Egocentric Gesture Recognition Using Recurrent 3D Convolutional Neural Networks With Spatiotemporal Transformer Modules(ICCV2017)
description: 論文読んだまとめ記事
url: http://openaccess.thecvf.com/content_ICCV_2017/papers/Cao_Egocentric_Gesture_Recognition_ICCV_2017_paper.pdf
自分なりに解釈したメモになります。
ミスがあったら優しく教えてください。
-
Title
Egocentric Gesture Recognition Using Recurrent 3D Convolutional Neural Networks With Spatiotemporal Transformer Modules -
Conference
ICCV2017 -
Authors
Congqi Cao, Yifan Zhang, Yi Wu, Hanqing Lu, and Jian Cheng
中国の大学から出た論文
どんなもの?
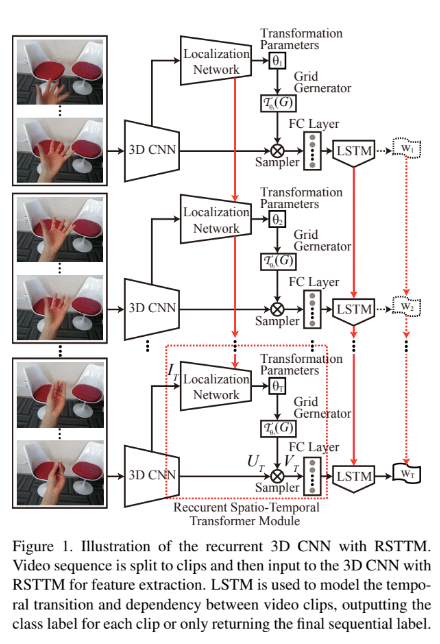
本研究では、VR機器のようなヘッドマウントカメラから装着者自身のジェスチャー動作をend-to-endな3D-RCNNで推定する手法を提案する。
特徴的な点として、STNを再帰結合と共に使ったモジュール(RSTTM)を提案している。
この構造によって空間的及び時間的次元の両方において3Dの特長マップを標準の視点に変換する。
先行研究と比べて何がすごい?
ヘッドマウントカメラからの認識を行う場合には、カメラが動くということと、視界が狭いという点が難しかった。
本研究では、カメラの動きに対して工夫しており、明示的に頭の動きを推定せずにend-to-endな推定を行う。
技術の手法や肝は?
STN(NIPS2015)は画像データに対して空間的不変性を得るためのモジュールであった。
本研究ではSTNを拡張して、3Dの特長マップを空間と時間の両方の次元で標準視点に変換するSTTM(spatiotemporal transformer module)を提案する。
STTMは以下の3つの要素で構成される。
- LocalizationNetwork
変換のパラメータ推定.
今回は最も一般的な射影変換であるホモグラフィー変換を選択した(4x4).
アフィンは長方形を平行四辺形にしたが、ホモグラフィーは台形に変換できる. - GridGenerater
推定したパラメータで移動した点の座標は小数点以下を持つ値なので、これを整数に丸めて移動後の座標を修正する. - Sampler
上記の要素で得た値から実際に変換を行う.
STTMに再帰層を付けたモジュール(RSTTM)を使っている.
どうやって有効だと検証したか
自作のデータセットを使って検証した。
-
自作データセット
- RGBD
- sample数
24,000 gesture
3,000,000 frames
-
従来手法との比較
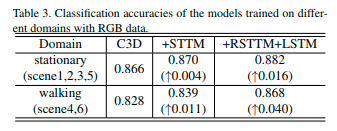
静止時では1.6%の精度向上、歩行時は4.0%の精度向上となった。
歩行時は特に精度の差が見られた。 -
混合行列の考察
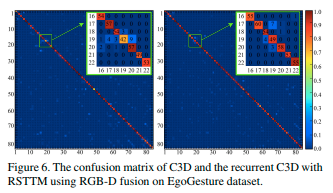
動きが類似している分類の難しい動作がうまく分類できるようになったとのこと。
参考文献