こんにちは。
株式会社クラスアクト インフラストラクチャ事業部の大塚です。
今日はAWSの公式ドキュメントを参考に、AWS AthenaやGlueについて初心者なりにメモを作成しておき、今後に活かしていければと思っております。
AWS Athena(アテナ)とは
(ギリシャ神話で出てきますよね。勝手なイメージですが厨二っぽい名前…笑)
簡単にまとめると「Amazon S3に保存されているデータに対して、標準的なSQLを使って直接分析ができるサーバーレス型のクエリサービス」ってことなんだと。
標準SQLを使用して Amazon Simple Storage Service (Amazon S3) 内のデータを直接分析できるインタラクティブなクエリサービスです。
Athena は、Amazon S3 に保存されている非構造化データ、半構造化データ、構造化データの分析に役立ちます。
Amazon Athena を使えば、Amazon S3 内のデータに対して、データのフォーマットやインフラストラクチャの管理をすることなく、インタラクティブなクエリを簡単かつ直接実行できます。例えば、Web ログに対して簡単なクエリを実行し、サイトのパフォーマンス問題をトラブルシューティングしたい場合などに Athena は便利です。Athena を使えば、すぐに使い始めることができます。データ用のテーブルを定義し、標準 SQL を使用してクエリを実行するだけです。
インフラストラクチャやクラスターの管理を必要とせず、Amazon S3 上のデータに対してインタラクティブなアドホック SQL クエリを実行したい場合は、Amazon Athena をご利用ください。Amazon Athena は、サーバーのセットアップや管理を必要とせず、Amazon S3 上のデータに対してアドホッククエリを実行する最も簡単な方法を提供します。
AWS Glueとは
データの抽出・変換・保存(ETL)」と「データカタログの管理」を行うサーバーレスのデータ統合サービス
データ分析を行う前に、バラバラに散らばったデータを集めて整理し、分析しやすい形に加工(前処理)するためのもの
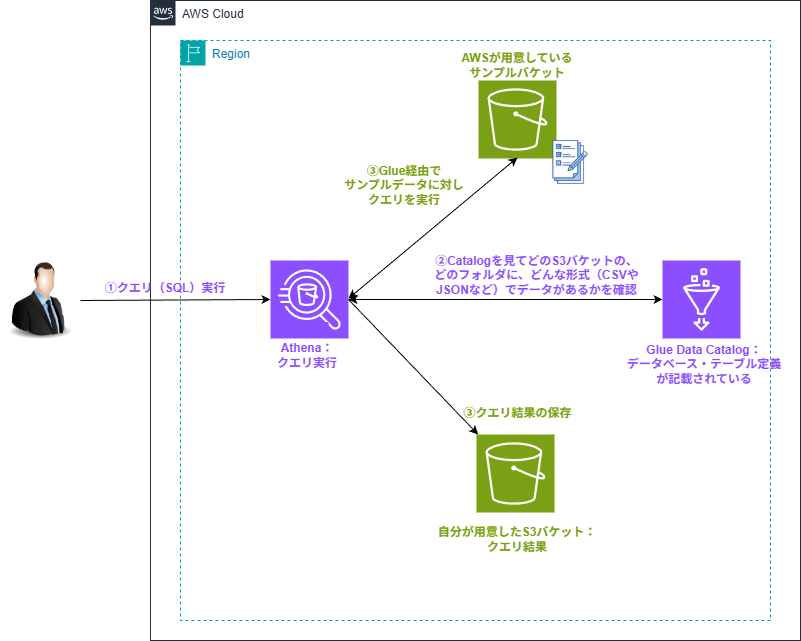
環境イメージ
今回の環境イメージはこうなると思っています。
ユーザがAthenaに対してクエリを投げると、Athenaに連携されているGlueを経由して、実際のデータが格納されているS3(今回はAWS公式が用意しているサンプルS3バケット)にSQLクエリを実行します。
実行結果はAthenaに表示されるほか、自身で作成したS3バケットにも保存されます。
環境構築
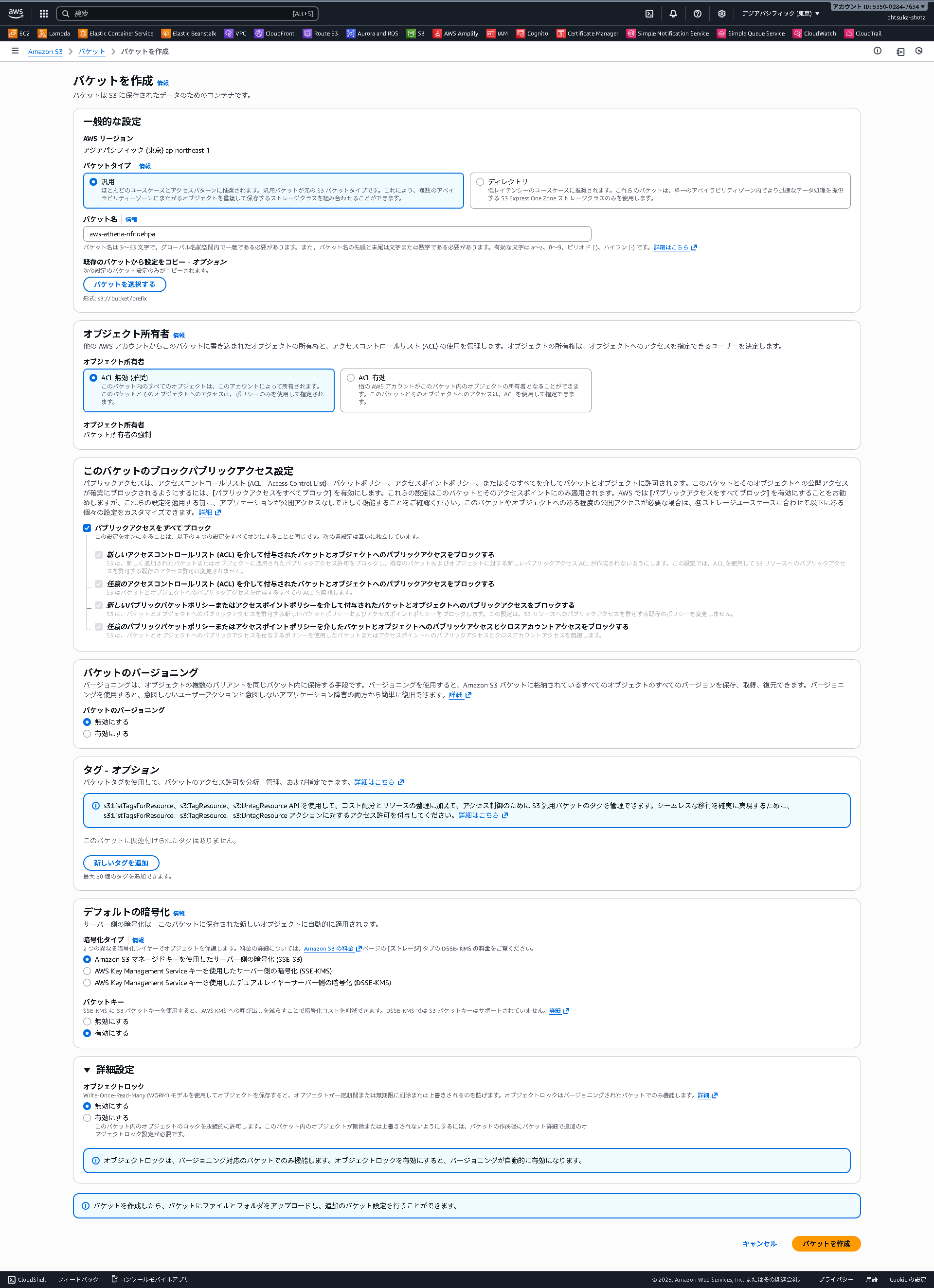
S3バケットを作成
以下のようにS3バケットを作成します。
名前はグローバルで一意である必要がありますが、他の設定はデフォルトで大丈夫です。
Athenaでの操作
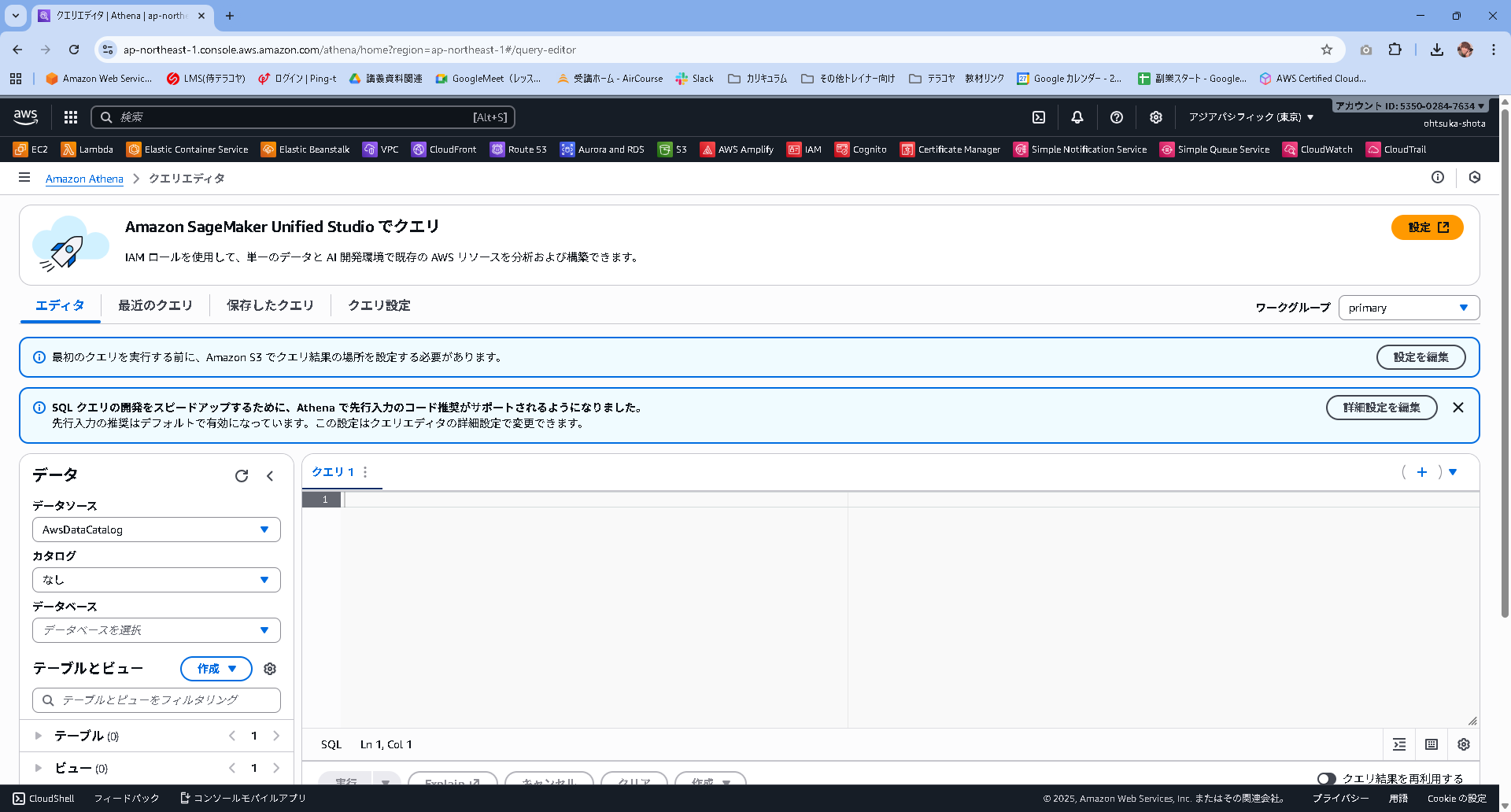
Athenaの管理画面に移動します。
最初はこのような画面になっていると思いますので、「最初のクエリを実行する前に、Amazon S3 でクエリ結果の場所を設定する必要があります。」と記載されている部分の設定を編集を押下します。
設定画面が開くと思います。Browse S3というボタンを押下して、S3を選択していきましょう。
※このS3にAthenaで実行したクエリ結果が格納されていく形になります。
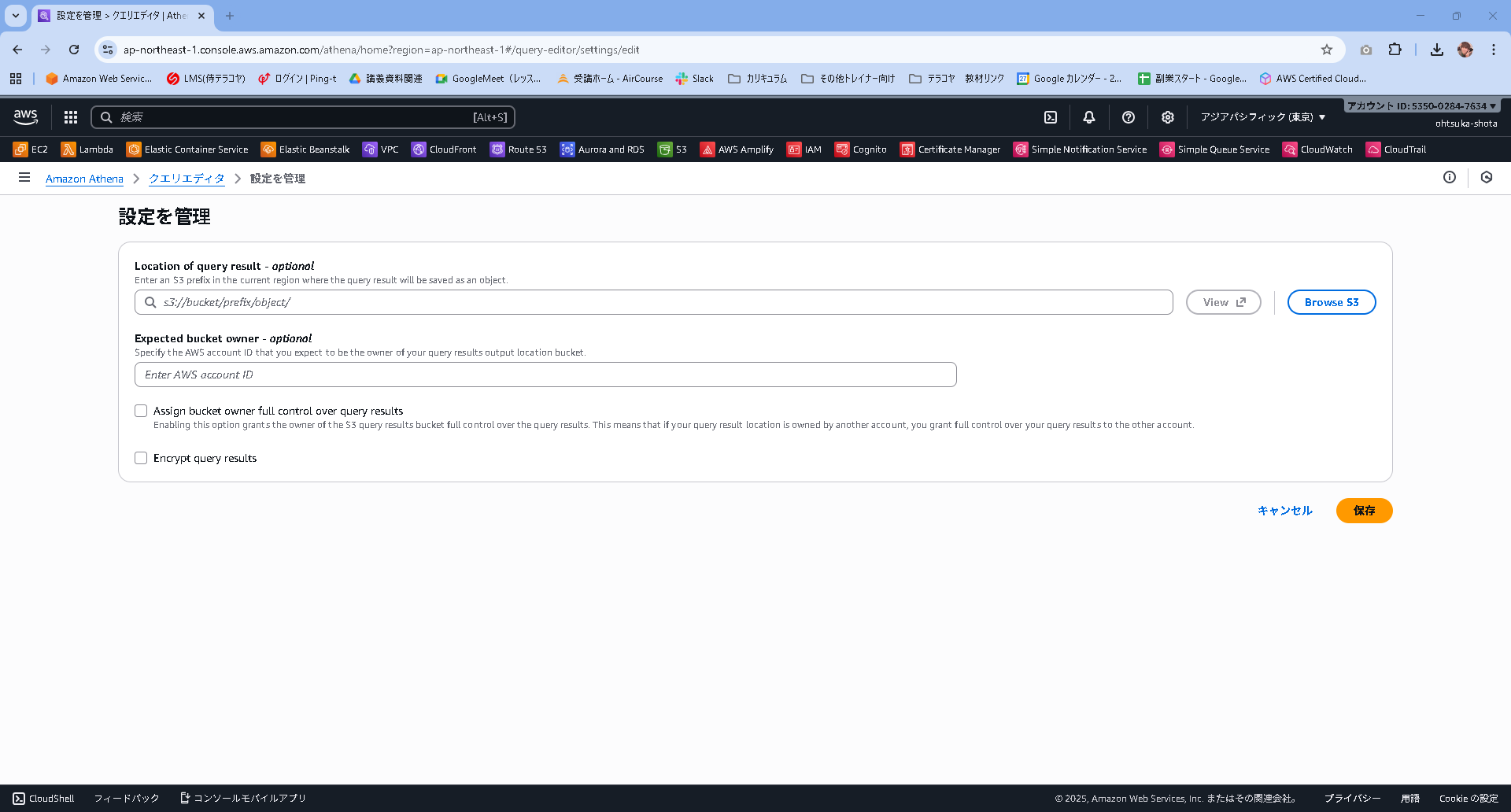
先程作成したS3バケットを選択して、保存を押下します。
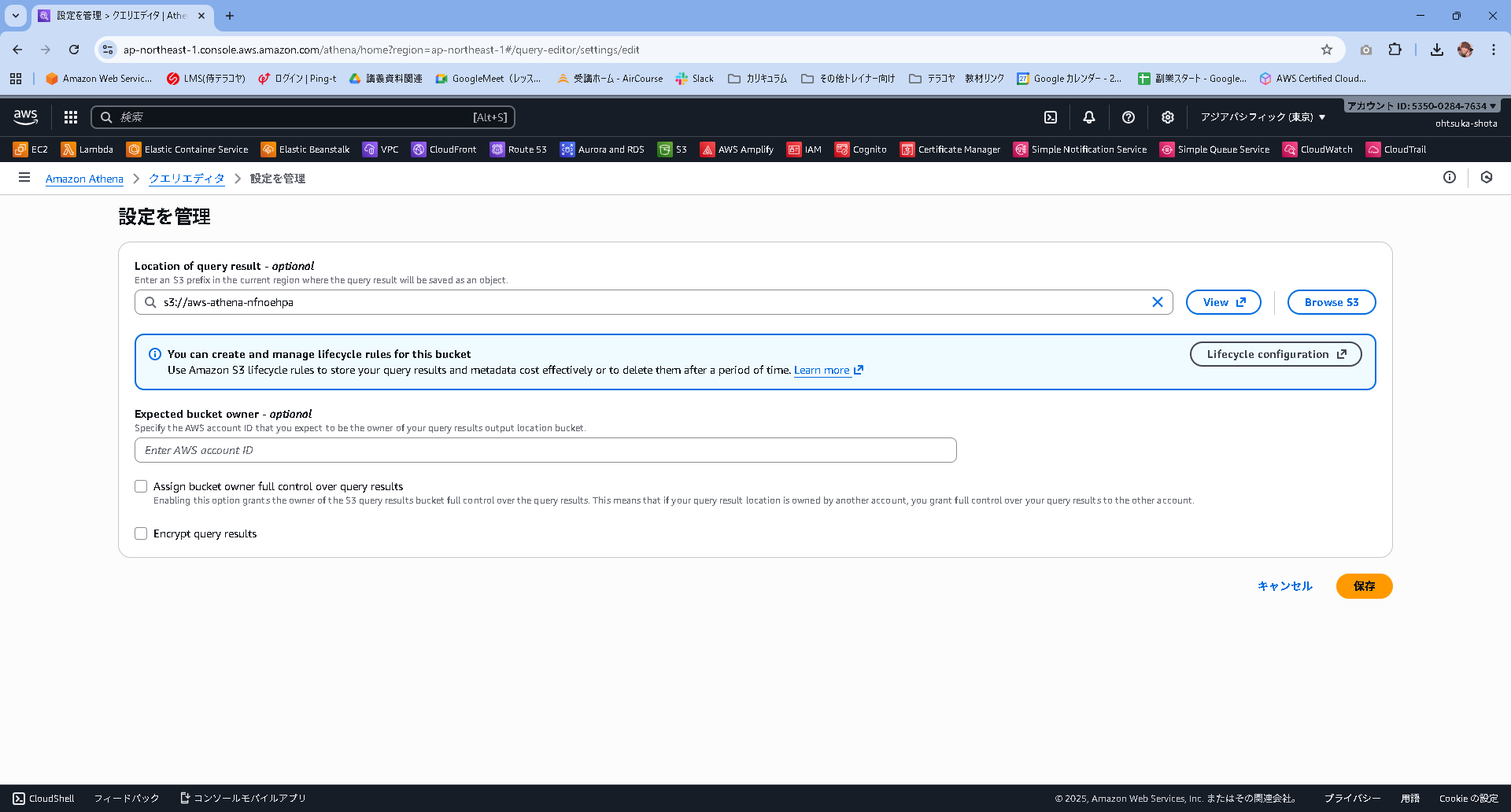
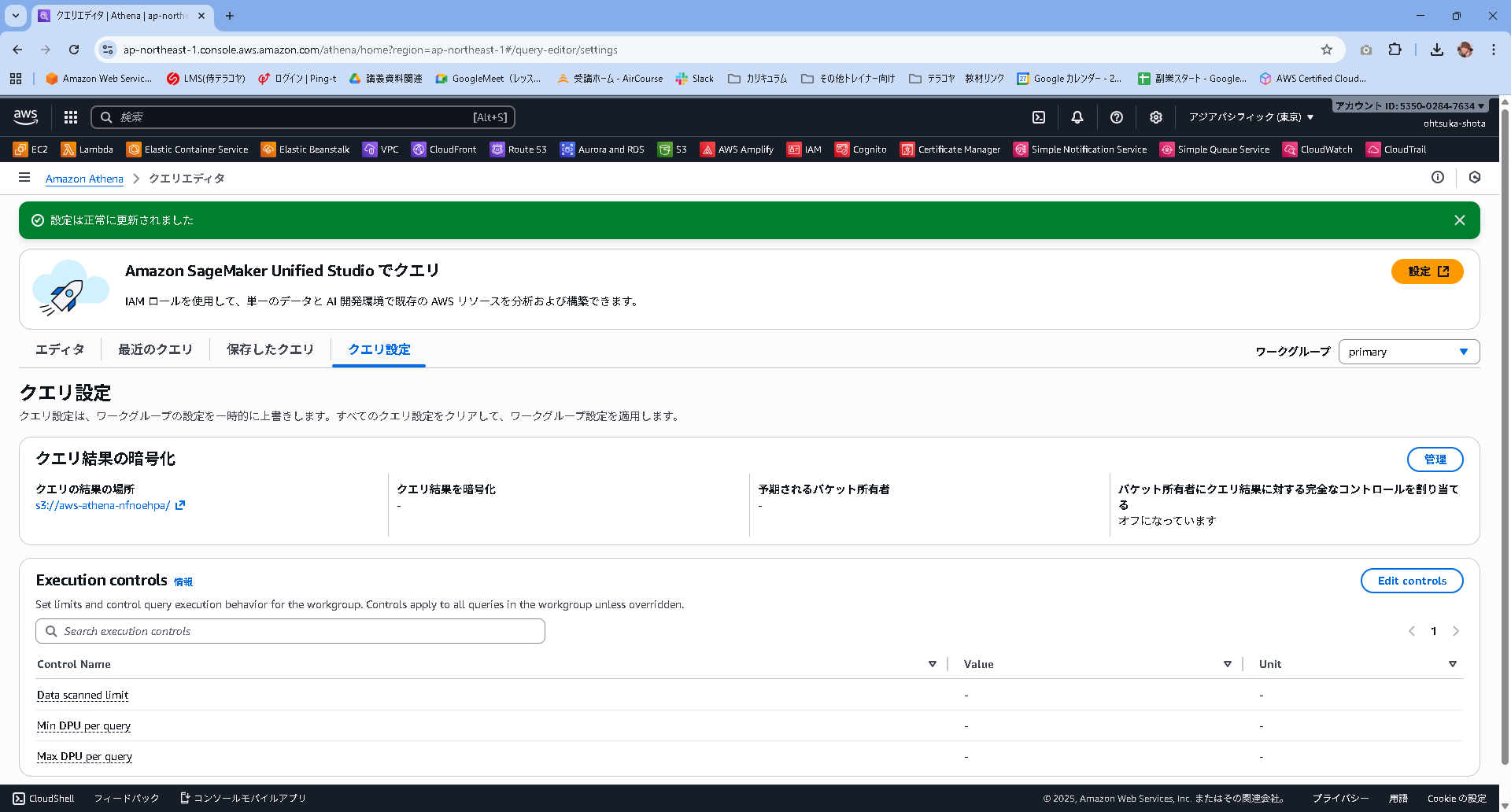
クエリ設定の画面が開くと思います。クエリの結果の場所に先ほど指定したS3バケットのURLが表示されていると思います。
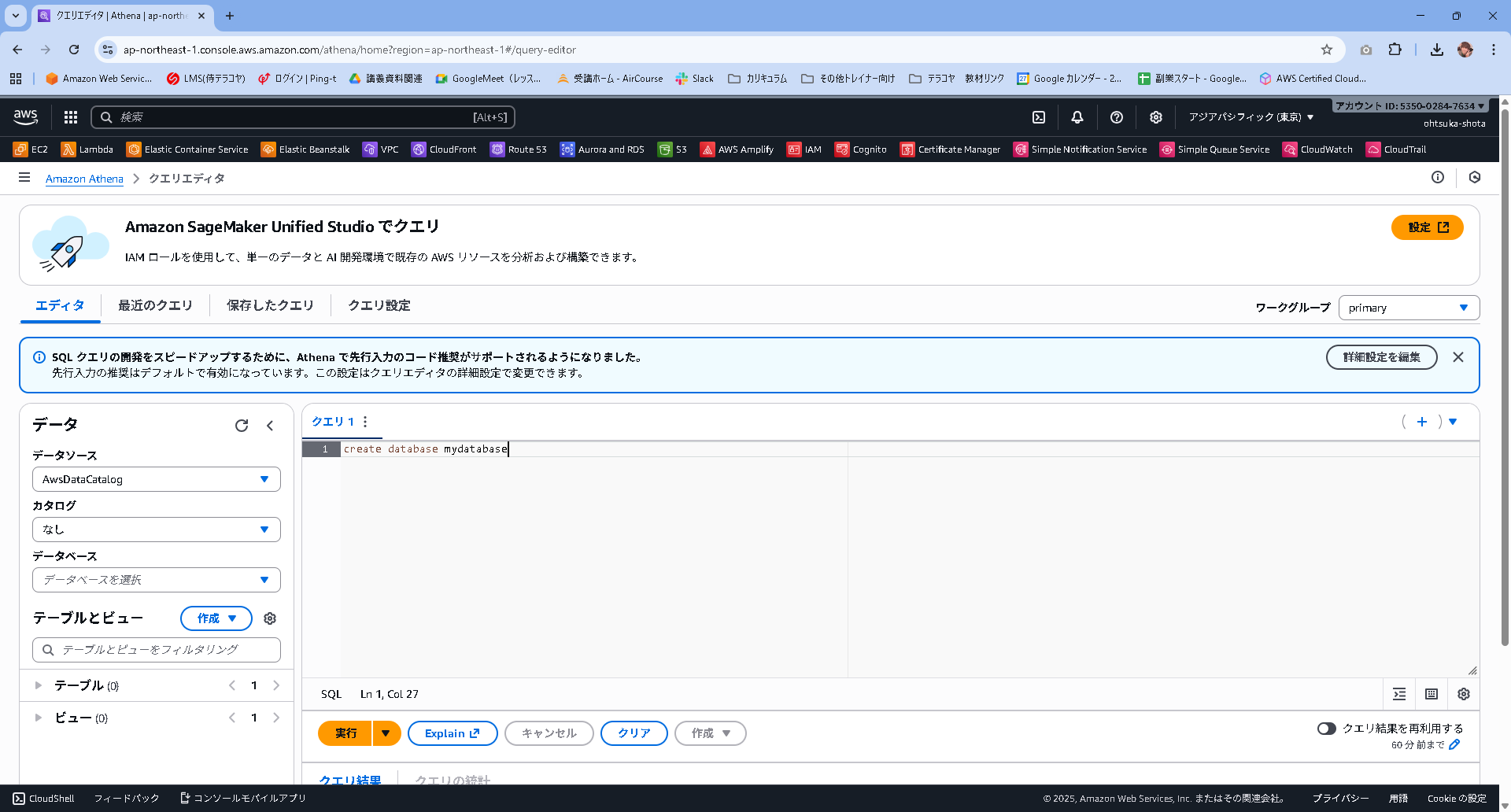
エディタタブを表示してクエリの部分で、create database mydatabaseと入力して実行ボタンを押下します。
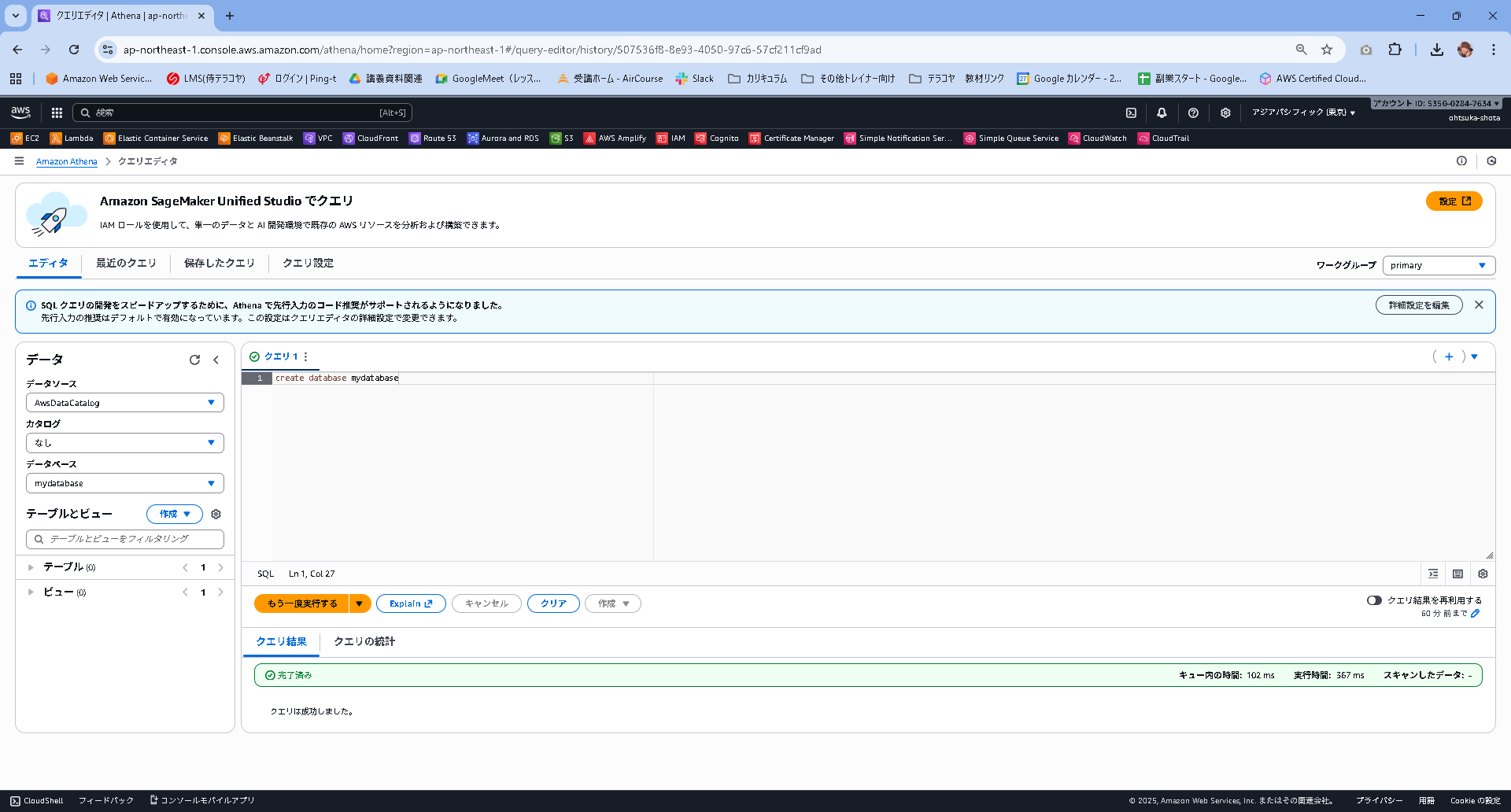
クエリ結果に完了済みと表示されることを確認します。
そして画面左側のデータベースでmydatabaseが選択できることを確認します。
S3バケットを見ると、txtファイルが作成されていることがわかります。
以下のコマンドを実行します。
"LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/';"のリージョン部分はAthenaを実行している環境に合わせます。
s3://athena-examples-ap-northeast-1/cloudfront/plaintext/はAWSが用意しているサンプルデータ格納用のS3バケットになります。
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`Date` DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/';
実行結果は以下となります。テーブルにcloudfront_logsが作成されていることがわかります。
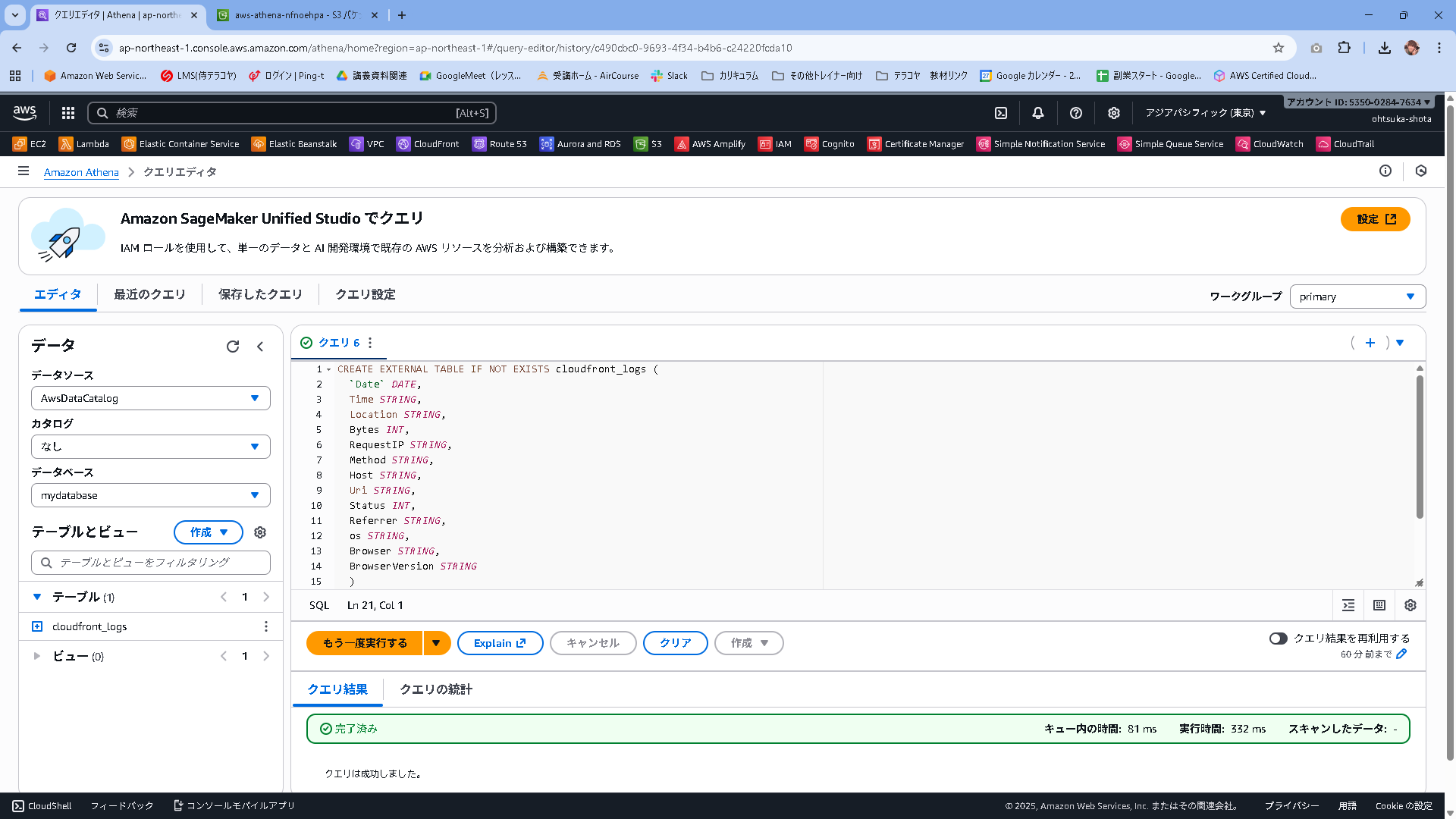
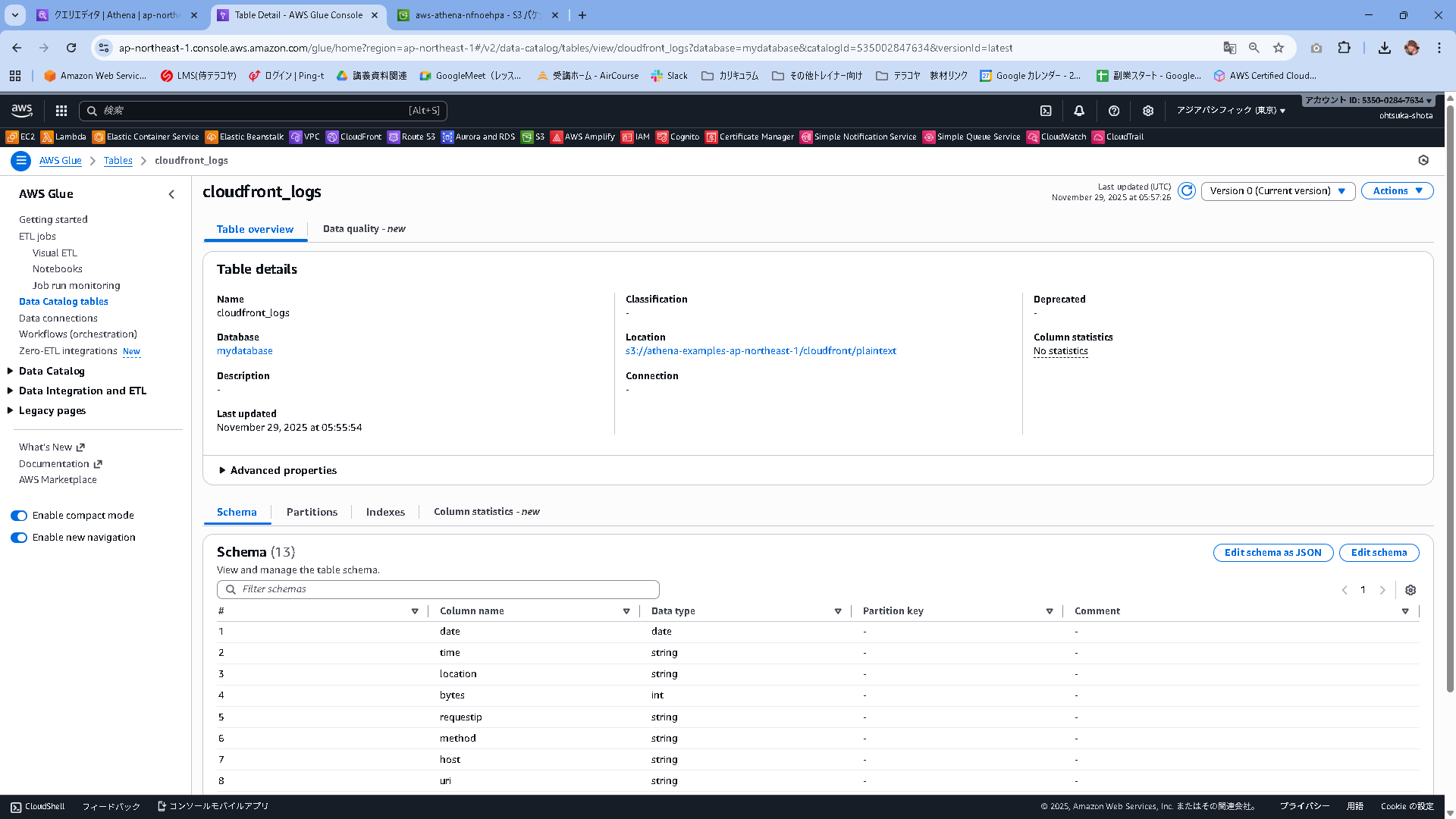
このタイミングでGlueを見てみると、Athenaで作成したデータベーステーブルと、AWS公式のS3に対して紐づけがされていることがTable detailsから見て取れると思います。
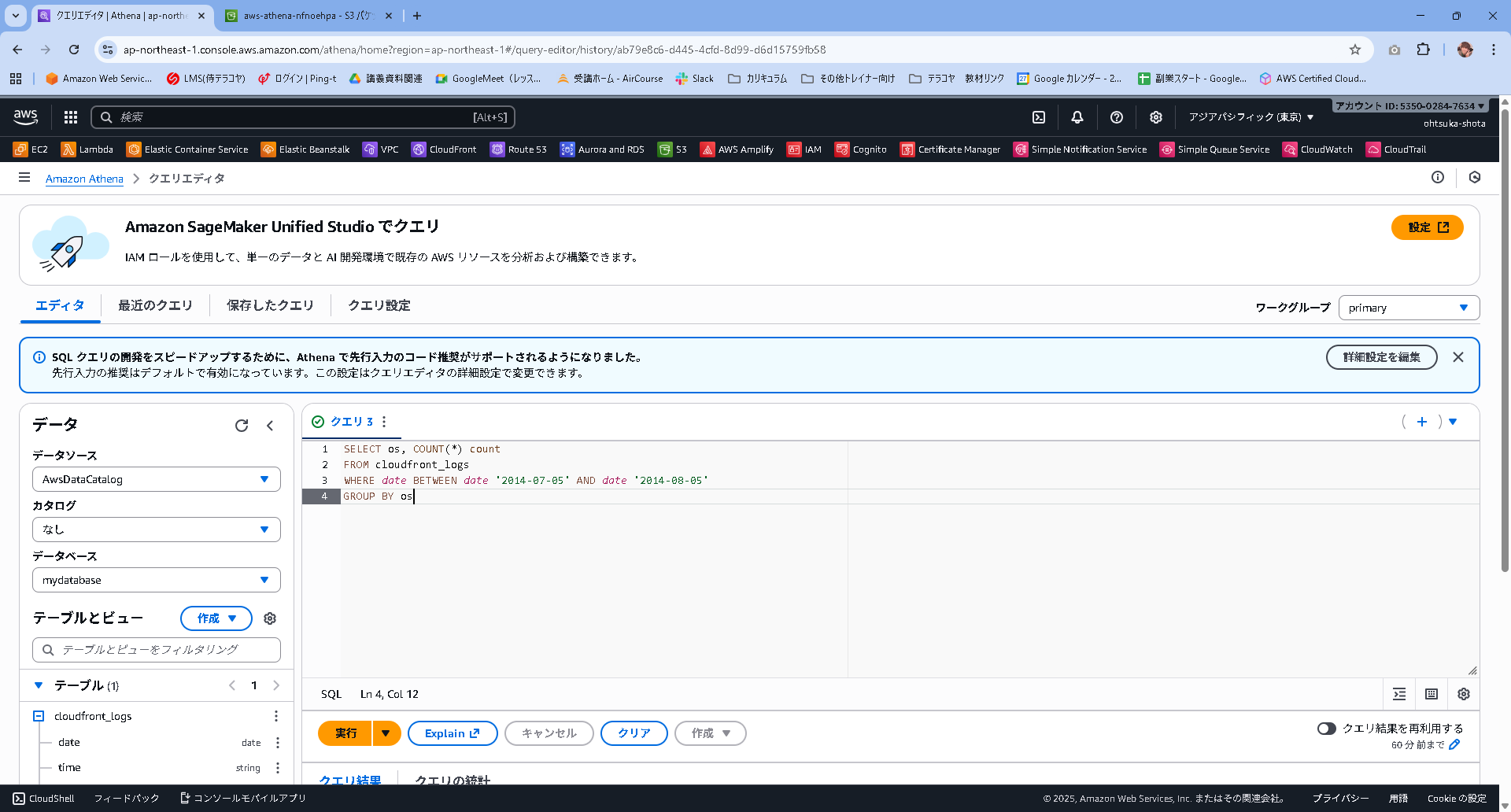
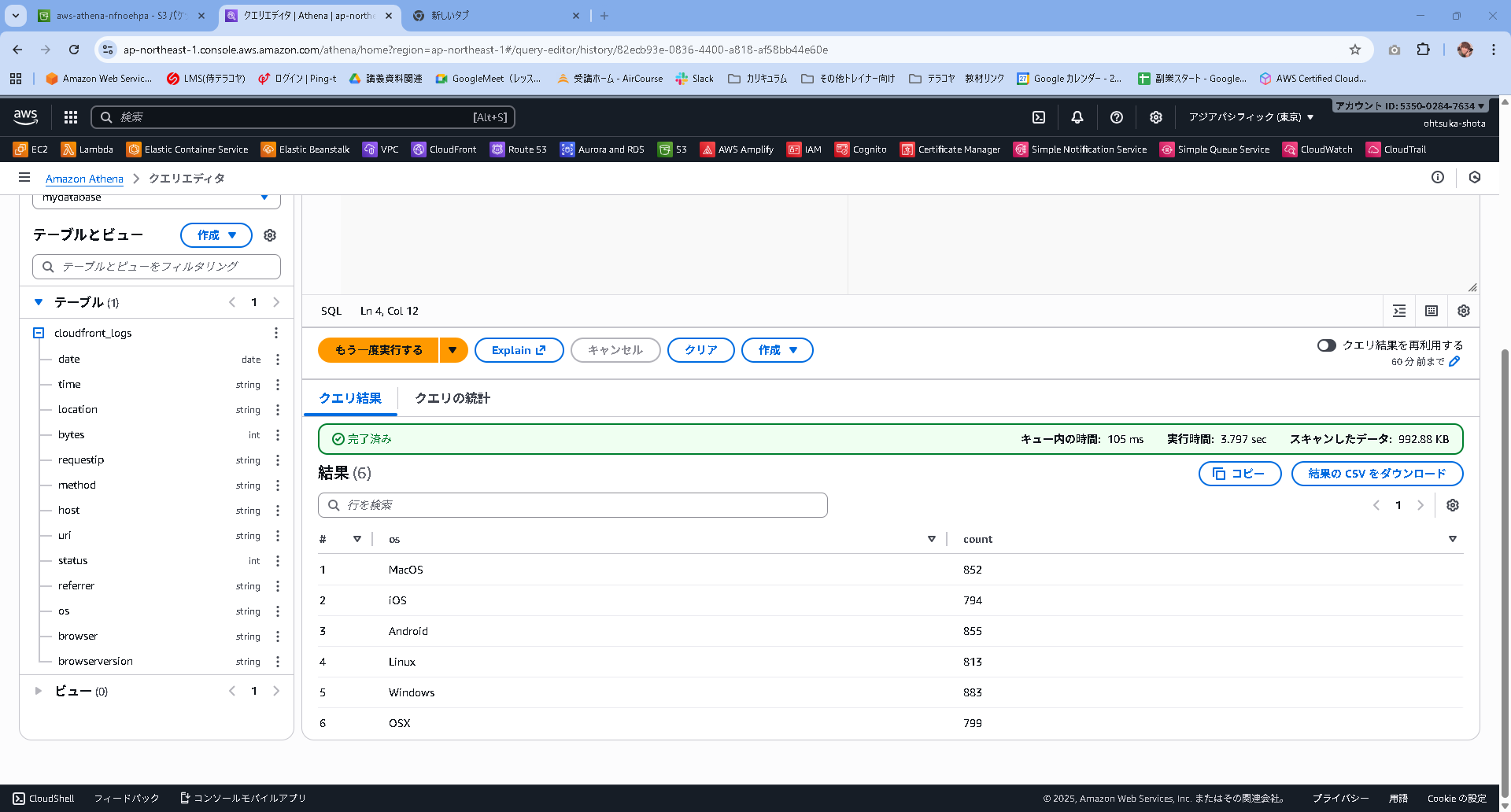
以下のクエリを投げてみます。
SELECT os, COUNT(*) count
FROM cloudfront_logs
WHERE date BETWEEN date '2014-07-05' AND date '2014-08-05'
GROUP BY os
クエリの結果が返ってくるとおもいます。
これはAthenaがGlue経由でAWS公式のS3に問い合わせに行った結果ですね。
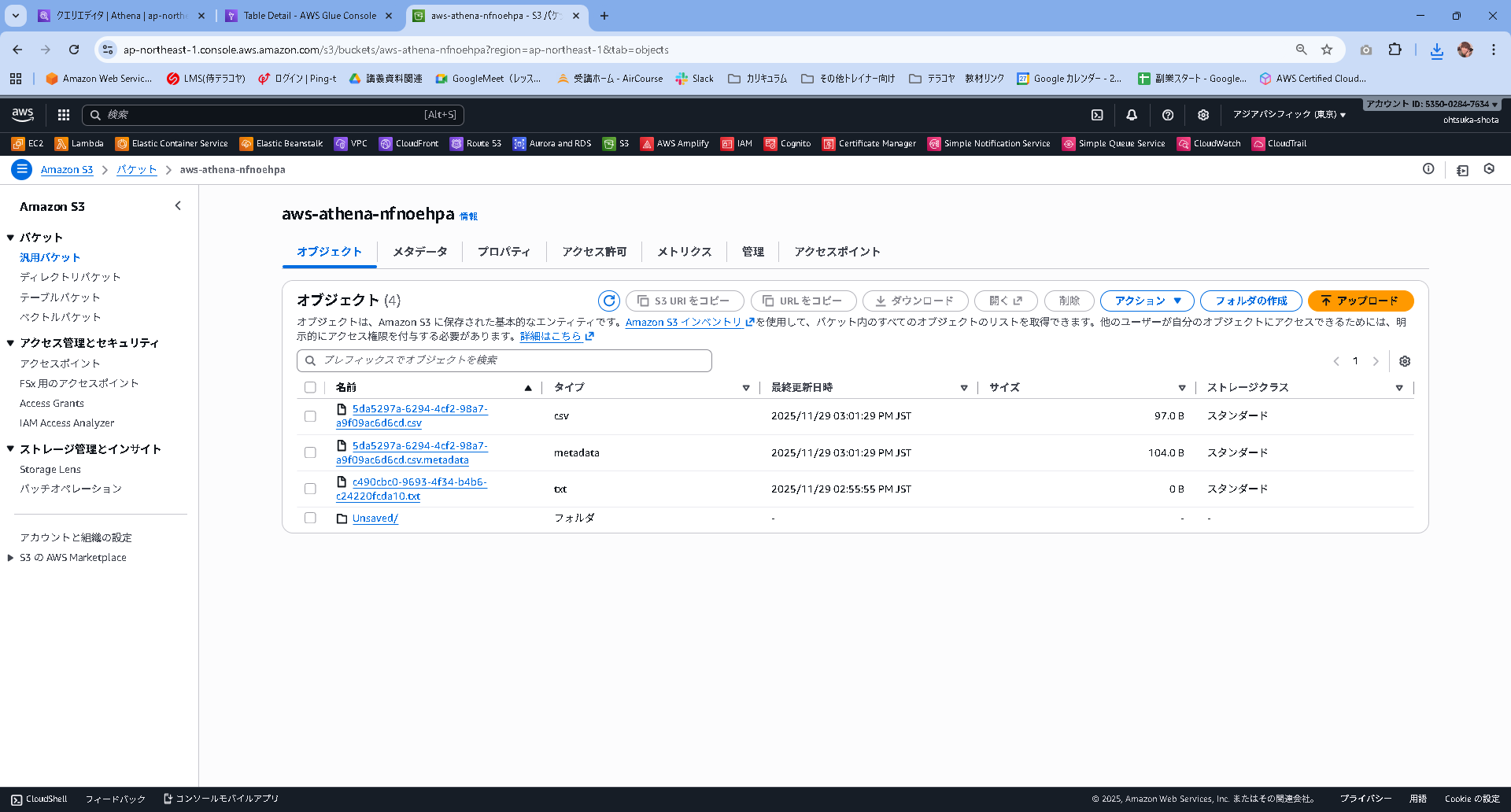
自分が作成したS3を見てみると、新しいファイルが作成されていると思います。
csvの中身は以下となっており、クエリの結果であるとわかります。
"os","count"
"Linux","813"
"Windows","883"
"OSX","799"
"iOS","794"
"Android","855"
"MacOS","852"
疑問に思ったこと(AIとの会話)
Q1.AthenaってS3をDB的に使えるようになるものだと思いますけど、それのメリットって何ですか?
A1.
. データの「ロード(取り込み)」が不要(ETLレス)
これが最大のメリットです。通常のデータベースでは、データを分析する前に「データをDBにインポートする時間」と「事前の定義」が必要です。
しかしAthenaの場合、S3にログファイル(CSVやJSONなど)を置いた瞬間から、すぐにSQLで検索が可能になります
一般的なデータベース(RDSやRedshift)は、サーバーを起動しているだけで時間あたりの料金が発生します(使っていなくてもお金がかかります)。
Athenaは**「クエリを実行した時」かつ「スキャンしたデータ量」に対してのみ**課金されます(例:1TBあたり5ドル
データベースにはディスク容量の上限があり、増やすには手間やコストがかかります。Athenaはデータの実体がS3にあるため、ストレージ容量を気にする必要がありません。数GBからペタバイト級まで、同じやり方で分析できます
「DBのバージョンアップ」「ディスク容量の拡張」「メモリのチューニング」といったインフラ管理作業が一切不要です
Q2.Cloudwatch LogsのInsightとかじゃだめですか?役割がかぶっているような・・・
A2.
CWLIは非常に優秀ですが、大量のログを扱う場合に以下の問題が発生します。
保存コストが高い: CloudWatch Logsにログを保存し続けるコストは、S3に保存する場合に比べて約10倍以上高いです(リージョンによりますが、S3標準クラスと比較して)。
取り込みコストがかかる: CloudWatch Logsにログを転送(Ingest)するだけで料金が発生します。
クエリ言語が独特: SQLではなく独自のパイプ記法(| filter ... | stats ...)を使うため、データ分析担当者(非エンジニア)には敷居が高い場合があります
ケースA:CloudWatch Logs Insightsを使うべき時
「さっきアラートが鳴った! エラーログを見たい!」という場合です。
S3への転送を待っていられない緊急時や、サーバーレスなログのリアルタイム監視にはCWLIが最強です
ケースB:Athenaを使うべき時
「先月のアクセスログを集計して、ユーザーの動向レポートを作りたい」あるいは「1年前のセキュリティ監査ログを出せと言われた」という場合です。
これをCW Logsに残しておくとコストが膨大になるため、古いログはS3へ退避(エクスポート)し、Athenaで安価に分析します