はじめに
みなさんはじめまして。おぼろと申します。
今回会社の研修で画像認識で分類問題を解いたので実際に自分の好きなもので同じような精度・結果が得られるのか。また精度が高くなかった場合、どのようなアプローチをすれば精度を高くすることができるのか、検証していきたいと思います。
AI関連ではない人が記事を読むことも想定して記事を書いたので、この記事を通じてディープラーニングを学びたい人には物足りない内容かと思います。ただ、実装内容は簡単に試せるものなので是非見ていっていただけたらと思います。
まず、大場花菜と大谷映美里って誰?
大場花菜ちゃんは私、おぼろが大好きなアイドルグループ「=LOVE」のメンバーです。
めちゃくちゃかわいいです。

以下、Twitterのアカウント。是非フォローよろしくお願いします。
大場花菜(https://twitter.com/hana_oba)
大谷映美里ちゃんも同じくアイドルグループ「=LOVE」のメンバーです。
この子もかわいいです。

大谷映美里(https://twitter.com/otani_emiri)
研修課題との違い
研修では犬猫の分類問題を解きました。
精度としては正答率95%ほどだったかと思います。
1.課題の前提条件
-
サンプル数は犬猫それぞれ100ずつ
-
画像サイズは224*224
-
学習データは全体の70%(検証データは全体の30%)
2.今回の実験条件
-
サンプル数はそれぞれ300ずつ(サンプルを収集するためにTwitterで画像を300枚づつ保存していた時間が幸せだったのは内緒)
-
画像サイズは224*224
-
学習データは全体の70%(検証データは全体の30%)
座学
実装する前に一応ディープラーニングによる画像処理の理論について少しだけ説明します。
実装、座学共に興味ない人は最後まで飛ばして、どうぞ
ディープラーニングとは
ディープラーニングとは、の前に
AI、機械学習、ディープラーニングがそれぞれ何を指しているのかわからない人も多いと思うのでそれも含めて簡単に説明させてください。
まちがっていたらごめんなさい…
-
AIとは人工知能のことで、文字通り人工的に作られた知能のことです
-
機械学習とは現在AIを実現するには欠かすことができない技術のひとつ。AIを実現するために機械学習を用いるのが現在は主流なんですね
-
ディープラーニングとは機械学習の手法の一つで大量のデータから、自らどのデータがどれだけ重要か判断し、解を導き出すことができる
画像データの取り扱い
画像データの1ピクセルはRGB(赤緑青)毎の輝度(明るさ0-255)で表現することができるのでこの形に落とし込むことで数値データとして扱うことができます。
例)22224の画像の場合
これは2242243(縦横*三原色)の行列で表現できるのでimg.shape = (224,224,3)となります。
ニューラルネットワークについて
以下がニューラルネットワークの簡単な絵です。

z1は以下の式で求められます。
z_1 = w_{31} y_1 + w_{32} y_2
y1,y2も同様に求められるため各入力、各重みにより出力が求まります。
出力と答えを比較し、誤差によって、重みを調整
また別の入力で出力をし・・・を繰り返し学習を進めていきます。
ディープラーニングはこの中間層が何層にもなっているので表現力が高いと言われています。
これは求める出力が様々な入力と重みによって表現ができるため、と考えてもらえればわかりやすいかと思います。
画像処理におけるニューラルネットワークの組み方
画像処理において上記の重みはフィルタというものによってニューラルネットワークを組んでいくことになります。
以下の画像のようにフィルタ(赤)を画像の緑の部分に当てます。
これよって最終的に出力"6"(青)を得ることができます。
フィルタの掛け方にもよりますが、これを一マス右にずらし、同じことを実施・・・とすることで出力による新たな行列を得ることができます。
この繰り返しの末、たどり着いた値によって分類するわけです。

実装
それでは、実装していきます。
環境はGoogle Colaboratory
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import cv2
import matplotlib.pyplot
import numpy as np
from glob import glob
import pandas as pd
%cd /content/drive/My Drive/
%tensorflow_version 2.x
from tensorflow.keras.preprocessing import image
from tensorflow.python.client import device_lib
# モデルを定義
from tensorflow.keras import models, layers
from tensorflow.python.keras.layers import Dropout
from tensorflow.keras import utils
import tensorflow as tf
from google.colab import drive
drive.mount('/content/drive')
ここら辺は使うかどうかに関係なくテキトーに呼び出してます。
GoogleDriveにあらかじめ用意しておいたそれぞれの画像を集めたフォルダのパスを取得します。
%cd /content/drive/My Drive/DATA/IDOL
hana_filepaths = glob('OBA_HANA/*')
emiri_filepaths = glob('OTANI_EMIRI/*')
続いて、保存した画像の大きさがまちまちなのでサイズを224*224に統一し、画像を数値化していきます。
image_size = 224
x, t =[],[]
for i in range(0,np.array(emiri_filepaths).size):
hana_filepath = hana_filepaths[i]
emiri_filepath = emiri_filepaths[i]
img = image.load_img(hana_filepath, target_size=(image_size, image_size))
img = np.array(img)
x.append(img)
t.append(0)
img = image.load_img(emiri_filepath, target_size=(image_size, image_size))
img = np.array(img)
x.append(img)
t.append(1)
x = np.array(x)/255.0 #標準化
t = np.array(t)
それでは、学習していきましょう。
K.clear_session()
reset_seed(0)
# nas_mobile_conv = keras.applications.nasnet.NASNetMobile(weights = 'imagenet', include_top = False, input_shape = (x_train.shape[1:]), classes=2)
nas_mobile_conv = NASNetMobile(weights = 'imagenet', include_top = False, input_shape = (x_train.shape[1:]), classes=2)
x = nas_mobile_conv.layers[-1].output
x = layers.Flatten()(x) # 最後の出力層を外し、新たに追加する
x = layers.Dense(1024, activation = 'relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dense(516, activation = 'relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dense(2, activation = 'softmax')(x)
model = models.Model(nas_mobile_conv.inputs, x)
model.summary()
optimizer = tf.keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer = optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
batch_size = 32
epochs = 100
history = model.fit(x_train, t_train,
batch_size = batch_size,
epochs = epochs,
verbose=1,
validation_data=(x_test, t_test))
epochs=100(繰り返し回数のこと)で回数ごとの精度の遷移は以下でグラフ化できます
result = pd.DataFrame(history.history)
result[['accuracy','val_accuracy']].plot()

青が訓練データ、オレンジが検証データです。(花菜ちゃんのサイリウムカラーですね)
ブレはあるもの回数が増えるに連れ精度が高くなっていることがわかるかと思います。
まだ上がりそうなので回数を増やしてみます。
※GPUで計算すると毎回同じ乱数の初期値にするのが難しいらしく、毎回実行するたびに結果が異なります。
(逆に乱数の初期値を毎回固定できれば何回やっても同じ結果が得られるはずです)
200回に増やしてみました。
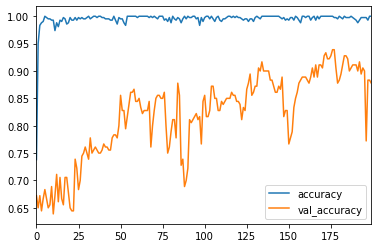
少し精度が上がって正答率90%くらいになりました。
今日は疲れたのでここまでにして、次回は精度を上げる試行錯誤や間違えた画像がどのようなものだったかを見ていきたいと思います。