概要
ラズパイでkerasやってみた。
gymのcartpoleやってみた。
kerasで強化学習やってみた。
写真
サンプルコード
import gym
import numpy as np
import random
from tensorflow.contrib.keras.python.keras.models import Model
from tensorflow.contrib.keras.python.keras.layers import *
from tensorflow.contrib.keras.python.keras import backend as K
from collections import deque
import matplotlib.pyplot as plt
def randf(s, e):
return (float(random.randrange(0, (e - s) * 9999)) / 10000) + s;
def discount_rewards(r, gamma = 0.99):
discounted_r = np.zeros_like(r)
running_add = 0
for t in reversed(range(0, len(r))):
running_add = running_add * gamma + r[t]
discounted_r[t] = running_add
return discounted_r
def one_hot(index, categories):
x = np.zeros((categories, ))
x[index] = 1
return x
def loss(advan):
def f(y_true, y_pred):
respons = K.sum(y_true * y_pred, axis = 1)
policy_loss = -K.sum(advan * K.log(respons))
return policy_loss
return f
env = gym.make('CartPole-v0')
state = Input(shape = (4, ))
x = Dense(24)(state)
x = Dense(24)(x)
x = Dense(2)(x)
x = Activation('softmax')(x)
model_a = Model(state, x)
state = Input(shape = (4, ))
adv_input = Input(shape = (1, ))
x = model_a(state)
model_b = Model([state, adv_input], x)
model_b.compile(optimizer = 'adam', loss = loss(adv_input))
all_rewards = deque(maxlen = 100)
epsilon = 1
epsilonMinimumValue = 0.001
reward_trend = []
for i_episode in range(200):
observation = env.reset()
state_history, action_history, reward_history = [], [], []
for t in range(200):
env.render()
state_history.append(observation)
pred = model_a.predict(np.expand_dims(observation, axis = 0))[0]
if (randf(0, 1) < epsilon):
action = np.random.choice(len(pred), 1, p = pred)[0]
else:
action = np.argmax(pred)
if (epsilon > epsilonMinimumValue):
epsilon = epsilon * 0.999
observation, reward, done, info = env.step(action)
reward_history.append(reward)
action_history.append(one_hot(action, 2))
if done:
reward_sum = sum(reward_history)
reward_trend.append(reward_sum)
print (i_episode, "Episode finished with reward {} {:.2f}".format(reward_sum, np.mean(all_rewards)))
if reward_sum > 198:
reward_sum += 100
all_rewards.append(reward_sum)
adv = discount_rewards(reward_history)
state_history = np.array(state_history)
action_history = np.array(action_history)
model_b.train_on_batch([state_history, adv], action_history)
break
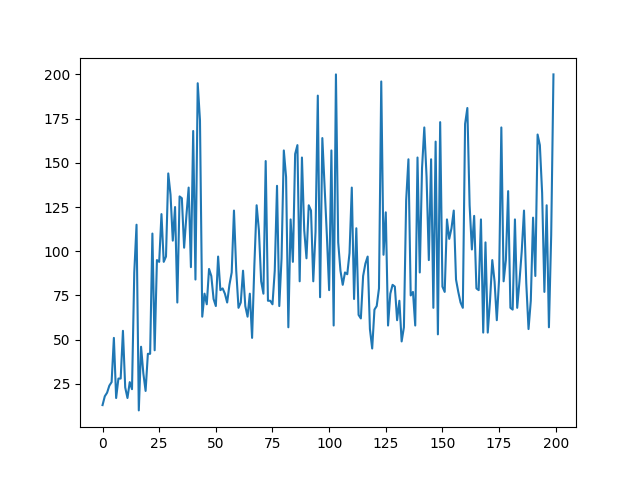
plt.plot(reward_trend)
plt.savefig("gym26.png")
plt.show()
結果
以上。