はじめに
にゃーん
この記事は、PostgreSQL 10全部ぬこ Advent Calendar 2017 の5日目のエントリです。
今日はPGCONF.Asia 2017のDay-1。私も勉強のためにいろいろ聞いてきます。
で、今日もちょい地味目のネタですまんな。
numeric型
PostgreSQLでは何種類か数値型がサポートされている。(参照:Numeric Types)
ちょっと紛らわしいが、「数値型全般」をNumeric TypesとPostgreSQLでは表記しているんだが、今日のテーマはその数値型のカテゴリの一つ、Arbitrary Precision Numbers(日本語PostgreSQL文書では「任意の精度を持つ数」のデータ型numericに関するもの。
このデータ型はbigintを超える範囲の数を格納でき、さらに小数点以下の値も格納可能。そして浮動小数点データ型と異なり演算の誤差がでない、という機能的には優れもの。そんかし、その代償として、他の数値型と比較すると大きな格納領域を必要とし、演算性能もよろしくないという特徴がある。
OracleのNUMBER型に相当するもの(でいいのかな?)。
PostgreSQL 10の性能改善内容
numeric型の演算性能については、以前から課題としてPostgreSQL開発コミュニティでも認識されていて、これまでにも幾つかのバージョンでnumeric演算に関する性能改善が実施されている。
そして、PostgreSQL 10でも集約関数の性能改善がされている。対象となる関数は以下の3つ。
- SUM()
- AVG()
- STDDEV()
どうやってやってるの
ここ数年のPostgreSQL開発ではCommitfestという枠組みを導入して、パッチレビューとパッチの組み込みを実施しており、パッチ投稿やレビューの様子を、自分のような非開発者・英語やC言語を読むのが苦手な人であっても追跡することができる。
今回のテーマになっている集約関数の高速化は、たぶん、このへんの議論の結果だと思われる。
で、そこにパッチのソースがついている。大抵の場合、ソースには詳しいコメントがついており、それを(俺みたいに英語が読めない情弱はGoogle先生のパワーを借りて)読むことである程度、どんな改善をしているか推測ができる。
この改善の場合、コストの高い桁繰り上がりの処理をint32の変数をうまいこと使って、10000単位で遅延させることで性能を改善させているように思える。
SUM(), AVG(), STDDEV()では大量の加算処理が発生するため、桁繰り上がりの処理を毎桁行わずに遅延させることで性能を向上しているのだろうと推測してみた。
(きちんと英語やCコードが読める人がいたら指摘よろしくです)
実測
とりあえず手元の環境で、本当に性能が向上しているのか見てみることにする。
環境
- Let's note SX4/SSD モデル/メモリ8GB
- VMWare/CentOS 7
- PostgreSQL 9.6/PostgreSQL 10ともにビルドインストール。
お金がないので手元で使えるノートPC上で測定します。
検証用データ
こんな感じのクエリで100万件のランダムなnumericデータを生成しておく。
COPY
(SELECT t.id, (random() * 1000000000000000)::numeric + random()::numeric
FROM (SELECT generate_series(1,1000000) as id) AS t)
TO '/tmp/numeric.dat';
データ内容はこんな感じ
1 622149858158082.795957470312715
2 483273191843182.15136305661872
3 206579154357314.880250687710941
4 551065794192255.122989198192954
5 473818496335298.539346074219793
6 910536431707442.00904520973563194
(中略)
999996 721897167619318.856217079795897
999997 125256475992501.740928886458278
999998 5043825134635.436023179702461
999999 260133428964764.634972156491131
1000000 472933328710496.334050448611379
これを以下のようなテーブルに突っ込んでおく。
numeric=# \d numeric_test
Unlogged table "public.numeric_test"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | numeric |
Indexes:
"numeric_test_pkey" PRIMARY KEY, btree (id)
検証用のクエリと設定
今回は以下の3つのクエリをEXPLAIN ANALYZEを付けて実行し、そのExecution Timeを測定する。
SELECT SUM(data) FROM numeric_test ;
SELECT AVG(data) FROM numeric_test ;
SELECT STDDEV(data) FROM numeric_test ;
なお、このクエリはPostgreSQL 9.6以降ではパラレルクエリの対象になるので、PostgreSQL 10の場合は
SET max_parallel_workers_per_gather TO 0;
でパラレルクエリを無効化しておく(9.6はデフォルトが0なのでそのまま)。
また、シンプルに集約関数の処理時間の差を測定することになるので、他のPostgreSQLパラメータは9.6も10もデフォルトのままにしてある。たぶん、それで大丈夫。
測定前にcount(*) を使って事前に共有バッファ上にキャッシュしておく。
3回測定し、その平均と分散を取得。
検証結果
数値の単位はms。
| バージョン | SUM | AVG | STDDEV |
|---|---|---|---|
| PG9.6 | 354.039 | 357.863 | 657.945 |
| PG10 | 263.492 | 265.170 | 457.593 |
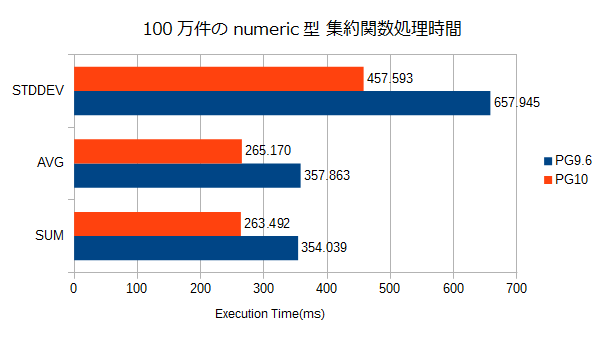
100万件程度でも有意な性能差が確認できた。
おわりに
numeric型の改善はこれからも続くのかな。
なので、以前ほどnumeric型を嫌うこともなくなってくるかもしれない。
とはいえ、格納するデータの値域が、int8で格納できる範囲であったり、誤差を許容できるデータであるならnumericよりはint8やdouble precisionを使うべき、というセオリーは変わらないとは思うけど。
参考:該当するリリースノート
本エントリに関連するPostgreSQL 10リリースノートの記載です。
E.2.3.1.5. General Performance
- Speed up aggregate functions that calculate a running sum using numeric-type arithmetic, including some variants of SUM(), AVG(), and STDDEV() (Heikki Linnakangas)