

素材の有無に関わらず、プロンプトから生成できるマルチモーダル動画生成AI

――はじめに、普段の画像および動画の生成AI活用状況について教えてください。
出口:画像生成AIは、公私共に結構頻繁に使っています。プライベートでは、ひどい肩こりのために首まわりの解剖図を生成してもらって「おそらくこの筋肉が張ってるんだな」と確認したり、自分の写真をベースに髪型や洋服のコーディネートをシミュレーションしたりしています。そうした日常使いから業務への応用まで、日々アイデアを試しています。
動画生成については、SoraやGeminiの動画生成がリリースされて話題になったタイミングで触ってみて、一通り試して終わりましたね。日常的に使い込むまでには至りませんでした。
――今回「Happy Horse」で様々な機能を試してみて、どのように感じましたか?
出口:画像生成との組み合わせで最初のシーンフレームを上手く作れれば、狙ったシーンの動画作成につなげられそうで、そのフローなら様々なことができそうだと感じました。個人利用はもちろん、業務利用の可能性が一気に広がりそうですね。
――細かいレビューに入る前に、「Happy Horse」の大まかな機能について教えてください。
出口:前提として、「Happy Horse」をすぐに試すには、公式サイト上から直接生成する方法と、Alibaba Cloud Model Studio上で生成する方法があります。前者が個人クリエイター向けのシンプルな一般公開版なのに対して、後者は主に開発者や企業向けが想定されています。非同期API方式でタスクを作成してIDを受け取り、結果が出るまでステータスを問い合わせる仕組みになっているため、アプリや業務フローへの組み込みに向いていると思います。今回の検証は、Alibaba Cloud Model Studio上のHappy Horseモデル(HappyHorse 1.0)を利用する形で進めました。
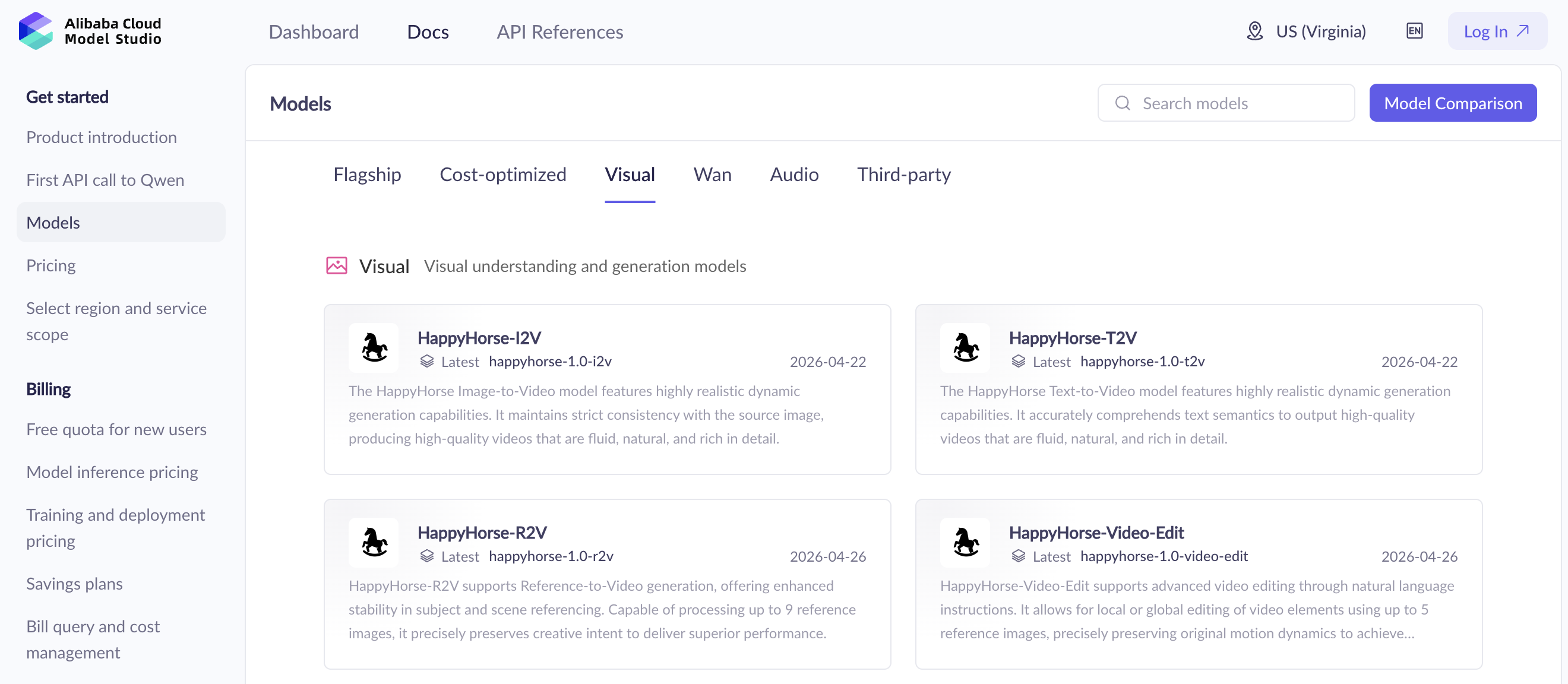
Alibaba Cloud Model Studioで利用できるモデル一覧ページより
――画面に「I2V」「T2V」「R2V」がありますが、これは何でしょうか?
出口:I2Vは「Image-to-Video」の略で、静止画の素材を起点にして動画を生成する方式です。T2Vは「Text-to-Video」の略で、文章のプロンプトでシーンを記述して、そこから直接動画を生成する方式です。そしてR2Vは「Reference-to-Video」の略で、1枚または複数の参照画像で内容をガイドしながら動画を生成する方式です。素材の有無や用途に応じて、これらを使い分ける形で動画を生成していきます。
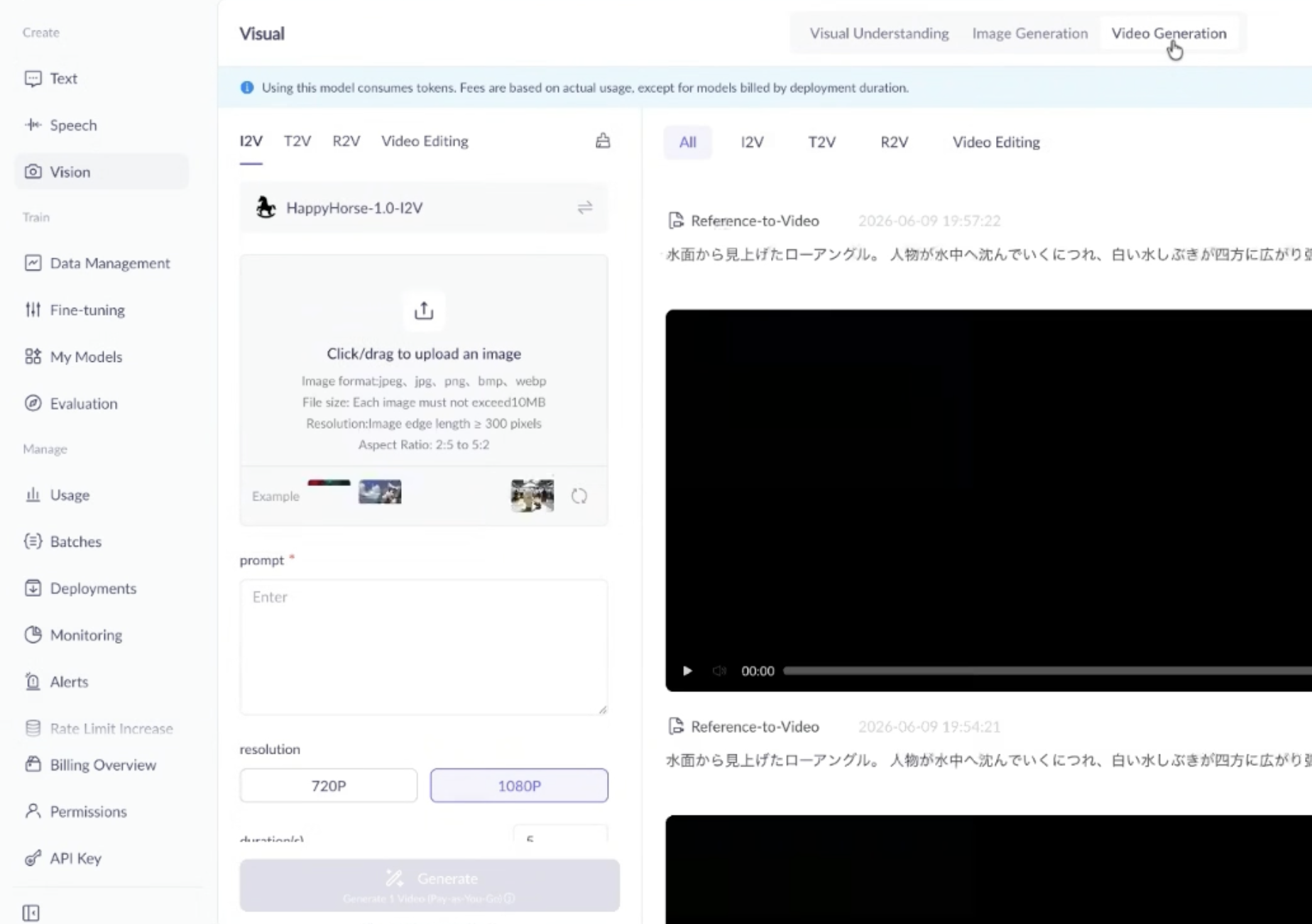
HappyHorse-1.0-I2Vモデルでは、起点となる画像素材をアップロードした上で、プロンプトを入力し、動画を生成する。なお、動画の尺は3〜15秒のいずれかで指定できる
検証①:T2V(テキスト→動画)|実写版

――それでは、検証された結果を順に見ていきましょう。まずはT2V(Text-to-Video)について、プロンプト追従性の検証結果を教えてください。
出口:最初に作ったのが、高速道路を走るスポーツカーです。試しに超高級車ブランドのブガッティ(Bugatti)をモチーフに、「青のブガッティで」と指定しました。

出口:形としては結構ブガッティっぽさが出ていて、ちゃんと高速道路感のある疾走シーンになりました。ローアングルという指定も意図通りです。ただ細かく見ると、ロゴは「ぽい」だけで正確ではなさそうですし、シーンによって右側通行・左側通行が入れ替わっているなど、何点か違和感はありました。
――細かいところは一旦置いておいて、本当にこの3行だけで生成したんですよね。すごいですね。
出口:SoraやGeminiが出てきたときも「思ったよりすごい」と感じましたが、Happy Horseを使った第一印象は、さらに上の「これほどクオリティ高いものができるんだ」でした。
別のシーンでは、雨の表現をチェックしたくて、雨の路地裏を歩く女性の動画も生成してみました。

――こちらも、漢字と韓国語が混ざったような看板は置いておいて、リアルな仕上がりですね。
出口:傘から雨の雫が落ちる様子とか、良い感じに仕上がっていますよね。ただ、僕はそれほど違和感はなかったのですが、後で同僚から「歩き方が男性っぽい」という指摘がありました。特に最後の足元のカット、つま先がやや外側を向いており、足の運び方などからも、たしかに男性風の歩き方だなと感じます。
――たしかにそうですね。
出口:個人的なお気に入りは、マンタ(オニイトマキエイ)の動画です。小魚が途中から急に登場する点に違和感があるものの、マンタそのものは非常にリアルに生成されました。個人的に、今回の検証で一番のお気に入り動画です。
――美しい感じに仕上がっていますね! 言われないと、AI生成だとわからないレベルですね。
出口:実写だともう一つ、ファンタジー世界の魔法演出の動画も作ってみました。

――まさに、ファンタジー映画みたいな雰囲気ですね。
出口:こういうファンタジー系の動画は、生成AIが特に得意な印象ですね。おっしゃる通り、映画のワンシーンでありそうな感じに仕上がりました。
検証②:T2V(テキスト→動画)|アニメ版
出口:続いては、T2V(Text-to-Video)でアニメも作ってみました。まずはこんな感じのものを作ってみました。
――どこか懐かしく、温かみのある手描き風の絵柄ですね。
出口:そう思って、プロンプトの「セルアニメ調」の部分を「某アニメーションスタジオ風」に差し替えて実行してみました。
※一部、プロンプトの表現を編集
――おお!それっぽい感じになりましたね。
出口:テイストの微妙な違いがちゃんと表現されている感じがして、ここは上手く調整してくれるんだなと感じました。
あと別のタッチとして、水彩タッチの蒸気飛行船も作ってみてもらいました。

出口:よく見るとプロペラ部分が止まっていたり変な動き方をしていたりしますが、そこだけ改善されれば、「何かの作品のワンシーン」と言われても違和感のない動画になっています。
検証③:I2V(画像→動画)
――続いて、静止画を渡して動画化するI2V(Image-to-Video)の検証結果を教えてください。
出口:まずは、Qiitaのマスコットキャラクター「Qiitan(キータン)」の画像を渡してみました。
(添付ファイル)



――おお、それっぽい感じでロボット化されていますね。
出口:泣かせてみた時もしっかり泣いてくれて、キャラクターの形状を大きく外すことなく動かしてくれたのはすごいなと思います。素材をちゃんと生かしてくれている感覚がありますね。
(添付ファイル)



出口:ちなみに、笑っている方は、比較としてGemini(Veo 3.1)にも作ってもらいました。

出口:Geminiはかなり別物のロボットになってしまって、画像への追従度合いはHappy Horseの方が高いと感じました。
――結構アレンジされていますね…。
出口:より業務利用を想定して、イベントの告知バナーの動画版も作ってみました。こちらも、Happy HorseとGeminiで比較してみたのですが、平面的なクリエイティブを動かす検証では、Happy HorseでもGeminiでも、同じようなクオリティになった印象です。
あと、自分の写真を使ってファンタジー風の覚醒シーンを作る検証もしてみました。
(添付ファイル)

↓Happy Horseの結果

↓Geminiの結果

――Geminiは急に体の向きが変わるので違和感がありますが、Happy Horseはスムーズにシーンが進みますね。
出口:個人的には、どっちも顔が変わってしまうのは気になりましたが(笑)。服のロゴやダボっとしたシルエットなど、服装まわりはうまく再現してくれた印象です。
検証④:R2V(内容ガイド→動画)
――続いては、1枚または複数の参照画像で内容をガイドしながら動画を生成するR2V(Reference-to-Video)の検証結果を教えてください。
出口:まずは、先ほどのQiitanを使って、3Dアニメーションの代名詞とも言えるオープニングムービーのような動画をめざして生成してみました。
R2Vの前に、まずはI2V(静止画を渡しての動画化)で作ってみた結果がこちらです。
(添付ファイル)

※一部、プロンプトの表現を編集

出口:文字ロゴがQiitaではなく「Qita」になっているので、全体的にNGが多かったです。これに対して、Qiitaの文字ロゴも加える形でR2Vに投げた時の結果がこちらです。
――プロンプトで指示したオープニングムービーのテイストに近づきましたね!
出口:そうですね、概ねこんな感じで作ってもらいたいというイメージに近づいたと思います。ただ、Qiitanのアニメーションは結構難しいようで、手足が生えてしまうなどの課題がありました。これはどの生成AIでも起きがちな、Qiitanというキャラクターの特殊性もあると思います。
――まあ、これはこれでかわいいので良い気がしますが、キャラクターの一貫性という観点ではNGになってしまいますね。
出口:それからもう一つ、Qiitaロゴを使った別の検証もしてみました。
(添付ファイル)


出口:形は大きく外していないものの、緑のカラーコードが微妙に違っているのが気になりました。
――カラーコードを遵守してくれないのは、別のAIツールでも結構な頻度で発生するなと感じます。
出口:そうですね。プロンプトはあくまでプロンプトで、ハーネスではないので、ちゃんとしたブランド展開用途としては慎重になる必要がありそうです。
検証⑤:リップシンク

――ここまで操作してみて、Happy Horseの強みはなんだと感じましたか?
出口:ここまでの検証で投げたプロンプトは、決して細かい指示内容ではないのですが、それでも概ね期待した内容の動画が生成されているのは、素晴らしいなと感じました。
あと、英語のリップシンク精度も高いと感じます。例えば、私の画像を使って以下のプロンプトを投げてみた結果がこちらです。
(添付ファイル)

――たしかに、ほぼ完璧なリップシンクですね!
出口:これが日本語になると、リップシンク自体はほぼ問題がないのですが、発音が不完全になってしまいました。ちなみに、動画の秒数に応じて適切な文字数にしないと、リップシンクがうまく機能しなかったり、動画として違和感がある感じになってしまうので、注意が必要です。
10秒に対して文字量を詰め込みすぎると早口になってしまい、口の動きが下手な腹話術のように崩壊してしまいますね。かといって少なすぎると、発言として随分ともっさりとするので、いい塩梅にするのが難しいですね。
検証⑥:動画編集
――逆に、上手くいかなかった機能はありますか?
出口:動画編集(Video Editing)機能があるのですが、それはなかなか意図通りにいきませんでしたね。Happy Horseでは、他のAIチャットツールみたいに生成された動画をプロンプトで指示出しして連続的に修正していくのではなく、生成された動画を一度ダウンロードし、再度アップロードした上でプロンプト指示で修正していきます。例えば最初のブガッティ動画について、気になったところを以下のプロンプトで修正指示出しをしました。
出口:何点か修正してほしいところを列挙したはずなのですが、ほとんど反映されず、元の動画と同じような動画が出力されました。
同じ要領で、雨の路地裏を歩く女性の動画についても何点か修正指示を出したのですが、こちらもほぼ反映されなかった印象です。
出口:もちろん、上手くいったケースもあります。次の、アニメーションのシーン変更については、簡単なプロンプトで、他の要素をほぼ保ったまま忠実に反映してくれました。
(添付動画ファイル)


イメージのすり合わせなどでめちゃくちゃ使えそう

――生成時間とコストについて教えてください。
出口:生成時間は1本あたり1〜10分弱で、結構バラつきがありました。コストは、HappyHorse-1.0-T2Vの場合、720pで1秒あたり0.14USドル、1080pで0.24USドルと表示されていました。10秒の動画なら1.4〜2.4ドルの計算ですね。
――一連の検証を経て、率直な感想をお願いします。
出口:実務レベルの“完成品”を求めると、「面白いもの」で止まってしまいそうな印象です。一方で、自分の表現したいものを趣味感覚で作る分には、多少の破綻を妥協できることも含めて、十分すぎるクオリティだと思います。
実務寄りで言えば、映像素材としての活用は結構アリだと思っています。3つのシーンを一度に生成させるより、1シーンずつ指定して作っていく方が適しているので、シーン単位の素材作りですね。あとは映像制作の構想段階。「こういう映像で、こういうシーンがあって」というラフを撮影前に映像化するステップでは、かなり使えそうです。
――改善されると良いと感じたこともあれば、教えてください。
出口:先ほどお伝えした通り、Happy HorseにはChatGPTやGeminiのようなチャット形式で対話しながら動画を修正するUIはなく、一度生成した動画をダウンロードして再アップロードする必要があります。ここは改善してほしいポイントだと感じました。また、生成を途中で止められないのも気になりました。プロンプトを間違えたと気づいても、リロードするしかなくて(笑)。完全従量課金なので、ここは地味にストレスになりそうです。
――企業利用を想定した際、どんなチームに向いていると思われますか?
出口:動画制作を受注する組織が、クライアントと「こういう映像にしていきましょう」とイメージをすり合わせるタイミングなどで大いに活用できそうです。発注側・受注側がお互いの頭の中をすり合わせる段階では、めちゃくちゃ使えそうな印象です。
――ありがとうございます。それでは最後に、Qiita読者へのメッセージをお願いします。
出口:動画生成に限らず、生成AIは体験してみないと人それぞれ感じ方が違いますし、プロンプトの伝え方も違ってきます。まずは触ってみるのが一番手っ取り早いでしょう。そのうえで、動画生成を継続的に使っていくには「作りたいもの」があることが大事です。試しに触って「こういうことができるんだ」と掴んだ後に、「じゃあこれで何を作ろうか」を考えていくのが、一番実践的なアプローチだと思います。