前回の続き
会社の研修で画像認識で分類問題を解いたので自分の好きなアイドルで同じことをしてみようとしたのがきっかけ。
以下、前回の記事
今回は前回の結果を踏まえ、精度向上と間違えてた画像がどのようなものだったのかを見ていこうと思います。
その前に分類対象となるお二方のご紹介
大場花菜
私、おぼろの心の推しメン。アイドルグループ「=LOVE」のメンバーです。
どがわええええええええええべほべほべろほろへゆろ、!!!!!ーー!!!

以下、Twitterのアカウント。是非フォローよろしくお願いします。
大場花菜(https://twitter.com/hana_oba)
大谷映美里
同じくアイドルグループ「=LOVE」のメンバーです。
かわいいですね。

大谷映美里(https://twitter.com/otani_emiri)
前回の精度が大体正答率90%くらいでした。
精度向上のために試すこと① ~試行回数を増やす~
前回がエポック数200回ほどでした。
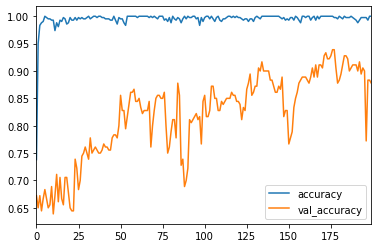
これをみるとまだ上がりそう(試行回数が多すぎると一時的ではなく恒常的にグラフが下降していきます)
なのでもっと回数を増やしていきます。
200→1000回へ
無事に精度が向上しました。
800回を超えたあたりで長い間低い値を推移しており、これは過学習してしまっているのか?と思いましたが最後持ち直してくれましたね。
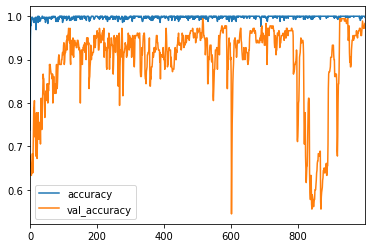
1000エポック目は正答率98.33%でした。
まぁ実際には研修の時に精度向上のためにいくらか試行錯誤をしているので回数を増やすだけで結構精度を出すことができました。
記事としてはもっと精度向上のためにもがき苦しむべきなんでしょうがこれで良しにしたい自分がいます。
・・・とりあえず今日は精度向上はここまでにしてこのモデルが何を間違えたのかを見ていきます。(早く推論がやりたい)
何を間違えてしまったのか見てみる
以下で答え合わせして、間違えてしまったやつがどれなのか、見ていきます。
ans = []
for i in range(0,x_test.shape[0]):
x = np.array([x_test[i]])
y = model.predict(x)
ans.append(np.argmax(y))
if(ans[i] != t_test[i]):
print(i)
以下が結果
75
82
148
検証データ140件のうち誤答が3件=正解率が約98%なのであってそうですね!
これをつかって以下のように一度数値に落としたデータを画像に復元します。
plt.imshow(x_test[75])
plt.imshow(x_test[82])
plt.imshow(x_test[148])
- 75

- 82
カメコさんの画像だったので載せるのはやめておきます。
以下のツイートの1枚目です。(いいね!押しておいてください)
https://twitter.com/hana_oba/status/1119100534286217221?s=20
- 148

うーん、、、普通に花菜ちゃんですね。
1枚目はみりにゃ率89%
2枚目はみりにゃ率58%
3枚目はみりにゃ率64%
で最終的にみりにゃという判断をしたみたいです。
まぁ、ディープラーニングはなぜそのような判断をしたのかを人間がわかるレベルで説明することはなかなかできないのでこれ以上推測することとかは何もないのですが。
では次回は違う方法で精度を高めていこうと思います。