初の表が○○明細など網羅的な表で、続く結合表が結合列が歯抜けになるような疎な表のSQLのJOINについて問われた場合 | 大抵、LEFT JOINになる。これは結合の左表が網羅的であるために、情報の取りこぼしがなくなるようなイメージをしてもらえれば良い。 |
| 2つの○○JOIN(○○には結合の種類が入る)をUNIONでつなぐ場合 | 大抵、○○にはINNERが入る。なぜかというと、それぞれJOINの内部結合で両方の表にある行だけを残す(抜け落ちる行がある)が、これをUNIONで補うことができるから(イメージ的にはA∪Bのような和集合)。 |
| APの暗号化・復号化関数でDBのデータを暗号化・復号化ている場合のセキュリティについて | DBのデータを単体で盗んでも暗号化されたデータは復号できない。復号するには復号関数名と鍵(通常はAES等の共通鍵なので暗号鍵と復号鍵は同一)を盗む必要がある。これには、メモリダンプや通信経路のパケット盗難等の技術が必要である。 |
| 暗号化されたデータの検索性能について | データの暗号化を行うと、暗号化されたデータについてインデックスが貼られることになり、暗号化前のデータを対象にした検索においてインデックスは使用されない。条件の完全一致検索の場合には、条件を暗号化することによって暗号化されたデータ同士を比較することができるためインデックスが使われるが、LIKE等を使った部分一致の場合には、一度、復号化しなければならないため性能が劣化する。 上行のようにAPで暗号化・復号化を行う場合、SQLによる対話的なデータ検索を行えなくなり、APを介して検索する必要がある。 |
| 入出庫に係る業務で指図と実績は大概、1対1の関係となる | 例えば、製品出庫指図が製品単位であり、製品出庫実績も1つの倉庫から出荷される場合などが該当する。(実績-実績も1対1になることが多く感じる。例えば、生産された製品が毎回、同じ倉庫に入庫される場合、製品入庫実績と生産実績は1対1になる。) |
| 冗長なリレーションシップ | 一見、エンティティ間にリレーションシップが必要と思われる記述があったとしても、そのリレーションの対象となるエンティティが、既存のリレーションをたどって辿り着くのであれば、それは冗長なリレーションシップとなり不要である(結合を繰り返せば必要な属性は得られるから。要するに、経路(リレーション)がループしているようなE-R図は正しくない。)。 |
| 排他的リレーションシップ(アーク) | 本来、1つのエンティティを2つのサブタイプに分離し、それぞれのサブタイプに向けて異なるカーディナリティのリレーションを設定しなければならない場合があるが、本試験においてはエンティティの追加が許可されていない場合がある。その場合、2つのサブタイプへ分離はせず、もともとあった1つのエンティティに2つのリレーションが発生する場合がある。これを排他的リレーションシップ(アーク)と呼び、望ましい設計ではないことを認識しておく必要がある。 |
| 「同時期には一つだけ登録できる」 | 左記の記述があった場合、例えば社員の所属などは所属開始日等も含めて主キーとし、履歴管理されると考えて良い。 |
| 予約システム等で予約する際に予約行をInsertすると失敗する | ダブルブッキングを防ぐために主キーの重複で登録できないよう制御しているため。 |
| スループットが低下する | コミットしないことにより、トランザクションAが更新時の専有ロックを保持しつづけ、他のトランザクションが専有ロックの解放まちになっているパターンなどがある。 |
| Aテーブルを1行読むたびにBテーブルを1行更新するような場合に、Aテーブルの読み込み順がBテーブルの索引順でない読み込みとなる場合のページ数はどうなるか | Bテーブルの探索は読み込んだページ内で連続して読み込むことができない(バッファヒットせずにランダムアクセスとなる)ため、Aテーブルの読み込み行数=Bテーブルのページリード数となる。 |
| 肥大化するテーブルにおいて、途中でコミットを発行せずにバッチ処理を続け、最後に1度だけコミットを発行する作りとなっていた場合に途中で失敗した場合どうなるか | ロールバック処理(アボート処理)に要する時間が日に日に長くなる。 |
解答時のテクニック 午後Ⅱ
設問の構成を最初に調べる
問題の構成は、おおむね最初に企業の業種や組織、業務プロセス、システムのテーブル構造を文章で説明し、その後に業務の改善要望が記述されているパターンが多い。ほとんどの問題で「現状の業務やシステムの説明→新しい要望の説明」となっていて区切りがつけられている。設問も現状の業務の解説と改善要望は分けられているので、「現状の業務」の説明まで読んだらその部分をまず解答して現状のテーブル構造を確定してしまおう。それから新しい要望に取りかかったほうが効率がいい。
問題文を読みながら会社の仕組み、ビジネスロジックなどを簡単な図でまとめる
午後1にも午後2にも言えることだが、その会社の組織やビジネスロジックを理解することはとても重要だ。そのため問題文を読みながらその組織の組織図、伝票の作られ方、商品の配送方法などを簡単にメモしながら問題文を読んでいくようにすると、すんなり組織を覚えてることができる。
問題文とER図、関係スキーマなどの図表を見比べて確認する
データベーススペシャリストの午後2問題は業務プロセスを文章で説明し、そしてテーブル構造を答えさせようとしている。逆に言えばテーブル構造を文章で説明していることになる。
説明はおおむねテーブルごとに、それぞれのテーブルについて解説している。なので、もし問題文に関係スキーマ(テーブル)、概念データモデル(ER図)が図や表として記述されているようなら、問題文とそれらの図や表をページをめくり行き来し、問題文中のテーブルの説明と図や表中に記述されているテーブルを比較し記述内容を確認するようにする。
例えば「企業には複数の支社があり支社コードで識別される」などという説明があれば、おそらく支社テーブルが存在し支社コードが主キーとなっているであろうことがわかる。そしたら関係スキーマやER図を調べて支社テーブルを探して、テーブルがあることの確認と、支社コードが候補キーまたし主キーとして存在していることを確認する。もし支社テーブルに該当するテーブルがなかったり、そのテーブルに支社コード属性がない場合、そのテーブルや属性を答えさせる設問が出る可能性が高い。
問題文へのマーキング
上記のように問題文と関係スキーマやER図を行き来し、一つ一つ確認していくとおかしな記述があったり、該当するテーブルがなかったりする場合がある。
テーブルがない場合はひょっとしたら虫食い問題になっている可能性があるので、その部分は非常に重要だ。とりあえず疑問に思いながらも問題文を読み進むわけだが、読み進めるうちに忘れてしまう可能性があるので疑問を感じた部分に下線を引いて欄外に「はてなマーク」を書いておこう。可能なら欄外に「支社テーブルがあるはず?」「主キーとして支社コードがない?」などとメモしておく。こうすると、あとで簡単に見直すことができる。
また読み進めるとロジック的におかしいなと思われる部分を見つけることもある。例えば将来的に商品の値段を変更する可能性があるのに、その商品の値段の履歴を残すようなテーブル構造になっていないような場合である。これだと商品の値段を変更すると過去の売上げの値段すべてが変更されて金額がおかしくなってしまう。こういうものを見かけたときも下線を引いて「価格変更履歴テーブルは?」などと記述しておく。
復習方法
情報処理教科書の解説を読み、具体的に回答するテクニックを学ぶこと。情報 処理教科書には、解答を導き出す方法が記述されているので、もういちど最初から解答するようなイメージで問題文と解説を見比べて、自分はなぜその問題文のヒントに気がつかなかったのか、なぜそのような手法などに気がつかなかったのか等を学んでいくようにしよう。
解答パターン 午後1&午後2
問題文を読んでいて疑問に思うパターン
問題文を読んでいると、これはどうするの?こうでなければおかしいと疑問に感じることがある。その多くは下記のパターンのいずれかに当てはまることが多いので、これらのパターンを覚えておくと何を答えさせようとしているかを理解しやすくなる。
問題文に記述されている属性やテーブルがない
よくあるパターンのNo1。問題文とER図や関係スキーマを確認し、該当するテーブルや属性があるかどうかを探す。無ければ虫食い問題になっている可能性が高い。
履歴が残せない
例えば商品マスタに商品金額が記述されているが、売上げ伝票(売上げ明細)に個別の商品金額を記録できないようなパターン。この場合、商品マスタの金額を変更してしまうと過去に売り上げた伝票の商品金額もすべて変更されてしまうことになるので問題になる。売上げ時の金額を残せないというのは問題にされる可能性がある。
正規化されていない
正規化されていないと同じ情報を重複して登録してしまう可能性がでてくる。例えば商品を販売するたびに売上げ伝票に顧客の名前、住所、電話番号を登録するような場合だ。この場合、顧客の電話番号が変わったりしたとき、過去の売上げ時に入力された顧客情報と整合性がとれなくなるので問題になる。
属性の変更を考慮していない
営業部員の売上げの成績は保存されるが、売上げ時の営業部員が所属していた支社の情報が記録されないパターン。例えば従業員マスタで営業部員と所属する支社の紐付けがされているとする。そうすれば従業員と支社の紐付けがされているので、営業部員の売上げ成績から支社別の売上げ成績も導きだすことができる。
しかし会社には異動が付きもの。もし従業員マスタで従業員が異動し現在の所属先の支社に変更されてしまったら、その従業員の過去の売上げも新しい支社の売上げとして計算されてしまうことになる。このように属性が変更されることを考慮しないと、あとから集計したときに値が変化してしまうことがあるので注意が必要である。
従業員と支社の関係以外にも、商品と商品価格、商品と商品の仕入れ先など、その時々によって変更する可能性があるものをマスタ的に登録していると不整合が生じる可能性があるので、そのあたりを見たときに疑問を感じてチェックしておくことが重要。
わざと冗長に記録させるパターン
集計などを早く行うために売上げ伝票に売上げ詳細の合計金額などを記録させるパターン。通常、売上げ伝票ごとの金額は売上げ詳細テーブルに記載されている商品金額×販売数の合計を計算して求めるが、詳細が多くなると計算に時間がかかってしまう場合がある。この場合、売上伝票に合計金額を保存しておけば売上げ詳細テーブルの演算を行わなくて済むので計算が早く済む。しかしご発注などのため売上げ詳細テーブルの金額や商品販売数が修正されると合計金額が変わってしまう。そうなると売上げ伝票テーブルに記録した合計金額と数字のズレがでてしまうが、これを考慮したロジックになっていないと問題が発生してしまう。問題文中にそれら整合性をどうするかの説明がないと疑問に感じなければならないパターンだ。
テーブルの新規作成パターン
午後2の問題を解いていると、ビジネスロジックの改良に伴い、既存のテーブルに新たにテーブルを追加して設計を変更させようとする設問がある。テーブルはだいたい以下のような理由で新たに追加される可能性が高い。このパターンを理解しておくと何を答えさせようとしている問題なのか想像しやすくなるので覚えておくと良い。
他のデータを束ねる
新たに他のデータをまとめるためのテーブルを新規作成するパターン。例えばカラオケボックスで、通常は一部屋に対して1枚の売上伝票で別々に精算しなければならないものを、グループで複数の部屋を借りたときにまとめて支払いたいというようなパターンだ。飲食店で席が別々になってしまったグループの複数の伝票をまとめて支払いたいなどというようなパターンにも当てはまる。
この場合には、例えば下記の画像のように新しく「まとめテーブル」などを新規作成し、その「まとめ番号」などを売上げ伝票テーブルに新たに作成したまとめ番号属性に保存することで実現する。こうすると、これまで客室ごとに一枚の伝票だったものが一つのまとめ番号で紐付けされるので複数の部屋でもまとめて支払いが可能になる。
連関テーブル
業務プロセスの変更で、テーブルのリレーションシップが1対多から、多対多になってしまいそれを表現するために連関テーブルを新規作成するパターン。例えば支社と従業員の関係で、これまで従業員は一つの支社にしか所属していなかったのに、業務プロセス等の変更で従業員が複数の支社に所属するように変更され、支社-従業員が1対多の関係だったものが多対多になってしまったパターンなどが該当する。
この場合、多対多の関係を表現するために連関テーフルを新規で作成することで対応する。
マスタテーブルとして追加する
業務プロセスの変更で、新たなマスタテーブルを追加しなければならなくなるパターン。例えば飲食店でこれまで「商品」だけだったものを、料理、ドリンク、セット定食などというように商品カテゴリで商品を分ける必要があり、商品区分マスタなどとして新たなテーブルを作成するパターンなどだ。
商品区分マスタに区分コード、区分名などの属性を作成し、商品テーブルに新たに商品区分属性を作成して区分コードを保存することで対応する。
サブタイプの追加
業務プロセスの変更で、新たなサブタイプを作成するパターン。例えば食料品メーカで使用する野菜に関して、これまで通常の野菜と有機野菜のみの区別だったものに、輸入野菜という新たな分類となる野菜を使用するために、輸入野菜を管理する新たな属性を追加する必要になるパターンなどだ。
この他にも、製造業で自社部品だけでなく他社製造部品も利用するようになり、部品を自社と他社で別の属性で管理する必要になったというパターンや、飲食店で同じレシピの料理だけどセット商品として提供する場合と単品で提供する場合によって異なる属性で管理したいというパターンなどがある。
主に「同じ商品」なんだけど、製造元が異なったり、提供先や提供方法が異なるため、その場合だけ別々に管理したいというような場合に新たなサブタイプとしてテーブルを新規追加することが必要になるパターンである。
テーブルへのフィールド新規追加パターン
午後2の問題を解いていると、ビジネスロジックの改良に伴い、既存のテーブルに新たにフィールドを追加して設計を変更させようとする設問がある。フィールドはだいたい以下のような理由で新たに追加される可能性が高い。このパターンを理解しておくと何を答えさせようとしている問題なのか想像しやすくなるので覚えておくと良い。
行の属性を表現するための属性の追加
商品マスタなどで、その商品に関する属性を追加させるパターン。例えば飲食店で提供する料理を飲み物と料理に区別して売上げを集計したいとか、ホテルの部屋を喫煙室と禁煙室に区別して予約を受け付けたいというパターンだ。
この場合、料理マスタに「商品区分」などの属性を追加したり、ホテルの部屋を禁煙と喫煙に区別するために部屋マスタに「喫煙区分」を追加するなどが該当する。
集計行を追加するための属性追加
部品マスタなどで、その部品の在庫数を保存する属性を追加させるパターン。例えば製造メーカでこれまでは半製品の在庫を記録していなかったが業務効率改善のために半製品の在庫数を保存する必要がでてきたなどのパターンだ。
この場合、半製品マスタに「在庫数」などの属性を追加するなどが該当する。
履歴を残すための属性追加
商品マスタなどで、その商品の価格の履歴を保存する属性を追加させるパターン。例えば製造メーカでこれまで商品の値段は同じであったがこれからは頻繁に価格を反映させたいので履歴を残しておく必要があるとか、飲食店で一定期間だけ料理を特別価格として安く販売したいので過去の販売金額の履歴を残したいとか、従業員の過去の所属部署を履歴として残しておきたいというパターンだ。
この場合、商品マスタに「販売開始日」などの属性を追加したり、料理マスタに「販売開始日」などの属性を追加したり、社員マスタに「配属日」などの属性を追加することなどが該当する。
このパターンは、これまで普通だったただの縦横の表に、突然時系列という時間の流れという概念を取り入れなければならないので発想の転換が必要になり難易度が高い。
このパターンでは例えば商品価格では、商品の価格を変更するたびに販売開始日を設定して新たに行を作ることになる。従って、例えば{商品コード、販売開始日}が候補キーになる。販売開始日を設定することで、例えば下記の例だと商品コード0001の製品は、2015年01月01日から2015年01月31日まで300円で販売していたことがわかるということになる。
またこのパターンでは、将来に対する価格変更の予約のようなことも可能になる。例えば、2015年2月1日から新価格で販売することを事前登録しておくということも可能。
正規化に関する解答パターン
正規化に関する解答パターンも暗記しておくことが望ましい。これらは必ず出題されるので確実に答えられるようにしておこう。
詳細については情報処理教科書 データベーススペシャリストに記述されているので、その説明を読んで理解することが必要。以下は暗記用のチェックシート代わりに。
第一正規形でない理由(正規化されていない理由)
- 属性○○は属性△△の集合であり単一値ではないため
- 属性○○が繰り返し項目であり単一値ではないため
第一正規形の理由
- すべての属性が単一値で、候補キーA、Bの一部であるBに非キー属性のCが部分関数従属するため
- 非キー属性であるCが候補キーの一部であるBに関数従属し、候補キーに完全関数従属していないから
- 非キー属性であるCが候補キーの部分集合{A、B}に関数従属し、候補キーに完全関数従属していないから
第二正規形の理由
- すべての属性が単一値で、候補キーからの部分関数従属がなく、推移的関数従属性A→B→Cがあるため
第三正規形の理由
- すべての属性が単一値で、候補キーからの部分関数従属がなく、候補キーからの推移的関数従属性もないため
ボイスコッド正規形の理由
- すべての属性が単一値で、すべての関数従属性が、自明であるか、候補キーのみを決定項として与えられている
第四正規形の理由
- すべての属性が単一値で、すべての多値従属性が、自明であるか、候補キーのみを決定項として与えられている
第五正規形の理由
- すべての属性が単一値で、すべての結合従属性が、自明であるか、候補キーのみを決定項として与えられている
正規化されていないと発生する可能性のある問題
- ○○(例:商品)を事前にマスタとして登録できない
- 属性○○が冗長になる
- 属性○○を重複して登録するので不整合が生じる
- 属性○○が冗長であるため、これらを同時に修正しないと整合性が失われる
- 属性○○の情報が特定の一行にしか存在しない場合、その行を削除するとその属性の情報が永遠に失われる
結合に関する解答パターン
集計時に外部結合する理由
- すべての○○(例:店舗)に対して△△(例:売上げ)が存在するとは限らないが、すべての○○ごとに集計して結果を出力するから
間違い易い午前Ⅱ問題
-
カーソルを用いたUPDATE文
-
UPDATE 表名 SET 代入コンマリスト WHERE CURRENT OF カーソル名
-
-
再現率(網羅率)と精度(適合率)
- 再現率=検索結果のデータのうち、質問に適合する件数(b)/蓄積されたすべてのデータのうち、質問に適合する件数(a)
- 精度=検索結果のデータのうち、質問に適合する件数(b)/検索結果のデータの件数(c)
-
BとCの和集合がAに関数従属するということは、A→B∪Cであり、自明の関数従属性(B∪C→B、B∪C→C)があるため、A→(B∪C)→B、A→(B∪C)→Cが成りたつ。つまり、BとCはそれぞれAに関数従属する。
-
代用キー(surrogate key)と代理キー(alternate key)
- 複合キーなど、主キーを構成するキーが多くなり扱いづらくなった場合などに連番などを振り、それを主キーにすることがある。この新たに設けた主キーを代用のキー(surrogate key)という。
- また、新たに設けた代用のキーによってもともとあった複合キー(候補キー)は代理キー(alternate key)となる。代理キーとは候補キーのうち、主キーとならなかったキーのことである。
-
ANSI3層スキーマアーキテクチャ
- 概念スキーマ
- 対象となる外界の事象を抽象化したもので、内部スキーマと外部スキーマの間に位置し、モデリングの基本となるものである。関係データベースでは、リレーション(表)が該当する。
- 内部スキーマ
- 概念スキーマをコンピュータの2次記憶(ディスク)上に記憶させるための格納構造の記述である。関係データベース管理システムでは、B木ファイルなどが該当する。
- 外部スキーマ
- 概念スキーマを利用する側、すなわち個々のプログラムあるいはユーザからの視点でデータベースを記述したもの。ネットワークモデルでは、これをサブスキーマと呼んでいる。関係データベースでは、ビューが該当する。
- 概念スキーマ
-
結合について
- タプルを足し合わせるために、比較演算子(=、>、<など)を使用するが、これをΘ(シータ)結合という。
- Θ結合のうち、=に限定したものを等結合という。
- 等結合のうち、重複する片方を射影(演算)によって取り除いたものが自然結合である。
-
データモデル
- 概念データモデルは対象世界の情報構造を抽象化して表現したものであり、代表的な表現方法としてERモデルがある。DBMSに依存しない表現であることが特徴。
-
ロールフォワードでは、データベースのシステム障害時に主記憶バッファに対する更新内容をデータベースに反映させるため、ログとしてページの更新後情報を取得する。なお、データベースの障害は次の3つに分けられる。
- トランザクション障害
- トランザクションがデータ操作の誤りなどで、異常終了すること。更新が行われている場合、ロールバックの対象となる。
- システム障害
- コンピュータの電源故障やOS/DBMSのバグなどでシステム全体が止まること。主記憶の内容は失われるが、データベースの媒体自体は破壊されていない。
- 媒体障害
- データベースファイル自体が破壊されていて、データが使用できなくなる状態のこと。
- トランザクション障害
-
導出表と導出属性を区別すること。導出表はビューのことだと思ってよい。
- 導出属性は、算術演算によって得られた属性の組である。
- 逆(非)正規化は、実表を冗長にして利用しやすくする。
-
WALプロトコルとは、データベースのコミット時に必ずログの書き込みをディスクに行うことにより、何らかの障害が発生した場合でもログファイルからデータベースを復旧できるようにする仕組み。WALプロトコルを採用しているデータベースでは、障害時にコミット済みだがデータベースに反映されていないデータを、ログファイルによって復旧させることができる。WALを採用する明白な利点は、ディスクへの書き込み回数が大幅に減ること。トランザクションコミットの時にそのトランザクションで変更された全てのデータファイルではなく、ログファイルだけをディスクに吐き出せばよいためである。
-
WALプロトコルの利点は以下のとおり。
- 障害時点でデータベースに反映されていなかった更新を、ログファイルから復旧させることができる。
- 障害時点で中途半端にデータベースへ反映されている更新を、REDOまたはUNDOすることでデータベースの一貫性を保つことができる。
- ログが必ず残っているため、メモリ上の更新データをリアルタイムにデータベースへ反映する必要がなく、更新処理を高速化できる。
-
トランザクションが正常終了したときはCOMMITコマンドによってトランザクションを確定させますが、COMMITを発行したからといって即座に補助記憶に更新内容が反映されるわけではない。データベースの更新が主記憶を介して①~⑤の手順で行われる。
-
-
トランザクション開始
-
必要なデータがデータベースから主記憶に読み出される
-
主記憶上のデータが更新される
-
コミット~トランザクション終了
-
書出しのタイミング(チェックポイント)ごとに、それまでに主記憶上で更新されたデータをまとめて補助記憶に書き込む
補助記憶への書出しは効率化のために一定時間ごとにまとめて行われるため、COMMIT文を実行したからといって、その内容が補助記憶に書き出されている保証はない。主記憶は揮発メモリなので、もしコミット文実行と補助記憶への書出しの間に障害が発生した場合は、トランザクションの情報が失われてしまうことになる。これではトランザクションの永続性(耐久性)を満たすことはできない。
このような理由からトランザクションは、コミット文が実行された時点ではなくWALプロトコルに従って更新後ログが物理的記憶装置に書き込まれた瞬間にコミットしたと見なす。一旦ログが安定記憶上(二重化されたディスクなど)に書き込まれたならば、たとえコミット文に実行以後に障害が発生しても、そのトランザクションを再現することが可能になるためである。
-
ダーティリードとは、他のトランザクションが更新したデータをまだそのトランザクションがコミットしていない時点で、その更新データを読み込んでしまうことである。コミットしていないので、もしロールバックすると本来存在しない値を読んだことになる。READ COMMMITEDで防ぐことができる(コミットしてから読んでね、ということ)
-
SQL単体?でクエリを投げてレスポンスを得る対話型(会話型)に対し、プログラムからSQLを呼べるようにしたのが埋込み型SQLである。
-
2相ロックプロトコルはロックの獲得フェーズとロックの解放フェーズを2つに分離することであり(ロックが必要な資源について、すべてのロックを獲得してから、アンロックを行う)、ロックの順番を一定にするわけではにのでデッドロックが防げるわけではない。
- アイソレーションレベルがREPEATABLE READもしくはSERIALIZABLEのとき、ロックはトランザクションのコミットまで解除されず、2相ロック方式となる
- 多くのDBMSではREAD COMMITTEDであり、本試験で出題される問題に係るアイソレーションレベルも基本的にはREAD COMMITEDである。