概要
kerasでblackjackやってみた。
gymのblackjack-v0やってみた。
kerasで強化学習やってみた。
写真
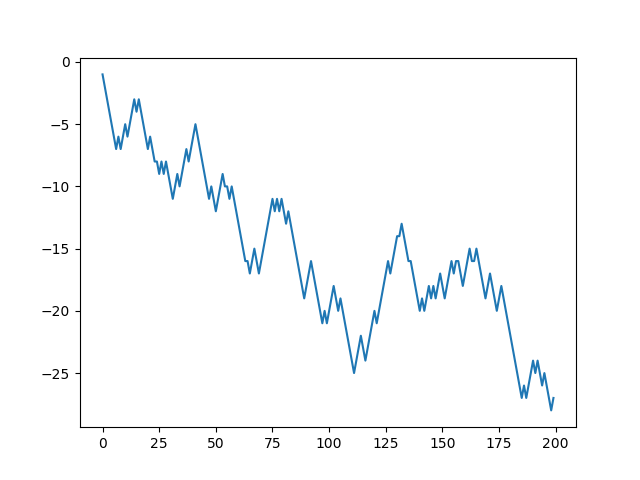
200回で-27。負けてるけど、勝ち進んだ時もある。
説明
ブラックジャックのルール
カードの数え方
「2~10」はそのままカウント。
「J、Q、K」の絵柄カードは全て「10」とカウント。
「Joker」は、ない。
「A」”エース”は「1」か「11」として任意にカウント。
ブラックジャックの用語
Hit(ヒット)
カードを1枚引く。
Stand、Stay(スタンド、ステイ)
カードを引かない。
Bust、Busted(バスト)
カードの合計が「22」以上。通称ブタ。
BlackJack(ブラックジャック)
最初に配られた2枚のカードが「A」+「10、J、Q、K」の組み合わせ。
最高の手(ハンド)であり、「ナチュラル21」と呼ばれる。
Up Card(アップカード)
ディーラー自身に初めに配られる2枚のカードの内1枚をプレイヤー全員に見えるよう表にして置くカード。
勝敗
BlackJackの場合
あなたがBlackJackで勝った場合、配当は1.5倍となります。
ディーラーよりも「21」に近い場合
1倍の配当となります。
3枚以上のカードでの「21」はBlackJack(ナチュラル21)に対しては「負け」です。
引き分け(プッシュ)
あなたとディーラー双方がBlackJack、もしく「21」以下の範囲で同点の場合は「引き分け」。
ディーラーとあなた双方がバストの場合
ディーラーとプレイヤー双方がバストした場合は、ディーラーの勝ちとなります。
ゲームの進行
プレイヤー全員がベットを終えるとディーラーはプレイヤー全員とディーラー自身にカードを2枚ずつ配ります。
この時ディーラーの2枚のカードの内1枚は表にしておきます。
プレイヤーはディーラーのアップカードからディーラーの最終的なハンドを予想してヒット、ステイを選択して最終的な自分の手(ハンド)を作ります。
プレイヤーはバストしない限り何回でもヒットできます。
プレイヤー全員が順番にハンドを作り終えたらディーラーはホウルカードをオープンして最終的なハンドを作り、各プレイヤーのハンドと比較して精算を行います。
gymのBlackjack-v0の場合
action
ヒット 1
ステイ 0
observation
ハンドの合計
ディーラーのアップカード
ハンドにエースがあるか
reward
勝ち 1
勝ち(blackjack)1.5
引き分け 0
負け -1
サンプルコード
import random
import gym
import numpy as np
from collections import deque
from tensorflow.contrib.keras.python.keras.models import Sequential
from tensorflow.contrib.keras.python.keras.layers import Dense
from tensorflow.contrib.keras.python.keras.optimizers import Adam, SGD, RMSprop
import matplotlib.pyplot as plt
class Agent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen = 1000)
self.gamma = 0.9
self.epsilon = 1.
self.epsilon_min = 0.01
self.epsilon_decay = 0.9
self.learning_rate = 0.1
self.model = self._build_model()
def _build_model(self):
model = Sequential()
model.add(Dense(24, input_dim = self.state_size, activation = 'relu'))
model.add(Dense(24, activation = 'relu'))
model.add(Dense(self.action_size, activation = 'relu'))
model.compile(loss = 'mse', optimizer = RMSprop(lr = self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma * np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs = 1, verbose = 0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
if __name__ == "__main__":
EPISODES = 200
env = gym.make('Blackjack-v0')
state_size = 3
action_size = env.action_space.n
agent = Agent(state_size, action_size)
done = False
batch_size = 32
score = 0
timestep = []
for e in range(EPISODES):
state = env.reset()
state = np.reshape(state, [1, state_size])
for time in range(200):
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
score += reward
reward = reward if not done else -1
next_state = np.reshape(next_state, [1, state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
if done:
print ("episode: {} score: {} epsilon: {:.2}".format(e, score, agent.epsilon))
timestep.append(score)
break
if len(agent.memory) > batch_size:
agent.replay(batch_size)
plt.plot(timestep)
plt.savefig("black7.png")
plt.show()
以上。