はじめに:スタースキーマの理論と実践
こんにちは、DX塾の大畑です。
この動画では、Power BIのサンプルデータ「Financial Sample」を使って、スタースキーマの理論と実践をステップごとに丁寧に解説していきます。
学習の目的
- 正規化の基本理解
- スタースキーマの構造と利点
- Power Queryによるディメンションテーブルの分割
- モデルビューでのリレーション設定
第二正規化と部分関数従属の理解
スタースキーマを実務で活用するには、まず データモデリングの基本 を押さえる必要があります。その中でも特に重要なのが、「第二正規化」と「部分関数従属」の理解です。
🔍 部分関数従属とは?
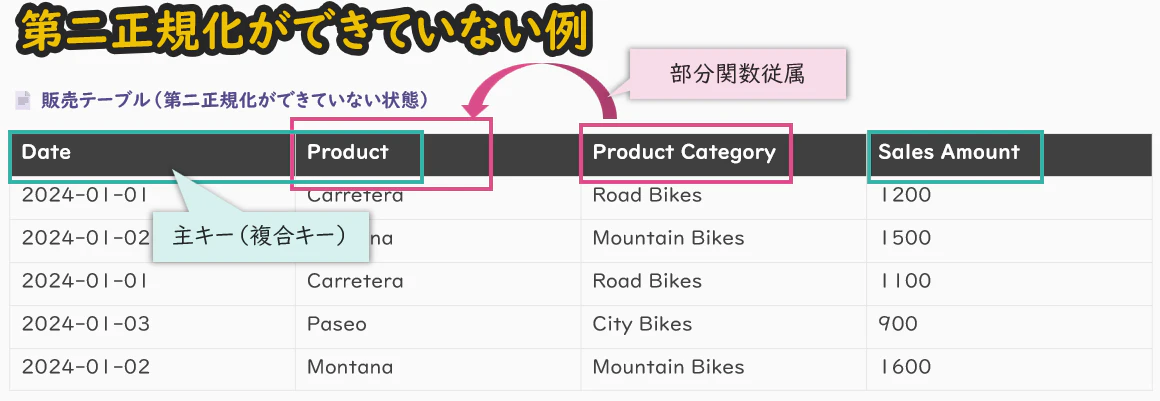
部分関数従属とは、複合主キーを持つテーブルにおいて、ある列が主キーの一部にのみ依存している状態を指します。
例:
以下の販売テーブルの主キーが OrderID + Product の場合、「Product Category」は「Product」によって一意に決まるため、主キー全体ではなく「Product」にのみ依存していることになります。
これは、第二正規化(2NF)に違反している状態です。
🎯 第二正規化の目的
第二正規化では、以下のような構造改善を行います:
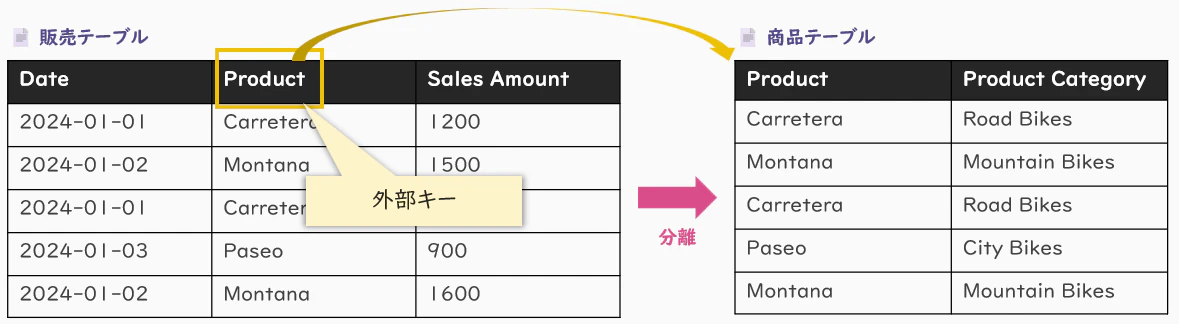
- 部分関数従属している列(例:Product Category)を 別テーブルに分離
- 元のテーブルには、外部キー(例:Product列)のみを残す
- 結果として、以下のメリットが得られます:
- 情報の重複を防止
- データの整合性を確保
- 保守性(メンテナンス性)が向上
🛠 スタースキーマ構築へのステップ
【追記】
コメントでご指摘いただいた説明不足について、補足いたします。
スタースキーマにおいて第二正規化の対象となるのは、ディメンションデータです。ファクトデータ(売上金額、利益、数量など)の列は、別テーブルに分割せず、1つのファクトテーブルにまとめるため、第二正規化の対象外となります。
その代わり、分析に適した粒度(例:時間単位 → 日単位)でデータを集約したり、ヘッダーテーブルと明細テーブルが分かれている場合は、それらを結合して1つのテーブルにするなどの対応が必要です。
この点については、別記事で改めて詳しく解説する可能性もありますが、まずはコメント欄をご参照いただければと思います。
【追記】終わり
第二正規化によって属性情報を整理することは、スタースキーマ構築に向けた 重要な準備ステップです。
部分関数従属のある列を分離し、意味ごとにディメンションテーブルとして再編成することで、 モデルの構造が明確になり、分析効率が向上します。
スタースキーマの構造と利点
スタースキーマとは、中心にファクトテーブルを置き、周囲にディメンションテーブルを放射状に接続する構造です。
Power BIでのデータモデリングにおいて、非常に有効な設計パターンです。
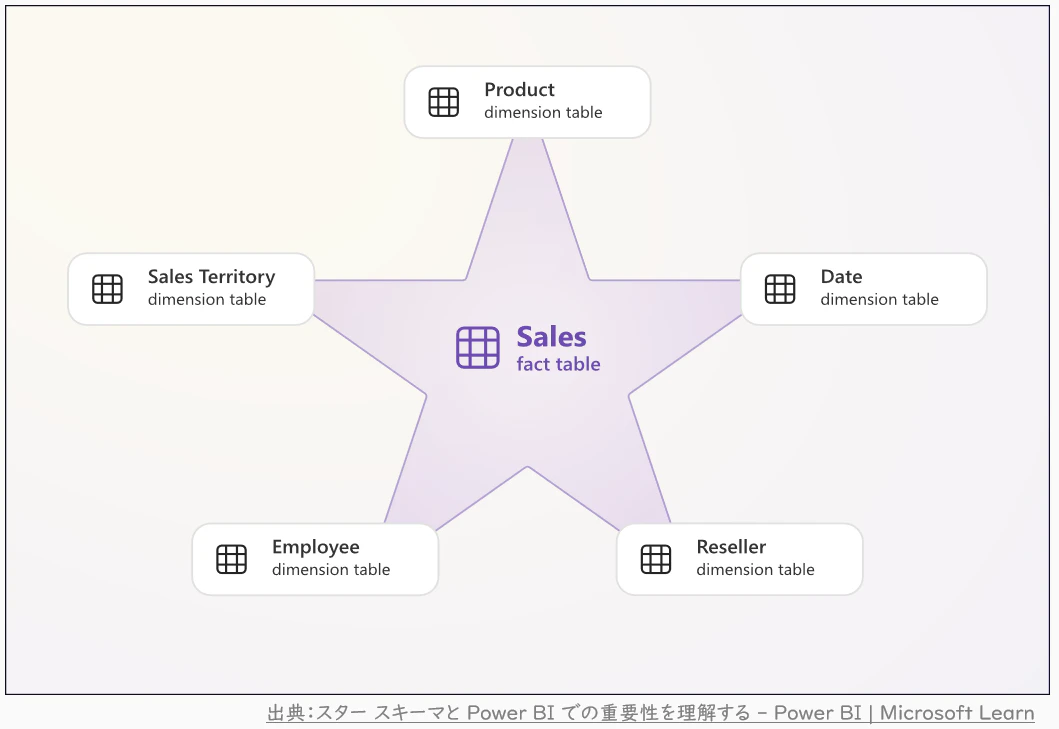
構造の例
- ファクトテーブル:売上金額、利益、数量などの数値情報
- ディメンションテーブル:日付、商品、地域、顧客などの分析軸
スタースキーマのメリット
- モデル構造が明確になる
- DAX計算のパフォーマンスが向上
- 商品別・期間別など、多様な切り口で柔軟に分析可能
実務への応用
販売テーブルをスタースキーマに再構築することで、Power BIの分析力を最大限に引き出すことができます。 構造の整理は実務でのデータ活用を加速させる鍵です。
スタースキーマ構築に向けた準備とデータ確認
スタースキーマを構築する前に、まずは データの構造と型を正しく把握すること が重要です。 今回使用するのは、Power BIに付属する「Financial Sample」データセットです。
Financial Sample に含まれる主な列
| 列名 | 説明 | データ型 |
|---|---|---|
| Segment | 顧客セグメント(例:Government、Enterprise) | 文字列 |
| Country | 国名(販売が行われた地域) | 文字列 |
| Product | 製品名 | 文字列 |
| Discount Band | 割引帯(Low、Medium、High 等) | 文字列 |
| Units Sold | 販売数量 | 数値 |
| Manufacturing Price | 製造原価 | 数値 |
| Sale Price | 販売価格 | 数値 |
| Gross Sales | 売上総額(販売数量 × 販売価格) | 数値 |
| Discounts | 割引額 | 数値 |
| Sales | 実売上(Gross Sales - Discounts) | 数値 |
| COGS | 売上原価(Cost of Goods Sold) | 数値 |
| Profit | 利益(Sales - COGS) | 数値 |
| Date | 販売日 | 日付 |
| Month Number / Name / Year | 月番号、月名、年(時系列分析用) | 日付 |
データ型の確認
- Date列:日付型
- Sales / Profitなど:数値型
- Product / Countryなど:文字列型
データ型が正しく設定されていないと、集計やリレーション設定が正しく機能しない可能性があります。
この準備を丁寧に行うことで、スタースキーマ設計がスムーズに進み、 Power BIでの分析の信頼性と柔軟性が大きく向上します。
ファクトテーブルとディメンションテーブルの分離
スタースキーマを構築するうえで重要なステップが、ファクトテーブルとディメンションテーブルの分離です。
ファクトテーブルとは?
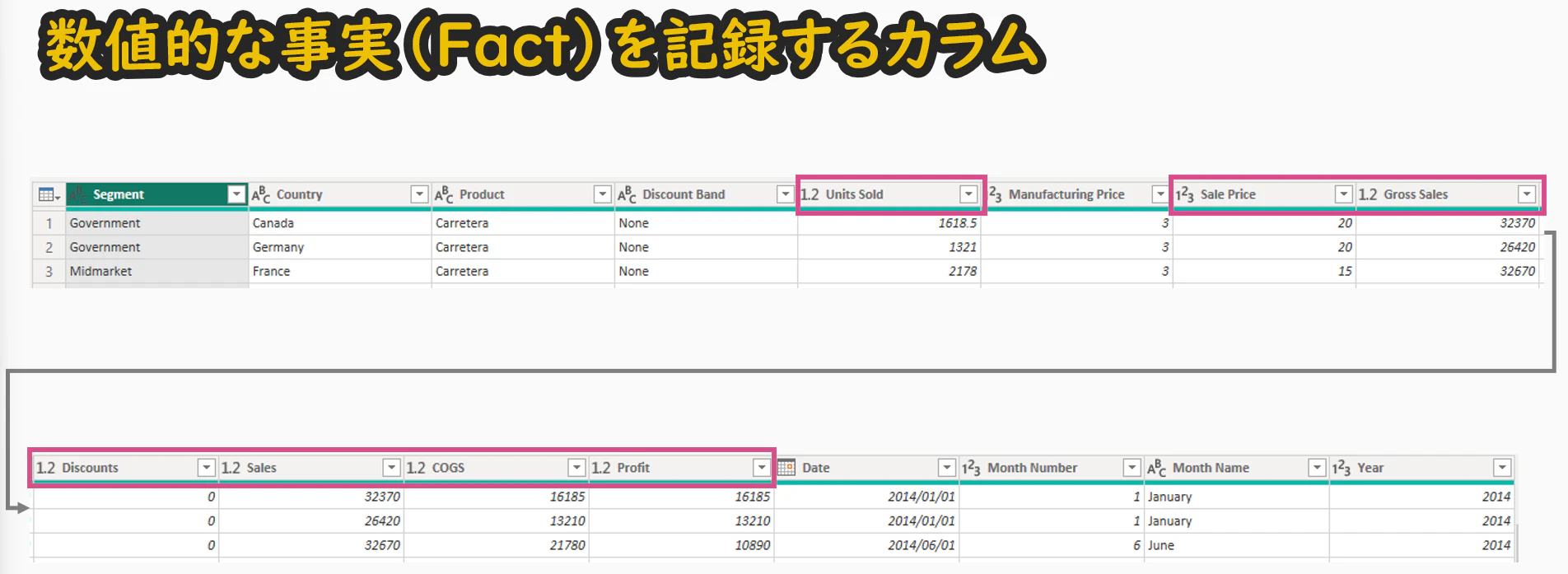
- 売上や利益、販売数量などの 数値的な事実(ファクト) を記録するテーブル
- スタースキーマの中心に位置し、分析の対象となる
ディメンションテーブルとは?
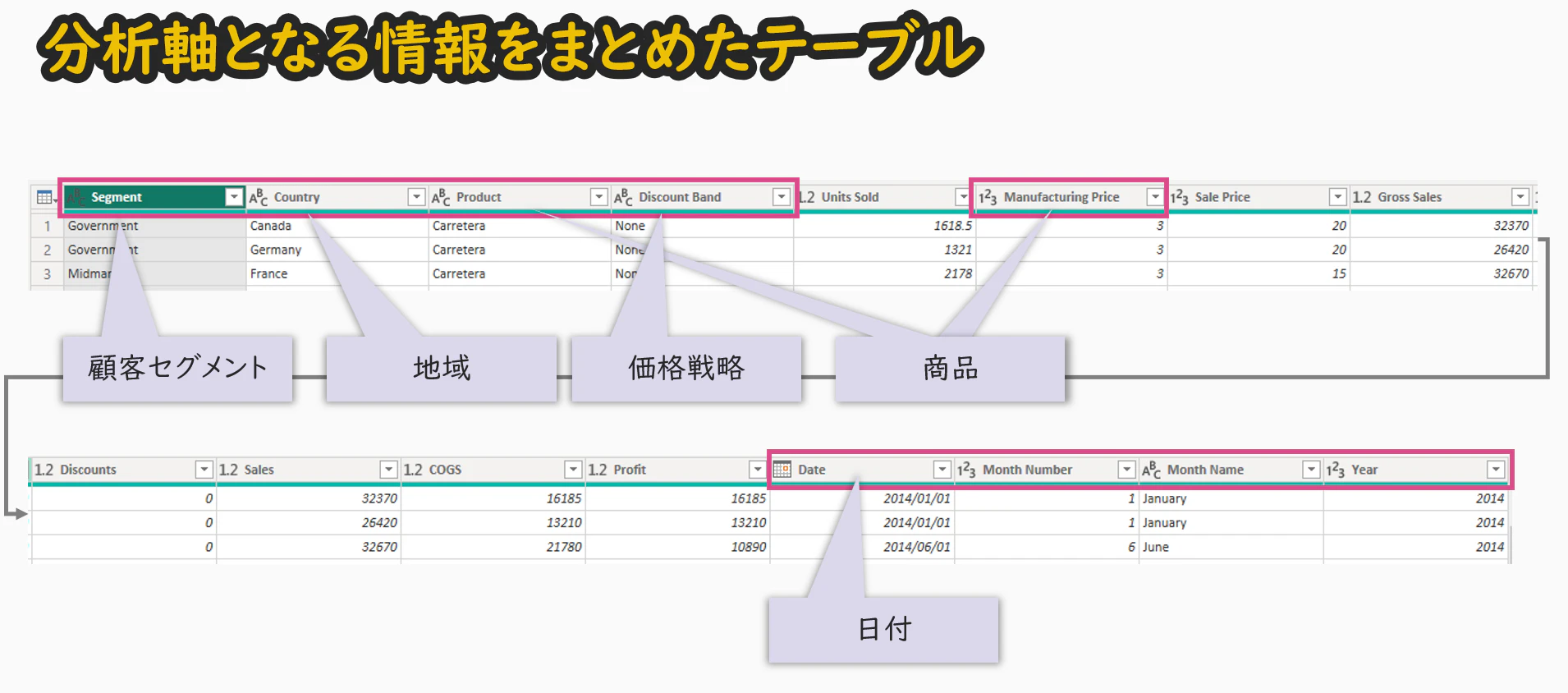
- 日付、商品、地域、顧客などの 分析軸となる属性情報 をまとめたテーブル
- ファクトテーブルの外部キーとして接続され、分析の切り口を提供
サンプルデータでの分類例
-
ファクトテーブルに残す列:
- Units Sold、Sale Price、Gross Sales、Discounts、Sales、COGS、Profit
-
ディメンションテーブルに分離する列:
- Segment(顧客セグメント)
- Country(地域)
- Product、Manufacturing Price(商品情報)
- Discount Band(価格戦略)
- Date(販売日)
設計のポイント
- 属性情報は 意味ごとに分けて整理
- 各ディメンションテーブルは ユニークな値を持つように整備
- モデル構造が明確になり、分析の柔軟性が向上
この設計により、Power BIでのスタースキーマ構築がスムーズに進みます。
Power Queryによるスタースキーマ構築手順
ここでは、Power BIのPower Queryエディターを使って、スタースキーマを構築する手順を解説します。
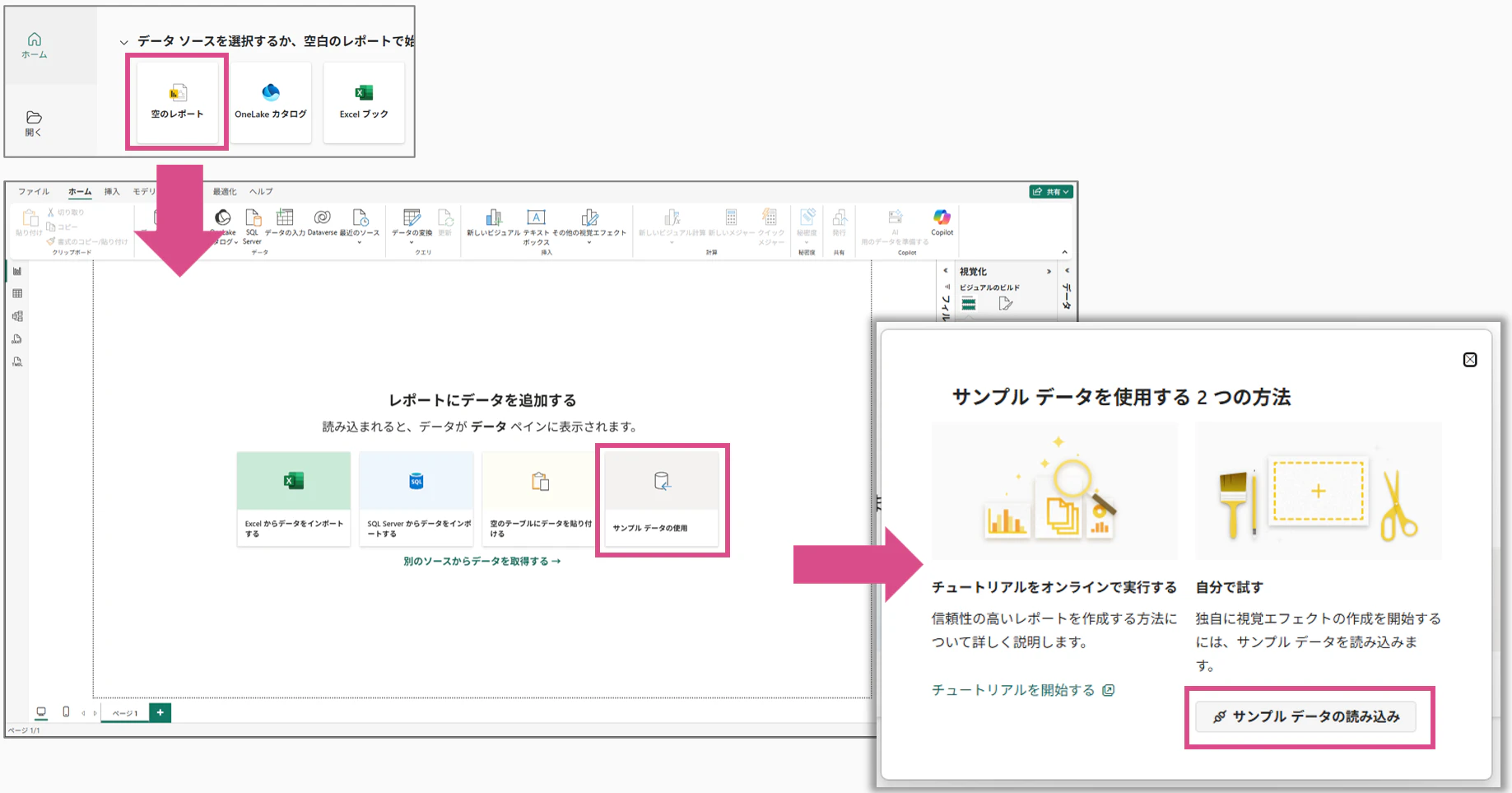
1. サンプルデータの読み込み
- Power BI Desktopを起動
- 「空のレポート」をクリック
- 「サンプルデータの使用」→「読み込み」
-
financialsテーブルを選択し、「データの変換」
2. ディメンションテーブルの作成(Power Query)
Power BI の Power Query エディターを使って、元の financials テーブルからスタースキーマ用のディメンションテーブルを作成する手順を、テーブルごとに整理します。
2-1. 顧客セグメントテーブル(dim_seg)
-
financialsクエリを右クリック → 「参照」 -
Segment列のみを残す(「列の選択」) - 右クリック → 「重複の削除」
- クエリ名を
dim_segに変更
2-2. 地域テーブル(dim_geo)
-
dim_segクエリを右クリック → 「複製」 - 「列の選択」ステップを編集 →
Segmentを外し、Countryを選択 - クエリ名を
dim_geoに変更
2-3. 割引帯テーブル(dim_dis)
-
dim_geoクエリを右クリック → 「複製」 - 「列の選択」ステップを編集 →
Countryを外し、Discount Bandを選択 - クエリ名を
dim_disに変更
2-4. 商品テーブル(dim_prod)
-
financialsクエリを右クリック → 「複製」 - 「列の選択」で
ProductとManufacturing Priceのみを選択 - [Ctrl + A] → 右クリック → 「重複の削除」
- クエリ名を
dim_prodに変更
2-5. 日付テーブル(dim_date)
-
financialsクエリを選択 → 「参照」 -
dim_prodクエリを右クリック → 「複製」 - 「列の選択」ステップを編集 →
ProductとManufacturing Priceを外し、Date,Month Number,Month Name,Yearを選択 - クエリ名を
dim_dateに変更
3. ファクトテーブルの整理
-
dim_prodクエリを右クリック → 「列の選択」 - 「列の選択」で
Manufacturing Price,Month Number,Month Name,Yearのチェックボックスをオフにする
モデルビューでのリレーション設定と最終調整
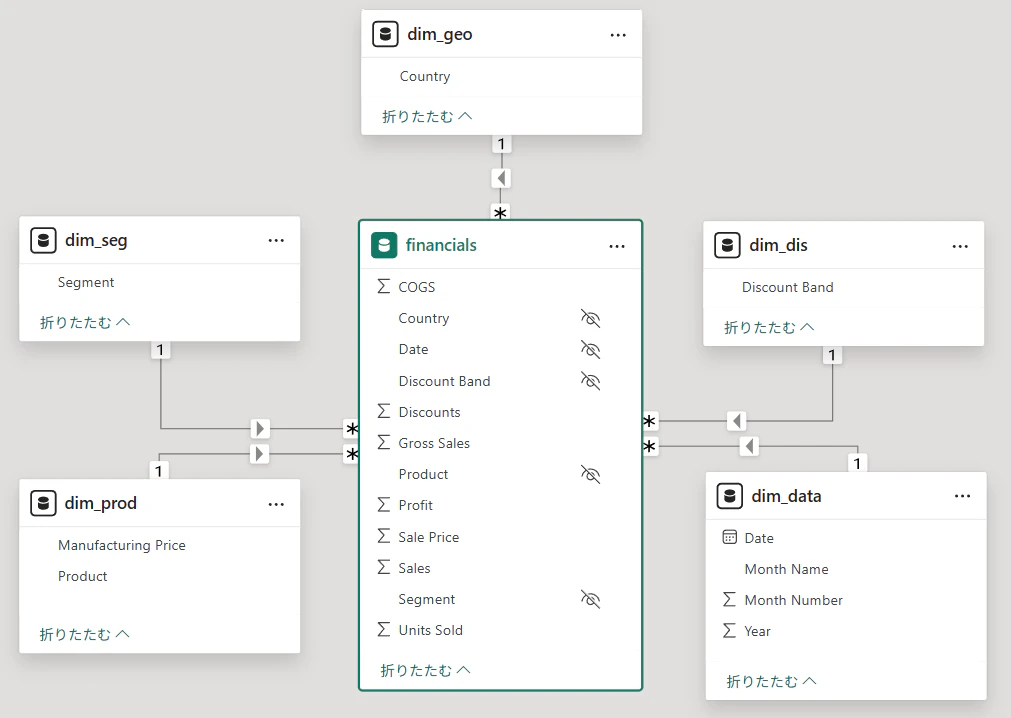
Power Queryでテーブルを作成したら、Power BIのモデルビューでリレーションを設定してスタースキーマを完成させます。
操作手順
- 「モデルビュー」をクリック
-
financials(ファクト)を中心に、dim_付きのディメンションが周囲に表示される - 以下のリレーションは自動検出される:
- Segment(dim_seg)
- Country(dim_geo)
- Product(dim_prod)
- Discount Band(dim_dis)
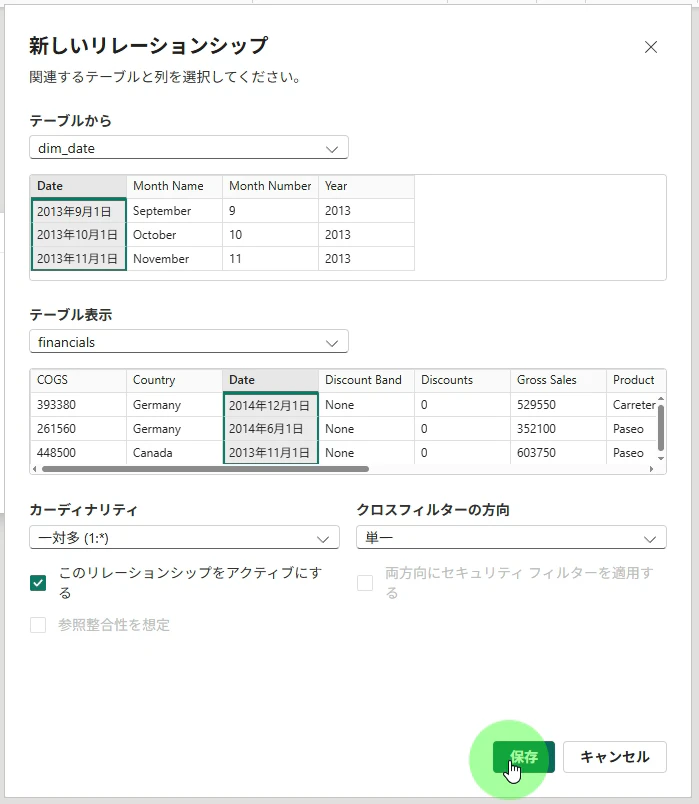
日付テーブルの接続(手動)
-
dim_date.Date→financials.Dateにドラッグ - リレーション設定画面で確認 → 保存
外部キー列の非表示(推奨)
| 非表示にする列 |
|---|
| Segment |
| Country |
| Discount Band |
| Product |
| Date |
最終調整
- 「レイアウトのリセット」で構造を整える
- すべてのリレーションが正しく設定されていれば、スタースキーマ完成!
タイムアタックでの効率化ポイント
Power BIのスタースキーマ構築を短時間で行うためのテクニックを紹介します。
1. 「列の削除」ではなく「列の選択」を使う
| 操作方法 | 特徴 |
|---|---|
| 列の削除 | ステップに列名が固定 → 後からの変更が面倒 |
| 列の選択 | GUIで再指定可能 → クエリの再利用性が高い |
2. 再利用性の高いクエリを作ること
タイムアタックでは、同じ操作を繰り返す時間を最小限に抑えることが重要です。そのためには、再利用性の高いクエリを意識することがポイントです。
✅ 工夫の例
-
「列の選択」ステップを使う
→ GUIなので複製しても、ステップ内容の編集が簡単 -
「全列を選択 → 重複の削除」ステップを活用
→ Ctrl + A で全列を選択し重複を削除することで、列数が増減しても対応しやすい -
クエリを複製して流用する前提で設計する
→ 列の選択、重複の削除などを行うベースクエリを1つ作成しておくと、複製後の修正が最小限で済む
💡 具体的な活用例
-
dim_segを作成した後、そのクエリを複製してdim_geoやdim_disを作成
→ 「列の選択」ステップだけを編集すればOK
このように、最初のクエリ設計を工夫することで、後続の作業を大幅に効率化できます。 タイムアタックだけでなく、日常のPower BI開発でも有効なテクニックです。
3. 命名規則の統一
- すべてのディメンションテーブルに
dim_を付ける
→ モデルビューでの識別がしやすくなる
これらの工夫は、タイムアタックだけでなく、日常のPower BIモデリングにも有効です。
YouTubeチャンネルのご紹介
YouTubeチャンネル DX塾では、Power BIやFabricを中心に、日々のデータ活用に役立つ動画を配信中です。
ぜひチャンネル登録して、スキルアップにお役立てください!
YouTubeチャンネルはこちら
最後に
📌この記事が参考になった方は、ぜひ「LGTM」や「ストック」をお願いします!
📢データ活用に興味がある方は、フォローして今後の更新もチェックしてください。