クラスタリング
クラスタリングには階層的クラスタリングと分割最適クラスタリングがある。
階層的クラスタリング
階層的クラスタリングはボトムアップ的にそれぞれのクラスタ間の類似度を求め、
類似度の高いクラスタ(つまり近い位置にあるクラスタ)を連結していく。
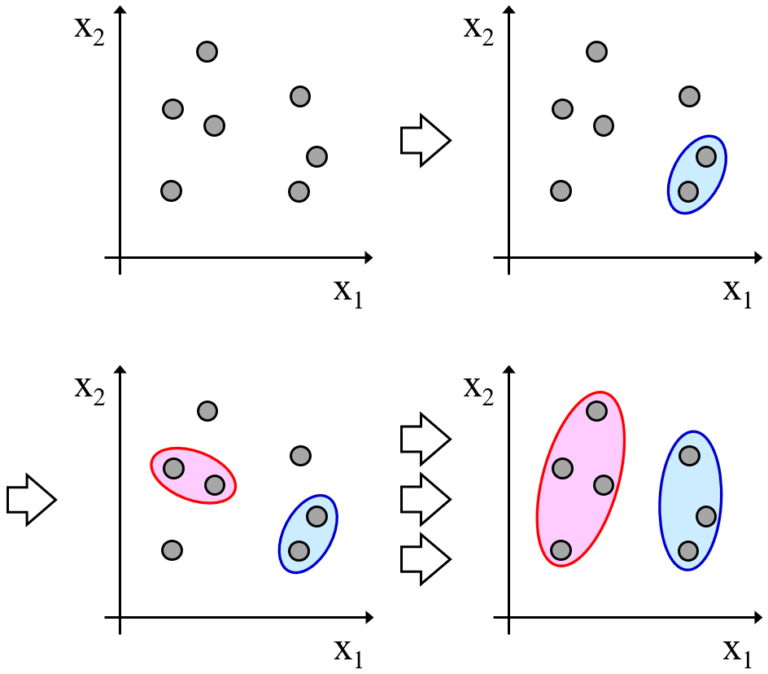
出典:データ化学工学研究室(金子研究室)@明治大学「階層的クラスタリング(クラスター分析)、近いクラスターを結合していく」2018/4/25
この類似度の置き方には、以下のようなものがある。
-
単連結法
クラスタ間で最も近いデータ同士の距離を類似度とする方法
クラスタの形が縦長だったりすることがある -
重心法
クラスタ重心間の距離をとる方法でバランス型 -
Ward法

下で説明
比較的良好な結果を示すメジャーな方法としては Ward法 が挙げられる。
これは”クラスタの重心と各データの距離の二乗和”と、”類似度を比較する2つのクラスタを一つのクラスタとしたときに同様に出した二乗和”の差を類似度として用いる。
分割最適クラスタリング
分割最適クラスタリングの代表手法は k-mean(k平均法) がある。
説明はこの記事がわかりやすい。 ![]()
ここで k-meanの評価関数 について話す。
k-meanの評価関数は各クラスタとそれに属するデータの距離の総和である。
(各クラスタが評価関数を持つのではないよ!)
データの所属するクラスタが変わるということは、これは評価関数を小さくする。
クラスタ中心の更新はクラスタに所属するデータから距離の総和が最小になる場所を見つけているということで、これも評価関数を小さくする。
こういうことから、k-meanは評価関数を小さくするように機能することがわかる。
ただし、これで見つかるのは局所的な最適解である。
そのため、異なる初期値で複数回試してみて、
最も評価関数の最も小さいものを解とする必要がある。(単純にスラカーを比較するだけ)
あとがき
自分用のメモですが、役に立てば幸いです。
なにか間違いがあればご指摘いただけるとありがたいです。 ![]()