こんにちは。
株式会社クラスアクト インフラストラクチャ事業部の大塚です。
今回はAWSの文字起こしサービスであるTranscribeを触ってみましたので、雑に備忘録します。
TranscribeもTranslateやComprehendと同様、コンソールから分析したい音声を直接入れることで文字起こしすることも出来ますし、音声ファイルを用意してそれを文字起こしさせる方法の2通りがあるようで、それぞれを試してみたいと思います。
AWS Transcribeとは?
音声をテキストに自動的に変換してインサイトを得る
Amazon Transcribe は、フルマネージド型の自動音声認識 (ASR) サービスで、デベロッパーが音声の文字起こし機能をプリケーションに簡単に追加できるようにします。数十億パラメーターから構成される、次世代の音声基盤モデルを採用し、ストリーミング音声と録音音声の高精度な文字起こしを実現します。業界を問わず数千ものお客様が、手動タスクの自動化、豊富なインサイトの取得、アクセシビリティの向上、音声および動画コンテンツの発見しやすさの強化に役立てています。
触ってみる
Webコンソールで音声を入力して文字起こしさせる
AWSコンソールでTranscribeと検索すると本サービスが出てきますので、押下します。

以下のような画面が表示されます。画面左のタブのリアルタイムトランスクリプションを押下します。

言語設定で日本語を選択した後、ストリーミングを開始ボタンを押下し、CNNの日本語訳の最初の方を読んでみると、以下のように私が読んでいた文章が出力されていることがわかります。
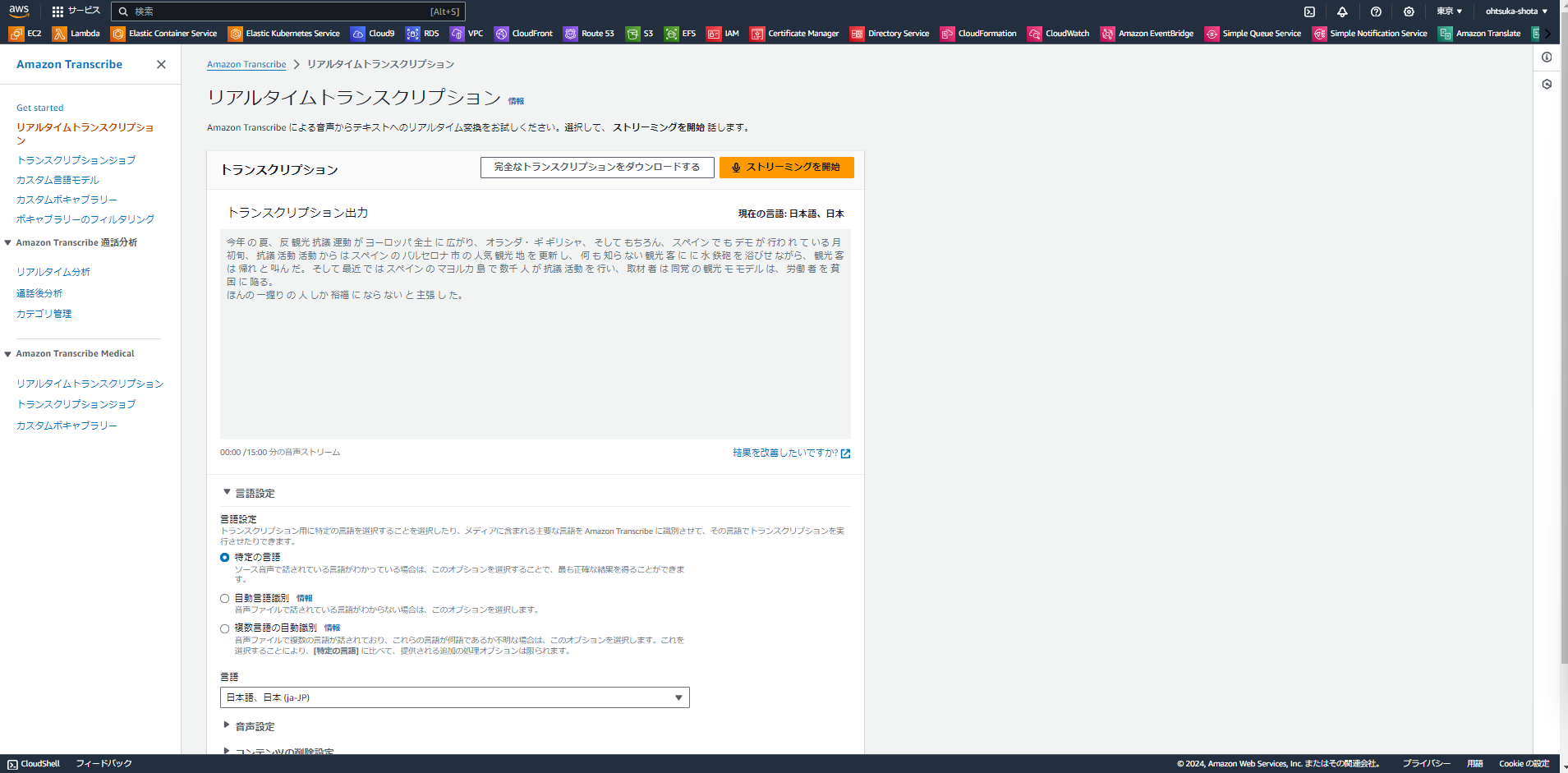
今年 の 夏、 反 観光 抗議 運動 が ヨーロッパ 全土 に 広がり、 オランダ・ ギ ギリシャ、 そして もちろん、 スペイン で も デモ が 行わ れ て いる 月 初旬、 抗議 活動 活動 から は スペイン の バルセロナ 市 の 人気 観光 地 を 更新 し、 何 も 知ら ない 観光 客 に に 水 鉄砲 を 浴びせ ながら、 観光 客 は 帰れ と 叫ん だ。 そして 最近 で は スペイン の マヨルカ 島 で 数千 人 が 抗議 活動 を 行い、 取材 者 は 同党 の 観光 モ モデル は、 労働 者 を 貧困 に 陥る。
ほんの 一握り の 人 しか 裕福 に なら ない と 主張 し た。
読んだニュース記事は以下の記事の最初の方です。
完全なトランスクリプションをダウンロードするボタンを押下するとJSONファイルがダウンロードされます。

これの中身を見てみると以下のようなデータが格納されています。
全文は20万行近くあるので、こちらに記載することはできないが、センテンスである程度区切っているように見えます。
{
"Transcript": {
"Results": [
{
"Alternatives": [
{
"Items": [
{
"Content": "今年",
"EndTime": 3.125,
"StartTime": 2.855,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "の",
"EndTime": 3.245,
"StartTime": 3.125,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "夏",
"EndTime": 3.485,
"StartTime": 3.245,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "、",
"EndTime": 3.485,
"StartTime": 3.485,
"Type": "punctuation",
"VocabularyFilterMatch": false
},
{
"Content": "反",
"EndTime": 4.045,
"StartTime": 3.805,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "観光",
"EndTime": 4.485,
"StartTime": 4.045,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "抗議",
"EndTime": 5.125,
"StartTime": 4.485,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "運動",
"EndTime": 5.275,
"StartTime": 5.125,
"Type": "pronunciation",
"VocabularyFilterMatch": false
},
{
"Content": "が",
"EndTime": 5.405,
"StartTime": 5.275,
"Type": "pronunciation",
"VocabularyFilterMatch": false
}
],
"Transcript": "今年の夏、反観光抗議運動が"
}
],
"ChannelId": "ch_0",
"EndTime": 5.775,
"IsPartial": true,
"ResultId": "ca04adfe-654f-44d7-8388-63e52dfbe97b",
"StartTime": 2.845
}
]
}
},
音声ファイルで文字起こしさせる
Translate,Comprehendと同様にS3にデータを格納して、それを使って文字起こしをしてもらいます。
まず音声データを作成する必要があるため、Windowsのデフォルトのアプリであるサウンドレコーダーを使って音声を収録しました。読んでいる記事内容は先ほどと同様です。

音声データがm4a拡張子で保存されていることがわかります。

S3バケットにtranscribeフォルダを切ります。translateの時と同様にinput/outputフォルダも内部で切ります。
inputフォルダに先ほど作成した音声データを格納しておきます。



音声データの準備が出来ましたので、ジョブを作成していきたいと思います。
左タブのトランスクリプションジョブを選択して、ジョブを作成ボタンを押下します。
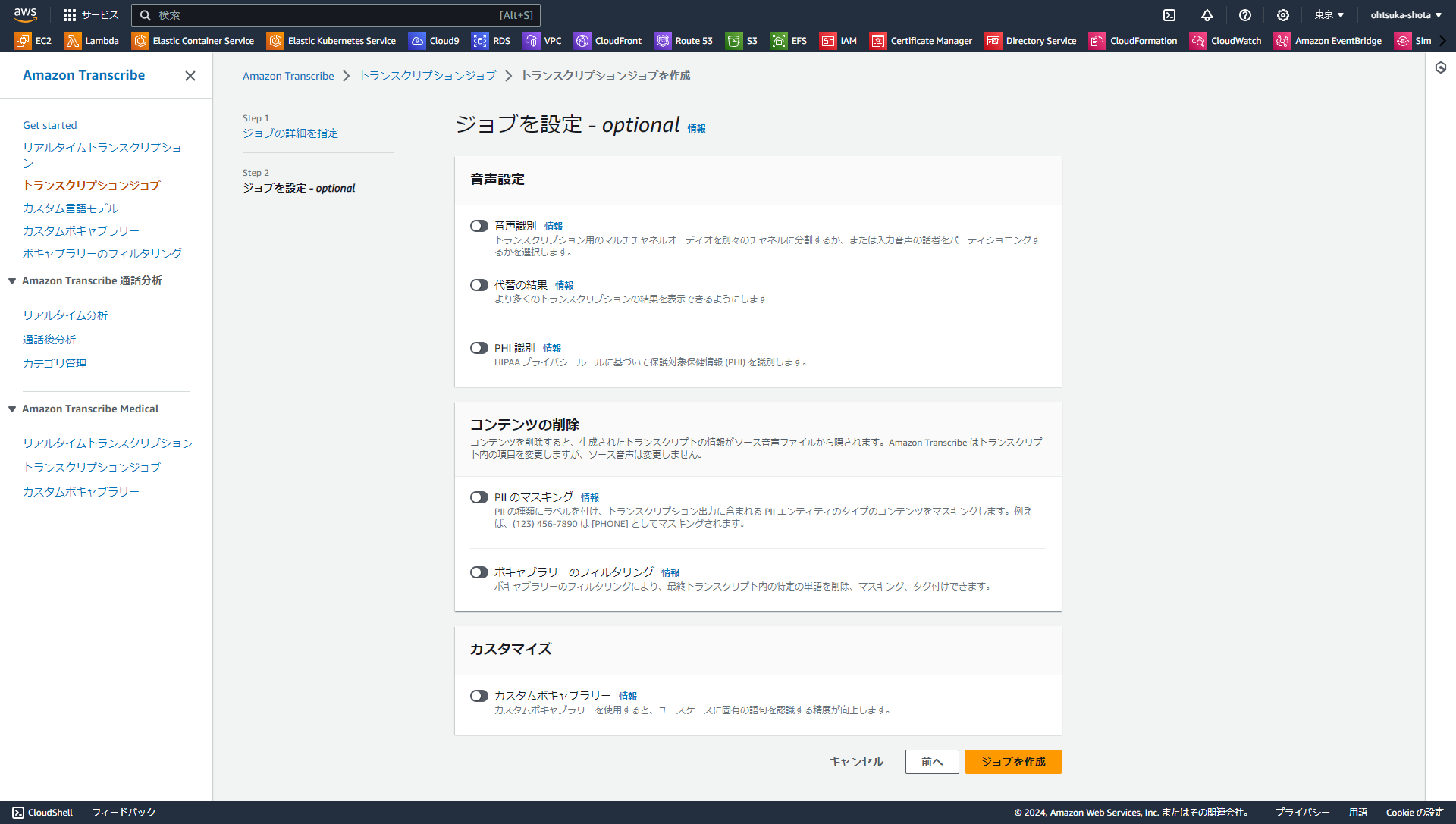
以下の設定でジョブを作成しました。
名前をtest-transcribeとしました。音声データは日本語ですので、言語は日本語を選択します。
入力データはS3に格納している音声データを選択。出力データは先ほど作成したS3バケットのoutputフォルダを選択します。
後はデフォルトの設定で作成しました。

作成すると以下のような画面が表示されます。ステータスが完了になることを確認しましょう。
私の環境だけかもしれませんが一瞬で終わりました。translateが時間かかった割に。。。



S3バケットのoutputディレクトリを確認すると、ファイルが格納されていることが確認できます。

上記ファイルをローカルにダウンロードして開いてみるとJSONデータがあることがわかります。

これのresultsオブジェクトのtranscriptsフィールドにあります。
若干文章が怪しいですが、たぶん私の活舌の問題でしょう(白目)
このまま使うのではなく、この後に文章が通るように成形するような処理をかませた方がよさそうですね。
"transcript": "今年の夏、反観光抗議運動がヨーロッパ全土に広がり、オランダ、ギリシャ、そしてもちろんスペインでもデモが行われている。七月初旬、講義講義活動からはスペインのバルセロナ市の人気観光を更新し、何も知らない観光客に水鉄砲を浴びせながら観光客は帰れ!と叫んだ。そして最近ではスペインのマヨルカ島で数千人が抗議活動を行い、主催者は道々の観光モデルは労働者を貧困に陥れ、ほんの一握りの人しか裕福にならないと主張した。"