「AIってつまりDBですよね」
僕「ちがいます」
どうやら、世の中にはAIとDBを同列のものだと考える人もいるようです。
(前回記事の続きです。AIの未来を本気で憂えているので、同感の方はLGTMお願いします)
DBだと語る人の意見と正解
- AIは学習データを丸暗記している
- 学習データは選択できるのだから、出力もコントロールできる
- 追加学習とかファインチューニングって知識を上乗せしているんでしょ
...全部違うぜ!正解は
- AIはデータの特徴からパターンを学習している
- これにより柔軟性を得る
- 出力はコントロールできない
- 演繹ではなく帰納だから
- (一般的に)追加学習はネットワークの全体を、ファインチューニングは出力に近いネットワークを調整する
- DBのレコード追加、削除のような簡単な話ではない
DBだと捉えた場合の弊害
「学習した内容は確実に取り出せる」
「学習したことなら完璧にできるでしょ?」
これは誤りです。
どれだけ複雑なモデルを用意しても、誤差が0になることはありません。
授業で回帰直線を書いたことがあると思いますが、すべてのデータポイントを通る直線を引くことはできません。
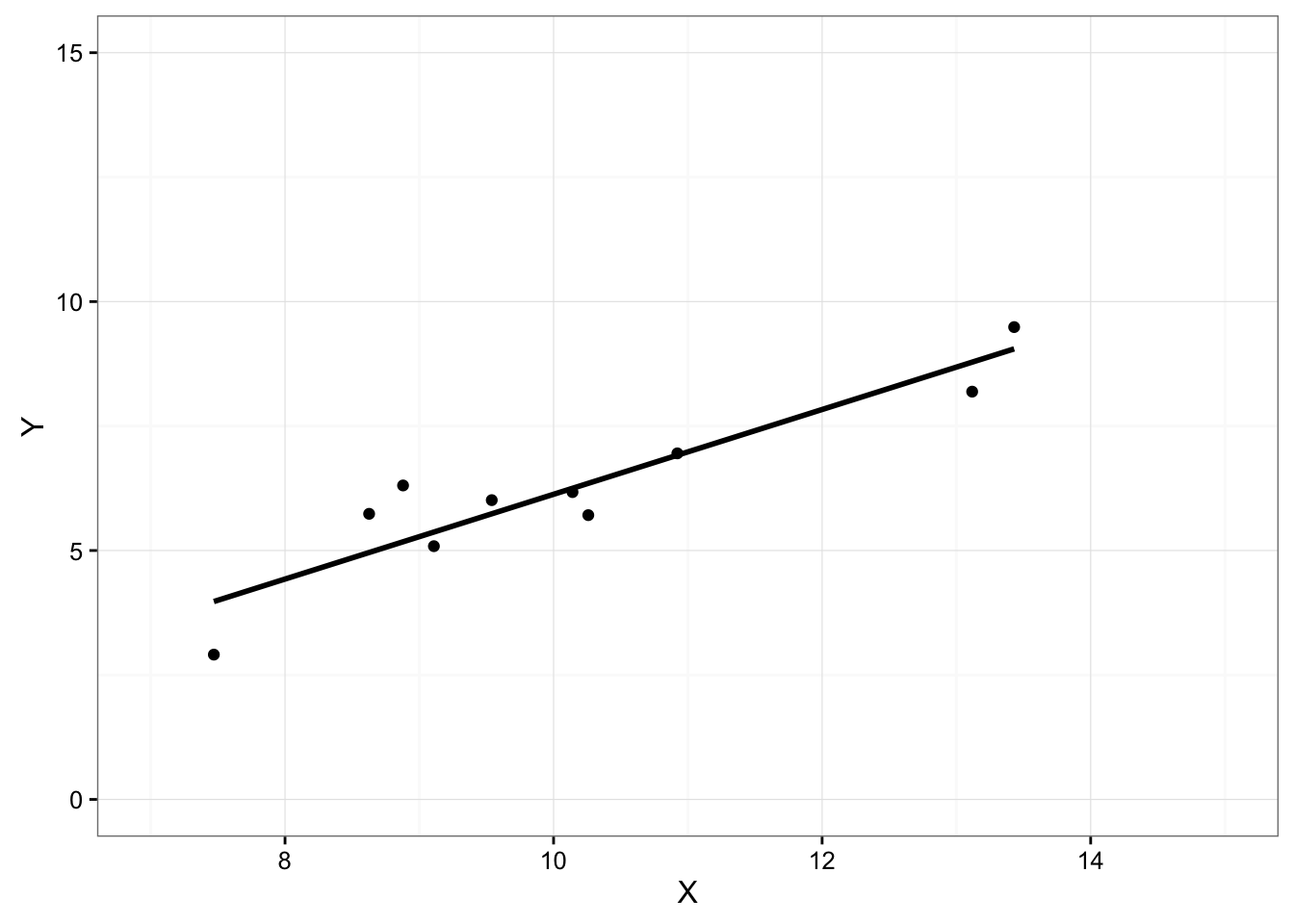
曲線なら?非線形なら?
どんなモデルを使用しようと、実際の因果と予測モデルの仕組みが異なる限りいたちごっこです。
「学習していないデータを入力すると異常な出力になる」
「学習していないデータに対する出力は何らかの異変があるはずだ」
そうとは限りません。
多くのモデルで「どうなるかわからない」が正しいです。
例:スパイラルデータの二値分類タスク
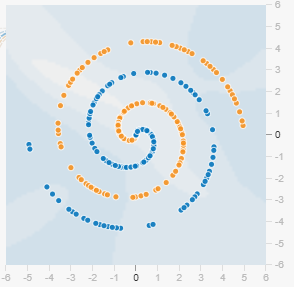
シード値以外同条件で実施 その1
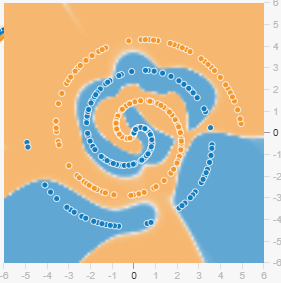
シード値以外同条件で実施 その2
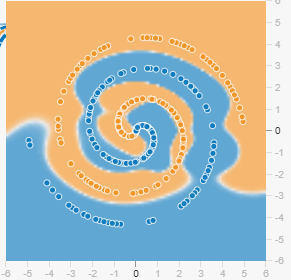
学習データがない場所でも、なんの変哲もなくどちらかに分類します。
例えばLLMにおいては、「文法は大量に学習したので合っているが、選択される名詞が誤っている」などが発生し、ハルシネーションの一つとして知られています。(特に生成モデルにおいては、ドンピシャに正解を当てることが目的ではなく次トークンの分布を出力するので揺らぎを許容します。実運用上ではtemperatureを低めに設定するので実質的に分類と同じになりますが...)
ちなみに、学習データ範囲外の特徴は外挿領域と呼ばれます。
外挿領域は未定義動作を引き起こします。
↓ここから遊べます
「誤りは確実に直せる」
「学習しているのになんでできないんだ?」
僕「モデルかデータが悪いと思います」
「じゃあ直して」
僕「無理です...」
AIを使うことで、非常に高い精度を得られますが、100%ではありません。ソフトウェア工学の世界から来たステークホルダーの多くは、これをバグとして扱い、100%正しいものしか受け入れようとしません。彼らは、どんなAIシステムも、間違った出力をすることがあるという事実を理解していません。
引用元:
機械学習では「あちらを立てればこちらが立たず」が高頻度で発生します。特に深層学習では決まったサイズのパラメータを調整するので、当然と言えば当然なのかもしれません。
ラプラスの悪魔がいたら
- すべてのニューラルネットワークのウエイト&バイアス
- 将来運用環境で入力されるすべての未知データ
これらすべてが見通せるのでできるかもしれません。
人間には不可能ですね...
LLMは枝刈りができる一方、非常に重要なウエイトがあることも事実です。パラメータを変えたら全く異なる挙動になる可能性が十分にあるのです。
加えて、実運用で入力されるデータは完全に未知なので、その場限りの修正ができたとしてもワークしないでしょう。
モデルは作った瞬間に世界と切り離され劣化するのです。
Ex.
上記の理由より、モデルの誤った出力について「なぜなぜ分析攻撃」をするとデータサイエンティストは簡単に病みます。すべては確率だからです。(僕は実際に製造業向け物体検出タスクで病みました)
確率ゆえに、無限の猿定理によってすべての可能性を否定することもできません。
完全ランダムにトークンを吐き出すLLMでも、運が良ければ期待するテキストが出てきてしまうからです。(もちろんハッシュが衝突する可能性と同様、考慮するべきでない。ほぼゼロ。)
tranformerではQuery, Key, Valueといったワードが出るけどこれはまたDBとは別のお話。
データとモデルについて議論することが最も有意義です。