2025/06/25 ~ 26に開催されたAWS Summit Japan 2025に参加しました。
私個人としては去年に続き2回目の参加となりました。
本記事では、参加レポートとして受けたセッションの内容をピックアップしてまとめていきます。
パナソニック エオリア アプリにおける、ユーザージャーニーを起点としたサービスレベルマネジメントの導入と実践
このセッションでは、エオリアアプリというエアコンの遠隔操作などができるスマートフォンアプリの監視・運用にNewRelicを導入し、「ユーザー視点」に最適化していく取り組みについて語られていました。
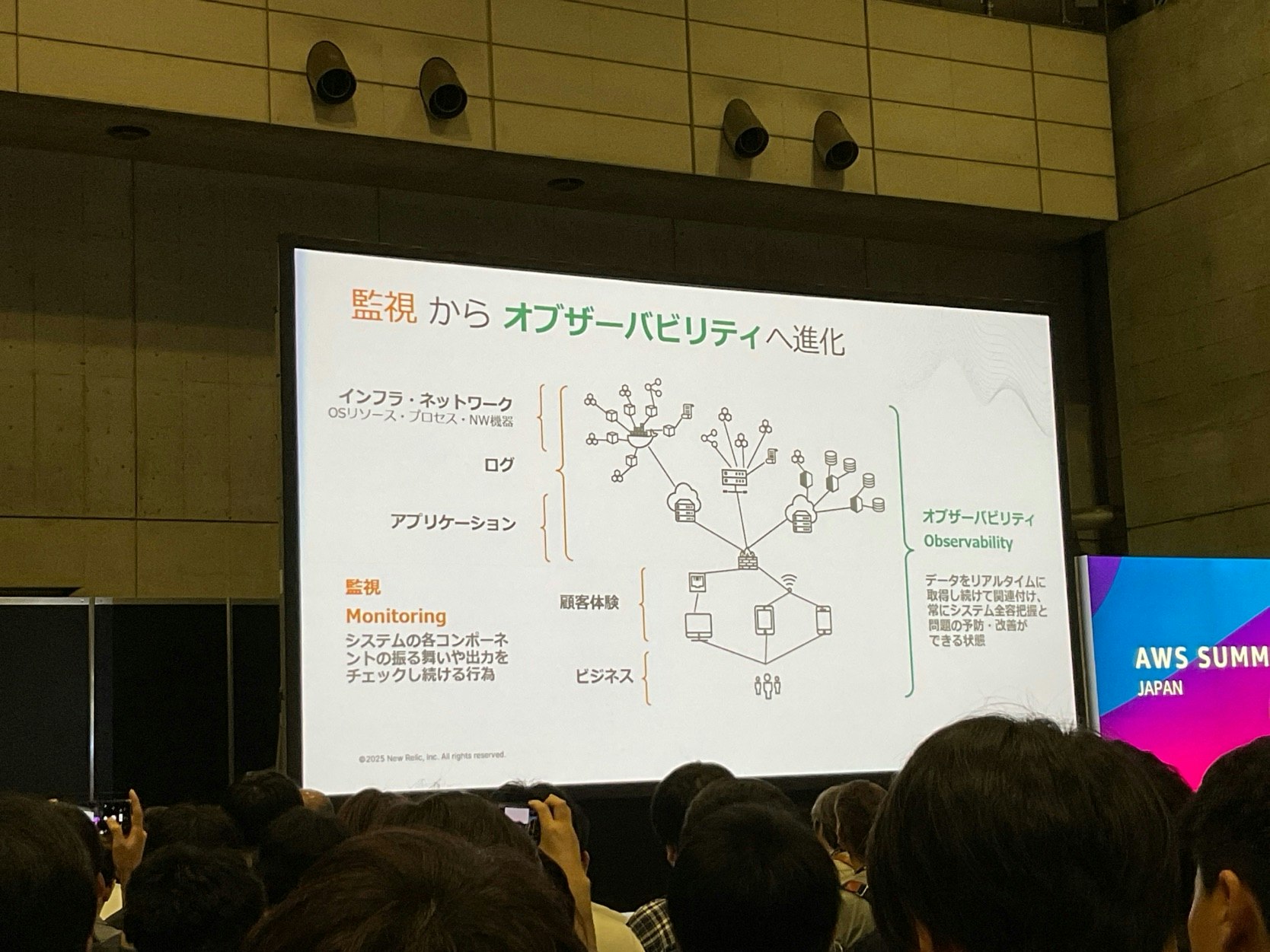
監視からオブザーバビリティへ
監視設計においてOSやCPUメトリクスだけを監視してもユーザーへのサービス提供に支障があるのかは把握できない。
ユーザーが気にするのは「アプリが満足に使えているか」であるため、ユーザーへの影響を基準としたオブザーバビリティの監視設計へシフトすべき
導入の取り組みアプローチ
CUJ, SLI, SLOの設定をAWS, NewRelicとのワークショップを通じて策定、それに基づきダッシュボード化
- CUJ(Critical User Journey): ユーザーが達成したい本質的な目的
- SLI(Service Level Indicator): CUJを定量的に図るための数値指標
- SLO(Service Level Objective): SLIに対して設定する達成目標

導入ステップ
- ユーザージャーニーの整理
- CUJの特定
- SLI/SLO仮決め
- 指標に必要なログメトリクス設計
- 指標実装
- Runbook改善
- SLI/SLO計測・見直し

- ユーザーがなにを真に求めているかに気付くことが大切
- 実際に、「エアコンが操作できること」よりも、「部屋の気温が分かること」の方が求められているというユーザ視点の発見があったようです。
CUJごとにダッシュボードを作成しNewRelic操作に詳しくなくても容易に情報確認できるよう設計

所感
NewRelicは直近に導入する機会がありましたが、CUJやSLI/SLOといったレベルまで踏み込んだ監視設計は正直できておらず、今回の事例で多く学びがありました。
特に印象的だったのは、「アプリが操作できること」ではなく、「部屋の温度が確認できること」がユーザーにとって最も重要だったという気づきです。開発側が思い込んでいる価値と、実際のユーザー価値とのギャップに気づくためにもこのCUJ定義のプロセスは重要だと感じました。
年間 20 兆円の決済システムを支える GMO ペイメントゲートウェイが内製開発で蓄積したクラウド活用の極意
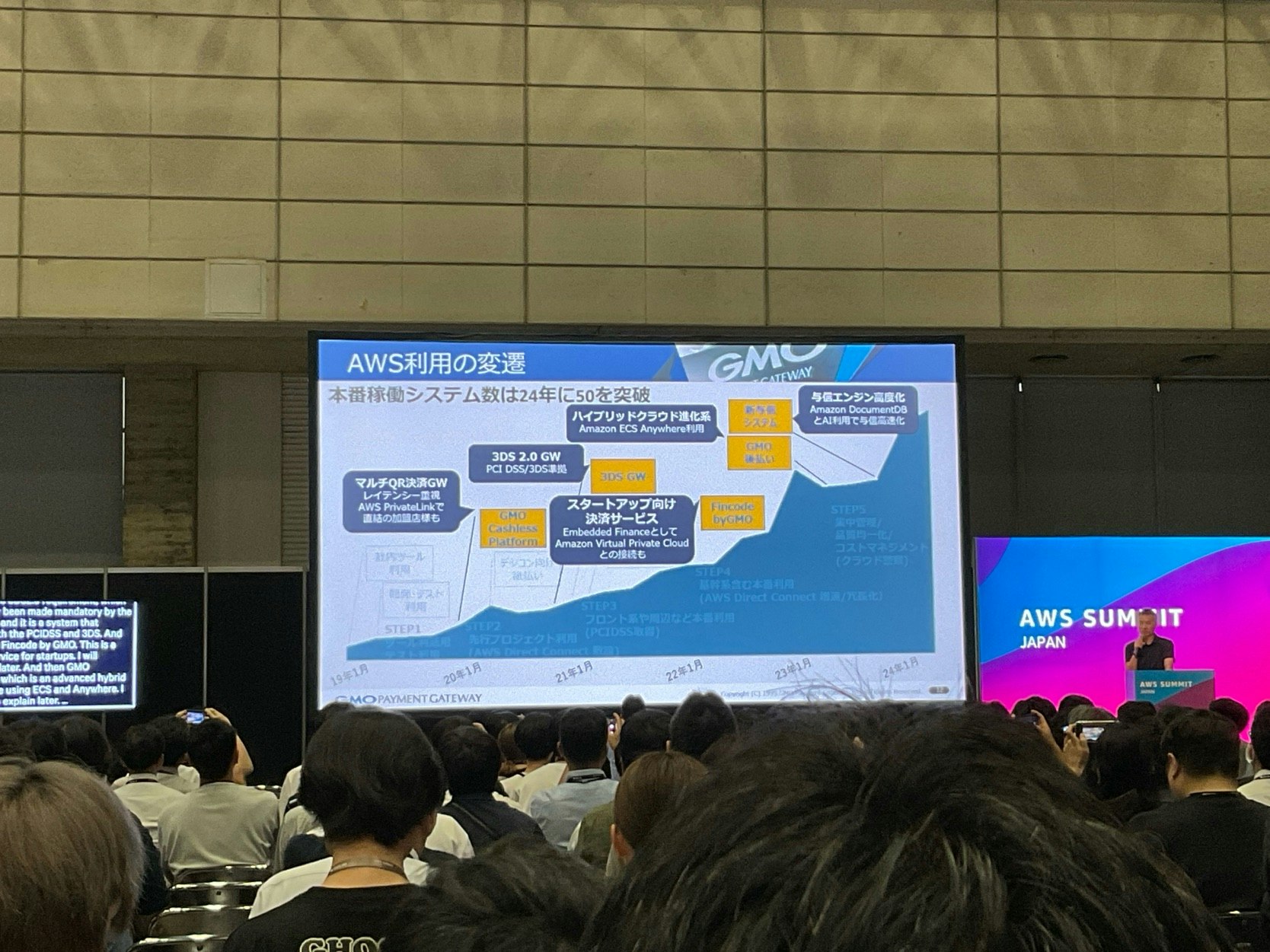
こちらのセッションでは、GMOペイメントゲートウェイが過去9年間でAWS活用へ変遷してきた過程を事例を通して説明されていました。
印象的だったのは、AWS導入のアプローチとして、EC2を禁止してマネージドサービス利用に振り切っている点でした。AWS利用による開発・構築のスピード向上や、管理負荷の軽減といったメリットを最大限に活かしたアプローチだと思います。




余談ですが、開発で天秤AIというサービスを活用しているそうで、複数のAIモデルを同時に比較しながら回答を得られるとのことで、少し気になりました。
Amazon S3 によるデータレイク構築と最適化
こちらは、S3でデータレイクを構築する際の課題と解決策をAnyCompanyという架空の企業を例に解説していくセッションでした。
課題
- クエリの遅延
- データへのアクセス制限
- コスト増加
解決策
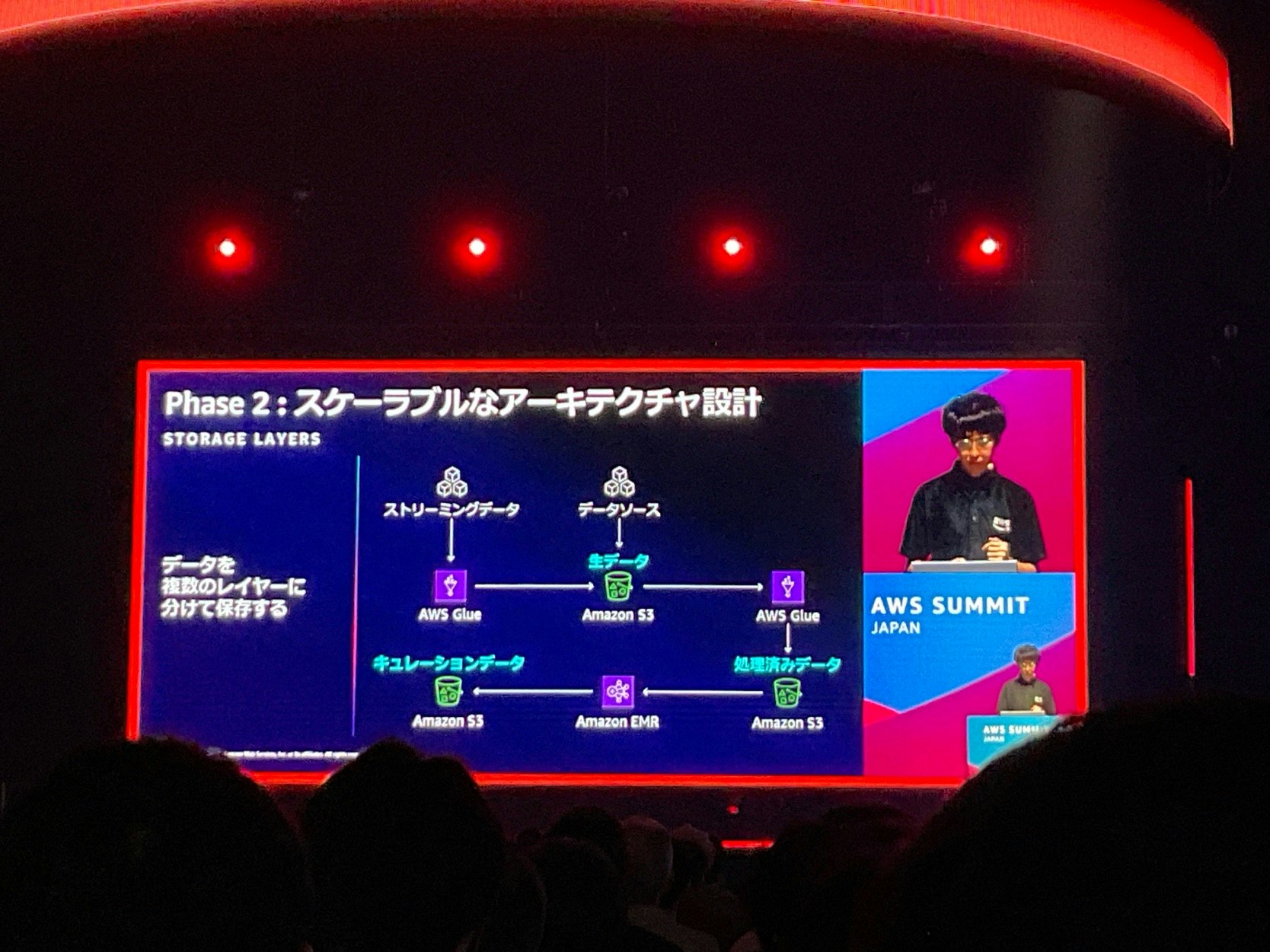
スケーラブルなアーキテクチャ設計
データを3層に分ける
- 生データ
- 処理済みデータ
- キュレーションデータ
ランダム性を持つ要素をPrefixの上位に設定する

データセキュリティとガバナンス
- AWS Glue Data Catalog: テーブル、スキーマ、パーティションなどのデータセットの詳細すべてが保存される
- AWS Lake Formation: ユーザー、ロールに基づききめ細かいデータアクセス制御をする
-
Amazon SageMaker Data & AI Governance: データをビジネスカタログ化

クエリ最適化
オープンテーブルフォーマット
- 既存のJSONやCSVのデータの上のレイヤーとして動作するもの
- テーブルの構造やスキーマの情報などが含まれている

Amazon S3 Tables
- フルマネージドなApache Iceberg TableをS3で実現


コスト対策
こちらは、S3のストレージクラスやS3 Intelligent-Tieringによる自動的なコスト最適化をしましょうという内容でした。
所感
ファイル形式のデータをテーブルとして扱えるオープンテーブルフォーマットという概念をこのセッションで初めて知りました。
特に、フルマネージドでオープンテーブルフォーマットを扱えるS3 Tablesに関して興味がわきました。
Amazon Aurora DSQL アーキテクチャー詳細
こちらのセッションはAurora DSQLの概要からアーキテクチャ詳細に至るまで説明されていました。DSQLの基本的な知識を前提としたセッションということもあり、フロントエンド寄りの私にはやや理解が難しい内容でした。ただ、使う側としては基本的な特徴だけでも押さえておけば十分かなと感じました。
基本的な特徴
- トランザクション処理に最適化: 分析系ではなく、業務アプリケーション向け
- サーバーレス
- 拡張性に優れている
- PostgreSQL互換
- アクティブ-アクティブマルチリージョン: 複数リージョンで同時に読み書き可能
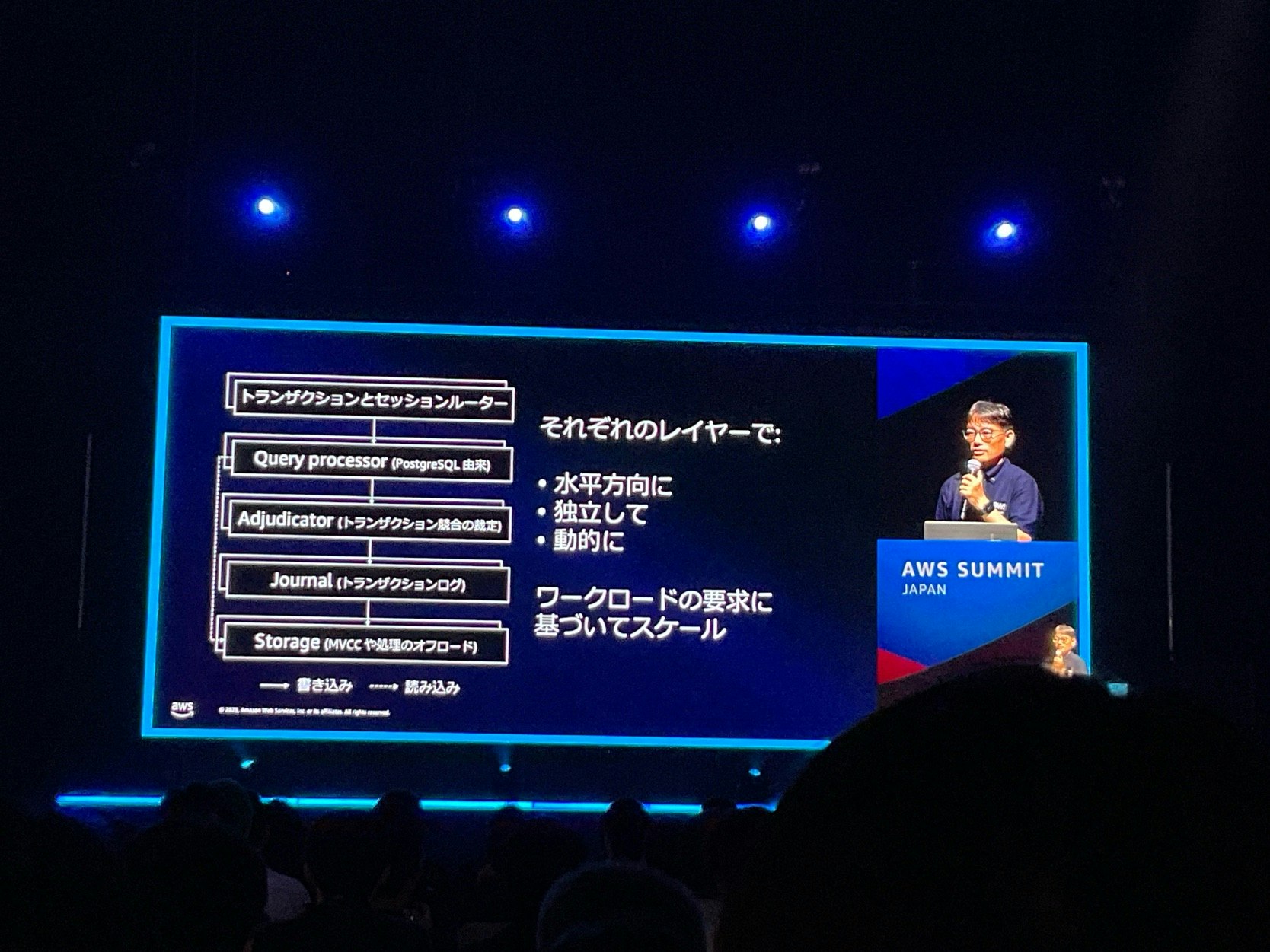
内部アーキテクチャの特徴
DSQL は、各コンポーネントが独立しており、それぞれが水平スケーリング可能な構成になっているのが特徴です。
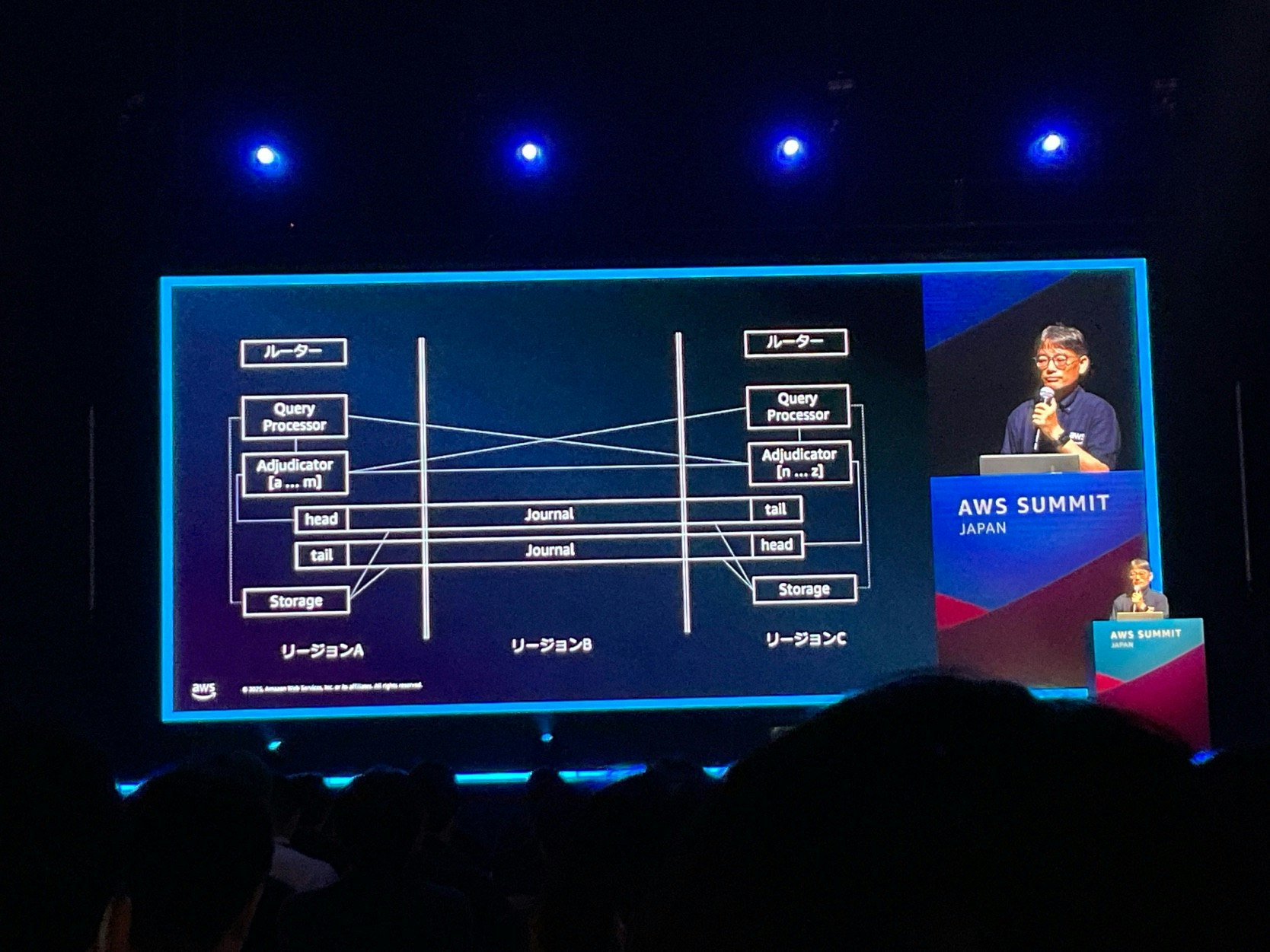
楽観的同時実行制御: Optimistic Concurrency Control
- 従来のデータベースのようなロックが不要
- トランザクション中の調整は不要で、コミット時にのみ競合チェックが行われる
- Adjudicator が、コミットのタイミングで競合を判定
トランザクションの分離性
- DSQLでは、EC2 の Amazon Time Sync Service を活用したタイムスタンプ制御によってマルチリージョンでの一貫性を保持しているようです
マルチリージョンでの最適化
- 読み取り専用トランザクション: 完全にローカルで実行されリージョン間の調整が不要
- 書き込みトランザクション: コミット時に一度だけリージョン間調整
- 高速フェイルオーバー
モダンな CI/CD ツールボックス:一貫性と信頼性を確保するための戦略
CI/CDの価値は理解しているけどその可能性を十分に活かしきれていない、という多くの組織が抱える悩みに対して、ベストプラクティスを次のレベルに引き上げるための具体的戦略を解説するセッションでした。
主要なトピック
- 変更への対応
- コード署名と構成証明
- デプロイ戦略
- ドリフト対策
- パイプラインの一貫性
- 継続的コンフィグレーションとフィーチャーフラグ
- 依存性の軽減
変更への対応
- インフラ、アプリ、設定、シークレットのすべてをバージョン管理
- 一貫したロールバック戦略
- アトミックなデプロイメント
コード署名と構成証明
- 改ざん、不正な変更、サプライチェーン攻撃からの保護
- 構成証明によりアーティファクトが改ざんされていないことを保証
GitOps
- Gitを唯一の信頼できる情報源として、アプリケーションとインフラを管理
- AWSではCloudFormation Git syncやCodePipeline V2でGitOpsライクなアプローチが可能
- Amazon Bedrockのような生成AIを活用し、過去のデプロイ結果から意思決定を支援
デプロイ戦略
- ローリングデプロイ: インスタンスを段階的に更新
- ブルー/グリーンデプロイ: 新旧環境を切り替え、ダウンタイムなしデプロイと迅速なロールバック
- カナリアデプロイ: 一部のユーザーに新バージョンを先行リリースし、段階的に展開
ドリフト対策
- CI/CDパイプラインを通さない手動変更(ドリフト)を検出・防止
- 開発者には本番環境への読み取り専用アクセス権のみを付与
- AWS CloudFormation Drift DetectionやAWS CloudTrailのアラートを活用
パイプラインの一貫性
- プロジェクト間のパイプライン構成のバラつきを解消
- 集中管理と分散管理のハイブリッドアプローチ(標準テンプレート提供と各チームでのカスタマイズ)
継続的コンフィグレーションとフィーチャーフラグ
- コードデプロイと機能リリースを分離
- フィーチャーフラグにより、コードデプロイ後もアプリケーション再起動なしに機能のオン/オフを動的に切り替え可能
依存性の軽減
- 特定のCI/CDベンダーへの依存を軽減
-
projen-pipelinesのようなツールで、TypeScriptでパイプラインを定義し、プラットフォームに依存しないポータブルなCI/CDを実現


所感
このセッションで特に印象的だったのは、projen-pipelinesでした。
将来的にCI/CDプラットフォームをGitHubからGitLabへ移行する際も、設定をコードで生成する仕組みのおかげでスムーズに移行できそうだと感じました。
コード生成による構成管理のアプローチはIaCなどよくありますが、それをCI/CDのパイプラインに適用するという考え方は新たな発見でした。