■0.はじめに
直近一年間で人工知能の実装を学んできました。
きっかけは下記で聴講したgoogleの方のお話しでして。
”AI”、”人工知能”というキーワード自体は聞いてましたが、このお話しで大きな刺激を受けました。
【雑感】Developers Festa Sapporo 2016
今ですとクラウドで学習済のモデルが使えたりと、ビジネスに適用していくハードルは下がっているイメージはありますが、実装をある程度理解していないとハマったときに手も足も出ないと思い、まずは実装を理解できるようになるレベルを目指してきました。
こちらで、スクラッチで実装することで、機械学習の中の部分がどうなっているかを理解し、
ライブラリを使ってディープラーニングを構築する ~Keras + TensorFlow編
こちらなどで、機械学習ライブラリを使って(スクラッチよりは)お手軽に実装する方法を学びました。
ここまでの学びでは基本的にデータセットとして、入門者にはおなじみのMNISTを使ってきましたが、さて次のステップとしてMNIST以外のデータセットを使ってやってみようか!
と思い立ったまではよかったのですが...
■1.環境
・Windows 10
・Anaconda 4.4.1
・Python 3.6.1
・TensorFlow 1.4.0
・Keras 2.1.2
4種類のライブラリを試してみて、Kerasが一番使いやすいかなと感じました。
Kerasはライブラリ上で動くライブラリなので、ベースにはTensorFlowを選択。
■2.私はただのMNISTおじさんでした...
MNISTおじさんって何やねん(゚∀゚)ガハッ∵∴
ってお思いの方に説明しますと、
MNISTでしか機械学習できないおじさん、つまり私のことですw
MNIST以外のデータセットでと考えた時、最初に思い浮かんだのは何か画像を集めて分類してなんですが、学習に必要な数を集めて分類してという作業を考えた時点で半分心が折れまして。
そもそも何を集めたらいいんだろ...orz
じゃあ画像以外で...と考えても思いつかないorz
機械学習で過学習というワードがありますが、私はあたかもMNISTで過学習したおじさんのようでありました。
そもそも論としては、どんな問題を解決するのに機械学習を使うのか(必要なのか)ってアプローチとなるところが逆になっているのが悪いのですが、学びの過程なのでそうなってしまうのはしょうがない。
で、何か参考にできるものがないかいろいろとググって、利用するデータを決めました。
■3.利用データ
気象庁のサイトから過去の気象データをダウンロードすることができます。
画面から地点、項目、期間を選んでCSVファイルとしてダウンロードします。
一回のリクエストで取得できるデータ量が制限されているので、データ量が多い場合は何回かに分けてダウンロードする必要があります。
Excelで開くとこんな感じのデータです。
今回使用したのは、1975年~2017年の北海道札幌市の気象データで、どの項目を使うかはまだ決めてなかったので、取得できる項目は全て取得しました。
■4.日々の気温の推移から次の日の平均気温を予測する
ここからは実装になります。
まずは1か月の平均気温を予測するための下準備として、日々の気温の推移から次の日の気温を予測するモデルを作成します。
▼4.1.概要
日々の気温の推移から次の日の気温を予測します。
予測するためのアルゴリズムとして、時系列データの予測に優れたRNN(Reccurent Neural Network)、その中でも最近よく使われるというLSTM(Long Short Term Memory)を用いることにしました。
なお、再帰型ニューラルネットワークと呼ばれるこれらについてはまだ不勉強なもので、具体的な仕組みについての説明は省きます。
▼4.2.学習用のデータセットを作成する
気象庁のサイトから入手したCSVファイルから学習用のデータセットを作成します。
今振り返ればここの部分に相当の時間を費やすことになりました。
# coding: utf-8
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.recurrent import LSTM
from keras import optimizers
from keras.callbacks import ModelCheckpoint
from keras import metrics
# CSVファイルから気象データをDataFrame型で取得する
def get_dfWeather_data():
# 最初のカラム(年月日)をindexとし、最初の5行を読み飛ばす
dfWeather = pd.read_csv('data_sapporo1975-2017.csv', index_col=0, parse_dates=True, skiprows = 5, encoding = 'shift_jis', header=None)
# 不要な列を削除する
dfWeather = dfWeather.drop([3, 4, 6, 8, 10, 11, 12, 14, 15, 17, 19, 20, 21, 23, 24, 26, 28, 29, 30, 32, 33, 35, 37, 38, 39, 41, 42, 44, 46, 47, 49, 51, 53, 54, 56, 58, 60, 61, 63, 65, 67, 68, 70, 72, 74, 75, 77, 79], axis=1)
# 列名を指定する
dfWeather.columns = [
'day_of_the_week', # 曜日
'average_temperature', # 平均気温(℃)
'average_temperature_avg', # 平均気温_平年(℃)
'average_temperature_diff', # 平均気温_平年差(℃)
(中略)
'average_cloud_cover', # 平均雲量(10分比)
'average_cloud_cover_avg', # 平均雲量_平年(10分比)
'average_cloud_cover_diff' # 平均雲量_平年差(10分比)
]
return dfWeather
まずはCSVファイルを読み込んで、DataFrame型にします。
その際、最初のカラムである年月日をindexとし、"parse_dates=True"とすることでその値を日付型にします。
CSVファイルにある実値以外のカラムを削除し、残ったカラムに列名を指定しています。
# 扱う特徴量
FEATURE_VALUE = ['average_temperature'] # 平均気温
# 次元数
DIMENSION = len(FEATURE_VALUE)
# 気象データを取得
dfWeather = get_dfWeather_data()
# 学習用データを取得(日付順にソート)
dfWeatherTrain = dfWeather.ix['1975-01-01':'2017-12-31', FEATURE_VALUE]
dfWeatherTrain = dfWeatherTrain.sort_index()
dfWeatherTrain = dfWeatherTrain.dropna() # 欠損値のある行を取り除く
最後の欠損値のある行を取り除くというのが大事です。
欠損値のある行をそのまま学習させようとすると予期せぬ結果になったり、実装次第ではそもそもエラーになってしまうこともあります。
気象データの場合、ある特定のポイント(日、観測地点、項目)が欠損しているということもありますし、この項目はxxxx年から計測を開始したとかありますので欠損値を取り除くという処理は必須です。
# モデルに読み込ませるデータを生成する
def generate_data(data, length_per_unit, dimension):
# DataFrame→array変換
data_array = data.as_matrix()
# 時系列データを入れる箱
sequences = []
# 正解データを入れる箱
target = []
# 正解データの日付を入れる箱
target_date = []
# 一グループごとに時系列データと正解データをセットしていく
for i in range(0, data_array.shape[0] - length_per_unit):
sequences.append(data_array[i:i + length_per_unit])
target.append(data_array[i + length_per_unit])
target_date.append(data[i + length_per_unit: i + length_per_unit + 1].index.strftime('%Y/%m/%d'))
# 時系列データを成形
X = np.array(sequences).reshape(len(sequences), length_per_unit, dimension)
# 正解データを成形
Y = np.array(target).reshape(len(sequences), 1)
# 正解データの日付データを成形
Y_date = np.array(target_date).reshape(len(sequences), 1)
return (X, Y, Y_date)
CSVファイルから読み込んだDataFrame型のデータを学習用のデータセットに成形します。
時系列データは、引数で指定されて日数分を配列で持たせ、最後の日の翌日を正解データとします。
ex.
時系列データ:1975/1/1~1975/12/31
正解データ:1976/1/1
この組み合わせを1セットとし、日付を一日ずらして次の1セット、これを繰り返して学習用のデータセットを作成します。
正解データの日付データは学習では用いませんが、結果を可視化する際に用います。
# 一つの時系列データの長さ
LENGTH_PER_UNIT = 365
X_train, Y_train, Y_train_date = generate_data(dfWeatherTrain, LENGTH_PER_UNIT, DIMENSION)
# 正規化
X_train /= np.nanmax(np.abs(X_train))
今回は一つの時系列データの長さを365日としました。
一年の推移を学習させることで次の日の予測がし易いのではという意図から定めました。
学習に使う時系列データを正規化します。
▼4.3.モデルを定義し、学習する
ここからはこれまで学んできたことの繰り返しなのでそれほど苦労はなかったです。
# モデルリストを取得する
def get_model_list(input_shape):
# 実行するモデル一覧
model_list = [
['LSTM_1', Sequential([
LSTM(100, input_shape=input_shape),
Dense(1),
Activation("linear")])],
['LSTM_2', Sequential([
LSTM(300, input_shape=input_shape),
Dense(1),
Activation("linear")])],
]
return model_list
# 実行するモデル一覧
model_list = get_model_list(input_shape)
まずはモデルの定義。
複数のモデルを一括で実行できるよう、リストで取得するようにしました。
# 入力の形状
input_shape=(LENGTH_PER_UNIT, DIMENSION)
# 最適化手法の設定
opt = optimizers.Adam()
# 全てのモデルについて実行する
for save_path, model in model_list:
# 結果格納用のフォルダ作成
if not os.path.isdir(save_path):
os.mkdir(save_path)
# モデルの要約を出力
model.summary()
# モデルのコンパイル
model.compile(optimizer = opt, # 最適化手法
loss = 'mean_squared_error', # 損失関数
metrics = ['accuracy']) # 評価関数
リストで取得したモデルについて順にコンパイルしていきます。
model.summary()
とすると下記のように要約を出力してくれます。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 100) 40800
_________________________________________________________________
dense_1 (Dense) (None, 1) 101
_________________________________________________________________
activation_1 (Activation) (None, 1) 0
=================================================================
Total params: 40,901
Trainable params: 40,901
Non-trainable params: 0
_________________________________________________________________
# 途中で保存するモデル基準設定
fpath = save_path + '/weights.{epoch:03d}-{loss:.2f}-{acc:.2f}-{val_loss:.2f}-{val_acc:.2f}.hdf5'
model_ckp = ModelCheckpoint(filepath = fpath, monitor='loss', verbose=1, save_best_only=True, mode='auto', period=5)
# 学習
history = model.fit(X_train, Y_train,
epochs=50,
batch_size=10,
validation_split=0.1,
callbacks=[model_ckp])
ModelCheckpointを使うと、学習途中のモデルを保存することができます。
#Accuracyの推移
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy : ' + save_path)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(save_path + '/accuracy.png')
plt.close()
# Lossの推移
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss : ' + save_path)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(save_path + '/loss.png')
plt.close()
AccuracyとLossの推移をグラフにしています。
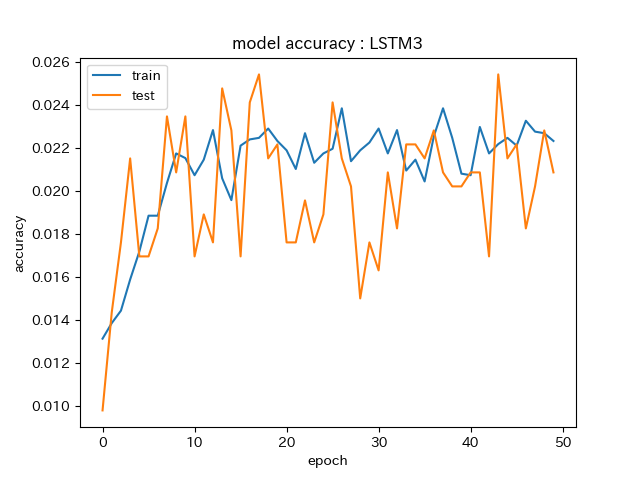
Accuracy推移の一例。
途中まで順調に精度が上がってますが、10epoch以降は上がらなくなってます。
テストデータは若干振り幅が大きくなってますが同じ傾向です。
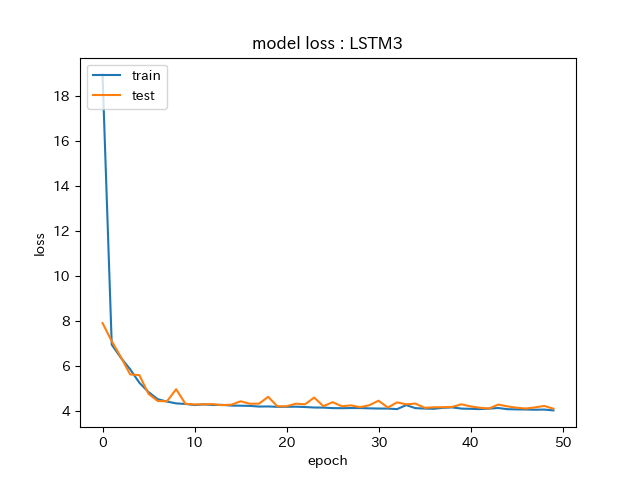
Lossを見ていくと、Accuracyが上がらなくなった10epochで落ち着いています。
▼4.4.モデルと学習結果を保存する
最終epochまで学習した結果をモデルと一緒に保存します。
# モデルと学習結果を保存する
model_json_str = model.to_json()
open(save_path + '/Keras_rnn.json', 'w').write(model_json_str)
model.save_weights(save_path + '/Keras_rnn_weights.h5');
このファイルを予測時に読み込んで使用するという流れになります。
▼4.5.次の日の平均気温を予測する
まずはモデルに学習させた内容そのままに次の日の平均気温を予測し、モデルの精度を見てみます。
# 扱う特徴量
FEATURE_VALUE = ['average_temperature'] # 平均気温
# 次元数
DIMENSION = len(FEATURE_VALUE)
# 気象データを取得
dfWeather = get_dfWeather_data()
# テストデータを取得(日付順にソート)
dfWeatherTest = dfWeather.ix['2016-01-02':'2017-12-31', FEATURE_VALUE]
dfWeatherTest = dfWeatherTest.sort_index()
dfWeatherTest = dfWeatherTest.dropna() # 欠損値のある行を取り除く
X_test, Y_test, Y_test_date = krc.generate_data(dfWeatherTest, LENGTH_PER_UNIT, DIMENSION)
# 正規化
X_test /= np.nanmax(np.abs(X_test))
データセットの作成は学習時と同じです。
# 最適化手法の設定
opt = optimizers.Adam()
# 入力の形状
input_shape=(LENGTH_PER_UNIT, DIMENSION)
# 結果格納用DataFrameのカラム定義
df_columns = ['予測', '実測値', '差(予測-実測値)']
model_list = get_model_list(input_shape)
# 全てのモデルについて実行する
for save_path, model in model_list:
# 結果を格納するDataFrame
dfResultWeather = pd.DataFrame(columns=df_columns)
# フォルダが存在しなければスキップ
if not os.path.isdir(save_path):
continue
# モデルを読み込む
model = model_from_json(open(save_path + '/Keras_rnn.json').read())
# 学習結果を読み込む
model.load_weights(save_path + '/Keras_rnn_weights.h5')
# モデルの要約を出力
model.summary()
# モデルのコンパイル
model.compile(optimizer = opt, # 最適化手法
loss = 'mean_squared_error', # 損失関数
metrics = ['accuracy']) # 評価関数
保存しておいたモデルとその学習結果を読み込んでコンパイルさせます。
実測値と比較してモデルの精度を見ていきたいので、結果格納用DataFrameのカラムは下記のように定義しています。
# 結果格納用DataFrame
df_columns = ['予測', '実測値', '差(予測-実測値)']
予測の準備はこれで完了。
一日ずつ予測していきます。
# 予測を行う
for i in range(0, len(X_test)):
#for i in range(0, X_test[0].size):
y_ = model.predict(X_test[i:i+1, :, :])
tmp = np.array([float(y_), float(Y_test[i:i+1, :]), abs(float(y_) - float(Y_test[i:i+1, :]))])
tmp = np.ravel(tmp)
dfResult = pd.DataFrame([tmp], columns=df_columns, index=[Y_test_date[i:i+1]])
dfResultWeather = dfResultWeather.append(dfResult)
予測結果と実測値、2つの差を1セットとして順次追加していきます。
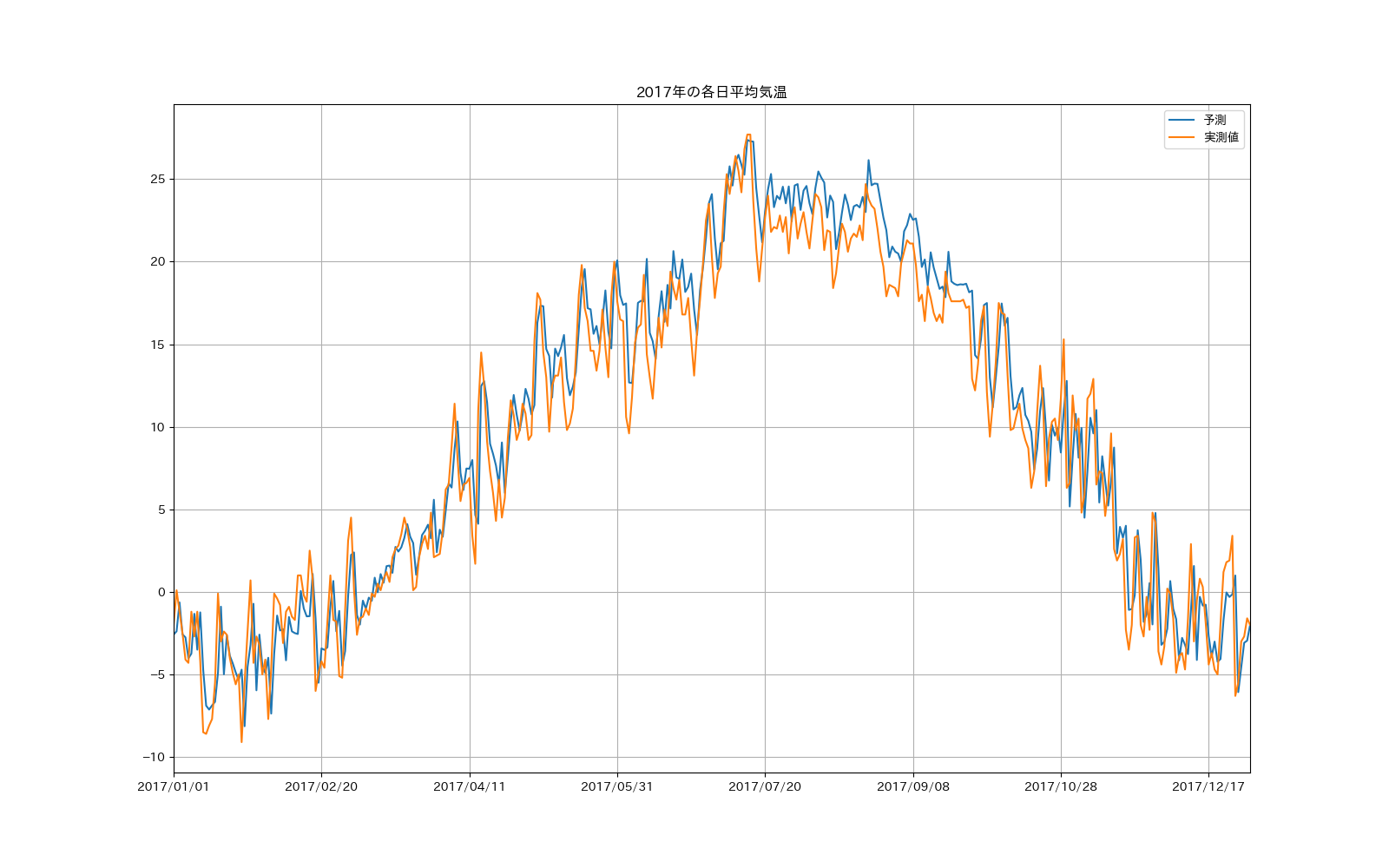
パッと見るとなかなかの精度っぽく見えますが、拡大してみると結構ずれているところもあります。
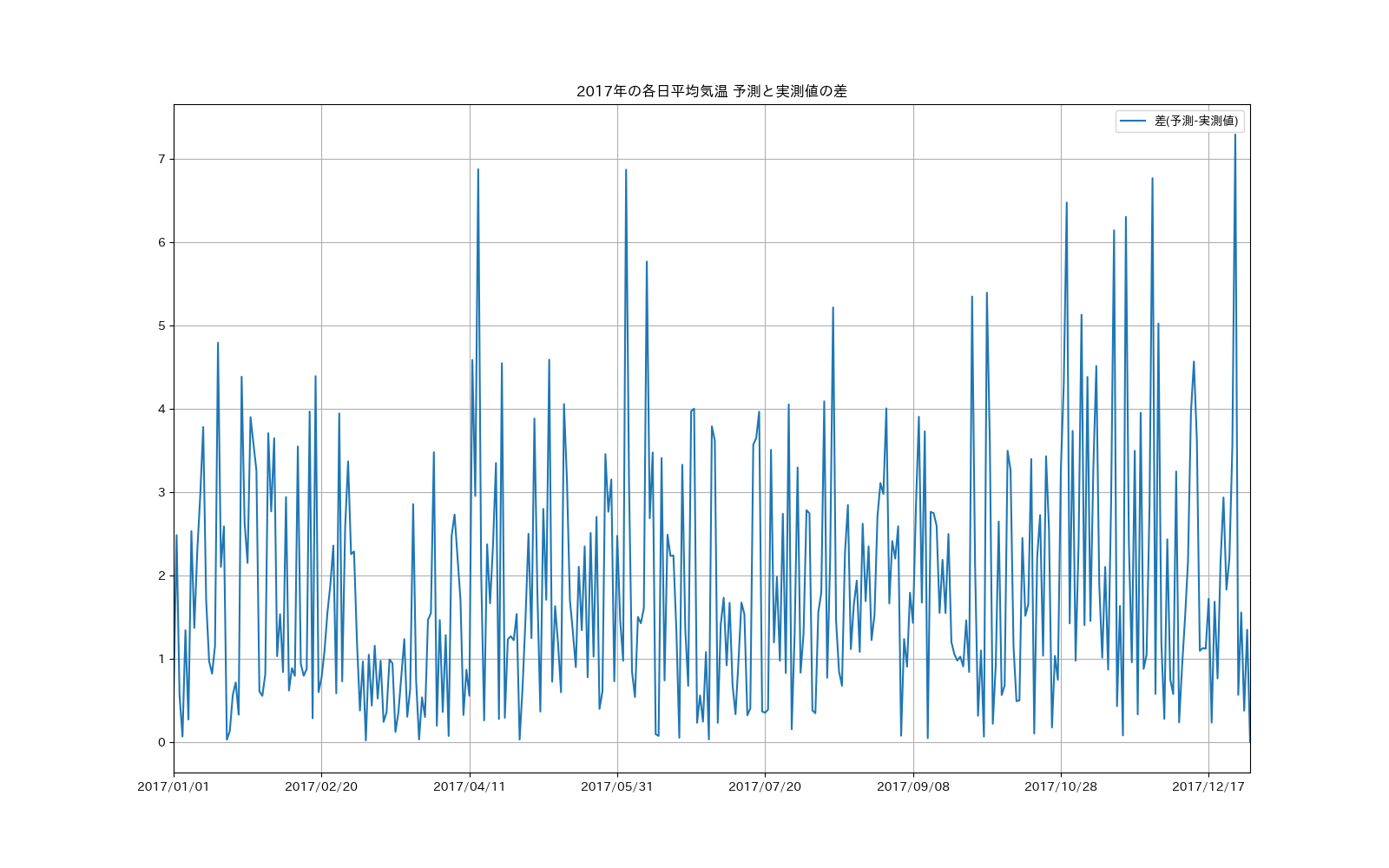
実測値との差を見ていくと数度の違いは普通で、最大で8度近く差が出ている日もあります。
# 統計情報を表示
print('統計情報:')
print(dfResultWeather.describe())
# 差(予測-実測値)の最大値
print(dfResultWeather[dfResultWeather['差(予測-実測値)'] >= 5])
# グラフ描画
dfResultWeather.plot(y=['予測', '実測値'], figsize=(16,10), title='2017年の各日平均気温', grid=True)
plt.savefig(save_path + "/predict.png")
dfResultWeather.plot(y=['差(予測-実測値)'], figsize=(16,10), title='2017年の各日平均気温 予測と実測値の差', grid=True)
plt.savefig(save_path + "/predict_diff.png")
DataFrameではdescribe関数で統計情報を簡単に見ることができます。
統計情報:
予測 実測値 差(予測-実測値)
count 365.000000 365.000000 365.000000
mean 9.873768 9.183014 1.858874
std 10.138869 9.597346 1.445496
min -8.134899 -9.100000 0.002906
25% -0.308933 0.100000 0.756734
50% 10.543715 9.800000 1.468483
75% 18.657780 17.700000 2.733871
max 27.374790 27.700000 7.293734
これを見ると、最大で約7.3度の差は出ていますが
・25%のデータは約0.76度の差に収まっている
・50%のデータは約1.47度の差に収まっている
・75%のデータは約2.73度の差に収まっている
ことがわかり、それなりの精度になっていることがわかります。
さらに5度以上の差になっているデータを抽出してみると
予測 実測値 差(予測-実測値)
2017/04/14 4.122703 11.0 6.877297
2017/06/03 17.471853 10.6 6.871853
2017/06/10 20.170122 14.4 5.770122
2017/08/12 23.618959 18.4 5.218959
2017/09/28 18.250427 12.9 5.350427
2017/10/03 17.495890 12.1 5.395890
2017/10/30 12.778524 6.3 6.478524
2017/11/04 9.931356 4.8 5.131356
2017/11/15 8.744248 2.6 6.144248
2017/11/19 4.005367 -2.3 6.305367
2017/11/28 -1.970369 4.8 6.770369
2017/11/30 1.425418 -3.6 5.025418
2017/12/26 0.993734 -6.3 7.293734
こんな感じですが、これだけだと何が要因でよくない精度になっているかわからないですね...
その日の実測値が異常値(季節外れの暑さ、寒さ)なのかなあと直感的には思いますが、それほど単純な原因ではないのかも。
まあそれなりの精度は出ましたので、とりあえず先に進みます。
■5.指定した月の平均気温を予測する
ようやく本題に辿り着きました。
ここまでで実装してきた次の日の平均気温を予測する学習モデルを使用して、指定した月の平均気温を予測する機能を実装していきます。
気象庁が発表しているこの先1か月の季節予報を行うイメージです。
季節予報は例えば4月の予報が3月末に出てもあまり意味がないので、10日前に予報が出せる仕様とします。
# coding: utf-8
import numpy as np
import pandas as pd
# CSVファイルから気象データをDataFrame型で取得する
def get_dfWeather_data():
# 最初のカラム(年月日)をindexとし、最初の5行を読み飛ばす
dfWeather = pd.read_csv('data_sapporo1975-2017.csv', index_col=0, parse_dates=True, skiprows = 5, encoding = 'shift_jis', header=None)
# 不要な列を削除する
dfWeather = dfWeather.drop([3, 4, 6, 8, 10, 11, 12, 14, 15, 17, 19, 20, 21, 23, 24, 26, 28, 29, 30, 32, 33, 35, 37, 38, 39, 41, 42, 44, 46, 47, 49, 51, 53, 54, 56, 58, 60, 61, 63, 65, 67, 68, 70, 72, 74, 75, 77, 79], axis=1)
# 列名を指定する
dfWeather.columns = [
'day_of_the_week', # 曜日
'average_temperature', # 平均気温(℃)
'average_temperature_avg', # 平均気温_平年(℃)
'average_temperature_diff', # 平均気温_平年差(℃)
'total_precipitation', # 降水量の合計(mm)
'total_precipitation_avg', # 降水量の合計_平年(mm)
'total_precipitation_diff', # 降水量の合計_平年差(mm)
'total_snowfall_amount', # 降雪量合計(cm)
'total_snowfall_amount_avg', # 降雪量合計_平年(cm)
'total_snowfall_amount_diff', # 降雪量合計_平年差(cm)
'deepest_snow_cover', # 最深積雪(cm)
'deepest_snow_cover_avg', # 最深積雪_平年(cm)
'deepest_snow_cover_diff', # 最深積雪_平年差(cm)
'sunshine_hours', # 日照時間(時間)
'sunshine_hours_avg', # 日照時間_平年(時間)
'sunshine_hours_diff', # 日照時間_平年差(時間)
'average_wind_speed', # 平均風速(m/s)
'average_wind_speed_avg', # 平均風速_平年(m/s)
'average_wind_speed_diff', # 平均風速_平年差(m/s)
'highest_temperature', # 最高気温(℃)
'highest_temperature_avg', # 最高気温_平年(℃)
'highest_temperature_diff', # 最高気温_平年差(℃)
'lowest_temperature', # 最低気温(℃)
'lowest_temperature_avg', # 最低気温_平年(℃)
'lowest_temperature_diff', # 最低気温_平年差(℃)
'average_humidity', # 平均湿度(%)
'average_humidity_avg', # 平均湿度_平年(%)
'average_humidity_diff', # 平均湿度_平年差(%)
'average_cloud_cover', # 平均雲量(10分比)
'average_cloud_cover_avg', # 平均雲量_平年(10分比)
'average_cloud_cover_diff' # 平均雲量_平年差(10分比)
]
return dfWeather
# 特徴量のリストを取得する
def get_feature_value_list():
return ['average_temperature']
# 一つの時系列データの長さを取得する
def get_length_per_unit():
return 365
まず、学習モデルと共用できる部分を別プログラムとして外出しにしました。
# coding: utf-8
import copy, datetime, os, sys
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import Keras_rnn_common as krc
from dateutil.relativedelta import relativedelta
from keras.models import Sequential, model_from_json
from keras.layers import Dense, Activation
from keras.layers.recurrent import SimpleRNN, LSTM
from keras import optimizers
from keras.callbacks import CSVLogger
from keras import metrics
ARGV_SIZE = 2 # コマンドライン引数の数
LENGTH_PER_UNIT = krc.get_length_per_unit() # 一つの時系列データの長さ
FEATURE_VALUE = krc.get_feature_value_list() # 扱う特徴量
DIMENSION = len(FEATURE_VALUE) # 特徴量の数
# 引数の数が異なれば終了
if len(sys.argv) != ARGV_SIZE:
print('Error : Please specify ', str(ARGV_SIZE - 1) , ' arguments.') # プログラム名が引数の1つなので
sys.exit(1)
### 引数から値を取得
# 予測する年月(yyyymm)
predict_month = sys.argv[1]
try:
# 予測する年月を日付型に変換
predict_month_date = datetime.datetime.strptime(predict_month, '%Y%m') # 予測する年月の1日
except ValueError as e:
# 変換に失敗した場合
print(e, ': Please specify the predict month in the form of yyyymm.')
sys.exit(1)
予測する年月を引数で指定する仕様とし、引数チェックを最初に行っています。
学習モデルを読み込んで設定する部分は同じなので省略。
### 気象データを初期取得する範囲を決める
# 終了日は予測する年月の1日の10日前
end_date = predict_month_date - datetime.timedelta(days = 10)
# 開始日は、先に決めた終了日の365日前
start_date = end_date - datetime.timedelta(days = 365)
# 気象データを取得
dfWeather = krc.get_dfWeather_data()
dfWeatherTest = dfWeather.ix[start_date:end_date, FEATURE_VALUE] # 指定範囲に絞り込む
dfWeatherTest = dfWeatherTest.sort_index() # 日付順に並び替え
dfWeatherTest = dfWeatherTest.dropna() # 欠損値のある行を取り除く
# モデルに読み込ませるデータを取得する
X_test, Y_test, Y_test_date = krc.generate_data(dfWeatherTest, LENGTH_PER_UNIT, DIMENSION)
# 正解データは使用しないので一旦削除しておく
Y_test = []
Y_test_date = []
例えば2017年12月の平均気温を予測する場合、
2017/12/1の平均気温を予測時に必要な時系列データは2016/12/1~2017/11/30
なんですが、10日前に予報が出せる仕様になってますので、実測値が使えるのは2017/11/20までとなります。
予測する範囲に2017/11/21~2017/11/30も加わるため、予測に必要な時系列データの範囲は
2016/11/20~2017/12/30となります。
2016/11/20~2017/11/20は実測値を用い、
2017/11/21~2017/12/30は予測値を用いるということになります。
この考えのもと、取得する実測値の範囲を決めているのが上記の実装になります。
次に指定月の1日の予測をするために必要なデータで実測値を使えない範囲(ここまでの説明例だと2017/11/21~2017/11/30)を予測します。
### 取得できなかった範囲は予測データを取得する
# 取得範囲を指定
start_predict = end_date # 開始日は初期取得データと同じ日
end_predict = predict_month_date - datetime.timedelta(days = 1)
# 予測データを取得する
days_num = (end_predict - start_predict).days
for i in range(0, days_num + 1):
# テストデータは毎回正規化し直すため、正規化前のデータを一旦よけておく
X_tmp = copy.deepcopy(X_test)
# テストデータを正規化
X_test /= np.nanmax(np.abs(X_test))
# 予測を行う
y_ = model.predict(X_test)
# 正解データを追加
Y_test = np.append(Y_test, y_)
# 正解データの日付を追加
this_date = start_predict + datetime.timedelta(days = i)
Y_test_date = np.append(Y_test_date, this_date.strftime('%Y/%m/%d'))
# 次回用のテストデータを作成する
X_this = []
for j in range(0, X_tmp[0].size - 1):
# 1つずつ前に出していく
X_this.append(X_tmp[0:1, j + 1, :]) # 正規化前のデータを使用する
# 最後は正解データをセット
X_this.append(Y_test[i:i+1])
# テストデータを置き換える
X_this =np.reshape(np.array(X_this), (1, len(X_this), 1))
X_test = copy.deepcopy(X_this)
予測する際の注意点としては以下2点。
・正解データが次回予測のテストデータとなる
・テストデータは毎回正規化し直す
2点目に最初気が付かなくて結構ハマりました。
ここまでで、指定月の予測を行うためのデータ準備ができました。
ここから指定月の予測を行います。
### 指定月の予測を行う
# 予測範囲を指定する
start_predict = predict_month_date
end_predict = predict_month_date + relativedelta(months=1) - datetime.timedelta(days = 1)
print('predict date range:', start_predict, ' - ', end_predict)
# 結果格納用DataFrame
df_columns = ['予測', '実測値', '平年値', '差(予測-実測値)', '差(予測-平年値)']
dfResultWeather = pd.DataFrame(columns=df_columns)
# 実測値を取得
df_actual_data = dfWeather.ix[start_predict:end_predict, ['average_temperature', 'average_temperature_avg']]
actual_data_array = df_actual_data.as_matrix()
days_num = (end_predict - start_predict).days
for i in range(0, days_num + 1):
# テストデータは毎回正規化し直すので一旦よけておく
X_tmp = copy.deepcopy(X_test)
# テストデータを正規化
X_test /= np.nanmax(np.abs(X_test))
# 予測を行う
y_ = model.predict(X_test)
# グラフ表示用にDataFrame作成
tmp = np.array([
float(y_),
float(actual_data_array[i][0]),
float(actual_data_array[i][1]),
abs(float(y_) - float(actual_data_array[i][0])),
abs(float(y_) - float(actual_data_array[i][1]))])
tmp = np.ravel(tmp)
this_date = start_predict + datetime.timedelta(days = i)
dfResult = pd.DataFrame([tmp], columns=df_columns, index=[this_date])
dfResultWeather = dfResultWeather.append(dfResult)
# 正解データを追加
Y_test = np.append(Y_test, y_)
# 正解データの日付を追加
Y_test_date = np.append(Y_test_date, this_date.strftime('%Y/%m/%d'))
# 次回用のテストデータを作成する
X_this = []
for j in range(0, X_tmp[0].size - 1):
# 1つずつ前に出していく
X_this.append(X_tmp[0:1, j + 1, :]) # 一旦よけておいた正規化前のデータを使用する
# 最後は正解データをセット
X_this.append(Y_test[i:i+1])
# テスト用データを置き換える
X_this =np.reshape(np.array(X_this), (1, len(X_this), 1))
X_test = copy.deepcopy(X_this)
予測の流れは同じです。
結果を可視化するのにDataFrameに予測結果を追加しているのが違う部分。
# 統計情報を表示
print('統計情報:')
print(dfResultWeather.describe())
print('### 予測結果 ###')
print(dfResultWeather)
# グラフ描画
dfResultWeather.plot(y=['予測', '実測値', '平年値'], figsize=(16,10), title='各日平均気温', grid=True)
plt.savefig('one_month_predict.png')
dfResultWeather.plot(y=['差(予測-実測値)', '差(予測-平年値)'], figsize=(16,10), title='各日平均気温 予測と実測値・平年値の差', grid=True)
plt.savefig('one_month_predict_diff.png')
2017年12月の平均気温を予測してみました。
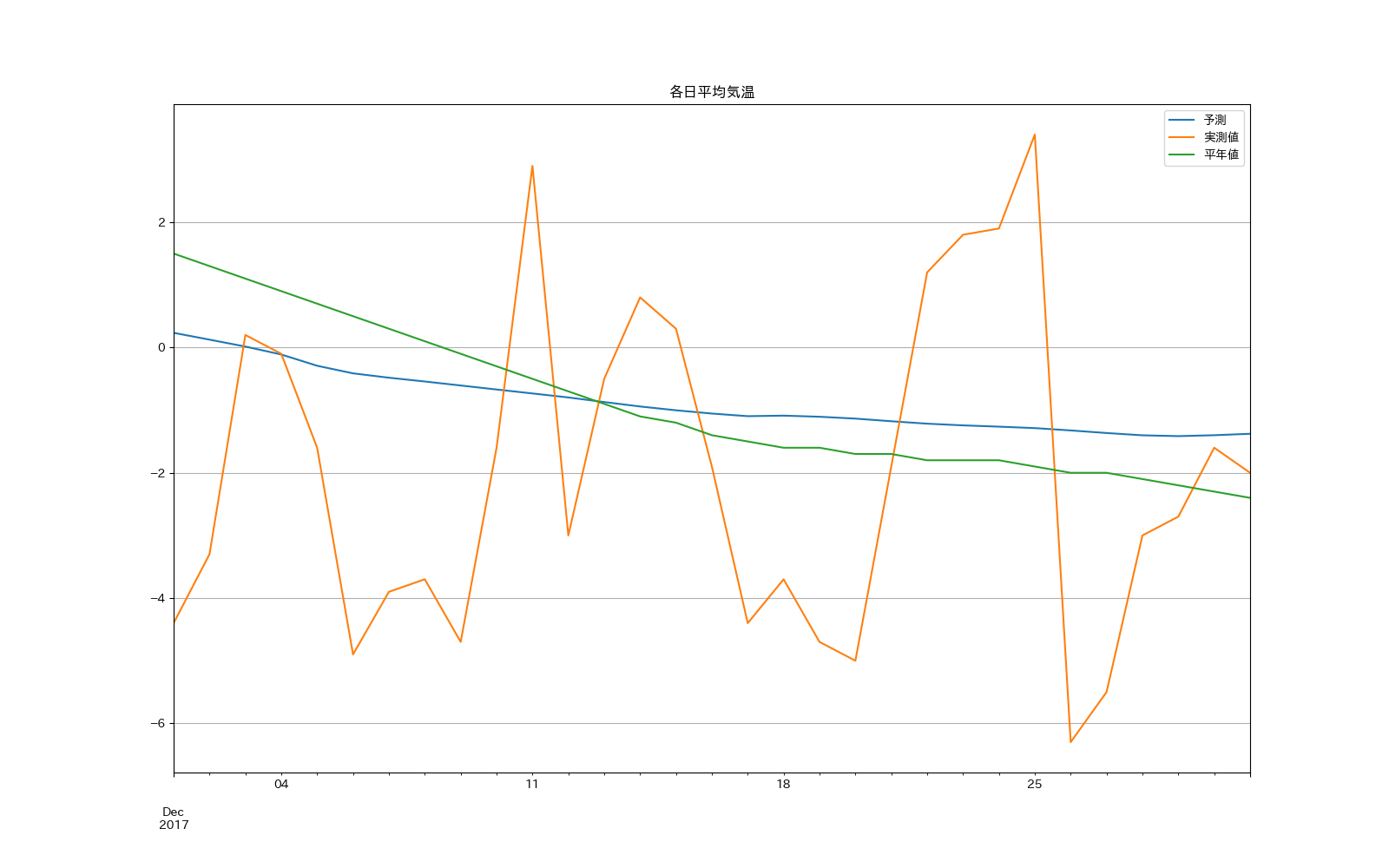
うーん見事に予測できてませんねw
どちらかと言うと平年値に近い結果になってしまいました。
統計情報:
予測 実測値 平年値 差(予測-実測値) 差(予測-平年値)
count 31.000000 31.000000 31.000000 31.000000 31.000000
mean -0.871988 -1.996774 -0.909677 2.450756 0.622927
std 0.484301 2.615401 1.185848 1.543859 0.317917
min -1.414653 -6.300000 -2.400000 0.011315 0.029363
25% -1.253193 -4.150000 -1.800000 1.107573 0.449308
50% -1.054291 -2.000000 -1.400000 2.612444 0.584156
75% -0.574402 0.050000 0.000000 3.614060 0.842681
max 0.234754 3.400000 1.500000 4.976292 1.265246
統計情報を見ても、平年値を予測する機能なら素晴らしい結果ですが...(以下略)
もう一例ぐらいということで、2017年10月を予測してみたところ...
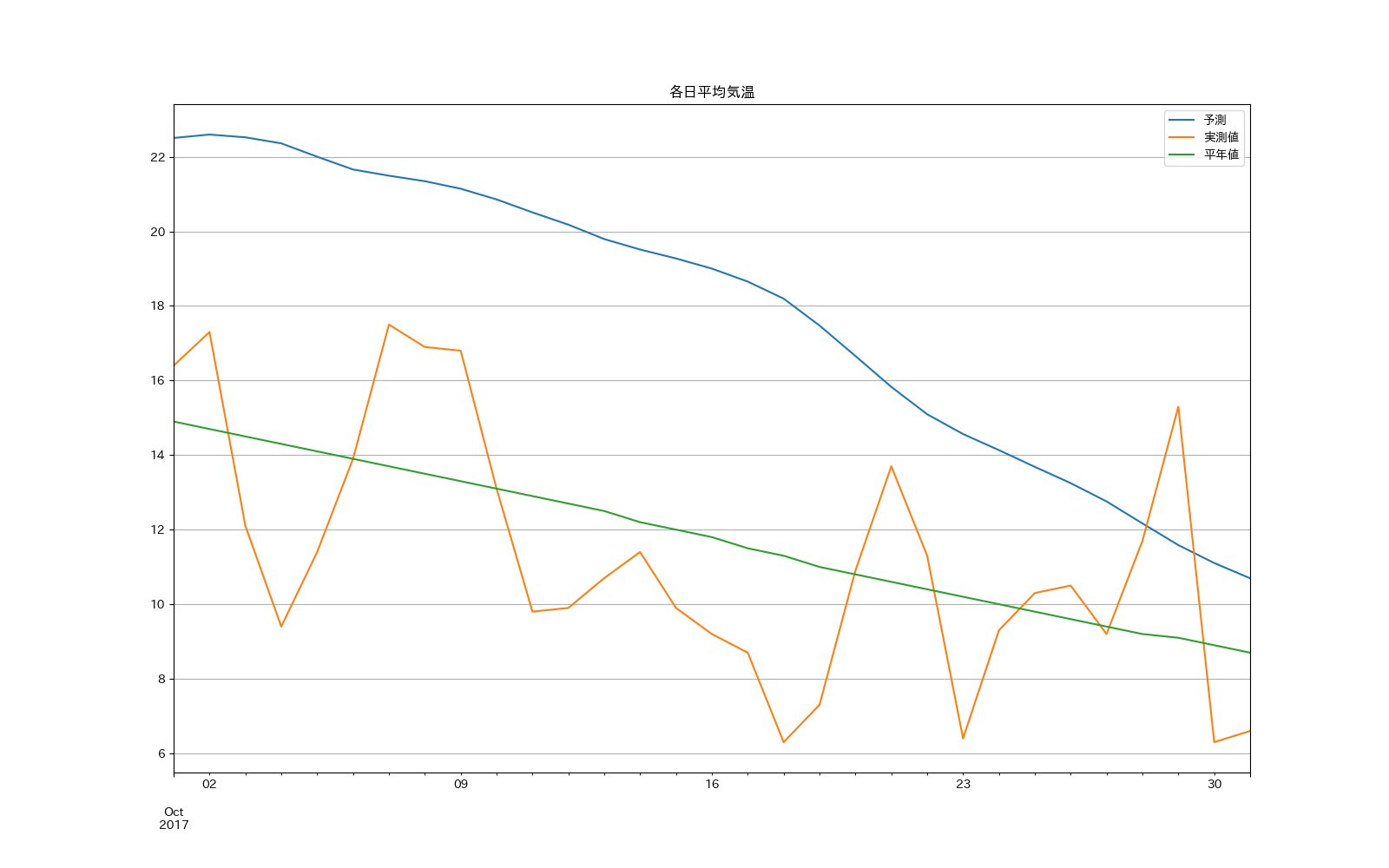
あああ全然ダメですやん(゚∀゚)ガハッ∵∴
まあ...すごーくすごーく贔屓目に見ると実測値と傾き(徐々に気温が下がっている)は似ているのかなと...
■6.まとめと考察
[1]気象庁のサイトからダウンロードした過去の気象データを使用
[2]過去365日の平均気温の推移から次の日の気温を予測する学習モデルを構築
統計情報:
予測 実測値 差(予測-実測値)
count 365.000000 365.000000 365.000000
mean 9.873768 9.183014 1.858874
std 10.138869 9.597346 1.445496
min -8.134899 -9.100000 0.002906
25% -0.308933 0.100000 0.756734
50% 10.543715 9.800000 1.468483
75% 18.657780 17.700000 2.733871
max 27.374790 27.700000 7.293734
・最大で約7.3度の差は
・25%のデータは約0.76度の差に収まっている
・50%のデータは約1.47度の差に収まっている
・75%のデータは約2.73度の差に収まっている
それなりの精度にはなっている。
[3]その学習済モデルを使い、ある月1か月の平均気温の推移をその月の10日前に予測するモデルを作った
2017年12月の平均気温を予測。
平均気温よりは平年値に近い予測結果となった。
別の月ではもっと顕著な差が出て、モデルとしては予測できていないことがわかる。
原因として推測されるのは、学習済モデルの精度の問題なのかなと。
単体で見ると悪くないように見えるが、それを使って別の予測をするには精度がもっと高くないとダメなのかも。
もしくは回帰ではなく、分類させた方がよいのかも。
後は、一項目だけの単純なモデルなので、異常値(平年よりも高すぎ/低すぎ)の影響を受けやすいというのもありそうです。