簡単なシミュレーションプログラムでMPIによる並列化の練習をします。
1.プログラムサンプル
サンプルはモンテカルロ法によるパイのシミュレーションプログラムを使います。内容はぐぐれば沢山でてきますので、詳細は説明しませんが、イメージを図に示します。
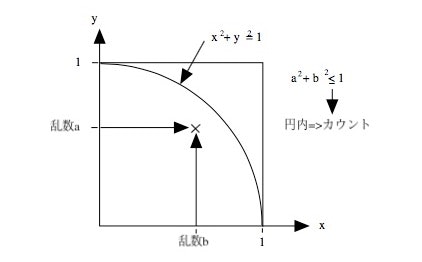
図1 モンテカルロ法によるπの計算
これにより以下のようなプログラムを組んでみました。
c234567
real*8 second
t0=second()
nstep=1000000000
n=0
m=0
do 20 i=1,nstep
x=rand()
y=rand()
r=x*x + y*y
n=n+1
if(r.LE.1.0) m=m+1
20 continue
pai=(float(m)/float(n))*4.0
write(6,*) n,m,pai
t1=second()
WRITE(6,*) 'TIME=',t1-t0
stop
end
2 並列化
パイのシミュレーションの説明はスルーしますが、モンテカルロ法は色々なところで使われている手法です。作成したプログラムをMPIを使用して並列化してみます。さて、MPI並列化の方法ですが、ポイントとしてはいくつか挙げられます。最初に、MPIコマンドを入れ込んで、MPI化を図り、各プロセスの担当部分の正確な記述を入れていくのがよいでしょう。
2.1 MPI化する
最初に決まり文句を記述して、MPI化してしまいます。以下の通りです。
call mpi_init(ierr)
call mpi_comm_rank(mpi_comm_world,np,ierr)
call mpi_comm_size(mpi_comm_world,npe,ierr)
:
本文
:
call mpi_finalize(ierr)
これで、実際にmpirunコマンドで普通に動作するようになります。
この記述で、npeが全体のサイズで、npが自分のプロセス番号になります。
2.2. 分割方法を考える
このプログラムは、モンテカルロシミュレーションなので回数が命です。従って試行回数を並列化します。たとえば、試行回数100万回を50万づつなどと分けるわけです。すると、分けたことで半分の実行時間にすることができます。この原理で分割数を増やせば試行回数をどんどん減らすことができます。
しかし、分割した試行結果を最後に集計しなければ「結果」を得られませんので、各処理の結果を通信して集めます。
2.3 通信
普通は、便利な集計関数を使用しますが、何をするのか明確にするために、
実際に必要な操作を個別にみられるように以下のようにサンプルを作成しました。
if (np.eq.0) then
write(6,*) np,npe,' send=',m(0,0),m(1,0)
do n=0,npe-1
if(n.ne.0) then
call mpi_recv(m(0,n),2,mpi_integer,n,n,
& mpi_comm_world,ist,ierr)
endif
enddo
else
write(6,*) np,npe,' send=',m(0,np),m(1,np)
call mpi_send(m(0,np),2,mpi_integer,0,np,
& mpi_comm_world,ierr)
endif
この操作は、ランク0と呼ばれる親プロセスにすべての結果を集めています。普通は、こんな面倒なことはせずに関数を使用します。例えば、
call MPI_Reduce(m,mr,2,mpi_integer,MPI_SUM,0, mpi_comm_world,ierr)
などとします。
ここでは、練習なので面倒ですがプロセス別の記述を入れます。
2.4 プログラミング
先のプログラムを並列化して記述してみましょう。
c234567
include 'mpif.h'
integer np,npe,ist,ierr,ji,jj,js,je,n
real*8 second
integer m(0:1,0:7)
dimension ist(mpi_status_size)
t0=second()
call mpi_init(ierr)
call mpi_comm_rank(mpi_comm_world,np,ierr)
call mpi_comm_size(mpi_comm_world,npe,ierr)
c
nstep=1000000000
m(0,np)=0
m(1,np)=0
if(np.ne.0) x=rand(np)
do 20 i=np+1,nstep,npe
x=rand()
y=rand()
r=x*x + y*y
m(0,np)=m(0,np)+1
if(r.LE.1.0) m(1,np)=m(1,np)+1
20 continue
c
if (np.eq.0) then
write(6,*) np,npe,' send=',m(0,0),m(1,0)
do n=0,npe-1
if(n.ne.0) then
call mpi_recv(m(0,n),2,mpi_integer,n,n,
& mpi_comm_world,ist,ierr)
endif
enddo
else
write(6,*) np,npe,' send=',m(0,np),m(1,np)
call mpi_send(m(0,np),2,mpi_integer,0,np,
& mpi_comm_world,ierr)
endif
call mpi_barrier(mpi_comm_world,ierr)
call mpi_finalize(ierr)
m1=0
m2=0
do i=0,npe-1
m1=m1+m(1,i)
m2=m2+m(0,i)
enddo
pai=(float(m1)/float(m2))*4.0
if(np.eq.0) then
write(6,*) 'SAMPLE=',m2,' HIT=',m1,' PAI=',pai
endif
t1=second()
if(np.eq.0) WRITE(6,*) 'TIME=', t1-t0
stop
end
3 実行
さあて、いかがでしょうか。プログラムをコンパイルしてみます。
> gcc -c wclock.c
> mpif90 -o mpai mpai.f wclock.o
※エラーが出る場合、MPI環境の整備が必要です。
いよいよ、実行して見ます。
> mpirun -np 1 ./mpai
0 1 send= 1000000000 785397199
SAMPLE= 1000000000 HIT= 785397199 PAI= 3.14158869
TIME= 49.1830750
> mpirun -np 2 ./mpai
0 2 send= 500000000 392697098
1 2 send= 500000000 392691505
SAMPLE= 1000000000 HIT= 785388603 PAI= 3.14155436
TIME= 24.7455463
> mpirun -np 4 ./mpai
0 4 send= 250000000 196346292
3 4 send= 250000000 196347897
1 4 send= 250000000 196347336
2 4 send= 250000000 196346705
SAMPLE= 1000000000 HIT= 785388230 PAI= 3.14155293
TIME= 12.8648043
どうですか。処理時間がスケールしましたか。?
各プロセスの結果が全部が同じ結果になっている場合、乱数の引用列が同じになっています。この場合、引用列が変化するようにプログラミングしてください。
補足です。
プログラムで使用している外部関数の時計ルーチンを忘れていました。このルーチンは、システムの時計を使用(呼出)しています。
# include <sys/time.h>
double second_()
{
struct timeval tm;
struct timezone tmz;
int i;
i = gettimeofday(&tm,&tmz);
return ( (double) tm.tv_sec + (double) tm.tv_usec * 1.e-6 );
}
コンパイラによっては、一緒にコンパイルできますが、最初に時計ルーチンのオブシェクトを作って後でリンクしてやります。fortranからCを呼ぶときはそのまま呼べますが、Cからfortranを呼ぶときは名前の後ろに "_" アンダーバーをつけます。
その他
数字を大きくすると、桁数が足りなくなる場合があります。この場合は、コンパイルオプションに -r8 などとオプションを入れます。
また、プログラム内の判定に .LE. を使用していますが、 .LT. とすると数字が変わる場合と、変わらない場合があります。シミュレーションに興味を持っていただけるとうれしいな。