MYJLab Advent Calendar 2019 18日目の記事です。
推しメン堀未央奈のブログで遊んでみました。テキストマイニング編です。
スクレイピング
乃木坂46 堀未央奈 公式ブログをスクレイピングします。
scraiping.py
from time import sleep
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
def main():
options = Options()
driver = webdriver.Chrome(executable_path="ドライバのパスをここに", chrome_options=options)
url = "http://blog.nogizaka46.com/miona.hori/"
driver.get(url)
lines = []
# 1枚目取り出す
get(driver,lines)
click_tag = driver.find_elements_by_css_selector('#sheet > div:nth-child(1) > a:nth-child(12)')
click_tag[0].click()
# 2枚目以降取り出す
for i in range(10):
sleep(2)
click_tag = driver.find_elements_by_css_selector('#sheet > div:nth-child(1) > a:nth-child(13)')
click_tag[0].click()
get(driver,lines)
with open('miona.txt', 'w') as f:
for element in range(lines):
f.write()
driver.quit()
# ブログ内容の取得
def get(driver,lines):
sleep(1)
soup = BeautifulSoup(driver.page_source, "html.parser")
with open('miona.txt', 'w') as f:
for i in range(len(lines)):
f.write(lines[i])
if __name__ == '__main__':
main()
単純な構造でスクレイピングしやすいです!わーい
前処理
クレンジング処理
def cleansing
以下のいらない情報たちを削除
- URLテキスト
- 絵文字
- 句読点
- ハッシュタグ ( 堀氏は文章にハッシュタグ入れがちなのですが、今回はカット )
- 空白の行
- スペース
- インスタとTwitterのアカウントID
単語の分割処理
def wakti
形態素解析器はMeCabを、辞書は新語に対応したmecab-ipadic-NEologdを使用しました。
ストップワードの除去
def stop_word
ストップワードを指定して除去します。
preprocessing.py
from janome.analyzer import Analyzer
from janome.tokenfilter import *
import re
import neologdn
import emoji
import collections
import unicodedata
import string
import MeCab
def stop_word(text):
stop_words = [ 'てる', 'いる', 'なる', 'れる', 'する', 'ある', 'こと', 'これ', 'さん', 'して', \
'くれる', 'やる', 'くださる', 'そう', 'せる', 'した', '思う', \
'それ', 'ここ', 'ちゃん', 'くん', 'て','に','を','は','の', 'が', 'と', 'た', 'し', 'で', \
'ない', 'も', 'な', 'い', 'か', 'ので', 'よう', 'ん', 'みたい','の','私','自分','たくさん',\
'ん','もの','こと']
word_list = []
for i in text:
if i not in stop_words:
word_list.append(i)
return word_list
def wakati(text,terms):
cmd='echo `mecab-config --dicdir`"/mecab-ipadic-neologd"'
path = (subprocess.Popen(cmd, stdout=subprocess.PIPE,
shell=True).communicate()[0]).decode('utf-8')
tagger = MeCab.Tagger("-d {0}".format(path))
tagger.parse('')
# 分けてノードごとにする
node = tagger.parseToNode(text)
while node:
term = node.surface
pos = node.feature.split(',')[0]
# もし品詞が条件と一致してたら
if pos in ['動詞', '形容詞', '名詞']:
terms.append(term)
node = node.next
def cleansing(text):
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', text)
text = re.sub(r'#', '', text)
text = re.sub(r'\n', '', text)
text = re.sub(r'@horimiona_2nd', '', text)
text = re.sub(r'@horimiona2nd', '', text)
text = neologdn.normalize(text)
text = ''.join(c for c in text if c not in emoji.UNICODE_EMOJI)
text = unicodedata.normalize("NFKC", text)
table = str.maketrans("", "", string.punctuation + "「」、。・")
text = text.translate(table)
return text
def main():
text_file = 'miona.txt'
with open(text_file) as f:
s = f.read()
s_after_cleansing = cleansing(s)
word_list = []
wakati(s_after_cleansing,word_list)
s_after_wakati = " ".join(word_list)
s_after_rmstop = stop_word(word_list)
# ベクトル化用にテキストファイルで保存
with open('miona_wakati_file.txt', 'w', encoding='utf-8') as f:
f.write(s_after_wakati)
if __name__ == '__main__':
main()
ベクトル化
def generate_vectors
モデルの作成
gensimのWord2Vecを使いました。名詞で分かち書きしたファイルを使用。
from gensim.models import word2vec
def generate_vectors():
model = word2vec.Word2Vec(word2vec.LineSentence('miona_wakati_file.txt'),
size=70, window=5, min_count=1,iter=5)
model.save('miona_w2v.model')
テスト
from gensim.models import word2vec
model = word2vec.Word2Vec.load('miona_w2v.model')
words = ['日奈子','写真','乃木坂']
for word in words:
similar_words = model.most_similar(positive=[word])
print(word,':',[w[0] for w in similar_words])

いろんな可視化
テキストデータを可視化します。フォントはマメロン使用します。
理想
AIテキストマイニング by ユーザーローカルで出てくる感じ
ワードクラウド
スコアが高い単語を複数選び出し、その値に応じた大きさで図示してる。 形容詞、形容動詞、名詞で分かち書きしたファイルを使用。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def create_wordcloud(text):
fpath = "mamelon/Mamelon.otf"
wordcloud = WordCloud(background_color="white",font_path=fpath, width=900, height=500).generate(text)
plt.figure(figsize=(15,12))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file("miona.png")

ファンの人なら未央奈っぽいっていうのはわかるはず!
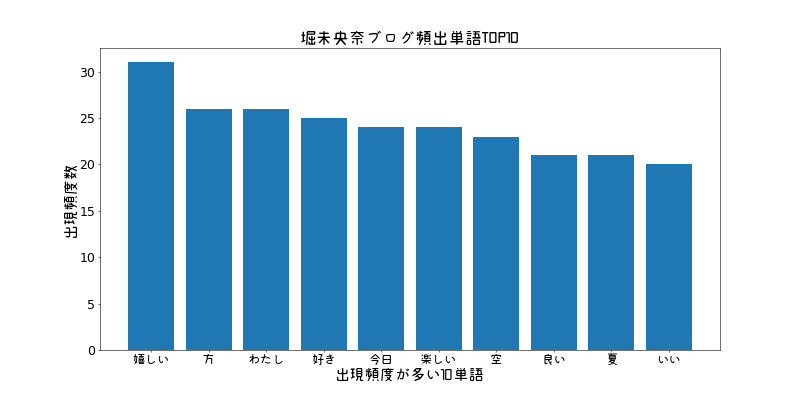
単語出現頻度
文章中に出現する単語の頻出を棒グラフで表示する。形容詞、形容動詞、名詞で分かち書きしたファイルを使用。
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def count(text):
c = collections.Counter(text)
mc = c.most_common()
value = []
count = []
for i in range(10):
value.append(mc[i][0])
count.append(mc[i][1])
fp = FontProperties(fname=r'mamelon/Mamelon.otf')
plt.figure(figsize=(16, 8), dpi=50)
plt.title("堀未央奈ブログ頻出単語TOP10", fontproperties=fp, fontsize=24)
plt.xlabel('出現頻度が多い10単語', fontproperties=fp,fontsize=22)
plt.ylabel('出現頻度数', fontproperties=fp, fontsize=22)
x = np.arange(len(value))
plt.xticks(x,value,fontproperties=fp,fontsize=18)
plt.yticks(fontsize=18)
y = np.array(count)
plt.bar(x,y)
plt.savefig('bar_word.png')
plt.show()
感情分析
日本語評価極性辞書を利用したライブラリのosetiを使って感情分析します。ポジティブ/ネガティブ表現の個数を表示することが可能です。動詞、形容詞、形容動詞、名詞で分かち書きしたファイルを使用。
import oseti
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def negapozi(text):
analyzer = oseti.Analyzer()
n = analyzer.count_polarity(text)
posi = 0
nega = 0
for item in n:
posi += item['positive']
nega += item['negative']
x = np.array([posi,nega])
fp = FontProperties(fname=r'mamelon/Mamelon.otf')
label = ["positive","negative"]
colors = ["lightcoral","lightblue"]
plt.figure(figsize=(11, 8), dpi=50)
plt.title("堀未央奈ブログネガポジ判定",fontproperties=fp,fontsize = 24)
plt.rcParams['font.size'] = 20
plt.pie(x,counterclock=False,startangle=90,colors=colors,autopct="%1.1f%%")
plt.legend(label, fontsize=20,bbox_to_anchor=(0.9, 0.7))
plt.savefig('negaposi.png')
plt.show()
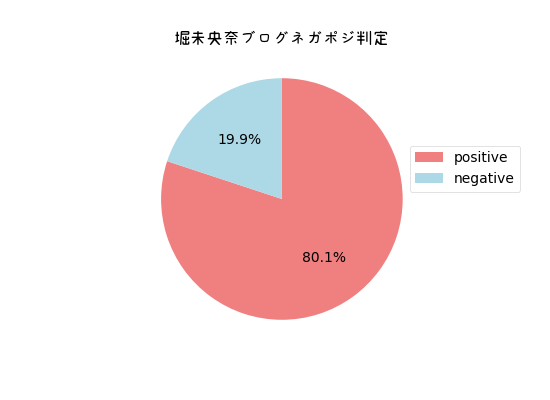
約8割ポジティブです。さすがアイドル。
ちょっと無理矢理感あるコードかもなので、何かご指摘あればよろしくお願いします🙇♂️
研究室の先輩まるたくさんに色々ご指摘していただきました。ありがとうございます🙇♂️