この記事は MLSE Advent Calendar 2019 23日目の記事です。150 Successful Machine Learning Models: 6 Lessons Learned
at Booking.comという論文がありまして、世界最大のホテル予約サイト Booking.com が、機械学習を実ビジネスで活用していく上で学んだ教訓がまとめられています。
今回はこの論文を眺めながら、受託分析の会社に10年身をおいている自分の経験を振り返り、しみじみしたいと思います。たぶん、こういう記事も役に立つ人がいるハズ。。なお、論文自体の日本語での解説はこちらのスライドを御覧ください。
All model families can provide value
Booking.com では、様々な場面で機械学習モデルを使っていますが、どれもちゃんとビジネス的な価値を出していますよ、というお話。
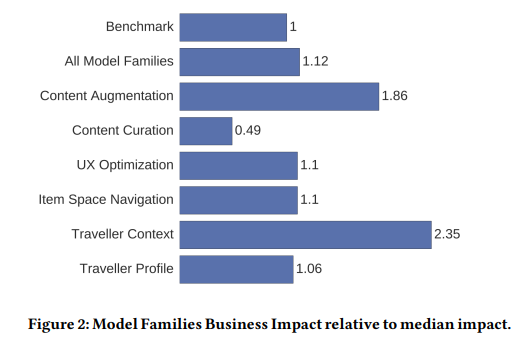
上図は、機械学習プロジェクトを6つのカテゴリに分類し、各分類ごとにBooking.comが決めた指標にどの程度貢献があったのかを示したものです。
- Traveller Preference Models: 行き先や日程などについて、どれくらい柔軟に考えているか(こだわっているか)推定するモデル
- Traveller Context Models: カップルなのか、家族なのか、車で近くに行きたいのか飛行機で遠くに行きたいかなどのコンテクストを推定するモデル
- Item Space Navigation Models: ユーザーがアイテムを
- User Interface Optimization Models: フォントサイズなどのUIを最適化するモデル
- Content Curation: レビューなどの情報を集約して提示するモデル
- Content Augmentation:
指標は解きたい問題毎に異なるので、ベンチマークを用意して、そこからの相対的な値(各カテゴリ毎にmedianをとっている)になっています。ベンチマークは、ある一定期間の間に実施された改善プロセス(ここには機械学習によるものもよらないものも含まれる)による効果です。どのカテゴリも正の値となっているので、各指標に対してプラスの効果があったことがわかりますし、Content Curation をのぞいて、ベンチマークよりも良い結果となっているようです。ただ、ベンチマークの詳細がわからないし、この結果をもって「機械学習がすごい」とはならない気がします。
下図は、目的地レコメンド機能の改善の履歴(上から施策の実施順に並んでいる)を表してます。
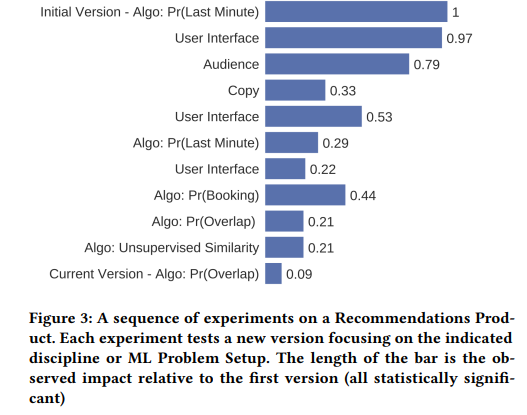
このように、各施策の指標が定義されていて、どの施策でどれだけ効果があったのかわかるようになっているというのは素晴らしいと思います。広告系の案件では、Booking.comと同じように効果をモニタリングできるようになっていて、改善のループをまわせるようになっていることも多いですが、それ以外の分野では、あまり多くないように思います。理由としては、データ収集の困難さなどがありそうです。また、そもそも受託分析だとスポットで入ることも多く、その場合は改善のループを回し続けるというよりは、その中の1つを実施するという形になりやすいというのもあるかもしれません。
MODELING: OFFLINE MODEL PERFORMANCE IS JUST A HEALTH CHECK
モデルの精度(オフライン評価)と実際の(ビジネス上の)価値は別物だよ、というお話。
下図は、各モデル毎に横軸にオフラインでの評価指標の改善幅、縦軸にコンバージョンレートの上がり幅をプロットしたものです。
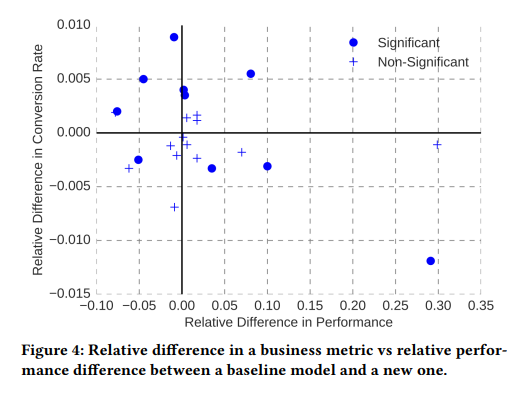
オフラインでの評価指標と実際のコンバージョンレートの上がり幅にはあまり相関がないのがわかります。
これは受託分析でもよく起こることです。オンラインで評価するのは本当に大事。レコメンデーションはわかりやすい例で、弊社のブログでも取り上げています。事前に入手できるデータは、基本的に機械学習を用いた施策を実施していない状態のもので、施策を実施した場合のデータは訓練に使えません。機械学習は、ざっくりいってデータに潜むパターンを見つけるものなので、訓練データに含まれない事象は予測できません。画像認識による不良品除去のように、ビジネス上の価値がモデルの精度から直接的に計算できる場合は問題になりませんが、レコメンデーションの場合、機械学習による予測結果をもとに商品を提示したときに人がどのように行動するか、というデータがないので、実際に使ってみるまでは適切な評価ができません。
レコメンデーションのように、すべてがオンラインですむ場合は、A/Bテストの機能をつかって継続的に評価できますが、それ以外の場合は、PoCと実地検証のフェーズを分ける事が多いです。PoCではあくまでモデルの精度を確認し、実地検証では、ビジネス上本当に価値があるかを検証します。不良品除去の例で言えば、PoCで「不良検知のモデルの精度がxx%であり、作業員の方の精度yy%と同程度以上である」というのを確認し、実地検証の段階ではプロトタイプをつくって実際に工場で使ってもらいます。
あと、ちょっと話がずれるかもしれませんが、PoCの段階で入手できるデータが、本番と異なるようなケースもあります。例えばクライアントが研究所や先行開発の部署で、社内事情等で実データを使えない場合です。また、機密性の高い情報のため、本番データは社外に出せないような場合もあり、受託特有のもどかしさを感じることもあります。
MODELING: BEFORE SOLVING A PROBLEM, DESIGN IT
問題設定フェーズでは、ビジネスケースやコンセプトから、機械学習の問題への落とし込みを行います。どのような問題に落とし込むかがかなり重要で、良いお年込み方法はすぐに思いつくようなものではないことも多い、という話。
受託分析では、まさにこの問題設定フェーズが重要ですし、実は実際の分析フェーズ以上に分析官が力を発揮するところです。よくあるのは、はじめは完全な自動化を目指しているが、実は一部分の自動化のほうが効率的なケース。
例えば品質検査や仕分けをAIに置き換えて、人件費を削りたいという話を聞くことがありますが、その場合、人間の精度を超える(実際には人間の精度は計測されていないことが多く、100%をめざしたくなる)までPoCが続いてしまうことになります。完全な自動化は放棄して作業員さんの負荷軽減を目指すと、例えば精度が50%でも意味のあるものになることがあります。
そんなわけもあり、このフェーズは基本的に分析官とビジネスサイドの人間、クライアントが一緒に取り組むことになりますが、分析官以外の人間が機械学習でどれくらいのことができて、どれくらいのことができないのか、勘所を掴んでいること、クライアントは必要に応じて、実際のユーザーとなる現場の方を巻き込むなどして、本当のニーズ・価値のありそうなことを引き出すのが重要になります。また、サンプルデータを受領して簡易的な分析をすることで、勘所をつかむこともよくやります。
Booking.com では、以下のような観点・ヒューリスティクスを問題設定に利用しているようです。
- Learning Difficulty(学習の難易度)
- Data to Concept Match(ビジネスケース・コンセプトがあったデータが得られているか)
- Selection Bias(選択バイアスの有無)
DEPLOYMENT: TIME IS MONEY
レイテンシは重要だよ、というお話。
よく言われることですが、レイテンシが増加するとコンバージョンレートが下がるため、高精度で重いモデルよりも軽量でほどほどの精度のモデルのほうが、良い結果となることがあります。
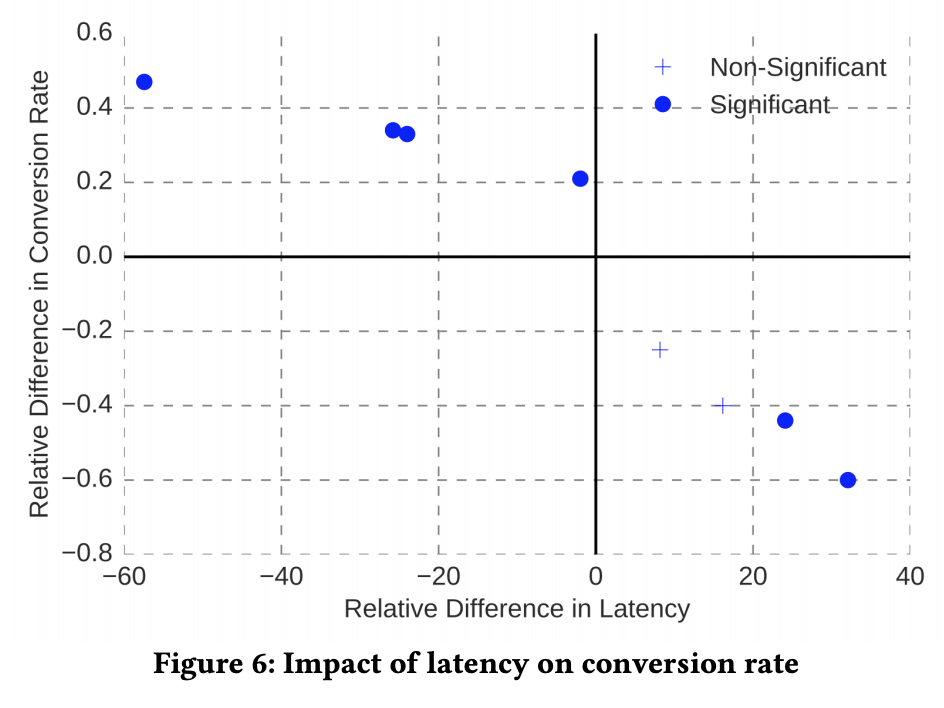
Booking.comでは、この問題に対応するため、以下のような取り組みをしているようです。
- 分散処理
- 高速な、独自実装の線形モデル
- パラメータの少ないモデルの利用
- 結果のキャッシュと、事前学習
- バルク処理
- 特徴量の変換の簡略化
実際の案件だと、そもそも論として都度推論する必要のない場合があります。例えばレコメンデーションで、直前の行動が説明変数に入っていないケースだと、前夜にバッチ処理で全アクティブユーザーに対するレコメンドリストを生成してKVSにいれておき、推論時には単にユーザーのIDで検索するだけ、というような実装をすることがあります(実際には、後処理として簡単なフィルタ処理をすることで、動的に推論しているように見せることもできます)。
別のケースでは、埋め込みを事前に訓練しておいて推論時には内積を取るだけ(実質線形回帰になっている)、といったように、モデルの一部分を事前に実行しておき、推論時には必要な処理だけを行う(もしくは近似処理をおこなう)ようなこともよくやります。
MONITORING: UNSUPERVISED RED FLAGS
サービングしているのであれば、モニタリングは必須だけど、つなに正解データが入手できるわけじゃないぞ、というお話。以下の2つの状況について述べ、Response Distribution Chart (RDC)をベースにしたヒューリスティクスを使っているようです。
- Incomplete feedback(不完全なフィードバック)
- Delayed feedback(フィードバックの遅延)
不完全なフィードバックやフィードバックの遅延はいろいろなところであわわれます。広告レポートとかだと、コンバージョンの値が徐々に埋まっていったり、コンバージョンの定義が媒体によって違ったり。適切に扱えばよいといえばよいのですが、つらい。あとは単純に画像分類するようなウェブアプリでも、提示結果をユーザーが修正してくれるような仕組みになっていない限りは、新たな正解ラベルは蓄積されないので注意が必要です。モデルを改善していきたいのであれば正解ラベルをどうやってためていくかを始めに考えておかないと「あれ?」ってなります。正解ラベルは貯められるものだと思いこんでPoCしてみたけど、「正解ラベルはPoCのために一生懸命我々が手で作りました。」みたいなのは普通に発生するし、どう考えても我々が考慮しておかないといけないポイントなので注意。
EVALUATION: EXPERIMENT DESIGN SOPHISTICATION PAYS OFF
A/Bテスト(Randomized Controlled Trials)も結構やっかいですよ、というお話。
単純にランダムに分けて済む時もあれば、済まない時もあります。
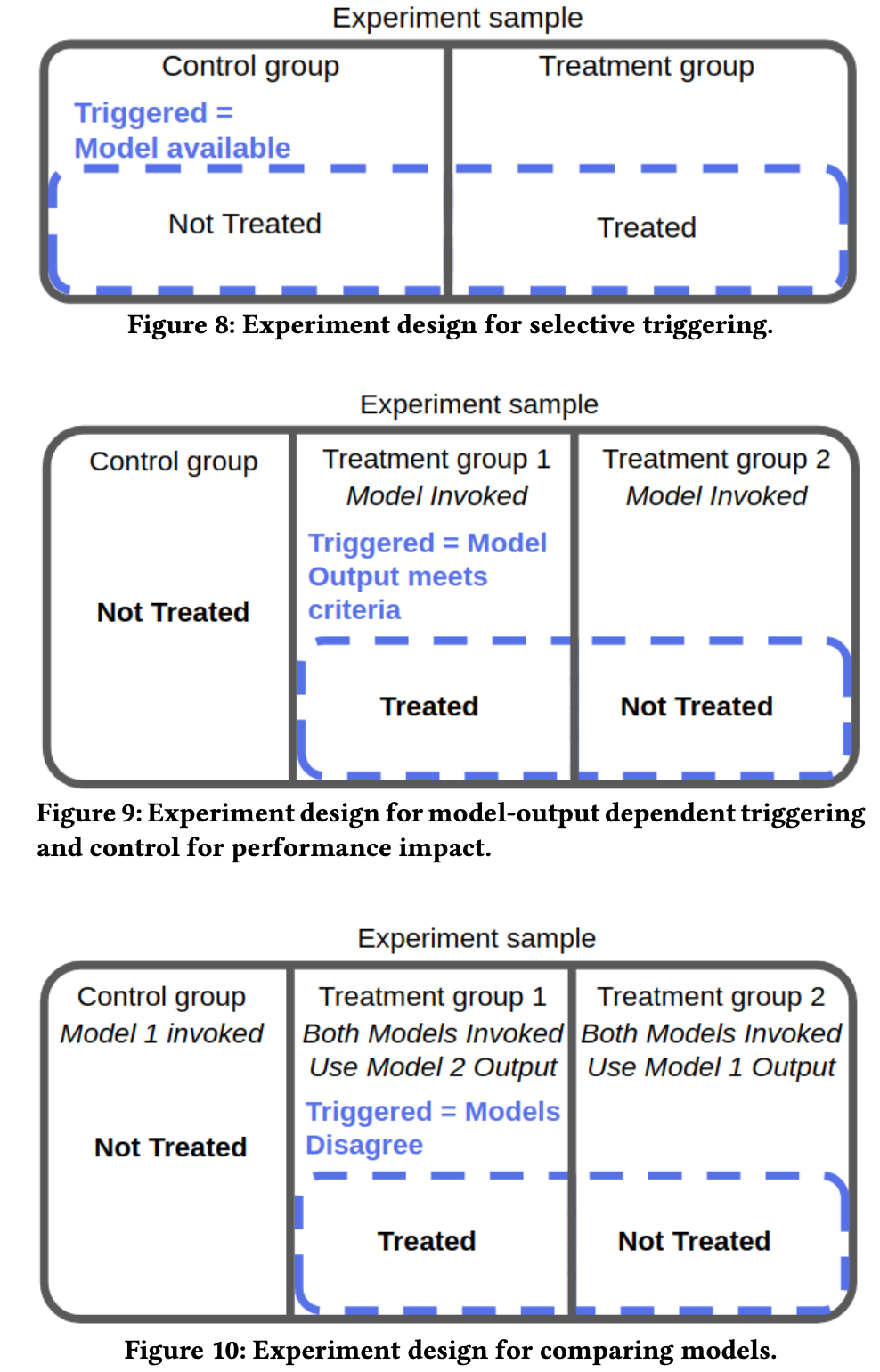
少し変わった例として、オンラインだとユーザー単位で施策を分ければよいことが多いですが、オフラインでA/Bテストをしようとすると難しい場合があります。例えば、オンラインと違ってユーザーごとに施策をかえるのが難しかったり、ユーザー個別のデータを収集できなかったりすことがあり、施策の振り分けの単位が店舗や営業所単位となることがあります。すると、営業所の数はユーザーほど多くないため、単純に乱数で振り分けると偏りが生じてしまうので、如何に偏りを減らすかという工夫が必要になったりします。データの量や入手のしやすさ、施策うちやすさなど、オンラインは恵まれているなと思います。
まとめ
しみじみしました。