S3 基礎(put/get/delete/list)
Lambda+S3はAWSサーバレスで頻繁に利用される。
文字列・CSV・JSON・バイナリ・設定ファイル...S3に配置して処理する。
ただし、boto3のS3APIは”つまずきポイント”多数あり、理解していないとデータ破損、ファイル取得ミス、prefix違いの事故が起きます。
1.ファイルアップロード(put_object)
➤サンプル
s3 = boto3.client("s3")
def put_text(bucket: str, key: str, text: str):
s3.put_object(
Bucket=bucket,
Key=key,
Body=text.encode("utf-8"),
ContentType="text/plain",
)
![]() ポイント
ポイント
-
Bodyはstrではなくbytes - 文字コードは必ずUTF-8指定(事故防止)
- ContentTypeを指定しないとブラウザがご解釈することも
→ PythonはstrをそのままS3に送れない。暗黙的に変換して送るため、想定外の挙動のならないため明示的に送ってあげる必要がある。またS3はバイナリストレージのため人が見てわかるようContentTypeを設定してあげる。
アンチパターン:文字列をそのまま入れる
s3.put_object(Bucket=b, Key=k, Body="hello")
- python内部で勝手にencodeing → AWS側の仕様変更で壊れる可能性が潜む
2.テキストファイル読み込み(get_object)
➤サンプル
def get_text(bucket, key) -> str:
resp = s3.get_object(Bucket=bucket, Key=key)
return resp["Body"].read().decode("utf-8")
==============================================
import gzip
def get_text(bucket, key) -> str:
resp = s3.get_object(Bucket=bucket, Key=key)
raw = resp["Body"].read()
if resp.get("ContentEncoding") == "gzip":
raw = gzip.decompress(raw)
return raw.decode("utf-8")
![]() ポイント
ポイント
- BodyはStreamingBodyという型でファイルの中身を持っているわけではなく、データを少しずつ読みだせ、一気にメモリに載せない。取り出すにはread()で取り出す
- decodeしないとStreamingBody.read() の結果は 必ず bytes
- レスポンスがgzip圧縮されてる場合にはdecodeの前に解凍が必要
アンチパターン:Bodyをそのまま返す
content = resp["Body"]
この場合、この処理時点ではエラーも出ず、テキスト、Jsonなど期待した結果は入っておらず
StreamingBodyのオブジェクトが入っているだけで取り出したファイルを処理する際エラーとなる。
3.JSON読み書き
JSON 保存
import json
def put_json(bucket, key, obj):
s3.put_object(
Bucket=bucket,
Key=key,
Body=json.dumps(obj).encode("utf-8"),
ContentType="application/json",
)
JSON 読み込み
def get_json(bucket, key):
resp = s3.get_object(Bucket=bucket, Key=key)
text = resp["Body"].read().decode("utf-8")
return json.loads(text)
アンチパターン:json.loads()にbytesを直接渡す
data = json.loads(resp["Body"].read())
pythonはbytes → JSONパースできない
![]() json.loadsって
json.loadsって
JSON形式の文字列(str)を、Pythonの辞書・リストに変換する関数。
例:'{"a": 1}' → {"a": 1}
S3 の「なんちゃってフォルダ構造」
S3はフォルダがないオブジェクトストレージ
見た目は階層的だが、中身はただのキー名
その結果実装で様々な事故に...
- prefixが曖昧で関係ないファイルまでヒット
- listが最大1000件までしか返さない
- フォルダのつもりで末尾 / の扱いをミスる
1.基本 list_objets_v2(最大1000件まで)
resp = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
contents = resp.get("Contents", [])
![]() ポイント
ポイント
-
Contentsが0件の時S3はキー自体を返さないためKeyErrorになる
→ 対策: .get("Contents", []) は実務必須の安全策。 - S3 の LIST API は 最大 1000 件までしか返さない
→ 対策: 1000 件超は NextContinuationToken を使って繰り返し取得
2. 1000件を超える場合(必須:ContinuationToken)
def list_all(bucket, prefix):
token = None
keys = []
while True:
params = {"Bucket": bucket, "Prefix": prefix}
if token:
params["ContinuationToken"] = token
resp = s3.list_objects_v2(**params)
for obj in resp.get("Contents", []):
keys.append(obj["Key"])
if resp.get("IsTruncated"): # まだ続きがある
token = resp.get("NextContinuationToken")
else:
break
return keys
やってることざっくり
- paramsの初期化
S3に渡すパラメータを作る。 - s3.list_objects_v2(**params)
prefixに一致する最大1000件のリストが返る。 - .get("Contents", [])
prefixに一致するオブジェクトが0件の時Contensキーを返さない - if resp.get("IsTruncated")
IsTruncatedはbool型(True / False)で返ってくる
Trueで1000件以上あり、レスポンスが途中まで、False=これで全部
![]() prefixはフォルダっぽい検索だけど、S3はあくまで文字列の一致
prefixはフォルダっぽい検索だけど、S3はあくまで文字列の一致
アンチパターン:# Prefixのファイル全部取りたい!!
resp = s3.list_objects_v2(Bucket=b, Prefix=p)
keys = [c["Key"] for c in resp["Contents"]]
![]() 1000件以上あると永遠に残りが取れない
1000件以上あると永遠に残りが取れない
Prefixの罠
何度も書いているが、S3のフォルダは実態ではなく「ただのキー名の一部」
dir1/file1.txt
dir1/file2.txt
dir10/file3.txt
こんな感じの時prefixを"dir1"で検索するとdir10までヒットしてしまう。
1.末尾スラッシュ("/")これ絶対
正しい例
prefix = "dir1/"
まずい例:
prefix = "dir1"
こうすることでdir1に絞りdir10,dir100がヒットしない。
2.「/」位置ずれ
S3内のキー:data/2025/...というのがあるとして
date = "2025/"
prefix = f"data/{date} # NG
prefix = f"data/{date}/ # OK
この場合NGパターンは一切ヒットしない。
OKパターンのようにすることで必ずフォルダ風の prefix になる
S3はホントに「キー文字列一致」の世界で
1文字ズレただけで見つからない or 取りすぎの事故発生
3.S3でフォルダを作る方法
AWSのコンソールでフォルダ作成から「my-dir」を作成してみる
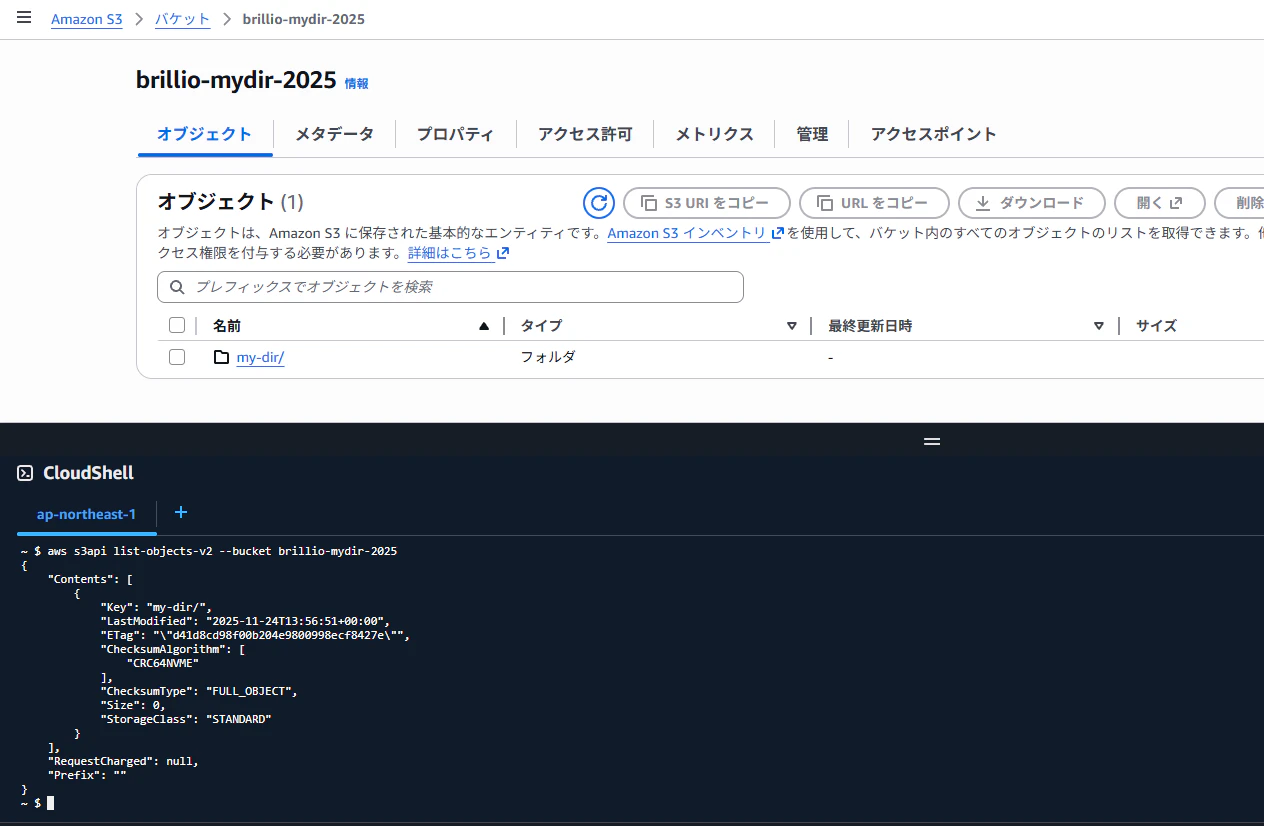
ん?フォルダの概念はないのでは![]()
実態は、ただのキー(文字列)であったフォルダではない。
フォルダを表現するための0バイトオブジェクト
なぜ知っておく必要があるか
狙った操作が正確に行えず事故の原因となってしまう可能性があるので知識として