はじめに
先日、ANNOUNCEのMLにpg_squeezeという見慣れぬEXTENSIONのbetaリリースが流れていたので、ちょっと試してみることにした。
pg_squeezeとは
ざっと見た感じでは、自動的にテーブルの再編成を行うツールのようだ。
要するに、自動CLUSTER、あるいは自動pg_repackという感じのツールか。
PostgreSQL 9.3から導入されたBackground Worker基盤の上で動くツールなので、EXTENSIONを組み込んでおけばPostgreSQL起動や終了と同期してくれるのがポイントか。
インストール
make
さっそく、ソースのアーカイブを入手してビルドしてみる。今回はPostgreSQL 9.6上にインストールしてみる。
何も考えずにアーカイブを展開してmakeしてみると・・・
[nuko@localhost pg_squeeze-1.0beta1]$ make USE_PGXS=1
make: --pgxs: コマンドが見つかりませんでした
make: *** ターゲットがありません. 中止.
(´・ω・`) しょぼーん
きちんとREADMEを見るか。
READMEを見ると、環境変数PG_CONFIGを設定しないといけないようだ。えー。
環境変数を設定して再度ビルドしてみる。
[nuko@localhost pg_squeeze-1.0beta1]$ export PG_CONFIG=/home/nuko/pgsql/pgsql-9.6.0/bin/pg_config
[nuko@localhost pg_squeeze-1.0beta1]$ make
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fpic -I. -I./ -I/home/nuko/pgsql/pgsql-9.6.0/include/server -I/home/nuko/pgsql/pgsql-9.6.0/include/internal -D_GNU_SOURCE -c -o pg_squeeze.o pg_squeeze.c
pg_squeeze.c: 関数 ‘squeeze_table’ 内:
pg_squeeze.c:1887:6: 警告: ‘tup_in’ はこの関数内初期化されずに使用されるかもしれません [-Wmaybe-uninitialized]
if (tup_in == NULL)
^
pg_squeeze.c:1771:13: 備考: ‘tup_in’ はここで定義されています
HeapTuple tup_in;
^
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fpic -I. -I./ -I/home/nuko/pgsql/pgsql-9.6.0/include/server -I/home/nuko/pgsql/pgsql-9.6.0/include/internal -D_GNU_SOURCE -c -o concurrent.o concurrent.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fpic -I. -I./ -I/home/nuko/pgsql/pgsql-9.6.0/include/server -I/home/nuko/pgsql/pgsql-9.6.0/include/internal -D_GNU_SOURCE -c -o worker.o worker.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fpic -I. -I./ -I/home/nuko/pgsql/pgsql-9.6.0/include/server -I/home/nuko/pgsql/pgsql-9.6.0/include/internal -D_GNU_SOURCE -c -o pgstatapprox.o pgstatapprox.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fpic -shared -o pg_squeeze.so pg_squeeze.o concurrent.o worker.o pgstatapprox.o -L/home/nuko/pgsql/pgsql-9.6.0/lib -Wl,--as-needed -Wl,-rpath,'/home/nuko/pgsql/pgsql-9.6.0/lib',--enable-new-dtags
[nuko@localhost pg_squeeze-1.0beta1]$
なんか警告は出てるけど一応はビルドできた。
make check
make checkはサポートしていない。
[nuko@localhost pg_squeeze-1.0beta1]$ make check
"make check" is not supported.
Do "make install", then "make installcheck" instead.
[nuko@localhost pg_squeeze-1.0beta1]$
make install
なのでインストールしてからinstallcheckを動かすことにする。
[nuko@localhost pg_squeeze-1.0beta1]$ make install
/usr/bin/mkdir -p '/home/nuko/pgsql/pgsql-9.6.0/lib'
/usr/bin/mkdir -p '/home/nuko/pgsql/pgsql-9.6.0/share/extension'
/usr/bin/mkdir -p '/home/nuko/pgsql/pgsql-9.6.0/share/extension'
/usr/bin/install -c -m 755 pg_squeeze.so '/home/nuko/pgsql/pgsql-9.6.0/lib/pg_squeeze.so'
/usr/bin/install -c -m 644 .//pg_squeeze.control '/home/nuko/pgsql/pgsql-9.6.0/share/extension/'
/usr/bin/install -c -m 644 .//pg_squeeze--1.0.sql '/home/nuko/pgsql/pgsql-9.6.0/share/extension/'
無事にインストール完了。
make installcheck
インストールできたので、installcheckをかけてみる。
[nuko@localhost pg_squeeze-1.0beta1]$ make installcheck
/home/nuko/pgsql/pgsql-9.6.0/lib/pgxs/src/makefiles/../../src/test/regress/pg_regress --inputdir=./ --bindir='/home/nuko/pgsql/pgsql-9.6.0/bin' --dbname=contrib_regression squeeze
(using postmaster on Unix socket, default port)
============== dropping database "contrib_regression" ==============
NOTICE: database "contrib_regression" does not exist, skipping
DROP DATABASE
============== creating database "contrib_regression" ==============
ERROR: permission denied to create database
command failed: "/home/nuko/pgsql/pgsql-9.6.0/bin/psql" -X -c "CREATE DATABASE \"contrib_regression\" TEMPLATE=template0" "postgres"
make: *** [installcheck] エラー 2
あー、うちの環境で動かすとユーザ名がnukoになっちゃうんだよな。仕方がない。
環境変数PGUSER=postgresを設定してリトライ。
[nuko@localhost pg_squeeze-1.0beta1]$ export PGUSER=postgres
[nuko@localhost pg_squeeze-1.0beta1]$ make installcheck
/home/nuko/pgsql/pgsql-9.6.0/lib/pgxs/src/makefiles/../../src/test/regress/pg_regress --inputdir=./ --bindir='/home/nuko/pgsql/pgsql-9.6.0/bin' --dbname=contrib_regression squeeze
(using postmaster on Unix socket, default port)
============== dropping database "contrib_regression" ==============
NOTICE: database "contrib_regression" does not exist, skipping
DROP DATABASE
============== creating database "contrib_regression" ==============
CREATE DATABASE
ALTER DATABASE
============== running regression test queries ==============
test squeeze ... FAILED (test process exited with exit code 2)
======================
1 of 1 tests failed.
======================
The differences that caused some tests to fail can be viewed in the
file "/home/nuko/src/pg_squeeze-1.0beta1/regression.diffs". A copy of the test summary that you see
above is saved in the file "/home/nuko/src/pg_squeeze-1.0beta1/regression.out".
make: *** [installcheck] エラー 1
[nuko@localhost pg_squeeze-1.0beta1]$
えー、installcheckにカジュアルに失敗してるんだけど・・・。
regressionのdiffを見てみると、
---
> FATAL: cannot create PGC_POSTMASTER variables after startup
> server closed the connection unexpectedly
> This probably means the server terminated abnormally
> before or while processing the request.
> connection to server was lost
えー、PGC_POSTMASTER変数って何よ・・・。そんなのREADMEに書いてないんだが。
まあ、いいや。とりあえずインストールはできたんだろうし、先に動かしてみよう。
使用条件
このツールもCLUSTERコマンドや、pg_repackと同様にPrimary Key/Unique Keyが存在するテーブルでないと動作しないっぽい。
First, make sure that your table has either primary key or unique
constraint. This is necessary to process changes other transactions might do
while "pg_squeeze" is doing its work.
PostgreSQL設定
READMEを読むと、以下のPostgreSQL設定が必要とな。
4. Apply the following settings to postgresql.conf:
wal_level = logical
max_replication_slots = 1 # ... or add 1 to the current value.
shared_preload_libraries = 'pg_squeeze' # ... or add the library to the existing ones.
ほお。pg_squeezeはロジカルデコーディングの機能も使っているんだな。ふむ。
あ・・・ということは、UNLOGGED TABLEに対してはこのツールは使えないってことなのかな・・・。
とりあえず、postgresql.confに上記のような設定をしてPostgreSQLを再起動してみる。
shared_preload_libraries = 'pg_squeeze'
squeeze.worker_autostart = 'bench'
squeeze.worker_role = postgres
squeeze.* のパラメータはpg_squeeze専用のもの。この設定にしておくと、PostgreSQLサーバ起動時に自動的にbenchデータベースに対するpg_squeezeの処理をしてくれるものっぽい(たぶん)。
サーバログを見ると、とくにこのEXTENSIONを組み込みが正常に終了した等のメッセージは出ていない。pgauditみたいに組み込んだことが分かるメッセージくらい出してもいいのになあ。
EXTENSIONの登録
pg_squeezeはデータベースへの登録が必要らしい。今回はpgbench用のデータベースbenchに組み込んで見る。
[nuko@localhost ~]$ psql -U postgres bench
psql (9.6.0)
Type "help" for help.
bench=# CREATE EXTENSION pg_squeeze ;
CREATE EXTENSION
bench=#
pg_squeeze用の設定
さて、このpg_squeezeだが、EXTENSIONを組み込んだだけで自動的によしなに再編成・・・ということはしてくれない。
いろいろ設定が必要っぽい。
squeezeスキーマのテーブル群
pg_squeezeでは、管理用にいろんなテーブルをsqueezeスキーマ上に作ってみるみたい。
bench-# \d squeeze.
squeeze.errors squeeze.tables squeeze.tables_tabschema_tabname_key
squeeze.errors_id_seq squeeze.tables_id_seq squeeze.tasks
squeeze.errors_pkey squeeze.tables_internal squeeze.tasks_active_idx
squeeze.log squeeze.tables_internal_pkey squeeze.tasks_id_seq
squeeze.log_started_idx squeeze.tables_pkey squeeze.tasks_pkey
bench-# \d squeeze.
pg_squeezeを使う場合には、squeeze.tableに再編成処理対象のテーブルを登録する必要がある。めんどい。
今回は、pgbench_branchesテーブルを対象にする。このテーブルは、fillfactorを設定しないと、すぐに肥大化しそうだからだ。
(もっとも、レコード数自体は非常に少ないので、肥大化したとしても、それほど実害はないような気もするが)
squeeze.tableはこんなテーブルだ。
bench-# \d squeeze.tables
Table "squeeze.tables"
Column | Type | Modifiers
------------------+--------------------------+-------------------------------------------------------------
id | integer | not null default nextval('squeeze.tables_id_seq'::regclass)
tabschema | name | not null
tabname | name | not null
clustering_index | name |
rel_tablespace | name |
ind_tablespaces | name[] |
task_interval | interval | not null default '01:00:00'::interval
first_check | timestamp with time zone | not null
free_space_extra | integer | not null default 50
min_size | real | not null default 8
vacuum_max_age | interval | not null default '01:00:00'::interval
max_retry | integer | not null default 0
skip_analyze | boolean | not null default false
Indexes:
"tables_pkey" PRIMARY KEY, btree (id)
"tables_tabschema_tabname_key" UNIQUE CONSTRAINT, btree (tabschema, tabname)
Check constraints:
"tables_free_space_extra_check" CHECK (free_space_extra >= 0 AND free_space_extra < 100)
"tables_min_size_check" CHECK (min_size > 0.0::double precision)
"tables_task_interval_check" CHECK (task_interval >= '00:01:00'::interval)
Referenced by:
TABLE "squeeze.tables_internal" CONSTRAINT "tables_internal_table_id_fkey" FOREIGN KEY (table_id) REFERENCES squeeze.tables(id) ON DELETE CASCAD
E
TABLE "squeeze.tasks" CONSTRAINT "tasks_table_id_fkey" FOREIGN KEY (table_id) REFERENCES squeeze.tables(id) ON DELETE CASCADE
Triggers:
tables_internal_trig AFTER INSERT ON squeeze.tables FOR EACH ROW EXECUTE PROCEDURE squeeze.tables_internal_trig_func()
トリガが設定されている。squeeze処理対象のテーブルをここに登録すると、他の管理用のテーブルにも何かしらの設定を伝播するのだろう。
とりあえず設定してみる。
bench=# INSERT INTO squeeze.tables (tabschema, tabname, first_check, task_interval, min_size)
VALUES ('public','pgbench_branches',now(),'1 min', 0.1);
INSERT 0 1
bench=# INSERT INTO squeeze.tables (tabschema, tabname, first_check, task_interval, min_size)
VALUES ('public','pgbench_tellers',now(),'1 min', 0.1);
INSERT 0 1
bench=#
とりあえずINSERTはされた。たぶん、こういう設定。
- ターゲットはpublic.pgbench_accountsとpublic.pgbench_tellers
- 最初のsqueeze処理のためのチェックはINSERT文実行時
- 1分毎にチェック(デフォルトは1時間ぽい)
- 肥大化したかどうかの閾値(?)は 0.1 MB
pgbenchによる動作確認
測定環境
今回はScale Factor = 10の状態でpgbench環境を初期生成した。
[nuko@localhost ~]$ pgbench -i -s 10 -U postgres bench
creating tables...
100000 of 1000000 tuples (10%) done (elapsed 0.15 s, remaining 1.38 s)
200000 of 1000000 tuples (20%) done (elapsed 0.42 s, remaining 1.68 s)
300000 of 1000000 tuples (30%) done (elapsed 0.70 s, remaining 1.63 s)
400000 of 1000000 tuples (40%) done (elapsed 0.83 s, remaining 1.25 s)
500000 of 1000000 tuples (50%) done (elapsed 1.04 s, remaining 1.04 s)
600000 of 1000000 tuples (60%) done (elapsed 1.27 s, remaining 0.85 s)
700000 of 1000000 tuples (70%) done (elapsed 1.44 s, remaining 0.62 s)
800000 of 1000000 tuples (80%) done (elapsed 1.65 s, remaining 0.41 s)
900000 of 1000000 tuples (90%) done (elapsed 1.86 s, remaining 0.21 s)
1000000 of 1000000 tuples (100%) done (elapsed 2.88 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
[nuko@localhost ~]$
pgbenchをデフォルトトランザクションで動かすと、pgbench_accounts, pgbench_branches, pgbench_tellersに対してUPDATE文が発行される。
現状はあえてfillfactorを100にしているので、どのテーブルもHOT更新がされにくく、肥大化しやすいはず。
bench=# \d+ pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Modifiers | Storage | Stats target | Description
----------+---------------+-----------+----------+--------------+-------------
aid | integer | not null | plain | |
bid | integer | | plain | |
abalance | integer | | plain | |
filler | character(84) | | extended | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Options: fillfactor=100
scale factorを10にして動かしているので、pgbench_branchesの初期件数は10件。リレーションサイズは8192バイト(1ページ)。pgbench_tellersの初期件数は100件、リレーションサイズは2ページ。
この状態でpg_squeezeを無効化/有効化して10万トランザクション実行してみる。
[nuko@localhost ~]$ pgbench -U postgres bench -c 4 -t 25000
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 4
number of threads: 1
number of transactions per client: 25000
number of transactions actually processed: 100000/100000
latency average = 3.371 ms
tps = 1186.728938 (including connections establishing)
tps = 1186.921844 (excluding connections establishing)
[nuko@localhost ~]$
pgbench実行前/実行後のリレーションサイズ
10万回pgbenchのデフォルトトランザクション実行後のテーブルサイズをpg_relation_size()の値で比較してみた(サイズはbyte)。
| 設定 | 初期サイズ | pg_squeezeなし | pg_squeezeあり |
|---|---|---|---|
| pgbench_tellers | 16384 | 204800 | 49152 |
| pgbench_branches | 8192 | 65536 | 16384 |
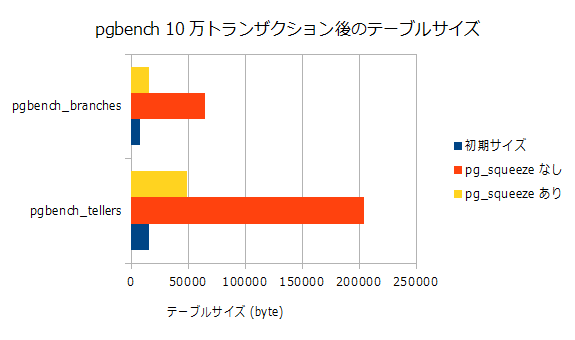
お、どちらのテーブルも25%程度のサイズに縮小されてますね。
おわりに
まだβバージョンなので、使い倒すといろいろトラブルもあるかもしれないが(例えば、再度CREATE EXTENSIONするときにバックエンド異常が起きたりもした)、テーブルが肥大化しがちな案件であれば、試しに使ってみるのもありかな、という印象はもった。
あとは、再編成中にどのくらい性能に影響がでるか、どこかで測定しておきたいもの。