注目度の高まる「音声処理技術」領域で、日立製作所メンバーの研究開発姿勢を探る

ここ数年で「音声」に関する技術およびビジネスに対する注目が高まっています。例えば、Amazon「Alexa」やApple「Siri」のような一般消費者向けデジタルアシスタントは着実にユーザが拡大していますし、各種音声SNSも大きな注目を集めています。
それに伴い、音声の認識や処理に関する技術研究も目まぐるしく進化し続けています。特にディープニューラルネットワークなどのモデル、いわゆるAI技術の発展によって音声の認識率が飛躍的に高まったことで、社会実装の可能性も広がっています。
音声関連技術はどこまで進んでいるのか。そして、それらはどんな社会課題をどのように解決しうるのか。
今回は、「デジタル対話サービス」の事業開発や、「話者ダイアライゼーション」と呼ばれる音声処理技術の研究開発などを行っている日立製作所のメンバーにお話を伺いました。
目次
プロフィール

研究開発グループ 先端AIイノベーションセンタ メディア知能処理研究部

サービス&プラットフォームビジネスユニットアプリケーションサービス事業部
Lumadaソリューション推進本部 サービス事業推進部

研究開発グループ 先端AIイノベーションセンタ メディア知能処理研究部
自然対話プラットフォームを活かしたデジタル対話サービス

――皆さまが現在携わっている研究開発・事業開発内容について教えてください。まずは山崎さん、いかがでしょうか。
山崎:私は「デジタル対話サービス」と呼ばれる、自然言語を処理するAIプラットフォームの提供サービスに携わっています。サービス開発はもちろん、アプリケーションの実装から保守・運用まで、一連の業務を担当しています。
音声・言語処理を「自然対話プラットフォーム」の位置付けで整備していまして、エンジンとしては、テキストによるユーザ質問に対して意図を理解し正しい回答を返す言語処理と、音声をテキスト化する音声認識の大きく2種類の機能を有しています。
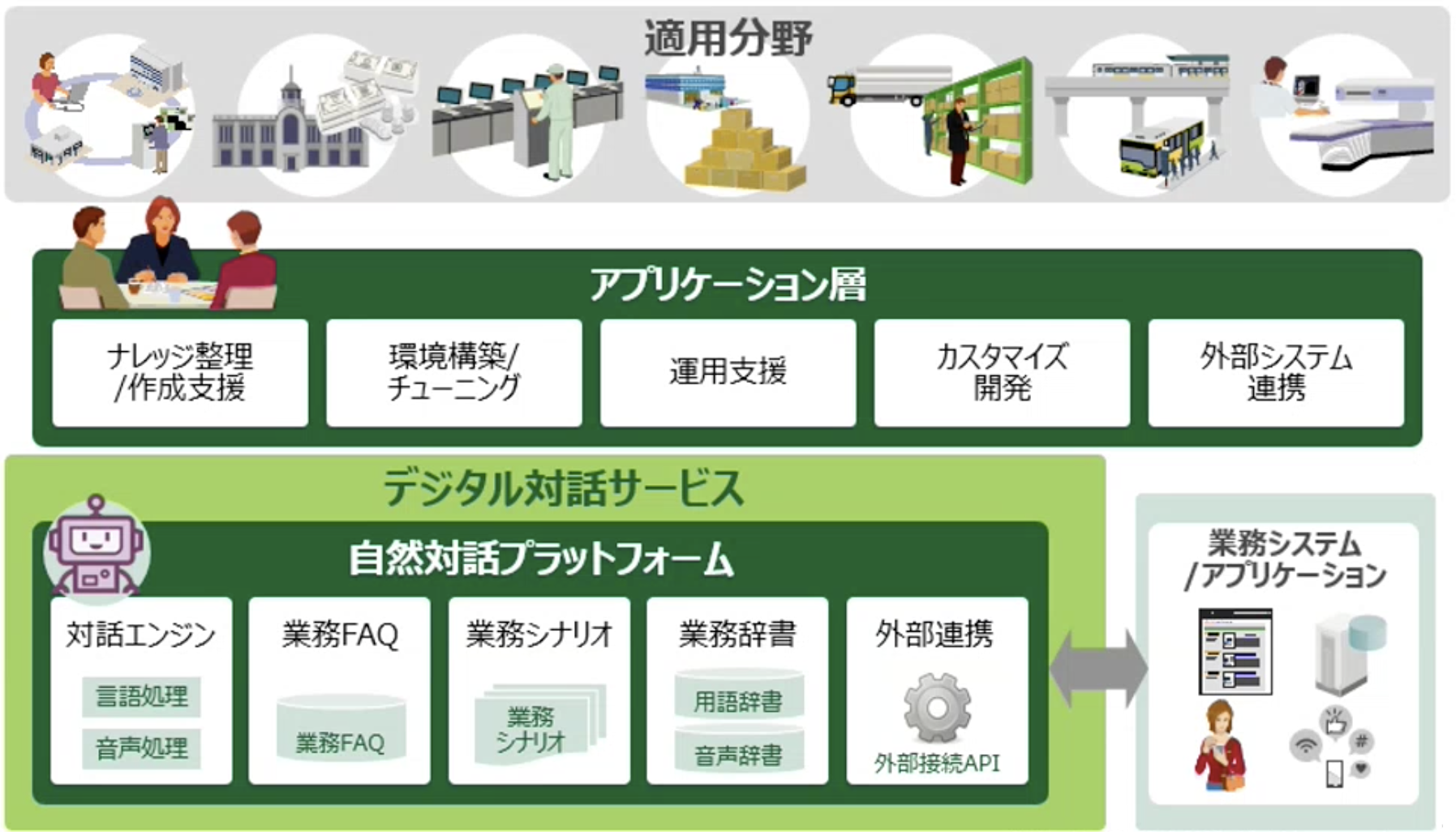
――サービスとしてはどんな展開がなされているのですか?
山崎:「チャットボットサービス」「音声書き起こしサービス」「音声認識サービス」「音声対話サービス」の4サービスを展開しています。また、チャットボットのエンハンスとして、RPAとの連携も開発中です。
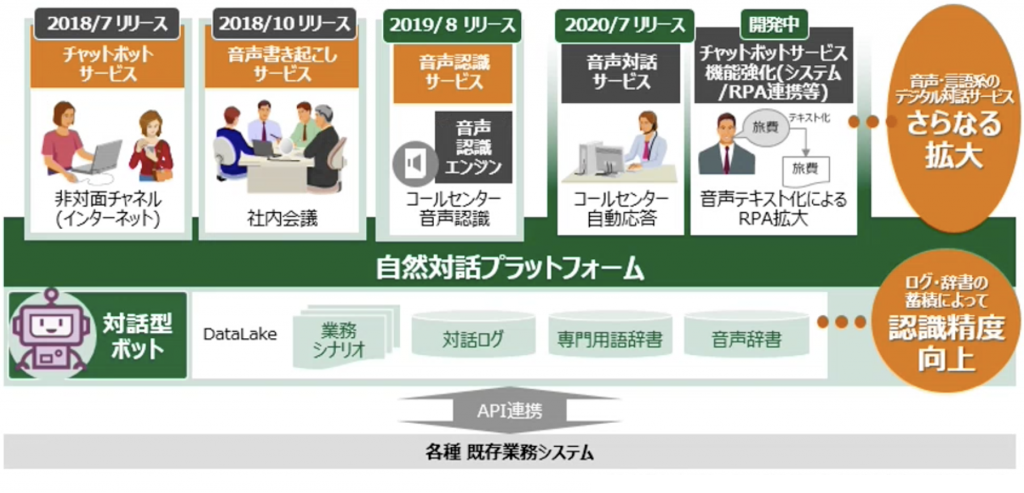
――4サービスの具体的なサービス内容をそれぞれ教えてください。
山崎:まず「音声認識サービス」は音声をテキスト化する単純な機能で、主にコンタクトセンターで利用されています。コンタクトセンターに集まった音声をもとに、会話の内容を可視化。オペレーターが「見える化」した内容を見ることができる機能の一部としてこのサービスが利用されており、4サービスの中で最も引き合いが多いです。
2つ目の「音声書き起こしサービス」は、日立独自の音声認識技術として、雑音や反響音を除去して認識対象の音声だけを抽出する「雑音除去技術」と、複数方向からの音声を別々に認識する「音源分離技術」を活用したサービスです。
現在は、企業内の会議議事録を書き起こす用途で活用されています。もちろん、これはインダストリーや職域に制限されることなくご利用いただけることを想定しています。
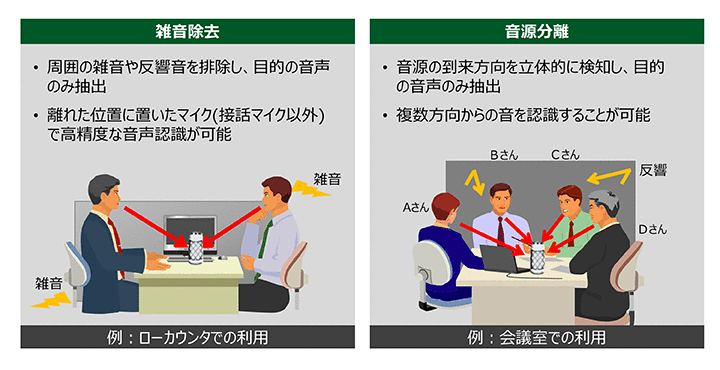
――複数方向からの音声をどのように識別しているのですか?
山崎:ソリューションとしては、8方向に対応したマイクを使うことを想定していまして、各方向からの音声を識別できるようにしています。認識可能な人数は8名までとなっています。
コンタクトセンターでの引き合いが多い対話型ボット

――残り2つのサービス(チャットボットサービス、音声対話サービス)についてはいかがでしょうか?
山崎:「チャットボットサービス」は、あらかじめ定義した業務シナリオに沿って会話を進める「シナリオ対話」、一問一答型の「QA対話」。そして質問者への聞き返しを通じて情報を補う「スロット対話」の3つの対話方式を、問い合わせ内容に応じて柔軟に切り替えるものです。
蓄積された対話履歴を分析可能なダッシュボードや、会話内容の分析を支援する機能も提供しており、分析結果をフィードバックすることでどんどん精度が高まり、それに伴って運用者の負担も軽減されることが期待されています。
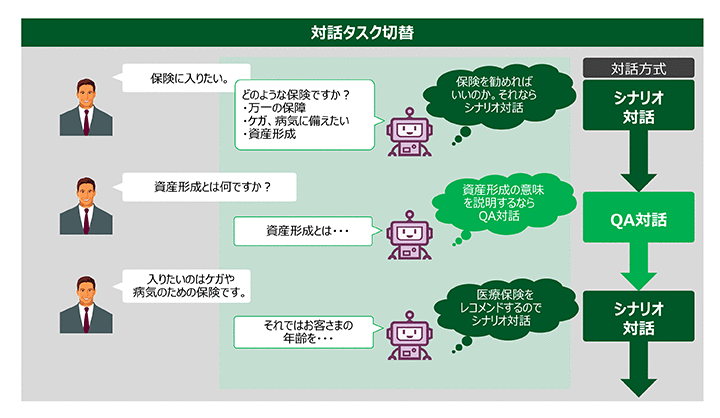
――こちらは対話の中でも、音声ではなく文字を前提にしたサービスということですね。
山崎:そうですね。各種製品・サービスのオンライン応対自動化に関する、あらゆる分野での活用を想定しています。
また、情報システム運用業務のような、マニュアル対応が前提となる業務の課題改善にも役立つと考えています。
例えば運用担当者がチャットから指示するだけで、対話型ボットが情報の取得や整形、更新を自動で行い、システム運用にかかっていた負担を軽減して人為的なミスを低減することを想定しています。
――なるほど。音声対話サービスの方はいかがでしょうか?
山崎:今お伝えしたチャットボットサービスが文字コミュニケーションを前提としているのに対して、「音声対話サービス」は音声コミュニケーションを前提としています。
技術的には、音声をテキスト化する技術と、問い合わせに対する回答を返す技術の2種類に分かれており、前者についてはお客さまから信頼をいただけるレベルの認識精度を誇っています。
また、後者は発話内容を理解する「意図理解」の処理部分です。人の発話でどうしても発生する語尾などの「ゆれ」も吸収できるロジックを導入しています。
そして、お客さまにご用意いただくデータも含めて、あらかじめ用意されている質問に近しい質問内容を探し出して、それに対応する回答を返すものとなっています。
こちらについても、様々な領域での応用が期待できますが、まずはヘルプデスクやコンタクトセンターでの活用を想定しています。
――やはりこの分野はコンタクトセンターでの引き合いが多いのですね。
山崎:そうですね。以前から人手不足や応対品質の均一化という課題はありました。またCOVID-19流行後は、感染症対策によるフロア人数の制限や閉鎖、緊急事態宣言に伴う通勤困難者の発生など、「人手不足で困っている」という声を以前より多くいただいています。
人が担っている業務をAIに代行させることができないか。社会やお客さまの課題解決に向け、音声認識の製品を持っていた我々の部署で、音声自動応答システムの導入を検討することになりました。
私たちがソリューションとして、プラットフォーム提供やコンサルティング・SI・運用支援などを担当。言語処理を行う部分のコア技術については、内田さんがいらっしゃる研究所へと依頼を出し、製品化を進めています。
約60年の歴史がある音声関連技術の研究

――次にコア技術の内容についても伺いたいと思います。そもそもですが、日立でこの領域の研究が始まったのはいつからなのでしょうか?
内田 : 日立の音声研究は1960年代からはじまっています。研究ユニットとして約60年の歴史があり、中央研究所の中では、最も歴史のあるユニットになると思います。
その中でも先ほどお伝えした通り、近年、コンタクトセンターでの音声認識のニーズが高くなってきたことから、そこに向けて音声認識の研究を進めてきたという流れになります。
――音声認識に関しては、それこそ様々な技術的アプローチがあると思うのですが、日立ではどのような技術を特徴としているのでしょうか?
内田 : はじめに音声認識技術の概要を説明します。音声認識は、音声の「音響的特徴」と「言語的特徴」をもとに、音声をテキストに変換する技術です。音響的特徴の分析を担うのが音響モデル、言語的特徴の分析を担うのが言語モデルで、特に音響モデルは音声認識の性能を左右する重要な要素です。
音響モデルは、音声の周波数成分や時間変化から、音声がどの音に近いかを識別します。私たち人間は、日常的に音声を聞いてそれを言葉として認識しているので一見簡単なことに思えますが、これを機械で実現するのは非常に難しいのです。
音声の特徴は、性別や年齢はもとより、同じ個人でも場面によって違ってきます。さらに、雑音や音の歪みといった外的要因の影響を受けやすいので、特徴変化の観点で識別の難度が非常に高いと言えます。
日立は、早い段階から、現在主流となっているディープラーニングを用いた高精度な音響モデルの研究に着手し、様々な技術を開発してきました。
――学習という観点でも特に難しそうですね。
内田 : おっしゃる通りです。
音響モデルは、様々な音声を収録して統計処理したものですが、実用に耐えうるモデルを作るには一般的に数千時間の音声が必要になります。しかも、ただ音声を集めてくれば良いというわけではなくて、その音を人が聞いて書き起こし、正解をつくる必要があります。書き起こしの作成には収録時間の5倍程度の時間が必要で、非常にコストのかかる作業となります。
このような課題に対し、日立では、シミュレーションによって様々な雑音や残響、歪みを付加して、学習データを拡張するという方法の開発に注力しました。学習データの拡張自体は一般的に行われていることですが、日立としてここに多くのノウハウを持っているからこそ、雑音や残響への強い耐性を獲得することに成功しています。
また、音響モデルの学習手法についても、大規模・高精度な「教師モデル」を模倣する「生徒モデル」を学習する手法による音響モデルの高速・省サイズ化や、音声認識の期待正解率を最大化するように学習する手法による高精度化など、いくつもの独自技術を開発しています。
――なるほど。もう1つの言語モデルはどのようなものでしょうか?
内田 : 言語モデルは、音響モデルにて音声から変換した「音素列」に対して、単語列に変換する役割を担っています。大量のテキストを統計処理していったものなので、単語を並べたときの「文章らしさ」を評価することができます。つまり、音響モデルが推定した音の羅列に合う大量の単語の組み合わせの中から、「もっとも文章らしいもの」を求めるというわけです。
――つまり、言語モデルの性能が悪いと、たとえ音響モデルの性能が良くても、文章がおかしなことになるということですね。
内田 : そうです。日立は非常に多様な大規模モデルを持っていて、そのままでも高い精度の音声認識を実現できます。しかし、コンタクトセンターなどでは専門性の高い用語も飛び交うので、どうしても言語モデルのチューニングが必要になります。我々はそういったチューニングのノウハウも蓄積しています。
強みの異なる技術を融合させ、勝ち取った国際コンペ入賞

――高島さんは、ここまでの内田さんおよび山崎さんが携わっている「デジタル対話サービス」とは別のアプローチで音声認識技術の研究を行っていると伺いました。そちらについても教えてください。
高島 : 私は「話者ダイアライゼーション」と呼ばれる技術の研究開発を行っています。複数の人が話しているような音声データに対して、「Aさんはこの時刻からこの時刻まで、Bさんはこの時刻からこの時刻まで、それぞれ喋っている」というラベル付けをする技術です。
ずっと1人の音声認識をするのであれば、そんなに複雑ではありません。ですが実際は1人の音声認識ばかりではありません。例えば会議やコールセンターなど、複数人の発話を収録して会話内容を分析する際に「どの発話が誰によるものか」という情報も必要になってくると思います。
従来は、各人の音声が重ならないことを前提にした音声認識システムを組んでいました。しかし、話者ダイアライゼーションを使うことで、1つのマイクで録音した発話の重なりがある自然な会話音声で、音声認識を実現することができます。
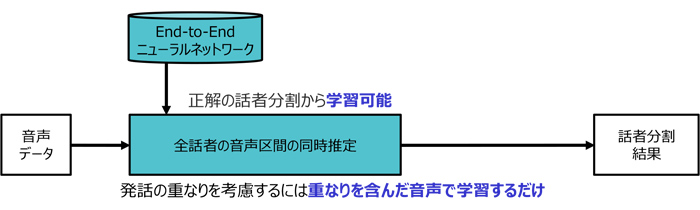
開発したEnd-to-End話者ダイアライゼーション方式
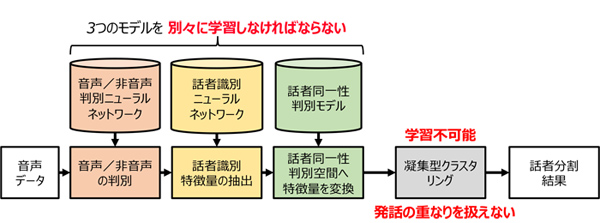
従来の話者ダイアライゼーション方式
――今回のような複数人インタビューケースでもまさに重宝される技術だと思うのですが、どのように実現しているのでしょうか?
高島 : 一般的には、ニューラルネットワークの出力として話者の人数分の出力ユニットを用意して重なりを含んだ音声に対応するのですが、どの話者がどの出力層に対応するか、は決まっておらず、このことは学習を妨げる要因になってしまいます。
これに対して日立では、「パーミュテーションフリー学習法」と呼ばれる、学習データにおける出力順序に依存しないでニューラルネットワークを最適化できる手法を適用しました。つまり、学習データから考えられる話者の組み合わせを全て評価し、最も誤りが小さくなる話者順序に基づいてニューラルネットワークの更新を行うことで、重なりを含んだ音声にも対応できるようにしています。
また、例え会話中の次の発話までに時間が開いても、話者の違いを識別することができるように、「自己注意型話者特徴抽出技術」も適用しています。各時刻の特徴を全時刻の特徴と比較して特徴間の類似性に基づいて、「より話者を識別しやすい特徴」へと変換する「自己注意機構」を用いることで、従来型の再帰型ニューラルネットワークでの性能よりも大幅に上回ることができています。
――実際、どこまでの精度を実現できているものなのでしょうか?
高島 : 昨年、ダイハード3(正式名称:The Third DIHARD Speech Diarization Challenge)という国際コンペで世界第2位を記録しました。日立と共同研究先のジョンズ・ホプキンズ大学のチームとで共同チームを組んで参加し、国際的にも高い精度を実現できたと自負しております。
――素晴らしいですね!ちなみに、勝因は何だったのでしょうか?
高島 : チームごとに異なる強みがあり、それらをうまく融合できたことだと考えています。
日立は主に、先ほどから話題に出ているニューラルネットワークによるダイアライゼーションを強化するようなモジュールの開発をしました。
一方でジョンズ・ホプキンズ大学のチームでは、ニューラルネットワークではなく、クラスタリングという従来型のダイアライゼーション技術に強みを持っていました。
これらを組み合わせることで、結果として精度が大幅に向上できたというのが、技術として面白い点かなと思います。
グループが非常に大きいからこそ、人財配置の自由度も高い

――ここまで皆さまの研究開発・事業開発領域でのお話を伺いましたが、今度は少し引いた目線で、日立で研究開発をすること/携わることのメリットややりがいについて教えてください。
内田 : 私はこれまで音声に限らず、様々な製品の開発に携わってきました。入社直後はデジタル家電の開発に携わっていましたし、自動車のヒューマンマシンインタフェースや、コミュニケーションロボットの開発にも携わりました。
これまでのキャリアを通じて、日立で研究してきて良かったと感じることは、事業領域が広く多様な分野や製品に携われるということですね。
それによって、様々な技術の研究開発に取り組めたので、技術者としての幅を広げることができたと感じています。
山崎:私も同じ意見ですね。日立グループ自体が大きい組織なので、多様な事業やサービスを展開しているからこそ、人財配置の自由度も高いと感じています。
あとは、要件定義から設計・保守まで業務のカバー範囲が広い。製品開発に関わる様々な業務に携わることで、日々、自分は何が得意なのかを改めて見つめることができると感じています。
――山崎さんの得意領域はどこになるのでしょうか?
山崎:個人的には、サービス開発の部分かなと思っています。
――なるほど。高島さんはまだ入社されて2年目だと思いますが、いかがでしょうか?
高島 : 私の場合はCOVID-19の影響もあり入社直後から在宅勤務なので、まだおふたりのおっしゃっているような体験はできていないですね。
なので、大学での研究との違いという点でお伝えすると、チームで仕事をしていくという意識が非常に強いのかなと思いました。
大学の頃は、個々人で頑張るというスタイルで研究を進めていたのですが、日立に入ったら「チームで取り組む」という意識が強く、そこがとてもいいなと思いました。
――どのような点を「いいな」と思われたのでしょうか?
高島 : 例えば、昨年の8月に論文を1本投稿したのですが、実はその2カ月前まで、まだ研修期間中だったんですよね。本格的に業務を始めたのが7月だったので、スケジュール的にも結構厳しいところがありました。でも、チームの人たちにフォローしてもらいながら、なんとか論文を書き上げることができました。あくまで一例なのですが、1人では到底無理だったなと感じています。
――チームという観点だと、国際コンペも良い経験になったのではないでしょうか?
高島 : そうですね!ダイハード3については、現役の学生の方とご一緒できたのも面白かったです。言語の違いや時差があったのでコミュニケーションの面で大変なところはありましたが、なかなかそういう機会もないので、とてもいい経験になりました。
社会からの「信頼」を醸成していけるAI開発に向けて

――皆さまの今後の目標についても教えてください。
高島 : まだ入社したばかりで特定の製品開発に深く携われていないので、まずは1つ、自分が技術領域で携わった製品をリリースすることが目標です!
内田 : 私は現在、音声認識領域からは離れて、言語モデルの研究開発に携わっています。
最近、事前学習言語モデルと呼ばれる大規模言語モデルが急速に普及してきています。以前の言語モデルが用途ごとにゼロから学習していたのに対して、事前学習言語モデルは少量の追加学習のみで様々なタスクに応用できる利便性の高さがその理由です。
一方で、事前学習言語モデルには倫理的な問題があることが指摘されています。この言語モデルは主にWeb上から機械的に収集したテキストで学習しているのですが、このようなテキストには様々なバイアスや倫理的に問題のある内容が含まれ、これが言語モデルを使用したアプリケーションに悪影響を与える可能性があるのです。私は、このような課題に対する研究を進めております。
AIの社会実装を進めるには、社会から信頼を得ることが重要です。だからこそ、AIにどういう問題があるのか、きちんと把握して対策をする必要があります。社会からの信頼を醸成していけるよう、貢献していきたいと考えています。
山崎:短期的な目標としては、今取り組んでいるコンタクトセンター向け音声自動システムのサービス化を、できるだけ早く開発して提供したいです。
また中長期的には、コンタクトセンターを在宅化したいという要望も多いことから、業務形態を支援できるようなシステム開発にも挑戦したいです。その場合は、セキュリティ面をより強化していくことになると思います。
――ありがとうございます!それでは最後に、今後どんな人と一緒に仕事をしていきたいか教えてください。
高島 : 最新技術をキャッチアップして、どのように課題を解決していくかを一緒に考え、積極的に議論できる人と働けたらいいなと思っています。
山崎:新しい技術にチャレンジできる人とご一緒したいですね。日立では、最先端レベルの技術を扱っているという自負があります。もっと世の中を便利にしていきたいので、自ら情報を収集して製品開発に取り組める人に、ぜひ来てほしいなと思います。
内田 : 日立には自身の持っている技術を活かせるフィールドが多くあると思います。技術そのものを高めるだけでなく、その技術がどういうところに役立つかなどのディスカッションができる方と一緒に仕事がしたいと思っています。
編集後記
同じ音声関連技術であっても、アプローチの違う技術研究が並行して走っており、それぞれの強みを活かしたサービス開発への道筋が描かれている話は、さすが国内最大規模の研究施設を有する日立グループならではだと感じます。
人財配置の自由度という観点で、とても魅力的だと思いました。
今回お話を伺った高島さまといい、日立製作所のメンバーへの取材を重ねていくと、国際コンペの入賞経験者がとても多い印象です。そして皆さま例外なく、個人の研究にプラスして、チーム力を活かした結果であるともおっしゃいます。自分の得意領域をうまく融合させて、より高みの成果へとつなげたい研究者にとっては、理想的な環境だと改めて感じた次第です。
取材/文:長岡武司
撮影:太田 善章
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所経験者採用実施中!
音声認識、音響認識、または時系列信号処理に関する研究開発
募集職種詳細はこちら
日立製作所の人とキャリアに関するコンテンツを発信中!
デジタルで社会の課題を解決する日立製作所の人とキャリアを知ることができます
Hitachi’s Digital Careersはこちら