はじめに
にゃーん
この記事は、PostgreSQL 10全部ぬこ Advent Calendar 2017 の15日目のエントリです。
で、今日はちょい地味目のネタですまんな。
macaddr型
PostgreSQLでは他DBMSにはない、ある領域に特化したデータ型を数多くサポートしている。今日取り上げるmacaddr型もそのうちの一つ。
このデータ型は名前のとおりmacaddrの表現を管理するデータ型。
単に格納するだけではtext型と変わらないのだが、この型に対する演算子・関数がいろいろ用意されている。
PostgreSQL 10の性能改善内容
PostgreSQL 10では、このmacaddr型のソート処理が高速化された。
どうやってやってるの
5日目のnumeric型の集約関数の性能向上でも取り上げたように、改善内容についてCommitfestから追ってみることにする。今回のテーマになっているmacaddr型の集約関数の高速化は、たぶん、このへんの議論の結果だと思われる。
タイトルはmacaddr型に対するソートの実装、というように読めるのだけど、実際にはPostgreSQL 9.6でもmacaddr型に対するソートは実行できる。
この改修は、macaddrの値をDatumnに詰めなおして、符号なし数値として高速にソートするというコンセプトっぽい。(たぶん)
実測
とりあえず手元の環境で、本当にmacaddr型のソート性能が向上しているのか見てみることにする。
環境
- Let's note SX4/SSD モデル/メモリ8GB
- VMWare/CentOS 7
- PostgreSQL 9.6/PostgreSQL 10ともにビルドインストール。
お金がないので手元で使えるノートPC上で測定します。
検証用データ
こんな感じのクエリで100万件のランダムなmacaddr型データを生成しておく。
COPY (
SELECT generate_series(1,1000000), '80:' ||
to_hex((random() * 255)::int)::text || ':' ||
to_hex((random() * 255)::int)::text || ':' ||
to_hex((random() * 255)::int)::text || ':' ||
to_hex((random() * 255)::int)::text || ':' ||
to_hex((random() * 255)::int)
) TO '/tmp/macaddr-1000k.txt'
;
データ内容はこんな感じ
1 80:bb:2b:f5:3d:ca
2 80:d6:b0:29:b:8
3 80:9e:21:18:bb:5f
(中略)
999998 80:d1:e:45:c4:2d
999999 80:44:d7:d6:80:32
1000000 80:55:95:3c:c:75
これを以下のようなテーブルに突っ込んでおく。
numeric=# \d numeric_test
Unlogged table "public.numeric_test"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | macaddr |
Indexes:
"numeric_test_pkey" PRIMARY KEY, btree (id)
検証用のクエリと設定
今回は以下の3つのクエリをEXPLAIN ANALYZEを付けて実行し、そのExecution Timeを測定する。
SELECT FROM macaddr_test ORDER BY data;
なお、ソート処理は9.6も10もメモリソート上で実施させる。このために、以下のようにwork_memの値を256MBに設定しておく。
SET work_mem TO '256MB';
また、シンプルに集約関数の処理時間の差を測定することになるので、他のPostgreSQLパラメータは9.6も10もデフォルトのままにしてある。たぶん、それで大丈夫。
測定前にcount(*) を使って事前に共有バッファ上にキャッシュしておく。
3回測定し、その平均を取得。
検証結果
PostgreSQL 9.6もPostgreSQL 10も実行計画はこんな感じになる。
macaddr=# EXPLAIN ANALYZE SELECT FROM test ORDER BY data;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Sort (cost=115063.84..117563.84 rows=1000000 width=6) (actual time=511.850..652.090 rows=1000000 loops=1)
Sort Key: data
Sort Method: quicksort Memory: 71452kB
-> Seq Scan on test (cost=0.00..15406.00 rows=1000000 width=6) (actual time=0.070..132.478 rows=1000000 loops=1)
Planning time: 0.043 ms
Execution time: 715.541 ms
(6 rows)
検索時間をSeqScan時間、ソート準備時間、ソート時間別にわけて確認する。
| バージョン | SeqScan時間(ms) | ソート準備時間(ms) | ソート時間(ms) |
|---|---|---|---|
| PostgreSQL 9.6 | 130.101 | 710.495 | 166.714 |
| PostgreSQL 10 | 128.866 | 305.350 | 143.310 |
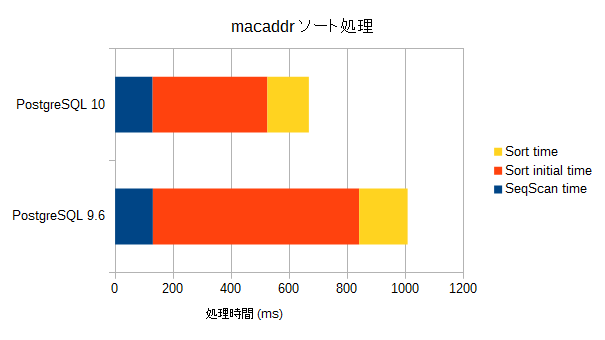
PostgreSQL 10では、ソート準備のための処理の時間が大きく短縮されていることが分かる。ソート処理そのものは、それほど大きな変化はない。
おわりに
macaddr型自体は、結構特殊な型なので、PostgreSQLでネットワーク機器を管理するようなケースでもない限り、実案件で使う機会はそれほど多くはないと思う。
しかし、そうした特殊なデータ型についても手抜きをせず、きちんと性能向上がなされているあたりが、PostgreSQL開発コミュニティの良いところだなあと、改めて思ったのである。
参考:該当するリリースノート
本エントリに関連するPostgreSQL 10リリースノートの記載です。
E.2.3.1.5. General Performance
- Improve sort performance of the macaddr data type (Brandur Leach)