「あなたのお仕事をちょっぴり豊かにする生成AI活用術」Qiita Conference 2024イベントレポート

2024年4月17日〜19日の3日間にわたり、日本最大級*¹のエンジニアコミュニティ「Qiita」では、オンラインテックカンファレンス「Qiita Conference 2024」を開催しました。
*¹「最大級」は、エンジニアが集うオンラインコミュニティを市場として、IT人材白書(2020年版)と当社登録会員数・UU数の比較をもとに表現しています
当日は、ゲストスピーカーによる基調講演や参加各社のセッションを通じて、技術的な挑戦や積み重ねてきた知見等が共有されました。
本レポートでは、アマゾン ウェブ サービス ジャパン合同会社の技術統括本部 ストラテジック製造グループ 本部長である清水崇之氏によるセッション「あなたのお仕事をちょっぴり豊かにする生成AI活用術」の様子をお伝えします。
※本レポートでは、当日のセッション内容の中からポイントとなる部分等を抽出して再編集しています
※本レポートでは、2024年4月時点でのサービス内容および価格に基づいたスライドや説明を用いています。 最新の情報はAWS公式ウェブサイトにてご確認ください
登壇者プロフィール

技術統括本部 ストラテジック製造グループ 本部長/シニアマネージャ,ソリューションアーキテクト
AWSが提供する生成AIスタック
清水:こんにちは、アマゾン ウェブ サービス ジャパンの清水です。本日はよろしくお願いします。まずは自己紹介ですが、アマゾン ウェブ サービス ジャパンで製造業を担当するソリューションアーキテクトチームのシニアマネージャをやっております。
私自身はAWS芸人と呼ばれることもございまして、AWSを使った面白いものをよく作っております。Xもやっておりますので、こちらに表示されていますQRコードからぜひフォローしてください。
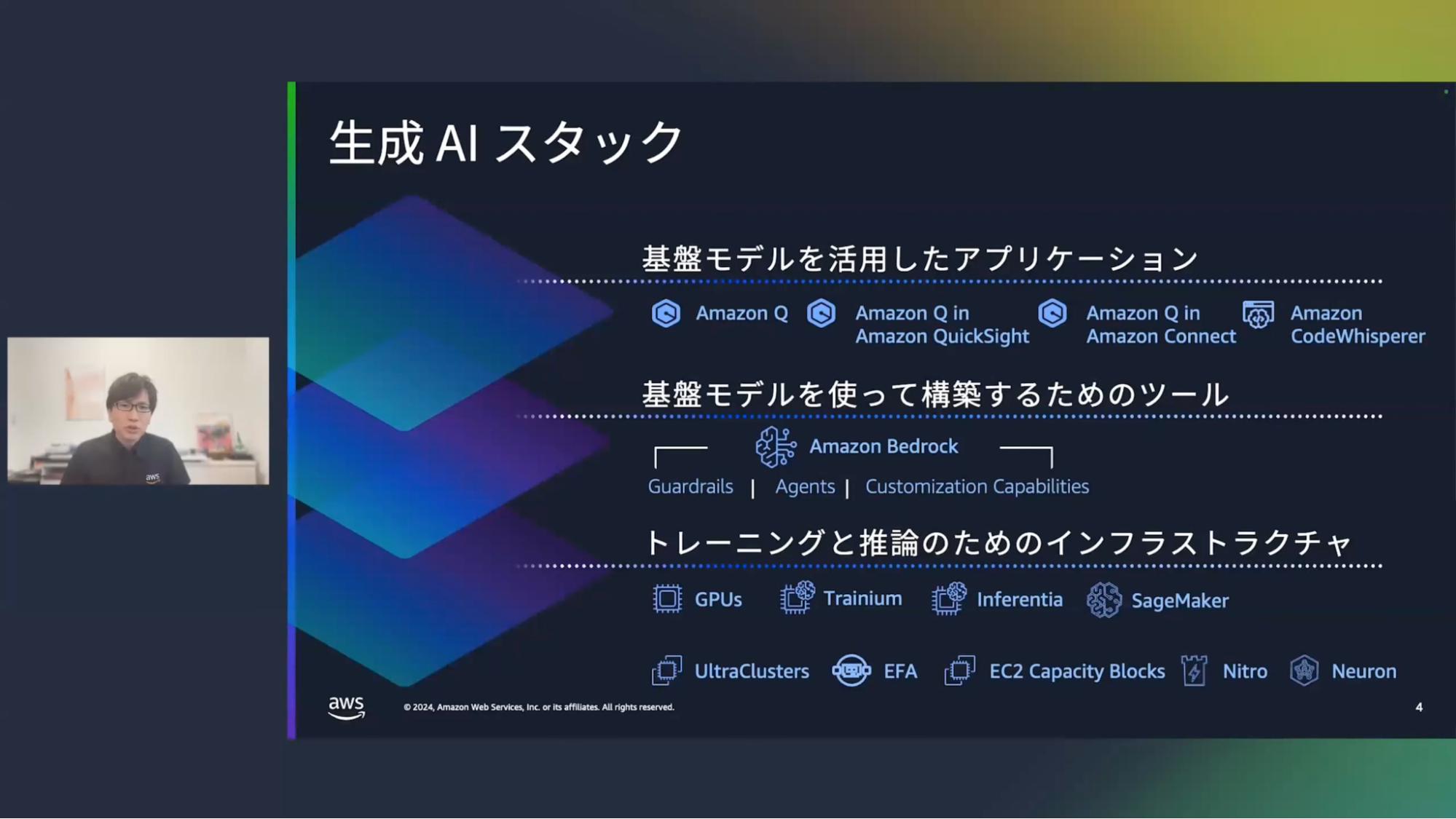
清水:まずはAWSが提供する生成AIについてです。生成AIというのは、基盤モデルと呼ばれるAIの頭脳に相当するものに対して、何かしらの入力(質問など)をすることで出力(回答)が得られるというものです。このスタックは3層の技術レイヤーで説明されており、ユーザーの様々なニーズに応えることができます。
まず上のレイヤーは基盤モデルをすぐに使えるアプリケーションとして提供するサービス群です。
例えばAmazon Qは生成AIでチャットボットを素早く構築するサービスで、BIツールであるAmazon QuickSightや、コンタクトセンターのソリューションであるAmazon Connectと連携して利用することもできます。
続いて真ん中のレイヤーは、基盤モデルを使ってアプリケーションを構築するためのサービス、Amazon Bedrockです。
開発者が生成AIのアプリを作るときに、コンテンツを監視するためのガードレールの機能や、AIとの対話の後にアクションを起こすためのエージェント機能、さらには独自のデータで基盤モデルをカスタマイズする機能などが必要になってくるのですが、Amazon Bedrockはこれらを提供しております。
そして下のレイヤーは、トレーニングや推論のために必要となるインフラストラクチャーです。基盤モデルの活用には大規模な計算を必要とします。GPUやAWS独自のチップであるTrainiumやInferentiaなどを使って、高速かつ低コストでご利用いただくことができます。
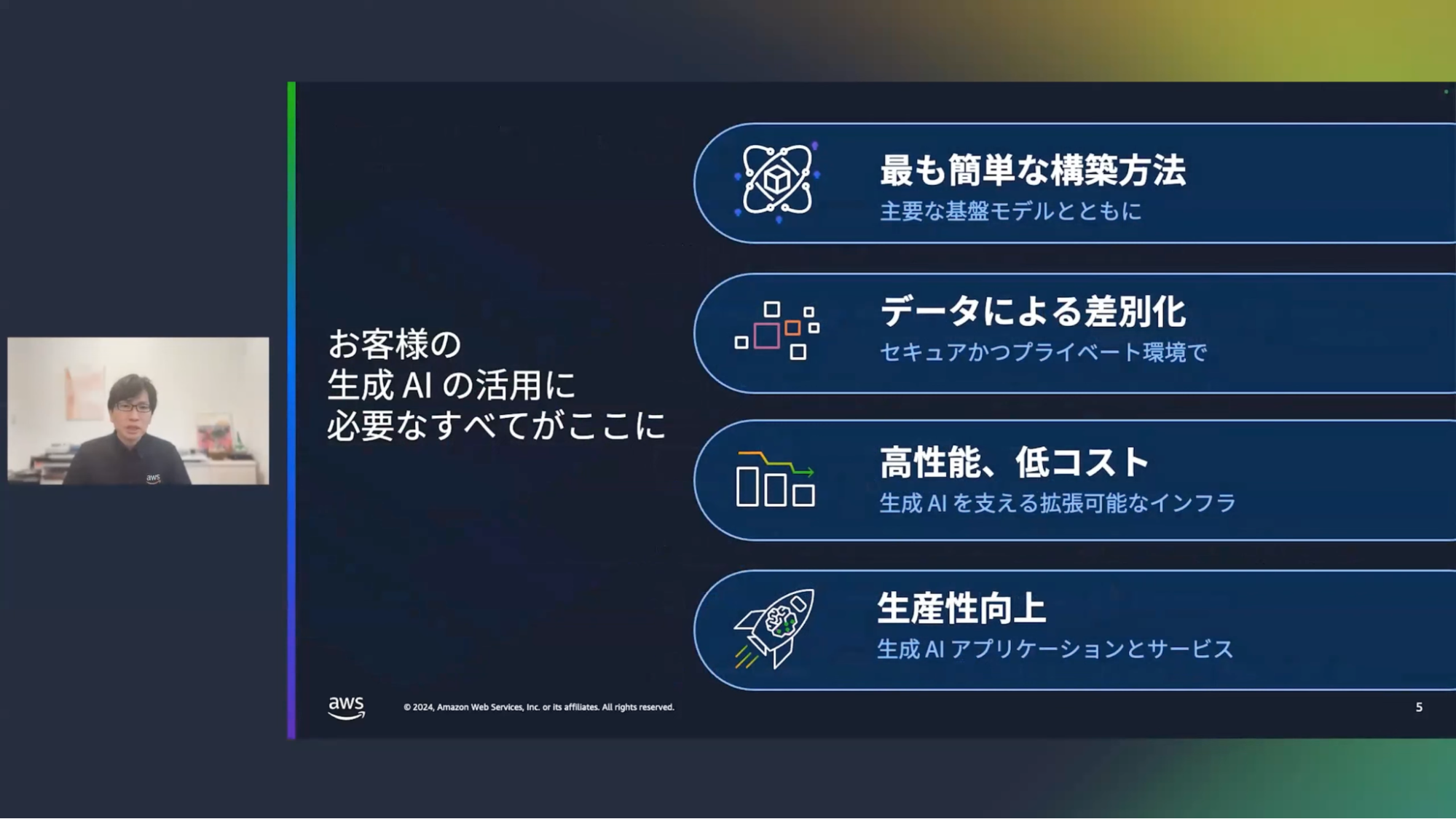
清水:ここで、AWSの生成AIスタックを利用するメリットをまとめておきます。本日は、2つ目の「データによる差別化」について、もう少し詳しく説明していきたいと思います。
データによる生成AIの差別化とは
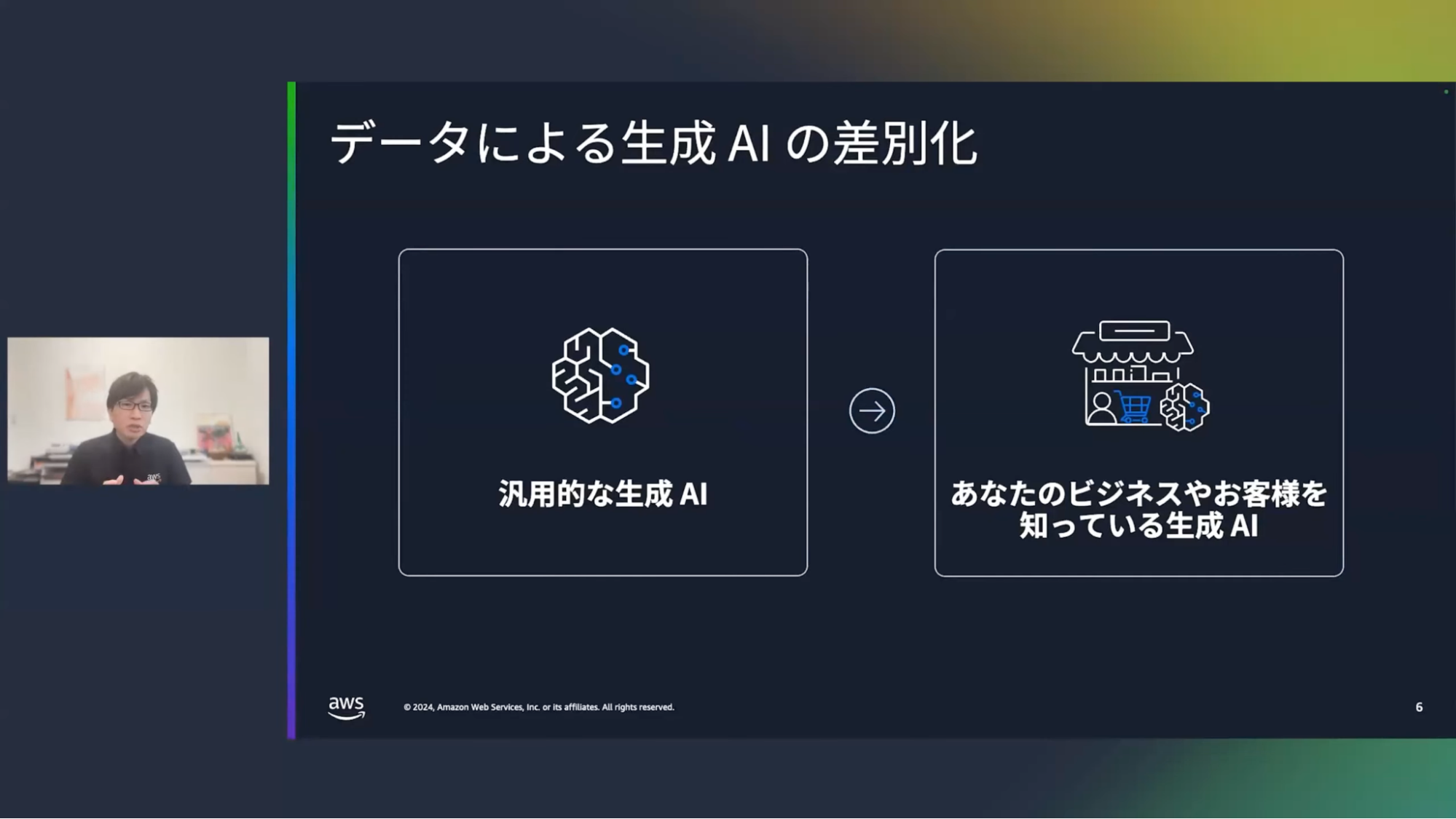
清水:AWSが提供している生成AIの基盤モデルは、汎用的なモデルではありますが、汎用的なモデルでも高性能なので非常に流暢・的確な回答を返すことができます。
こうした汎用的なモデルでは非公開ビジネスの詳細情報やお客さまに関する情報は当然含まれておりませんが、このような情報を反映することができれば、さらにユーザー体験を良くすることができるかもしれません。

清水:例えば、ユーザーの好みに合わせて提案をしてくれるようなAIエージェントの機能などです。こちらは旅行会社の例ですが、お客さまの過去の旅行履歴や、WEB上の検索履歴、登録されている好みの情報といったものを保有しているので、これらの情報を使ってカスタマイズすることができます。
さらに飛行機の空席情報や格安のプロモーション情報、もしくは似たような他の旅行者の情報等を組み合わせていただくこともできます。これによって、より適切な旅行プランをユーザーに提案できるようになるわけです。
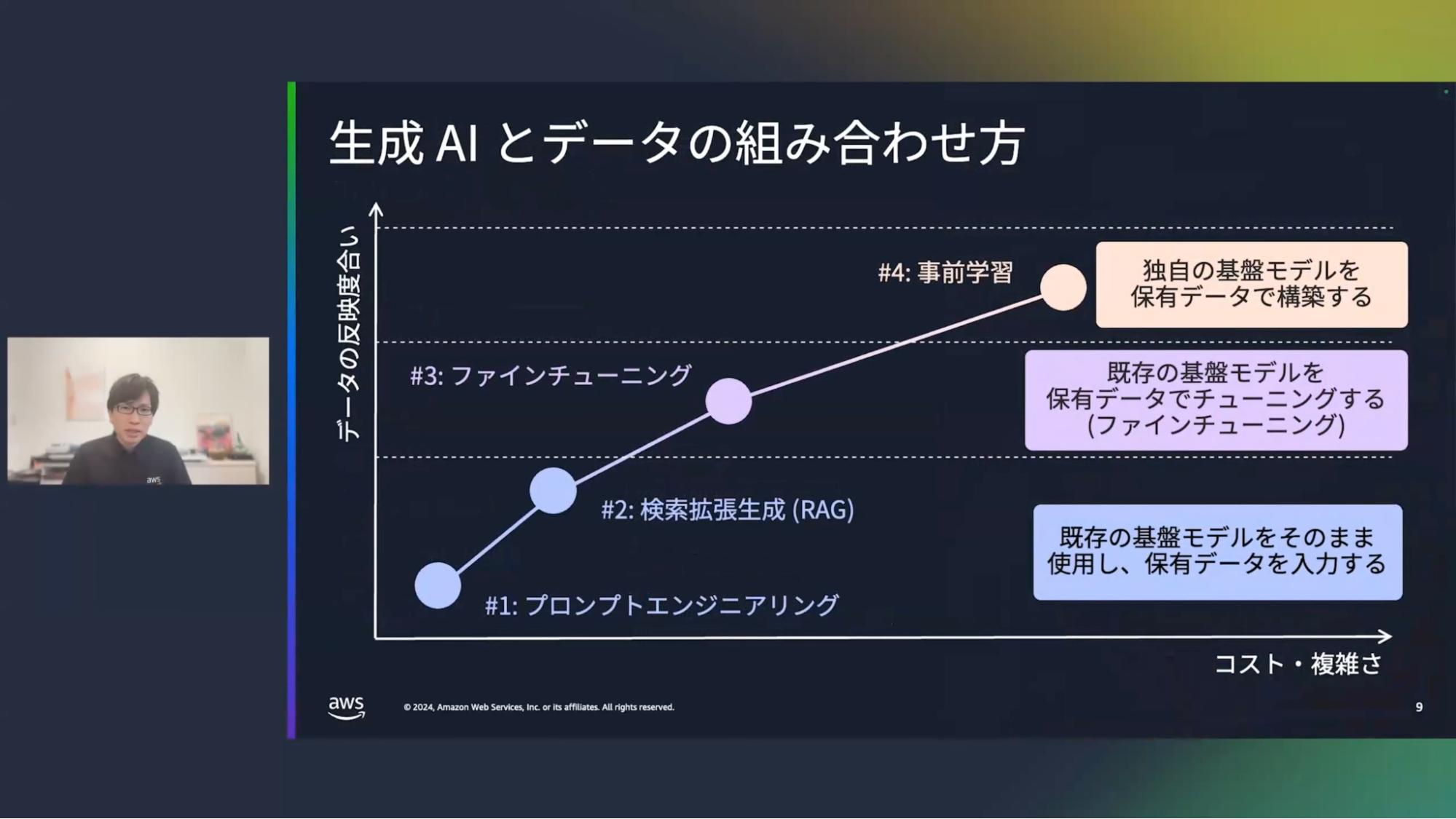
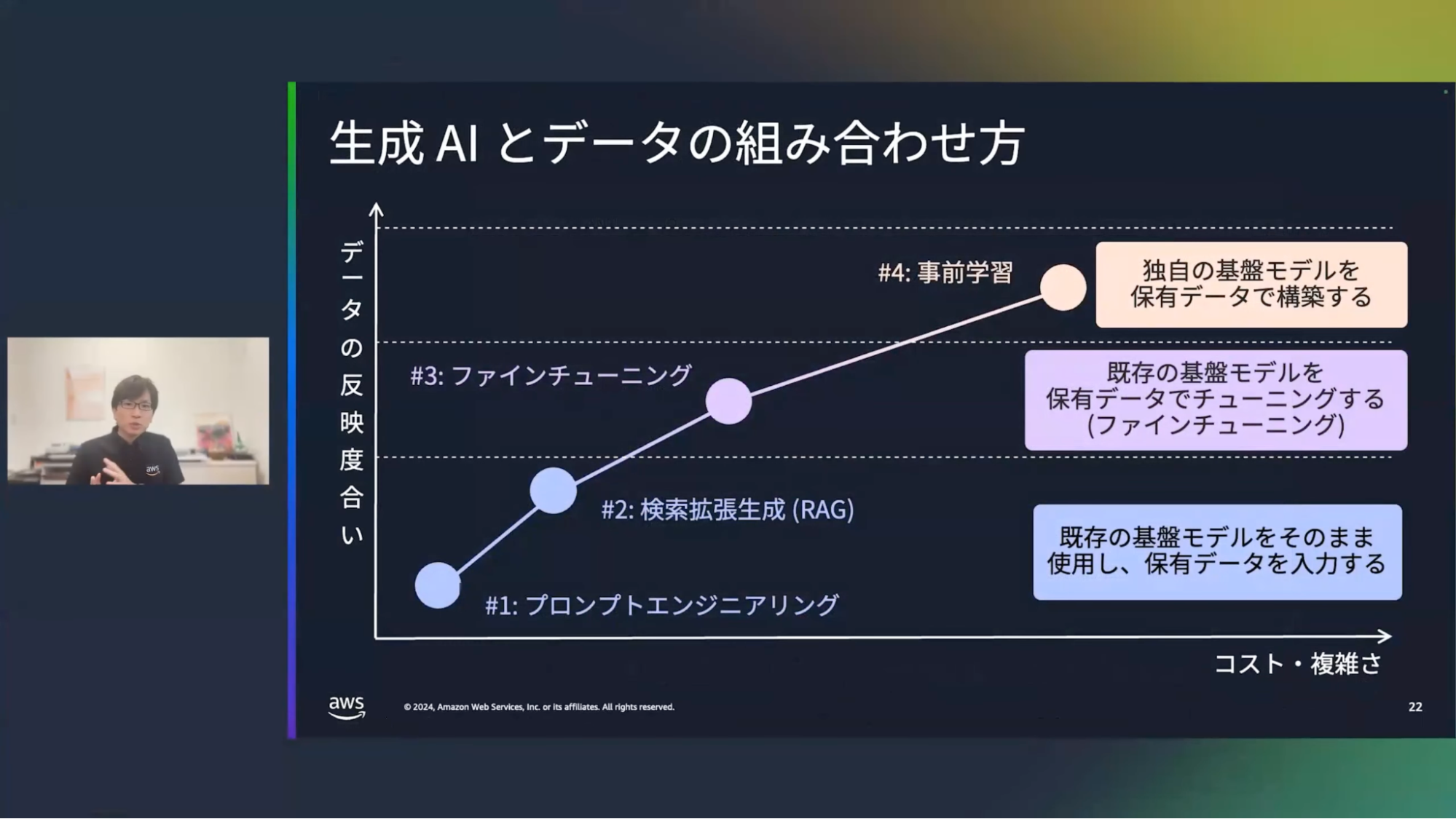
清水:ここで、生成AIとデータの組み合わせ方のよくある4つのパターンをご紹介していきたいと思います。こちらの図は、横軸がコストと複雑さ、縦軸が独自データをどれくらい反映できているかの度合いを表現しています。
まず1つ目は、プロンプトエンジニアリングです。生成AIに入力する質問/文章がプロンプトです。このプロンプトを工夫することで、条件などを指定してカスタマイズするというものになります。
2つ目は、検索拡張生成(RAG)です。これはドキュメント群を検索する仕組みと組み合わせて使うもので、検索結果を生成AIに入力することで、よりリッチな回答を得ることが出来ます。
これら2つのパターンでは基盤モデルとして汎用的なモデルを使います。つまり、入力方法を工夫したり検索によって情報を追加したりすることでカスタマイズする、というものになります。
3つ目は、ファインチューニングです。企業の独自データから質問と回答のセットを用意しておき、それによって既存の基盤モデルをカスタマイズするものです。
そして4つ目は、事前学習です。これは独自データを使って基盤モデル自体を作り変えるものになります。
まずは皆さんに生成AIを使ってもらうことが重要だと考えているので、今回のセッションではプロンプトエンジニアリングを中心にデモをしながら、日常で生成AIを使うきっかけ作りになればと考えております。
プロンプトエンジニアリングの実践

清水:では、プロンプトエンジニアリングについてご紹介していきます。プロンプトエンジニアリングは、ユーザーからの入力に補助的な情報を追加して出力を制御し、より良い回答を得るというものです。
これは、特定の業務や要件に従って出力させたいような時に適切なパターンとなります。
例えばプロンプトとして「機械学習基盤の作り方を教えてほしい」と入力する場合を考えてみましょう。
これを汎用的な生成AIの基盤モデルに入力すると、一般的に知られている情報だけを使って回答がなされます。例えば「コンピューターを用意して」「ネットワークを用意して」というようなところから始まってしまうかもしれません。
しかし、AWSを使った構築方法を知りたいというのがここでのニーズだったとします。そこで、補助的な情報を追加するわけです。
「あなたはAWS のソリューションアーキテクトです。質問に対して、AWSでどう実現できるか答えなければいけません。質問は機械学習基盤の作り方について教えて」
このように、前段で役割や制約を追加してあげることで、期待される回答が変わってきます。このように工夫することで、例えば回答は「まず機械学習のためのデータレイクとしてAWSのAmazon S3を準備します。 次にAmazon Bedrockを使って…」というふうに、こちらの意図に沿った回答をしてくれるようになるわけです。
デモ①:キーワードの意味を知りたい
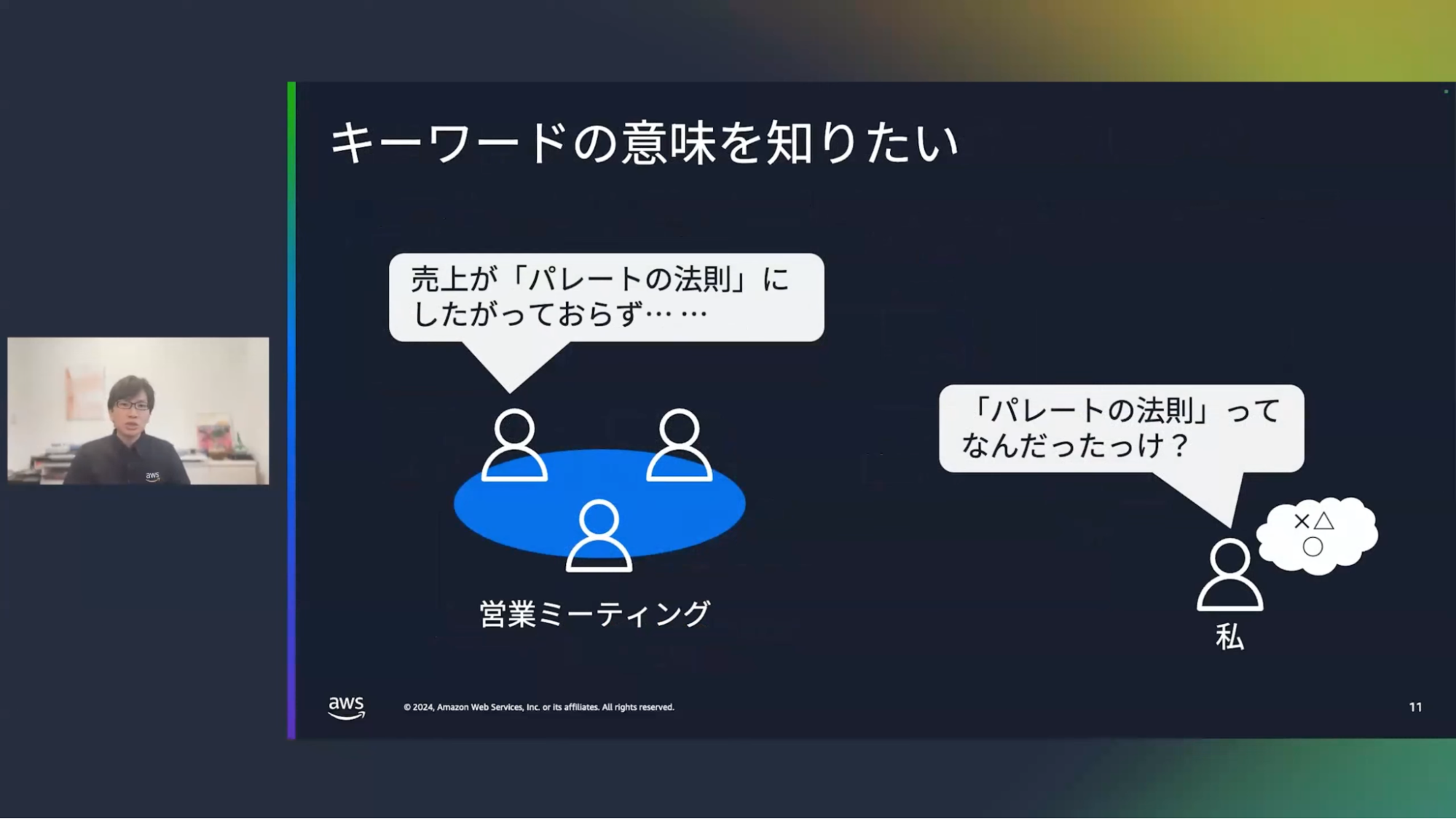
清水:ではここでデモをしてみたいと思います。よくあるユースケースとして、文章を要約したり、翻訳したり、メールを作成したりなどがありますが、普段日常のどのようなシーンで私が生成AIを使っているかをご紹介します。
私がよく使うケースとしては、まず、キーワードの意味を確認する場合です。例えばあるミーティングで「売上がパレートの法則に従っていないので、何かしなければいけない」となったとしましょう。「パレートの法則」というキーワードはどこかで聞いたような気がしますが、何だったかなと。キーワードがよくわからないので議論に参加するのも少し難しくなっている。そこでキーワードの意味を調べてみようというわけです。
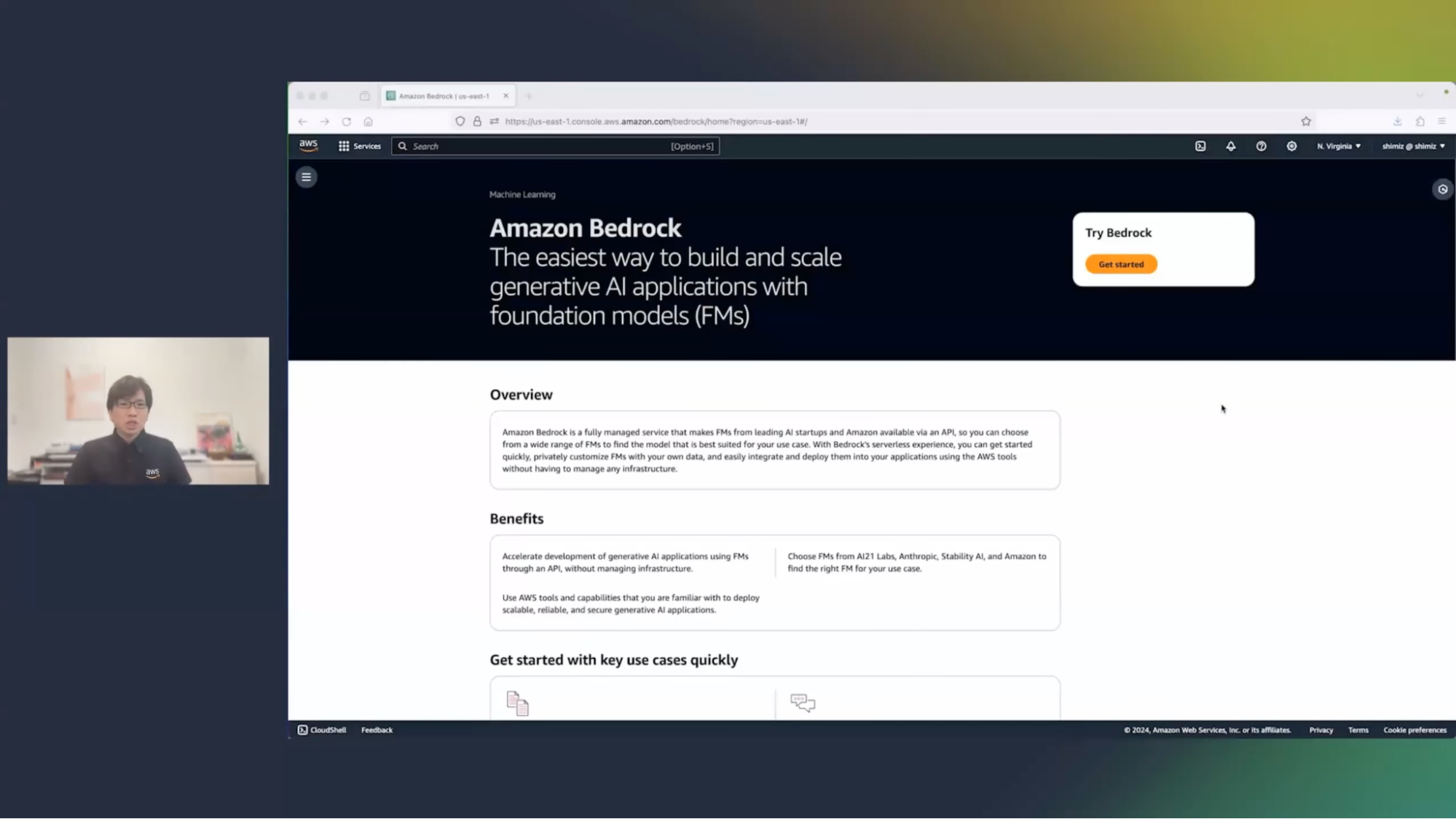
清水:こちらがAmazon Bedrockのコンソール画面です。まず右上にある黄色いボタン[Get Started]をクリックすると、画面に表示されている基盤モデルからお好きなものを使って、アプリケーションの開発を進めることができます。
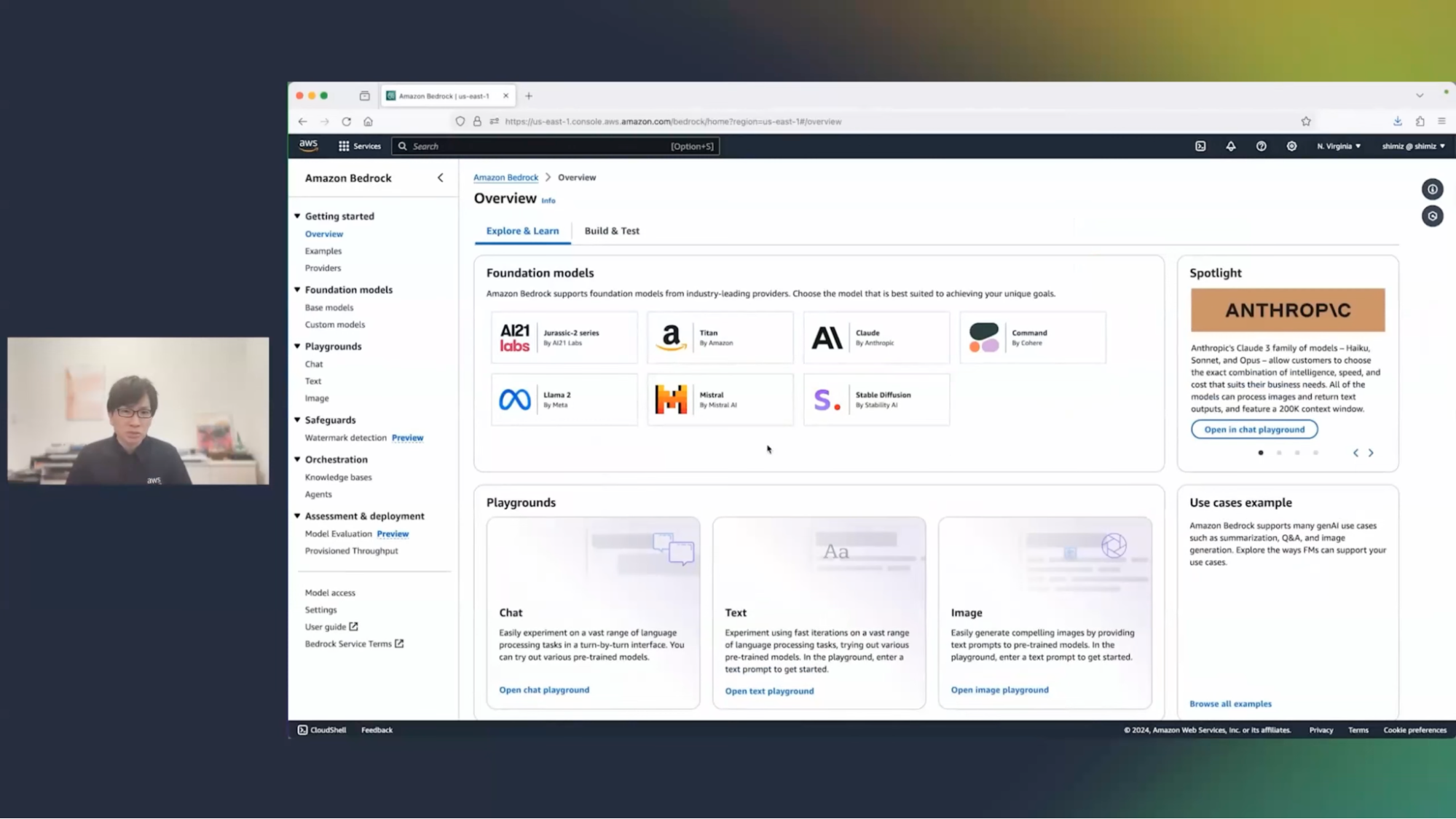
清水:下にあるChat Playgroundの機能(左下枠)を使うとすぐに基盤モデルを試すことができるので、これを使いたいと思います。クリックして次の画面に行きます。
清水:上にある黄色いボタン[Select Model]をクリックしていただくと、基盤モデルを選択できます。
清水:今回はこの中から、AnthropicのCloud 3 Sonnetを使いたいと思います。
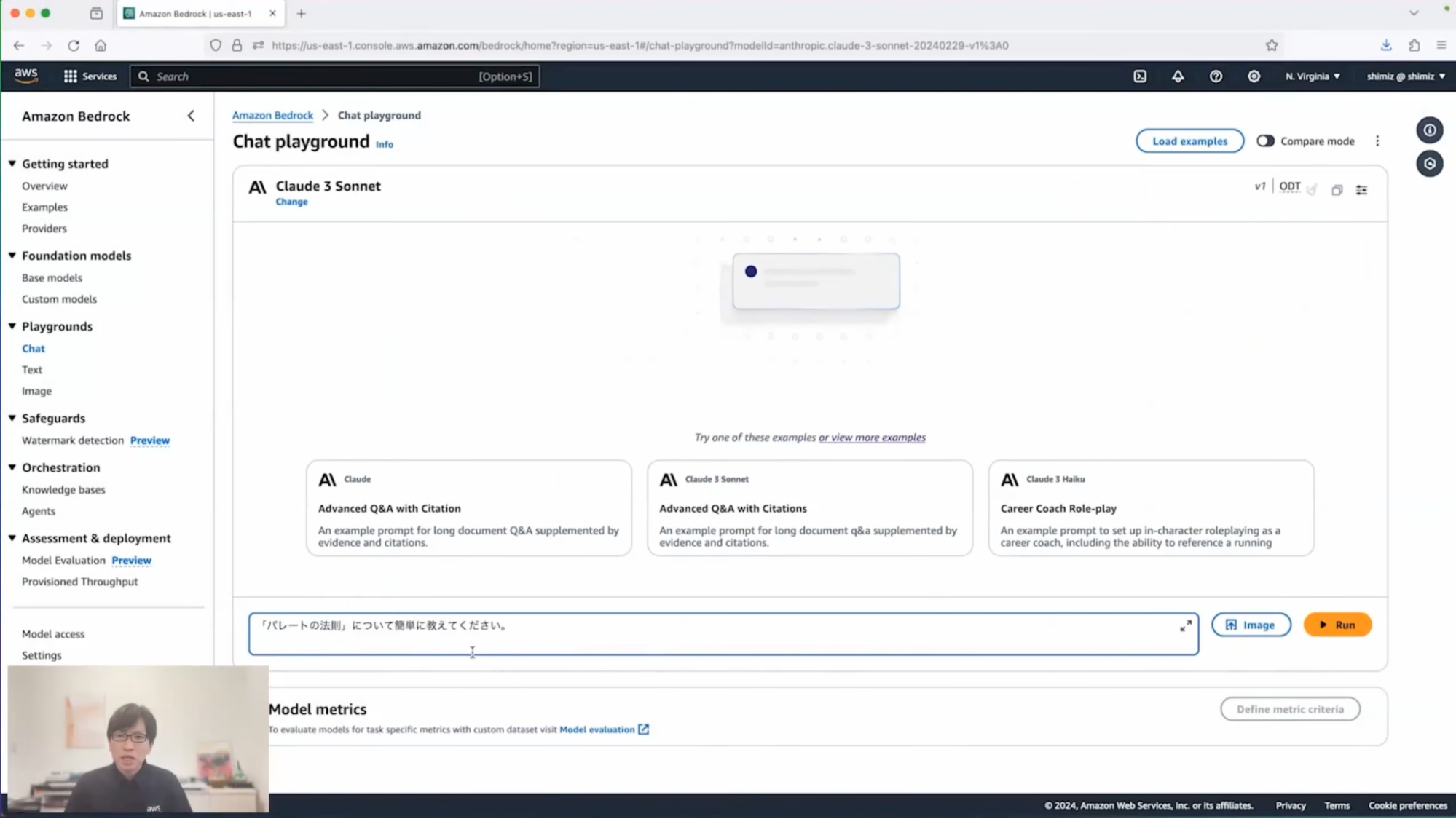
清水:こちらがプロンプトを入力する画面です。下にあるフォームの中に質問を入れてみたいと思います。「パレートの法則について簡単に教えてください」と入力して、右にある[Run]ボタンをクリックして実行してみます。すると、このように回答を得ることができます。
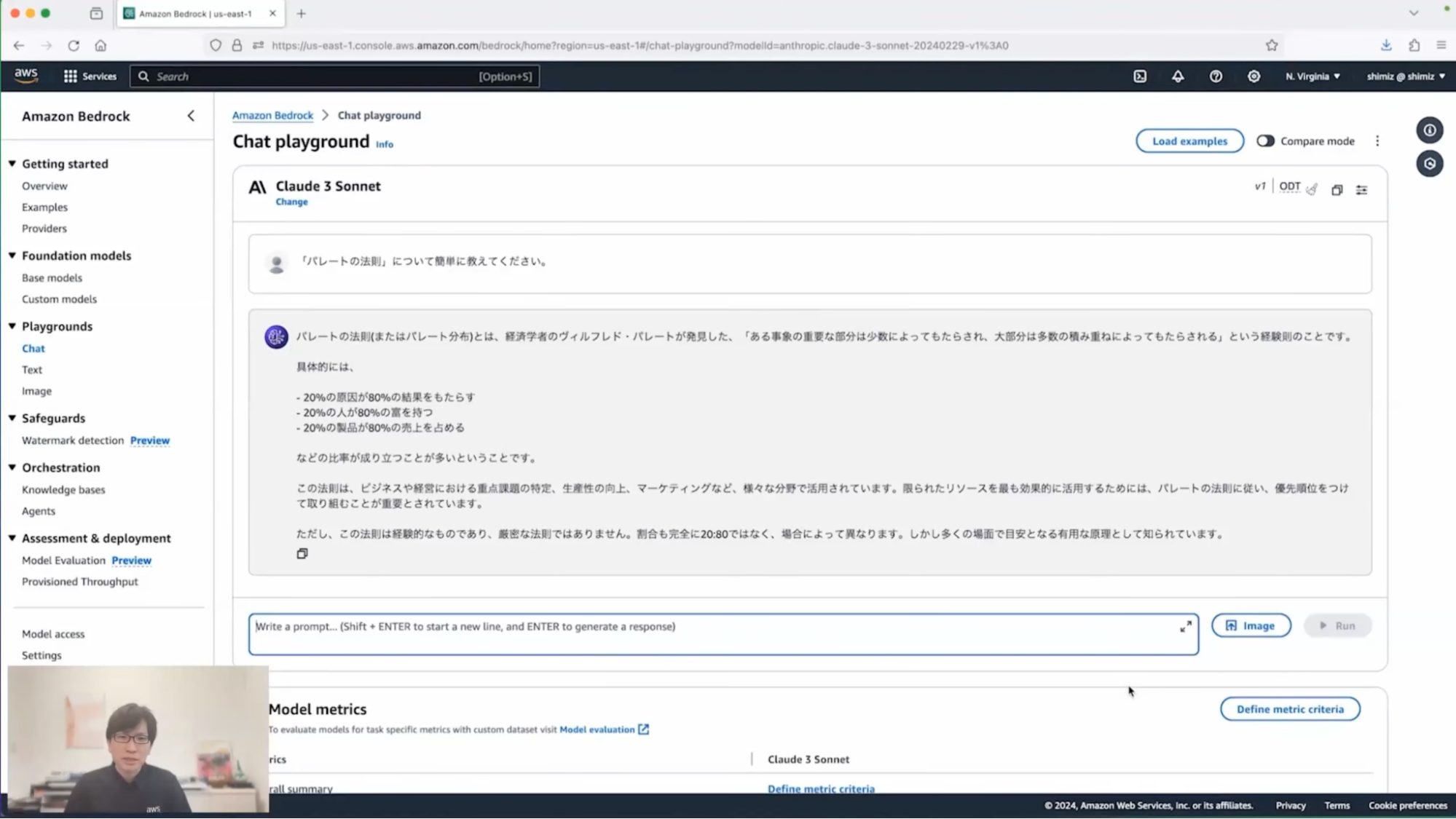
清水:回答が返ってきましたね。ここまでは、いわゆる検索エンジンなどを使っても同様の知見・回答を得ることができると思いますが、ミーティングで議論されている内容について、その良し悪しは判断できていない状態です。そこで追加の質問をしてみたいと思います。
「ある営業チームの売上がパレートの法則に従っていません、この原因は何ですか?またそのメリットとデメリットも教えてください」というのを実行してみたいと思います。そうすると下記の回答が得られます。
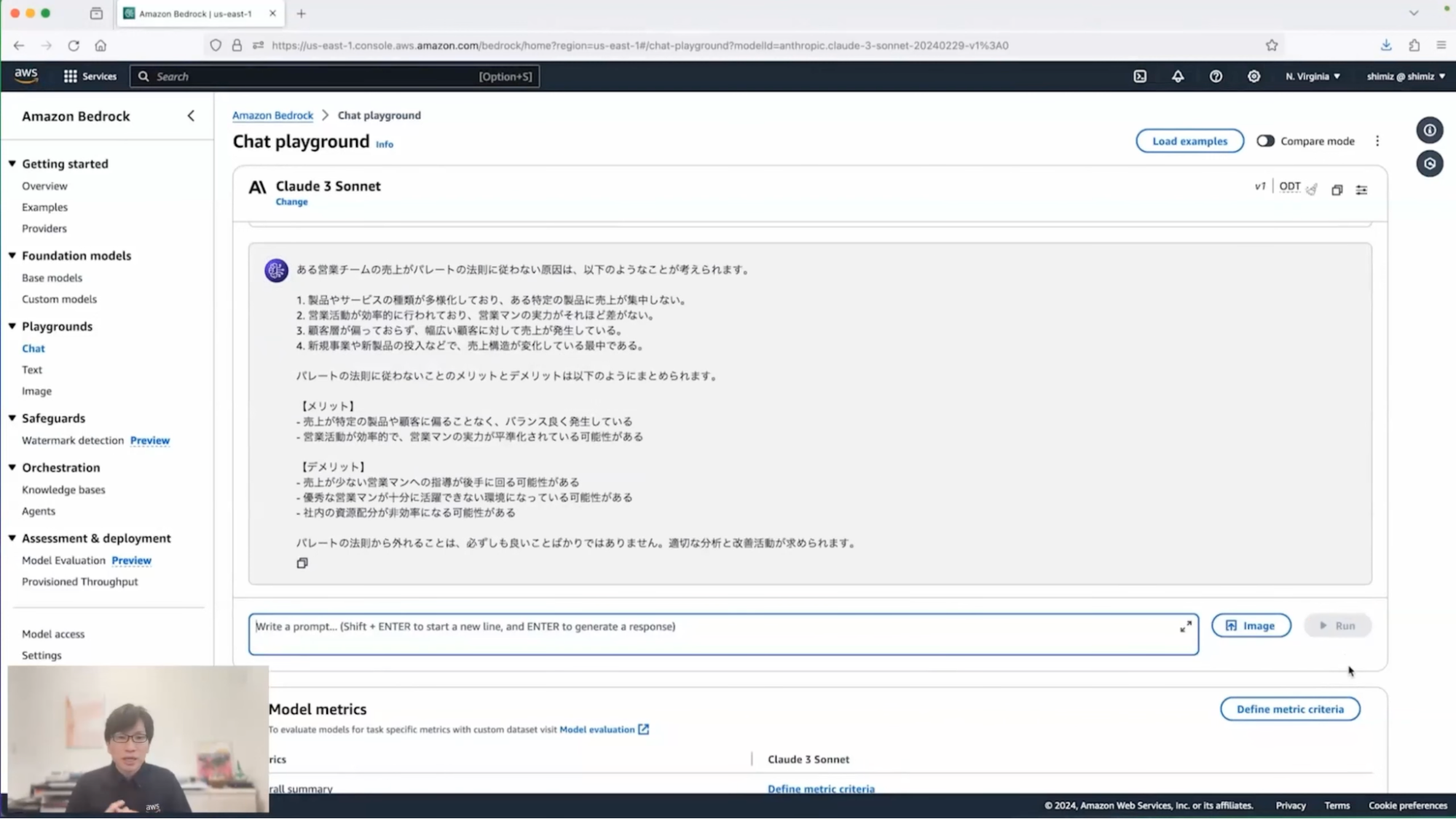
清水:この回答をざっくりとご説明すると、製品やサービスが多様化しているので売上も平準化しているのではないだろうか、営業活動が効率的に行われているので実力の差が出にくいような状態になっているのではないかなど、いくつかの示唆が示されます。
メリット・デメリットのところを見ていただいてもわかりますが、パレートの法則に従わないということが一概に良い/悪いというわけではないということが分かるわけです。当然すべてを鵜呑みにしてはいけませんが、判断するときの1つの参考材料として使うことができそうですね。こういった情報を踏まえて、私もミーティングの議論に参加しやすくなるわけです。
デモ②:キャッチコピー案を作りたい

清水:続いて、キャッチコピーなどの素案を作るようなケースを考えてみたいと思います。例えば、プレゼンテーションのタイトルを締め切りまでに決めなくてはいけません。しかし、あまり時間がなく、良い案も浮かばない。こういったときに壁打ち相手として使えるのではないでしょうか。
ではプロンプトを入力していきましょう。今回は役割や制限をいくつか指定して質問したいと思います。
「あなたの仕事は、提供されたプレゼンテーションの内容に基づいて、創造的で記憶に残るタイトルを生成することです」と制約をつけてから、その後に実際のプレゼンテーションの内容を記載しています。その上で実行します。
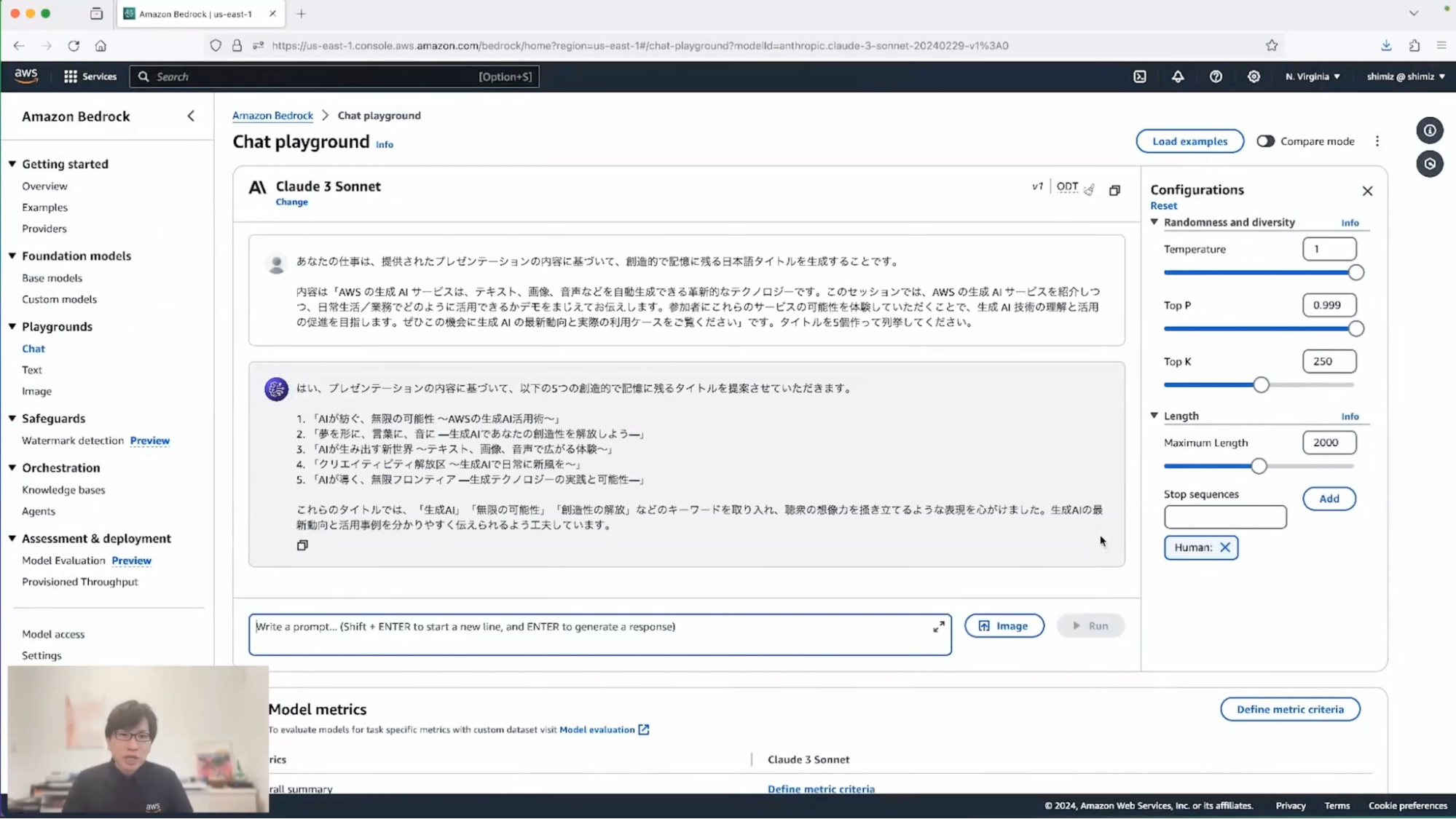
清水:いくつかのタイトルが示されたかと思います。「AIが紡ぐ、無限の可能性」「夢を形に…」など、少し硬派な印象を私は受けました。もう少し日常感がほしいなと思ったので、追加の提案「日常感を増したタイトルにしてください」をリクエストしてみたいと思います。
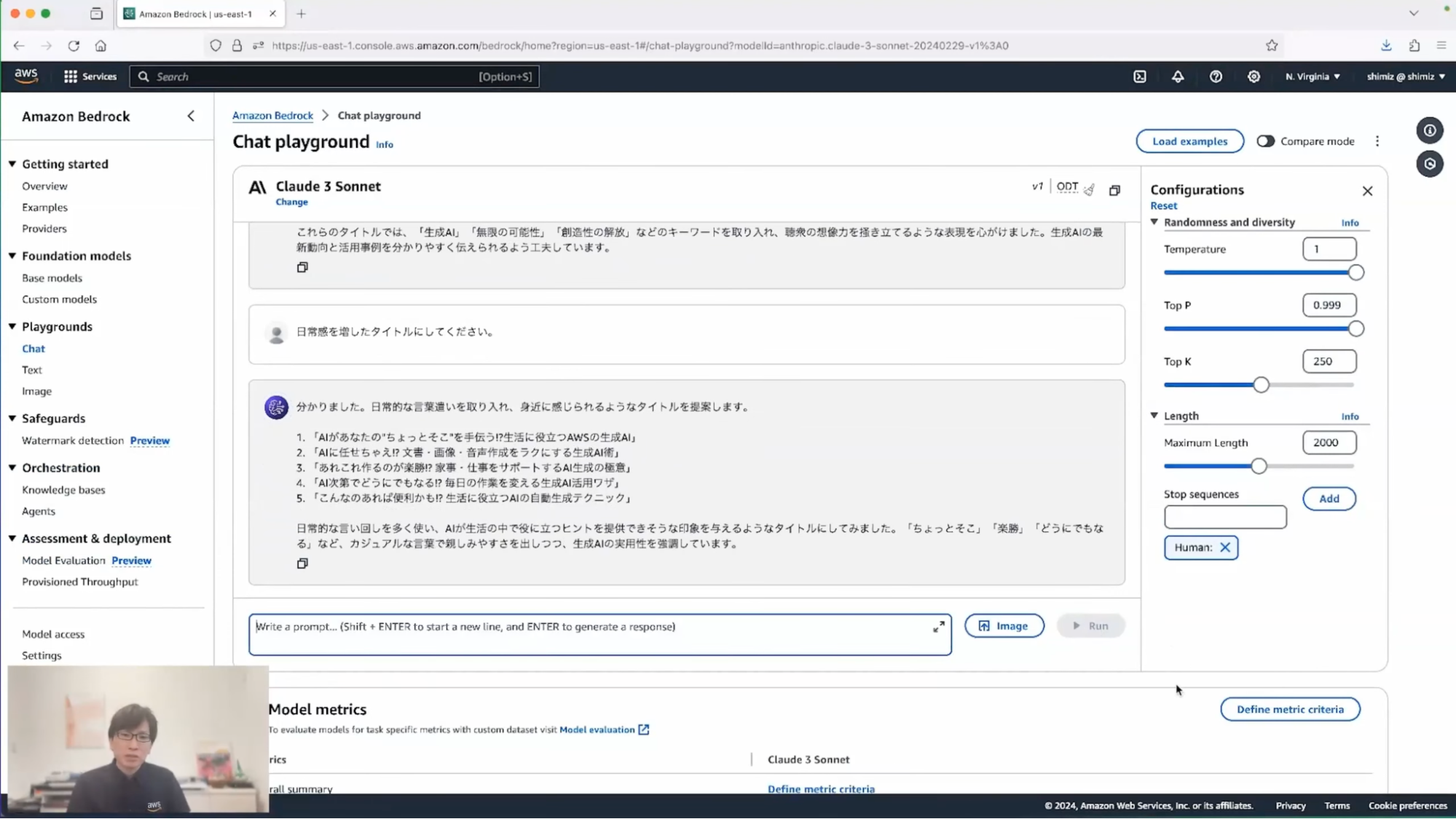
清水:そうすると、またいくつか提案がなされます。「生活に役立つ」とか「こんなのがあれば便利かも⁉︎」と、いくつか私がイメージしていたものに近しい案が出てきました。実は今回のプレゼンテーションのタイトルである「あなたのお仕事をちょっぴり豊かにする生成AI活用術」も、この流れで生成AIを使って検討したものなんです。
デモ③:デザイン案を作りたい

清水:アイデアを一緒に考えていくという観点で、デザインの素案を作りたいようなケースにも活用できるんじゃないかと思います。例えば、マーケティングイベントで配布するノベルティのデザインを考えていて、デザイナーに自分が思い浮かべたイメージを伝えなければいけないようなシーンがあるとします。しかし、言葉だけではうまく伝えることができないので、何か参考画像などを示したい。そういったときに、画像生成AIが使えそうです。
ここではStable Diffusionという基盤モデルを使って画像を生成します。ただし、プロンプトを作るのにもコツがいりますので、まずはClaude 3でStable Diffusionに入力するプロンプトを作ってもらいます。具体的には、「Stable Diffusionでデザイン案を作成しようとしています。そのためのプロンプトを作成してください」といったリクエストを投げてみます。この中に、ノベルティであることや、カラフル、ポップ、ドット柄といった、私のイメージとなるキーワードも含めております。
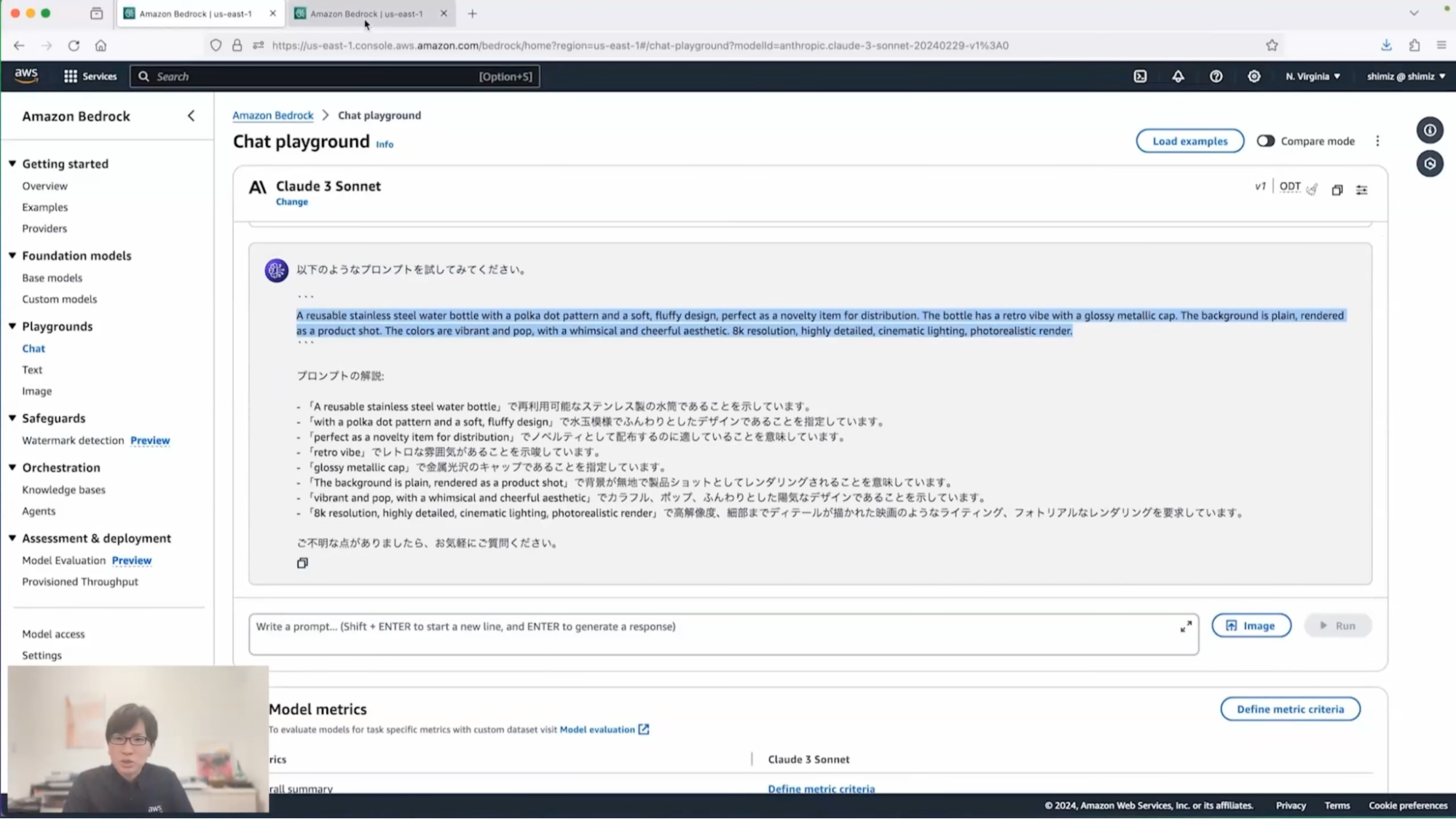
清水:これを実行すると作成されたプロンプトが提案されてきます。今回はこの提案されたプロンプトを使って、画像を生成したいと思います。これをコピーしておいて、次の画面にあるStable Diffusionのプロンプト入力画面にペーストして実行します。
清水:すると、数秒でこのように画像が生成されてきます。これは私がイメージしていたデザインにかなり近いものかなと思います。
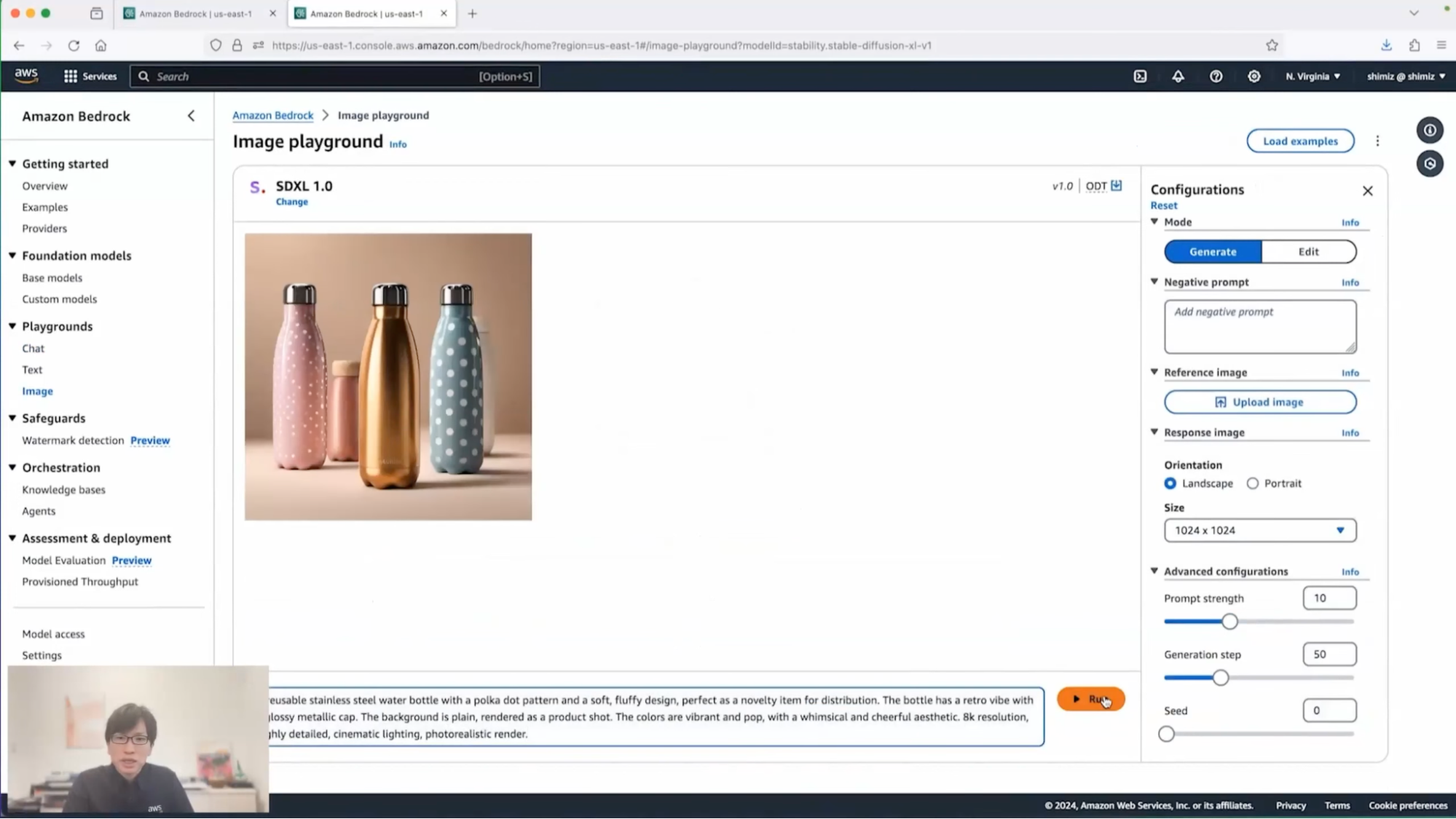
清水:これを使って、デザイナーと会話してデザインを詰めていく。こういったことができるんじゃないかなと思います。
デモ④:SQLのチューニングを手伝ってほしい

清水:最後にご紹介しておきたいのが、SQLのチューニングのお手伝いです。例えばデータベースのマイグレーションなどを進めていて、多くのSQLを確認していかなければいけない場合に、一つひとつ確認していくと当然時間が取られるので、そのお手伝いをできないかというコンセプトです。それではプロンプトを入力していきます。
清水:まずは役割を指定します。「あなたはデータベースアドミニストレーターです。RDSのパフォーマンスインサイトで応答が遅いSQLを確認すると、このようなSQLが表示されました。高速化するために考えてください」といった指示を出します。そしてその下にSQLもそのまま貼り付けています。見ていただくと、このSQLは少し複雑なものだというのがお分かりかと思います。
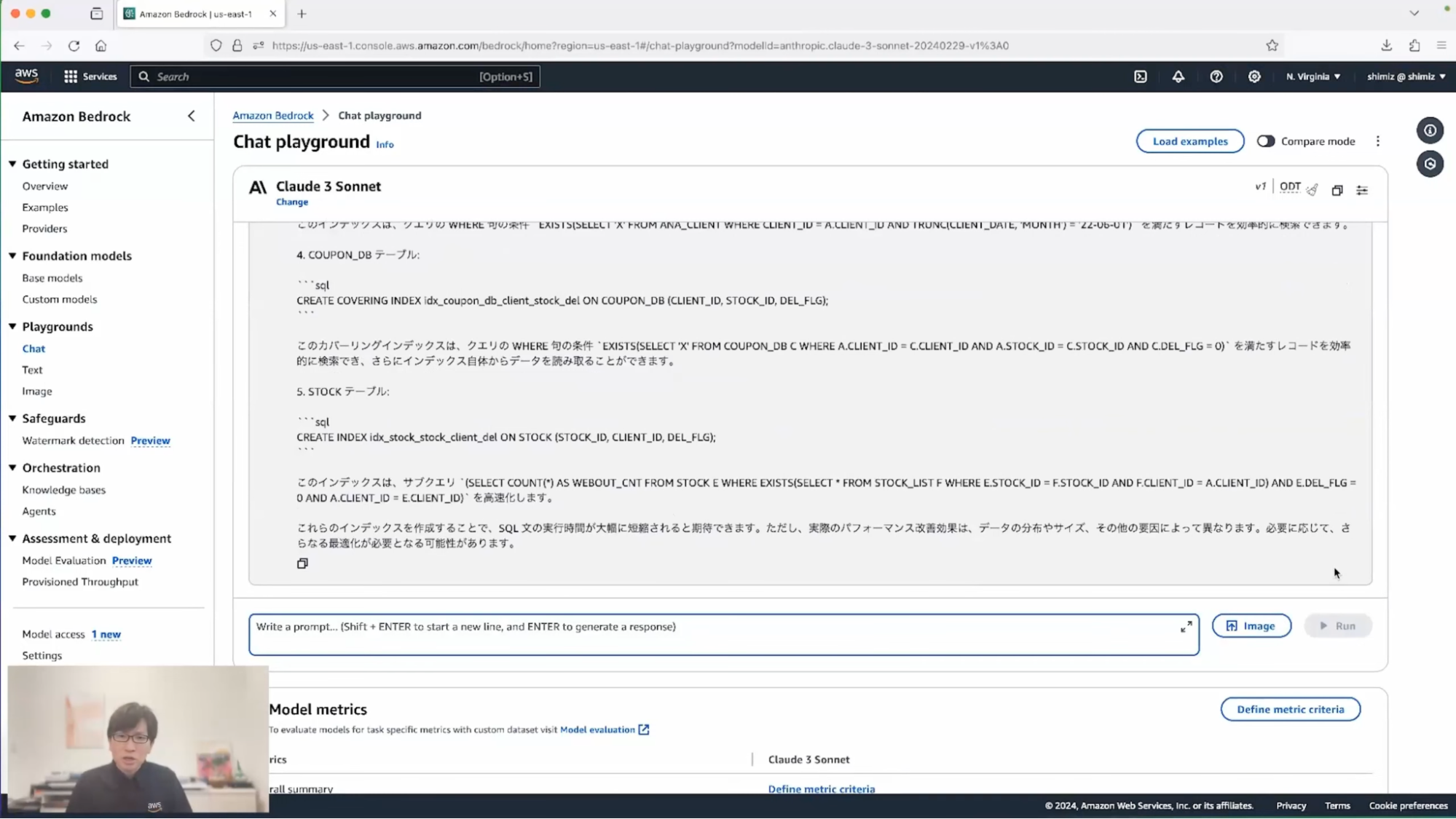
清水:これを実行すると、いくつかのCREATE INDEX文が提示されています。先ほどのSQLを見て一個一個確認していくと当然時間がかかると思いますが、この提案を使えば数秒で改善の方針を検討できるのではないかと思います。ここで出てきた提案をレビューして、使えるものは使うことで、さらに効率化できるのではないでしょうか。
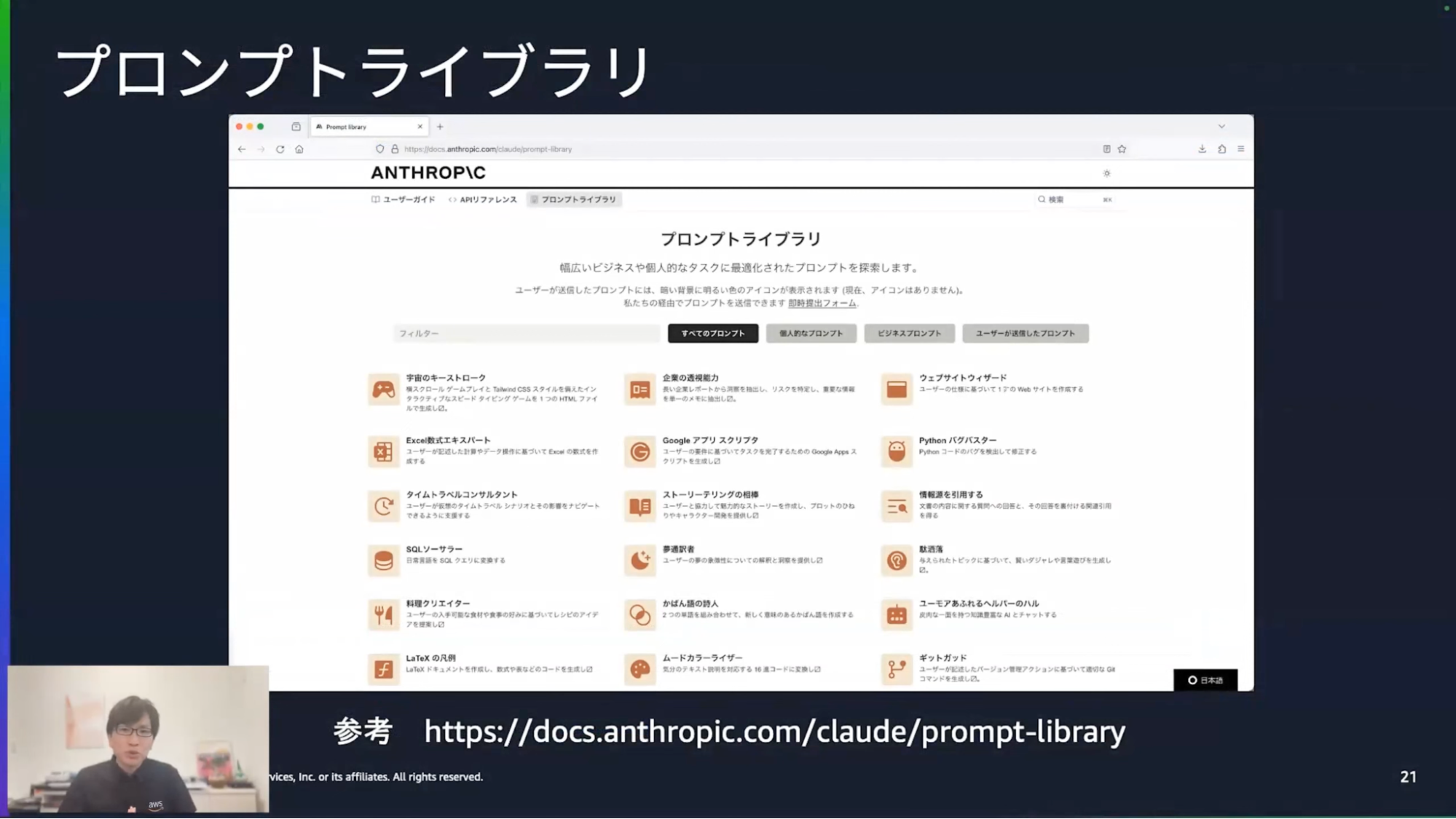
清水:今回はシンプルなデモということで、自然言語をそのままプロンプトに入力して試してみました。詳しいプロンプトの使い方については、ぜひAnthropicさんのプロンプトライブラリも見ていただけると良いのではないかなと思います。様々なアイデアが詰まっておりますので、ぜひ活用してみてください。
生成AIとデータの組み合わせの残り3パターン
清水:ということで、1つ目のプロンプトエンジニアリングについて、デモを交えながら説明していきました。ここからは残り3つのパターンについても、簡単にご紹介していきます。
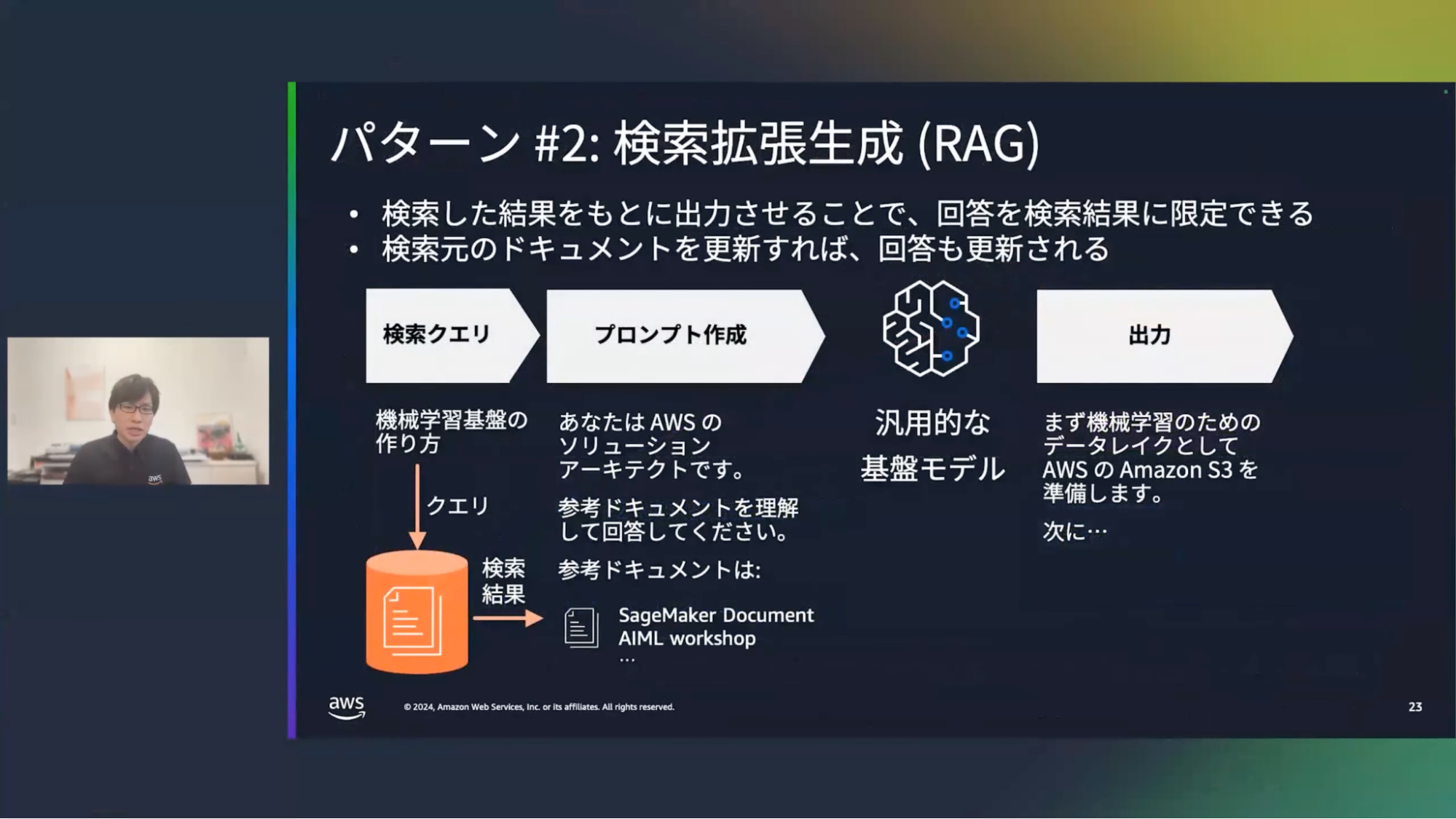
清水:2つ目の検索拡張生成(RAG)ですが、先ほどのプロンプトエンジニアリングが決め打ちで役割や制約を指定していたのに対し、RAGは入力に対してドキュメントを検索し、その検索結果に基づいて出力する回答を生成します。
例えば、AWSの技術ドキュメントやワークショップのコンテンツなど、事前に対象とするドキュメントなどをデータベースに保存しておく必要があります。
プロンプトエンジニアリングに比べてリッチな情報を持っているので、さらに精度が高まります。また参照情報も示すことができるので、回答が本当に正しいのかどうかを確認することができる点もポイントになります。さらにドキュメントが更新されたとしても、参考ドキュメントも更新されるので、最新の情報に照らし合わせて回答を得ることができます。社内のナレッジベースなどに活用できるパターンです。
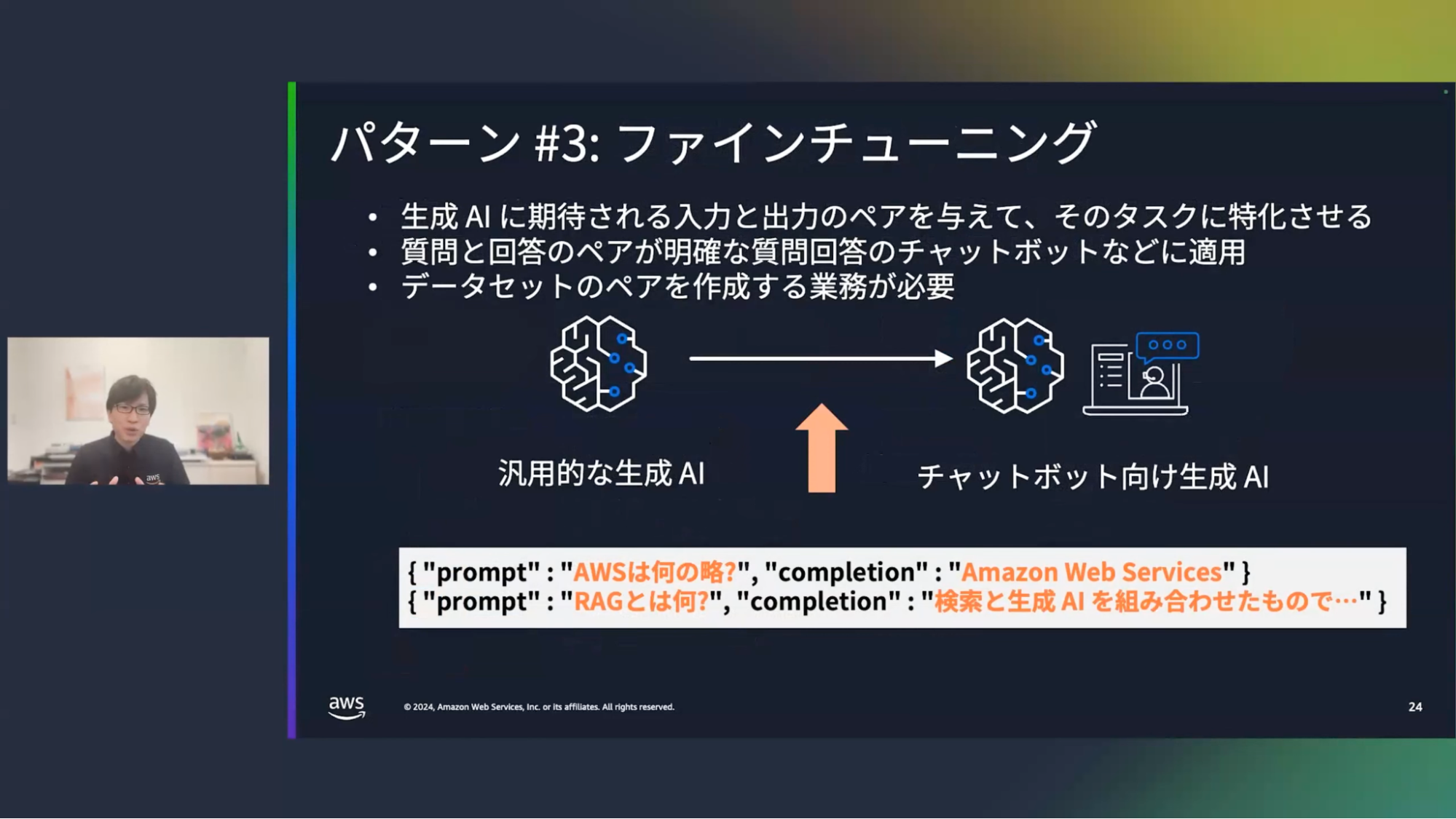
清水:続いて3つ目、ファインチューニングです。汎用的な基盤モデル自体をカスタマイズする手法です。生成AIに期待される入力と出力のペアを事前に与えておいて、そのタスクに特化させることができます。チャットボットであれば質問と回答のペアを与えることで、より明確な回答にすることができます。ただし、事前にデータセットのペアを作っておく必要があります。
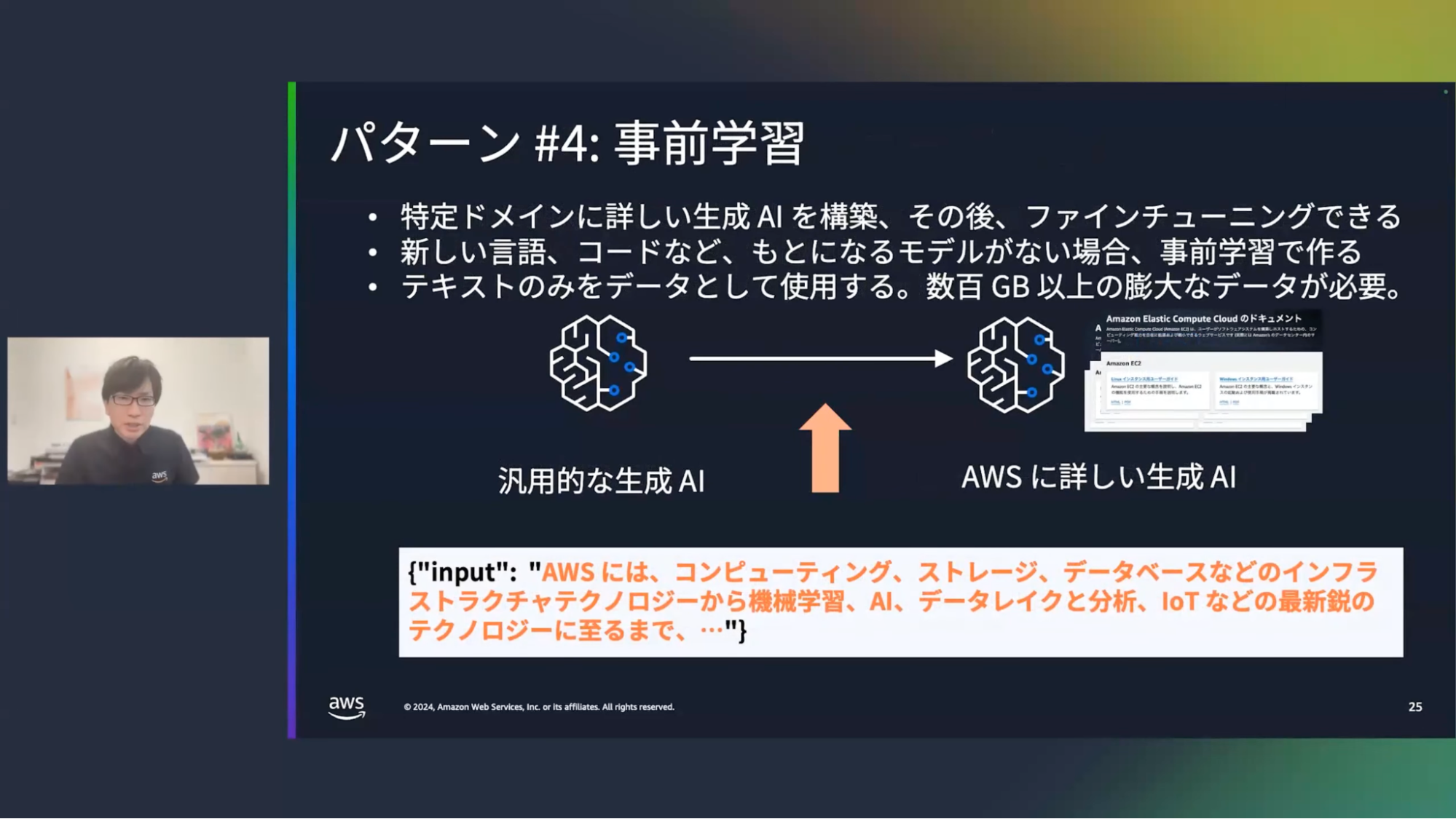
清水:4つ目は、事前学習です。これは特定のドメインに詳しい生成AIを構築するものです。基盤モデル自体を作り変えることになるので、時間やコストはかかります。これは主に、未知のドメインを扱うときに必要になります。例えば、日本語は汎用モデルでも使えますが、例えばあまり使われていない言語であったり、プログラミング言語などを扱う際には、この事前学習をする必要があります。データセットとしては、数百ギガバイト程度の膨大なテキストデータが必要になってきます。
まとめ
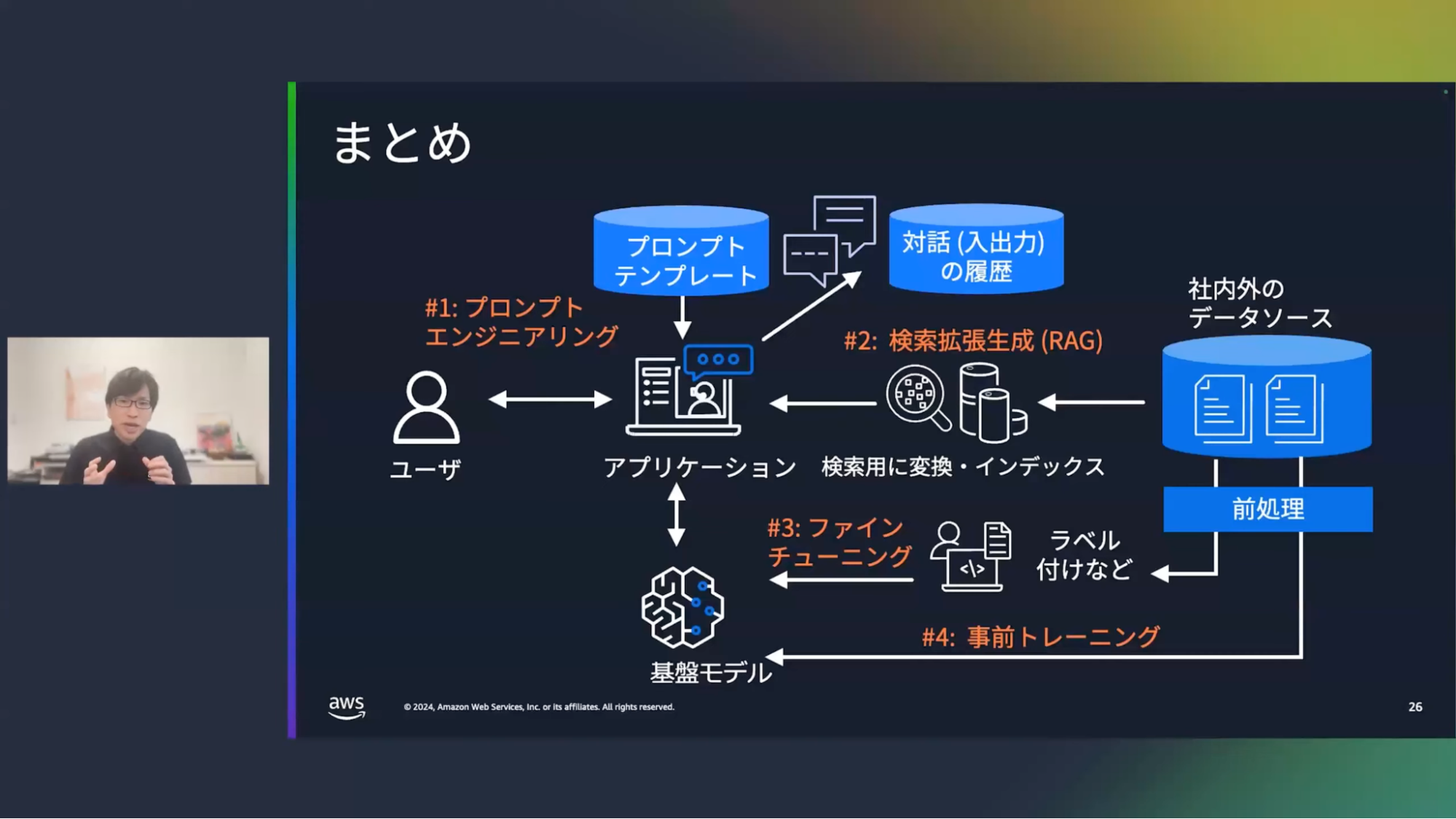
清水:では、まとめていきたいと思います。このセッションでは、生成AIとデータの4つのパターンを説明してまいりました。また、日常で生成AIを使っていただくために、プロンプトエンジニアリングを使ったアイデアをご紹介してきました。
生成AIを活用できるシーンはアイデア次第で様々あると思うので、まずAmazon Bedrockなどを使って試していただくのが良いのではないかなと考えております。
そしてその中から、皆さんの業務を効率化する方法を見つけていただいて、実際に生成AIのアプリケーションを作っていただくことができると思います。
まずは生成AIを使って試して、皆さんの日常をちょっぴり豊かにしていただきたいと思います。

清水:最後に、少しだけご紹介させてください。AWS Summit Japanが6月20日に幕張メッセで開催されます。150以上のセッション、展示、ハンズオンなど、180以上のコンテンツを用意してお待ちしております。QRコードからティザーサイトをご確認いただくことができます。私もブースなどにおりますので、是非、皆さまにご参加いただければ嬉しいです。以上ありがとうございました!
文:長岡 武司