やること
OSSのtess4jを利用して画像からテキストを取得する
Maven
mvnrepositoryからPOM.xmlへコピペ
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.3.1</version>
</dependency>
tess4j-4.3.1.jarがDLされる
Maven使えない場合はここから
日本語認識ファイル
GitHubのリポジトリから日本語の認識ファイル(jpn.traineddata)を取得
ソース
OcrTrial.java
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
public class OcrTrial {
public static void main(String[] args) throws IOException, TesseractException {
// 画像を読み込む
File file = new File("C:\\work\\INPUT.JPG");
BufferedImage img = ImageIO.read(file);
ITesseract tesseract = new Tesseract();
tesseract.setDatapath("C:\\work"); // 言語ファイル(jpn.traineddata))の場所を指定
tesseract.setLanguage("jpn"); // 解析言語は「日本語」を指定
// 解析
String str = tesseract.doOCR(img);
// 結果
System.out.println(str);
}
}
INPUTにした画像ファイル

出力された結果
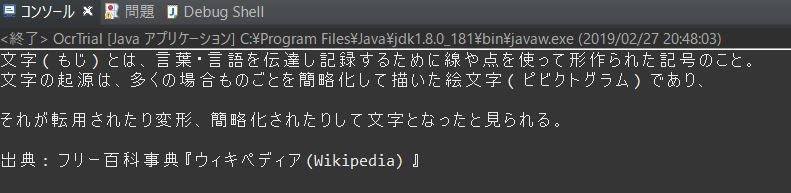
まとめ
間違いはここくらい
〇(ピクトグラム)
× ( ピ ビ ク ト グ ラ ム )
はっきり文字として判別できる画像であれば認識率は高そう
次回
- 色々な画像を試してみる
- グレースケール
- Class Tesseractの関数を理解し使ってみる