AI分野の世界トップ学会CVPRで論文採択&ワークショップ開催。トップカンファレンスでの実績を重ねる日立の研究者文化とは

コンピュータサイエンスの分野には実に様々な技術カンファレンスがありますが、中でもトップカンファレンスで論文採択されることは、研究者にとっての1つの目標と言えるのではないでしょうか。
今回はその中でも、コンピュータビジョン領域におけるトップカンファレンスがテーマです。日立製作所(以下、日立)所属の研究者による人の行動認識AIに関する論文が、コンピュータサイエンスに関する国際学会で大きな影響力をもつ「CVPR 2021*¹」で採択され、メインカンファレンスで発表されました。また同カンファレンスでは、日立主導で初のワークショップも開催。技術開発の協創とデータセット提供に伴う研究領域活性化に貢献しています。
具体的にどのような技術が採択され、どのような切り口と想いでワークショップが設計されていったのか。関わった2名の研究者に、詳しくお話を伺いました。
プロフィール

社会イノベーションセンタ Lumada Data Science Lab

R&D Big Data and Analytics Solutions Lab.
クロスモーダル学習技術を使い、人の小さな動きを認識

――ご経歴を拝見したのですが、おふたりとも同じ年に新卒入社されているのですね。
孔:はい、私と田村さんとは同期です。ふたりとも映像から人の行動を理解するAI領域の研究開発に携わっています。
――人の行動理解AIとは、具体的にどのようなものなのでしょうか?
田村:ひとことで言えば、私たちが日々見ているような形で、人とそれに付随する物体等の動きを判別して検知する技術です。主に監視映像などの用途で活用されることを想定したものです。
――行動検知については、それこそ各所で様々な発表やソリューションが提供されていると思いますが、おふたりの研究領域は何がポイントになるのでしょうか?
孔:それぞれ論文を発表しているので、まずは私からお伝えします。
2018年にユニット内で行動認識への研究の動きが始まりまして、行動認識AIを作ろうということになりました。
と言いますのも、AIに学習できるデータや、システムができた時にベンチマークするデータを揃えようと動いたのですが、監視映像データセットがほぼない状態で入手がかなり困難だったのです。
――監視映像って外に出るものではないですからね。
孔:だからこそ、まずはデータ整備からはじめることになりました。その際、人物の動きを認識するにはセンサも有効です。資格情報と様々なセンシング情報との相互作用をAIに学習させることで、よりロバストな認識ができるのではないかと考えました。そこで、カメラだけでなくセンサも加え、カメラとセンサの情報を持つデータセットを日立の中で整備していきました。
8ヶ月間ほどかけて企画からデータ収集までを実施し、最終的には合計36,000ほどの行動クリップ映像ができ、世界最大規模のマルチモーダル行動理解用のデータセットとなりました。
その内容は、男女20名にカメラを含む7種類のセンサをつけて、遮蔽などを含む様々な条件下で環境センサと映像の情報を同時に取得したデータです。

公開するデータセットにおける行動のサンプル画像。認識ニーズの高い37種類の行動が対象となり、遮蔽などを含む様々な条件下で、環境センサと映像の情報を同時に取得。当該分野での世界最大規模の行動認識と検出用データセットとなっている。
孔:カメラに映る人の多様な行動を理解するには、カメラの画角と解像度によって認識の難易度が変わったり、動きが微小な映像の判別が困難だったりします。一方、身体装着センサの場合、可視光のような遮蔽問題がなく、細粒度行動への認識も装着部位次第で認識可能となるが、運用時に装着する必要があり、安易に導入ができない場合があります。
そこで私たちは、身体装着センサから得られた信号を映像認識モデルに学習させるクロスモーダル行動認識技術を提案し、視学情報とセンシング情報間の相互作用による学習方法に着目しました。
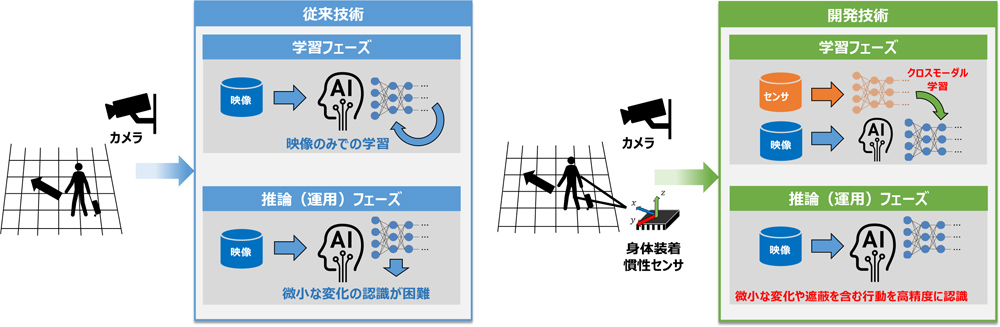
従来技術と開発技術との違い
孔:具体的には、複数種類の身体装着センサから学習に有効な情報を選別が可能となる行動認識モデルを学習し、その出力を重み付き教師情報として作成。映像のみで学習した行動認識モデルへ転移することで、運用時にカメラ映像のみからでもセンサ微小な行動の変化を捉えることが可能になります。
例えば、人混みでの不審行動や、軽量/重量物の運搬時などのわずかな行動の変化差が分類できるようになりました。
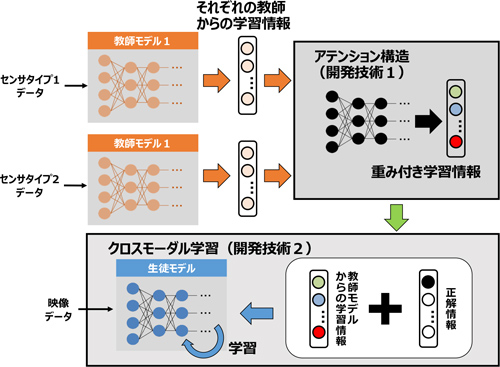
開発したクロスモーダル認識技術の詳細
孔:カメラ映像のみで学習した行動認識技術と比較すると、これまで判別が難しかった行動の認識精度が最大53%向上しました。こちらは、2019年10月29日〜11月1日に韓国ソウルで開催された「ICCV 2019(International Conference on Computer Vision 2019)」で発表し、開発技術の更なる発展に向け、構築したデータセットMMActも無償公開し、現在160以上の大学や研究機関で活用中です。
CVPR 2021採択→メインカンファレンス発表

――次に、田村さんの研究内容もお願いします。
田村:少し個人的な話から入りますが、私が日立に入社した2016年から目標としていたのが、研究者としてどんどん論文を学会に出していくということです。入社当時は、大学のころに学んでいたこととは違う分野だったので、なかなか学会に投稿することができませんでした。でも、2018年に初めて、IEEE主催の「WACV 2019(Winter Conference on Applications of Computer Vision 2019)」に論文を投稿することができました。
その時の内容は、魚眼カメラのような全方位カメラで、うまく人物を検出しようというもの。画像分野での投稿は初めてだったのですが、ありがたいことに採択していただけました。その頃からテーマは同じで、監視カメラから人間行動を理解して役立てる研究を続けていますね。
――1つ目標を達成したということですね。
田村:そうですね。さらに、別のカメラに写っている同一人物を見つける技術に関する論文についても、BMVC(The British Machine Vision Conference)で採択され、セカンドティアの学会には定期的に投稿できるようになっていきました。
今度は「トップカンファレンスに出したい!」と考えて投稿したのが、IEEEが主催するCVPRでした。コンピュータビジョン領域のいわゆるトップカンファレンスです。
画像から人の動作と物体の関係性を検出する技術について投稿し、ここでも採択いただき、メインカンファレンスで発表することになりました。
――素晴らしいですね。具体的には、どのような技術になるのでしょうか?
田村:一言でお伝えすると、人と物体の2つの場所を特定して、その関係性も特定するというものです。
画像内で離れた位置にある人と物体の特徴量や、その物体に関連する別の物体の領域を動的に選択。特徴量をAIが画像から抽出・集積することで、人の動きと物体の関係性を高速・高精度に検出できるようになる技術ですね。
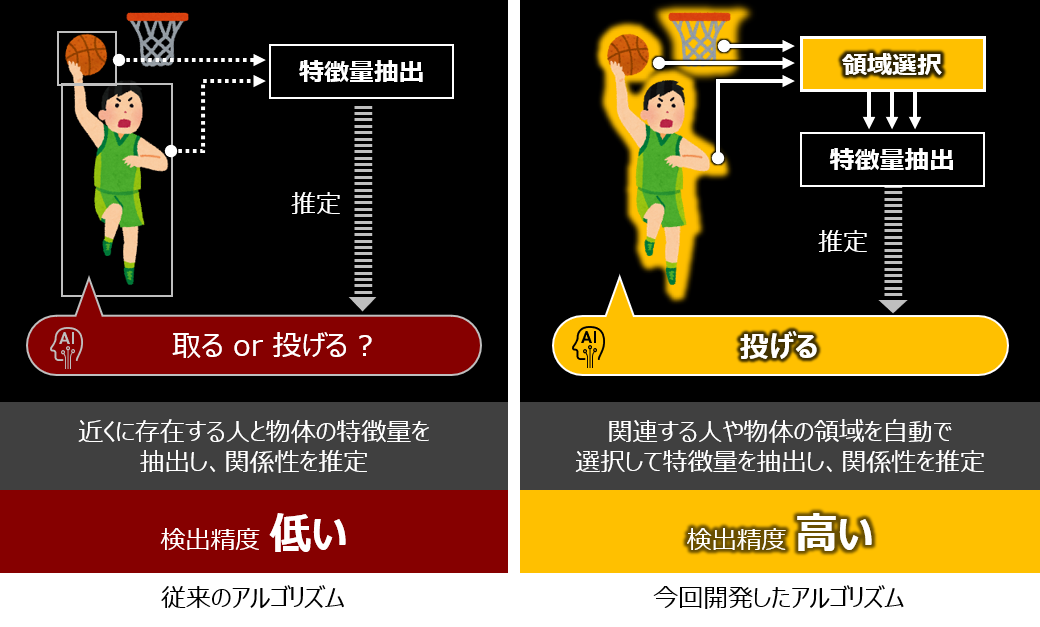
田村:従来の技術では、1つの画像に色々な情報が含まれている場合、人と物体の特徴量をうまく抽出できず、画像が示す意味や事柄を正確に認識することが困難でした。
例えば画像のように人がバスケットボールをシュートしようとしている場合、人のポーズとボールだけでなく、バスケットゴールが近くにあることが重要な情報の1つとなります。しかし、従来の技術では左の画像のように認識対象の人とボールをメインに特徴量を抽出していたため、対象以外のコンテクスト情報を掴みにくい欠点があるわけです。
田村:これに対して、どこに注目すれば良いかをAIが自ら判断し、それを使って目的を達成するというアプローチを取ったのが、今回発表した技術です。特徴抽出にCNN*²だけでなくTransformer*³も活用し、人の動作と物体の関係性を検出する「QPIC*⁴」という技術を提案しました。
この技術では、右の画像のようにAIがバスケットゴールにも着目した方がよいことを自ら判断して特徴抽出をしてくれます。これにより検出精度が改善するわけです。
田村:Transformerの採用もあり、人の動作と物体の関係性を検出するAIとしては、世界最高の検出精度(2021/4/7時点)を達成できました。
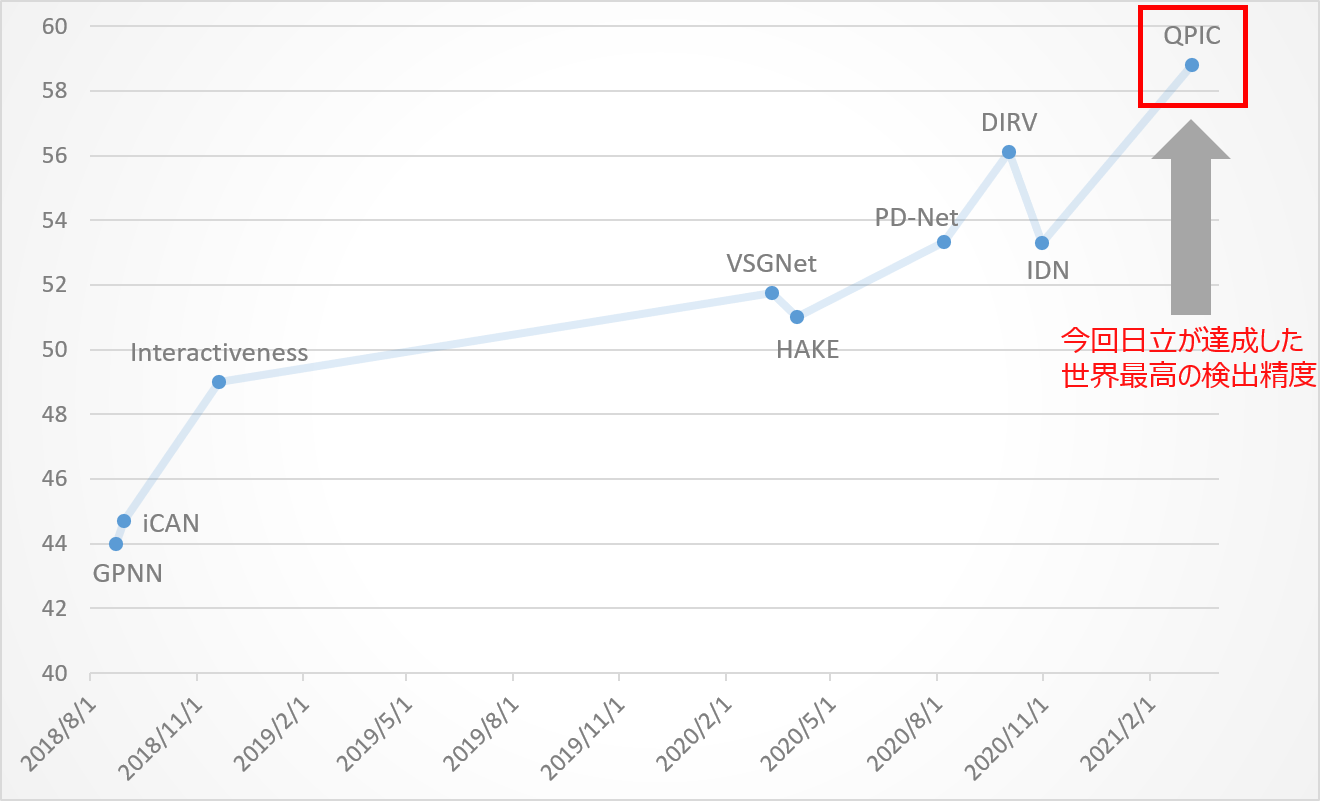
人の動作と物体の関係性を検出する技術のベンチ―マークデータセットV-COCOにおける検出精度の推移。検出精度は58.8%(Paper With Codeの情報を用いて日立が作成)
田村:もともとは、荷物を追跡したいというご要望から始まった研究でした。空港などで怪しい荷物があった際に、所有関係を自動で認識することで、荷物の所有者を迅速に特定するということですね。
孔:田村さんが発表したこの技術によって、人物と荷物の関係性を理解できるようになるので、映像からより深い理解を得ることが期待されています。
チームは異なりますが、アウトプットとしては一緒に監視映像ソリューションとして使いたいと考えていますし、より高度なサービスも提供できるのではないかと思っています。
CVPRで初のワークショップ開催

MMAct Challengeのデータセットより
――おふたりとも数年前よりトップカンファレンスでの実績を作られているわけですが、採択される技術のトレンドや、参加企業・参加者の変化などについて教えてください。
田村:技術については「高い精度を出す」ことがひとつのトレンドになっていると思います。今回私が発表した内容は、すごく複雑で画期的なアルゴリズムを出したというわけではありません。どちらかというと、潮流に乗って、スピード感をもって実装し、且つ高い精度を出せた。それが特徴ですね。
参加企業については、中国企業による投稿数がここ数年でどんどん増えていまして、確実に力を伸ばしていると感じています。一方、日本企業はまだ投稿数が伸びていません。徐々に増えているとは思いますが、まだまだ足りないなという印象ですね。
孔:コロナ以前はオフラインでの開催でしたが、例えばCVPRを見ると1万名近く参加者がいて、規模は非常に大きいです。企業を見ても、米国GAFAや中国BATなど、皆さんが知っているような大手テック企業が軒並みメインスポンサーとして参画しています。日立もスポンサーの1社として、コンピュータビジョンを含めた様々なトップ学会への投稿を積極的にサポートしています。
私たちのチームも今年度、ワークショップを主催しました。
――それはどのカンファレンスにおいてでしょうか?
孔:CVPRに併設されているワークショップの中です。2016年から、CVPRの中でActivityNet*⁵と呼ばれる行動理解に関する権威的なワークショップが開催されています。トップカンファレンスの中のトップコミュニティで、マイクロソフトやGoogleなど、最先端のAI企業がかなり力を入れて参加しています。
オープンイノベーションを通じて、行動認識技術の進化を加速する狙いのもとに、
日立として、ActivityNetのコミュニティと連携して、クロスモーダル行動理解向けのワークショップを一緒にCVPRへ提案できないかと働きかけを行いました。産学横断(日立以外、国立情報研究所、産業総合研究所、大阪大学)のチームを結成し、企画からプラットフォームの整備までゼロから行い、日立がCVPRで初のワークショップ開催となる「MMAct Challenge 2021」を運営することになりました。
孔:MMAct Challenge 2021は、MMActデータセットを用いた映像内行動認識精度を競うコンペティション型ワークショップです。先ほどお伝えした画角変化、遮蔽、機微な動作の差異への映像内行動認識のチャレンジ課題に焦点を当てており、2つのサブタスクが用意されています。
――それぞれどのようなタスクですか?
孔:1つ目は、与えられた行動映像セグメントに対して、それがどんな行動かをAIに認識させるというもの。そして2つ目は、長い映像の中で、行動の始点(Start)と終点(End)、そして内容(What)を全部教えるというものです。2つめのタスクの方が実用性が高いのですが、その分、技術的な難易度も高い。だからこそ、2段階のサブタスクで設計を行いました。
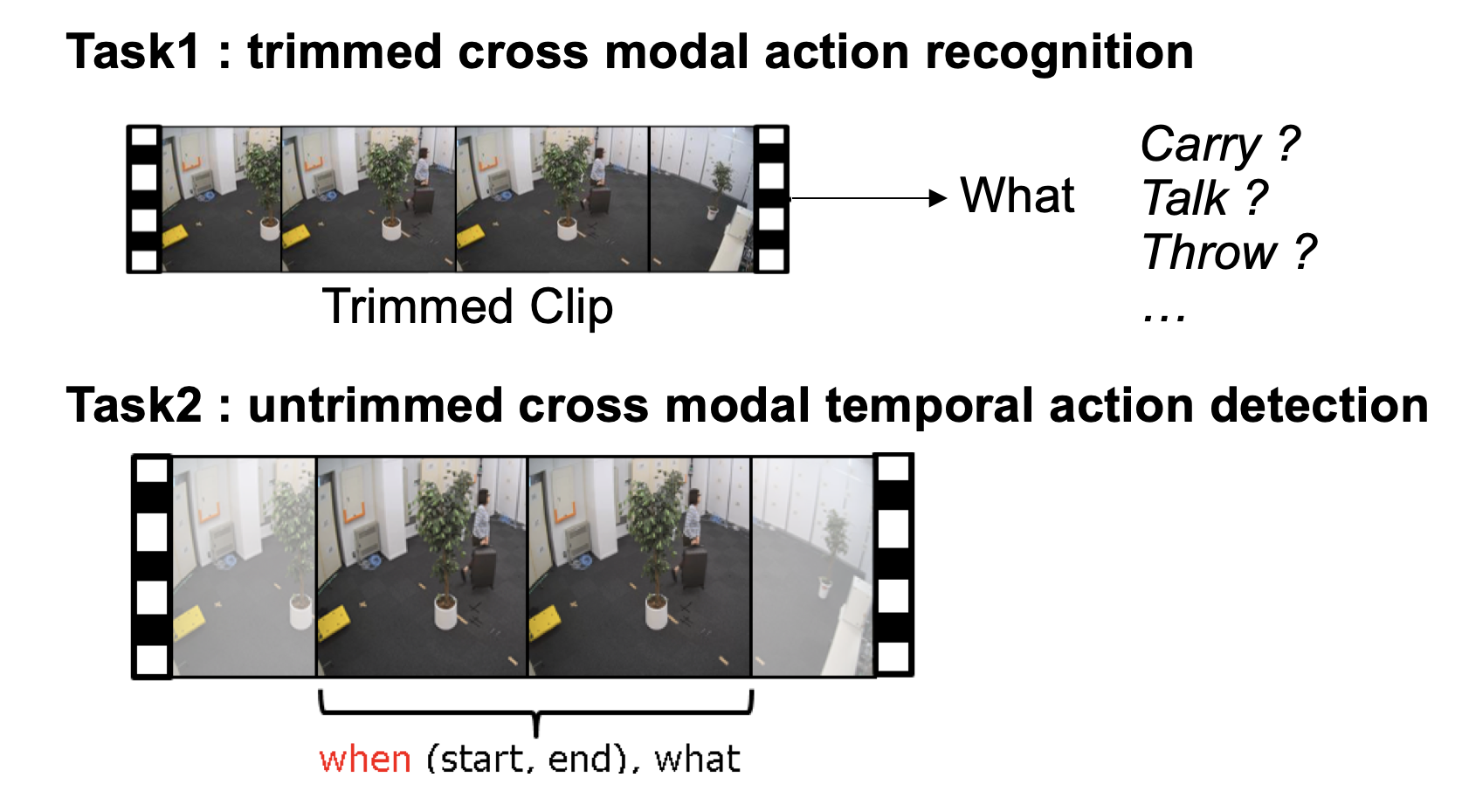
――なるほど。WhenとWhatの判断は難しそうですね。
孔:先ほどもお伝えした通り、MMActには、画角変化や遮蔽の影響を除外しつつ、機微な動作をチャレンジのベンチマークとして提供したため、センサ情報など行動のセンシティブのところを捉える特徴を活せるクロスモーダル学習などの手法の利用と提案も期待されています。最終的に、26のチームがエントリーし、130以上のサブミッションをいただきました。
ビジネスを踏まえアカデミックでも活躍、魅力的なカルチャーがある
――トップカンファレンスで活躍される中で、日立という会社で活動するメリットをどのように捉えていらっしゃいますか?おふたりの考えを教えてください。
田村:メリットは大きく3つあると思います。
まずは、会社として論文の投稿を強く推奨していること。先ほどもお伝えした通り、私自身が論文を書いていきたいと考えているので、その軸でキャリアを積み上げていくには非常に魅力的な文化だなと感じます。当たり前に享受しているこの環境も、もしかしたら他社では難しいこともあるのではないかと感じています。
また、研究所内でGPUクラスタを構築しているので、かなり潤沢な計算リソースがあります。実験をたくさん回したいときに、いくらでも実験ができるというわけです。
あと、論文のフィードバックを先輩などに気軽に相談できるのも、とても助かっています。1人でやるのは無理がありますからね。
孔:私も、今の田村さんのお話に共感する部分が多いですね。
よく20%ルールという、業務外のことに時間を割いて良い制度がありますが、日立ではこのルールがうまくワークしている気がします。研究テーマはアイデアや実践からヒントを得てスタートするものが多いので、自由に発想できる時間をちゃんともらえるというのは、とても大事なポイントだと思います。
また、学会で投稿するモチベーションを他のメンバーと共有できるのもいいですね。学会発表は常に高いモチベーションを保たねばならないのですが、日立にはその志がある人がとても多いです。入社2年以内のメンバーには、トップカンファレンスの見学機会も与えられており、いい環境だなと感じます。
あとは、コミュニケーションを活発に取れる文化があるのも、研究する場としてかなり魅力的な環境だなと思います。研究領域では、他の人と意見交換して、より高いレベルに研鑽していくことが大切ですからね。

――いいですね!今後の展開・今後取り組みたい挑戦なども教えてください。
田村:今回トップカンファレンスでの発表が実現しましたが、当然これで終わりではなく、引き続きトップカンファレンスに論文を出し続けたいと思います。
あと、私が先輩研究者に助けてもらったように、ゆくゆくは下の世代にリサーチのノウハウを伝えながら、一緒にやっていきたいなと思います。
孔:行動理解のタスクは非常に難しいです。しかし、本当に世の中のためになる技術にするには、人とそれ以外の情報を統合的に理解することも大切です。だからこそ、視覚で取れる情報を網羅的に抽出、構造化し、よりハイレベルなシーン全体における映像理解を施したいと思っています。
――ありがとうございます。それでは最後に、読者に向けたメッセージを、それぞれお願いします!
田村:研究は、面白いことをやることが、いちばん大切です。日立には、面白いことをやりたい人のための環境が用意されていると思います。世の中をよくしていく研究を、ぜひ一緒にやっていきましょう。
孔:それでは若手の方に一言。若いうちにどんどん挑戦してほしいと思いますので、挑戦する志と研究する意思があれば、ぜひ日立でご一緒しましょう!
編集後記
これまで何度も日立製作所の研究者にインタビューさせていただきましたが、どの方も口を揃えて、研究を進めるにあたって恵まれた環境が揃っているとおっしゃいます。中央研究所の正門から程なく歩いたところに「変人橋」(現在は「返仁橋」)という名の橋があることからもお分かりの通り、研究熱心な、良い意味での“変人”が同社のルーツ・DNAになっているわけです。トップカンファレンスで活躍するような人材が多く在籍しているのは必然なんだなと、なんだか妙に納得するインタビューとなりました。
取材/文:長岡武司
社会課題を解決する 日立の人とキャリアを知るメディア
「Hitachi Next Stories」公開中!
日立では社会の課題を解決し、未来へ向けて挑戦し続ける社員のインタビュー記事を掲載しています
Hitachi Next Storiesへ
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
「Qiita×HITACHI」AI/データ×社会課題解決 コラボレーションサイト公開中!
日立製作所の最新技術情報や取り組み事例などを紹介しています
コラボレーションサイトへ
日立製作所 キャリア採用実施中!
映像解析技術の研究開発
募集職種詳細はこちら
*¹ Conference on Computer Vision and Pattern Recognition。毎年アメリカで開催されるコンピュータビジョンに関する世界トップレベルの学会、Google Scholar H-index=356, CVPR21におけるフルペーパーの採択率=23.4%
*² 畳み込みニューラルネットワーク
*³ 2017年に発表された深層学習モデル。主に自然言語処理 の分野で使用される
*⁴ Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
*⁵ International Challenge on Activity Recognition (http://activity-net.org/challenges/2021/)