はじめに

にゃーん
趣味でポスグレをやってる者だ
この記事はPostgreSQL Advent Calendar 2020 18日目の記事です。
昨日の記事は @elhalti さんの「GCP Cloud SQL for PostgreSQL v13 をお触りしてみた」でした。
今年もPostgreSQL Advent Calendar 2020には、いろいろ為になる情報が集まってきました。素晴らしいことですね。
でも自分は、今年もQoN(Quality of Noodle)向上のためにPostgreSQLを使っている話を書きます。こんなネタでごめんね。


スパとラーメンと私
実は最近、ラーメンを食べるもだいぶ控えるようになって1、基本的には週末にお出かけしてラーメンを食べるだけになっている。
週末にラーメンを食べに行った後は、スパ銭に行ってまったり、というパターンが多いけど、



そうなると
- この店で食べたあと、一番近くのスパ銭ってどこになるっけ?
- 今日はこのスパ銭に行きたいんだけど、近くにラーメン店ってあったっけ?
ということを考え始めるわけですよ。
もちろん、今の時代、それくらいのナビゲーションはスマホからGoogle等を使えばできるんだけど、せっかくPostgreSQLを普段から使っているんだから、こういうこともPostgreSQLでやっておきたい。
このためには、地理情報を使った検索が必要になる。で、PostgreSQLで地理情報のサポートする拡張機能として、みんな知ってるPostGISがある。
自分もPostGISって名前はもちろん聞いたことあるけど、きちんと使ったことない。この機会にPostGISも使ってみようと思い立った。
ラーメンが絡むと自分のモチベーションはめっさ上がるw
環境
- AWS EC2 t2.medium
- PostgreSQL-devel (with IVM patch)
- PostGIS 3.0.3 (ソースビルド)
IVM(Incremental View Maintecance)については、12/16の @yugo-n さんの記事「PostgreSQLのマテリアライズドビューの自動&高速リフレッシュ機能を開発中」を見ていただければと。
テーブル構成
PostgreSQL Advent Calender 2019の記事(麺とポスグレと私 2019)を書いたときに、俺々ラーメンデータベースのテーブル構成を載せたけど、2020年版は、あれをベースにしてPostGIS対応のテーブルとマテリアライズド・ビューを追加することにした。
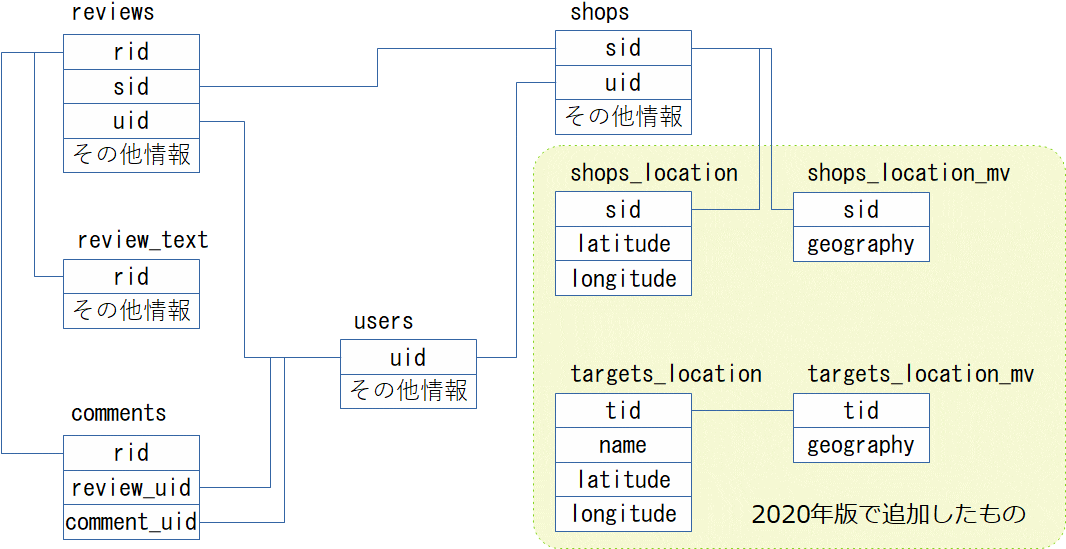
- 店舗の位置情報テーブル(shops_location)
- ターゲット(スパや自宅)の位置情報テーブル(target_location)
- 店舗のgeographyマテリアライズド・ビュー(shops_location_mv)
- ターゲットのgeographyマテリアライズド・ビュー(target_location_mv)
店舗と店舗の位置情報テーブル
店舗(shops)と店舗の位置情報(shops_location)って、同じテーブルで管理しないの?という疑問を持つ人もいると思います。
今回、店舗(shops)と店舗の位置情報テーブル(shops_location)を分けた理由は以下の2点。
- 既に約11万件の店舗情報を収集しているので、位置情報列を追加して再収集したくなかった(店舗情報を再収集すると6時間くらいかかる)。
- shopsはPostgreSQLの基本機能だけで利用可能だけど、位置情報はPostGISに依存したオプション機能になるので、テーブルとしても分割しておきたかった。
位置情報により検索後に、店舗情報を表示するためにはshopsとの結合が必要になりますが、sid(Primary key)で結合するだけなので、大したコストにはならないはず。
shops_locationとshops_locatoin_mv
shops_locatoinには、店舗ID(sid)と店舗の緯度(latitude)と経度(longitude)を持つ。この情報はスクレイピングして収集する。登録店舗は11万件以上あるので、自動収集できないとさすがにやってられない。
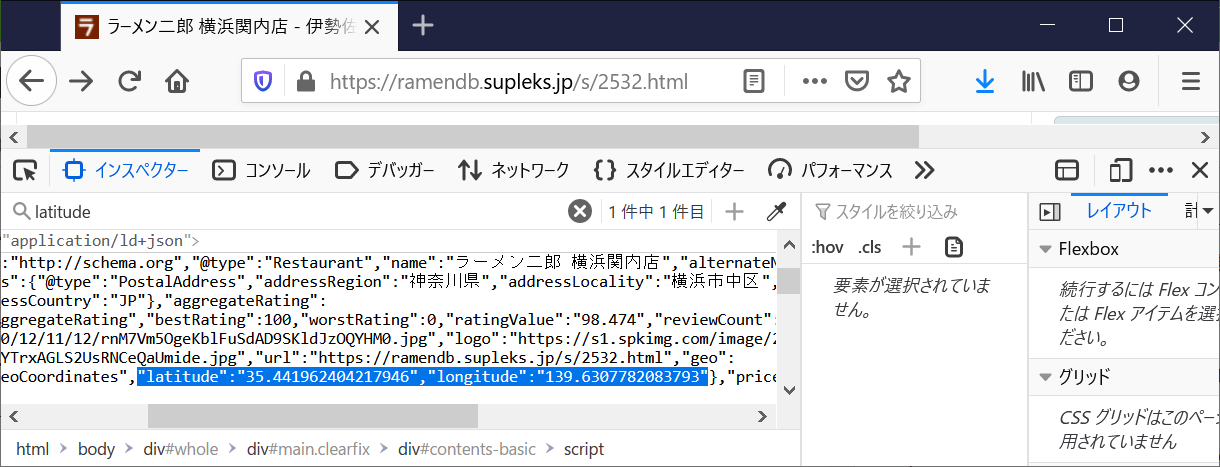
文字反転して示している箇所がlatitude, logitudeになる。幸い、この情報はJSON形式になっているので収集は楽だった。
ただ、これで収集したlatitudeやlongitudeの情報というのは、real型の情報なので、このままだと、PostGISの機能を使うことはできない。
なので、これをgeography型に変換する必要がある。PostgreSQLのCOPYコマンドではファイル読み込み時にSQL関数の適用はできないので、一旦、shop_locatonテーブルに格納したあとで、マテリアライズド・ビューをリフレッシュするときにgeography型への変換もやってしまう。
ramendb=# \d+ shops_location_mv
Materialized view "public.shops_location_mv"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+-----------+-----------+----------+---------+---------+--------------+-------------
sid | integer | | | | plain | |
geography | geography | | | | main | |
View definition:
SELECT shops_location.sid,
(((('POINT('::text || shops_location.longitude) || ' '::text) || shops_location.latitude) || ')'::text)::geography AS geography
FROM shops_location;
Access method: heap
ramendb=#
geography型にするためには、POINT関数に経度 緯度の形式で位置情報文字列を与える必要がある。
POINT関数だけを実行するとこんな感じのgeographyデータが生成される。
ramendb=# SELECT (((('POINT('::text ||
139.6307782083793) ||
' '::text) ||
35.441962404217946) || ')'::text)::geography;
geography
----------------------------------------------------
0101000020E61000009800C8552F746140BC165C3992B84140
(1 row)
ramendb=#
なんか謎の16進文字列が表示される。
これがgeography型の(文字列化された)データとなる。PostGIS関数へ、このgeography型を与えると距離を算出したりしてくれるのだ。
ターゲットの位置情報
ターゲットの位置情報(target_location)には施設名と、その施設の緯度経度のみを持つ。今回、target_locatoinに格納するのは神奈川県内のスパ銭50件ほどを格納する。
ターゲットの位置情報と(target_locatoin)と店舗の位置情報(shop_locatoin)を分けたのは単純に、shop_locationはスクレイピングスクリプトで取得したデータを格納するもの、target_locationは手動で編集するものにしたから。
今回、target_locatoinに格納するのは神奈川県内のスパ銭50件程度なので、そのくらいなら手動編集でもいいかなと。2
target_locationには、ターゲットのID(tid)、施設名、緯度、経度の情報を格納します。これをshop_locatoin_mvと同じようにマテリアライズド・ビュー化したtarget_locatoin_mvを作成してgeography型を管理する。3
PostGISを用いた検索
やっとデータの準備ができたので、検索してみる。
スパ銭の近くの家系ラーメン店
まず、施設(スパ銭)の近く(2Km以内)にある家系ラーメン店を探してみる。ターゲットとする施設は自分も良く通っている横浜市南区・弘明寺の「みうら湯」さんにしてみよう。
ramendb=# WITH tl AS
(
SELECT tl.tid, tl.name, tlmv.geography
FROM target_location_mv tlmv JOIN target_location tl ON (tlmv.tid = tl.tid)
),
s AS (
SELECT s.sid, s.name, s.branch, s.area
FROM shops s
WHERE s.status = 'open' AND
category @> '{"ramendb":true}' AND tags @> '{家系}'
),
near_shop_sid AS (
SELECT
sid,
ST_Distance((
SELECT tl.geography
FROM tl JOIN target_location ON (tl.tid = target_location.tid), shops_location_mv
WHERE target_location.name = 'みうら湯' LIMIT 1
), sl.geography) as dist
FROM shops_location_mv sl
)
SELECT s.sid, s.name, s.branch, ROUND(nss.dist) dist
FROM near_shop_sid nss JOIN s ON (nss.sid = s.sid)
WHERE dist <= 2000 ORDER BY dist LIMIT 10
;
sid | name | branch | dist
--------+---------------------+----------+------
51192 | 琉二家 | | 481
11076 | 壱八家 | 弘明寺店 | 522
118925 | ラーメン 小村 | | 824
79054 | 田上家 | | 908
78250 | 横浜家系 ぱるぷん亭 | | 994
97195 | 壱六家 | 上大岡店 | 1251
127457 | 北里家 | | 1425
6121 | 長浜家 | | 1634
75549 | 新岡商店 | | 1918
(9 rows)
ramendb=#
うん、たぶん妥当な結果がでている。

スパ銭の近くでサンマーメンを提供している店
同じように、みうら湯の近くでサンマーメンを提供しているお店を探してみる。
ramendb=# WITH tl AS
(
SELECT tl.tid, tl.name, tlmv.geography
FROM target_location_mv tlmv JOIN target_location tl ON (tlmv.tid = tl.tid)
),
s AS (
SELECT DISTINCT s.sid, s.name, s.branch, s.area
FROM shops s JOIN reviews r ON (s.sid = r.sid)
WHERE s.status = 'open' AND
r.menu ~ '.*(サンマー|さんまー|生馬|生碼).*(めん|メン|麺).*'
),
near_shop_sid AS (
SELECT
sid,
ST_Distance((
SELECT tl.geography
FROM tl JOIN target_location ON (tl.tid = target_location.tid), shops_location_mv
WHERE target_location.name = 'みうら湯' LIMIT 1
), sl.geography) as dist
FROM shops_location_mv sl
)
SELECT s.sid, s.name, s.branch, ROUND(nss.dist) dist
FROM near_shop_sid nss JOIN s ON (nss.sid = s.sid)
WHERE dist <= 2000 ORDER BY dist LIMIT 10
;
sid | name | branch | dist
-------+-----------------------+--------------+------
29489 | 中華料理 天華 | | 429
30110 | 精龍軒 | | 440
65557 | 廣州亭 | | 482
33154 | 中華料理 まさき亭 | | 602
19371 | 光陽軒 | | 957
56032 | 王家菜館 | 上大岡店 | 1106
7396 | 佐野金 | 総本店 | 1113
62511 | 餃子の王将 | 上大岡京急店 | 1160
69321 | 中華 香蘭 | | 1211
94462 | 中華ダイニング たくみ | | 1232
(10 rows)
ramendb=#
こっちの結果も妥当そう。やったね。
ラーメン店近くにあるスパ銭
今度は逆に、食べに行こうと思っているラーメン店近くにあるスパ銭を探してみよう。
店のターゲットを蒔田にある「太田樓」(カキソバが美味しいのだ)にして、その店から10Km以内にあるスパ銭を探してみる。
ramendb=# WITH t AS
(
SELECT
tl.tid, tl.name,
round(ST_Distance((
SELECT geography
FROM shops_location_mv
WHERE sid IN (
SELECT sid
FROM shops
WHERE name = '太田樓' LIMIT 1
)), tlmv.geography)::real) as dist
FROM target_location_mv tlmv JOIN target_location tl ON (tlmv.tid = tl.tid)
)
SELECT * FROM t WHERE dist <= 10000 ORDER BY dist ASC LIMIT 10;
tid | name | dist
-----+----------------------------+------
2 | みうら湯 | 1649
1 | ぬこ宅 | 2532
8 | 横浜みなとみらい万葉倶楽部 | 3788
16 | スカイスパ | 3968
17 | スパ・イアス | 4047
15 | 極楽湯 芹が谷店 | 4472
9 | 満天の湯 | 5056
18 | 反町浴場 | 5078
5 | おふろの王様 港南台店 | 5729
19 | 鷺の湯 | 7046
(10 rows)
ramendb=#
あ、自宅(ぬこ宅)も引っかかってしまったw
検索結果を見ると、みなとみらい(横浜みなとみらい万葉倶楽部)や、横浜駅周辺(スカイスパ、スパ・イアス)が上位に上がるけど、現実には蒔田から行きやすいのは、「みうら湯(弘明寺)」、「おふろの王様 港南台店(日野)」、「極楽湯 芹が谷店(東戸塚)」なんだよなー。まあ、直線距離で見ちゃうとこうなってしまうのは致し方ない。
おまけ(巡回神奈川ジロリアン問題)
 さて、PostGISの機能を使うと、神奈川県内のラーメン二郎の店舗間の距離も、こんな感じで一撃で算出できて便利である。
さて、PostGISの機能を使うと、神奈川県内のラーメン二郎の店舗間の距離も、こんな感じで一撃で算出できて便利である。
神奈川県の二郎スタンプラリーのときに役に立つかもしれぬ。。
#やらんけど
ramendb=# WITH t AS (
SELECT s.branch, slm.geography
FROM shops s JOIN shops_location_mv slm ON (s.sid = slm.sid)
WHERE pref='神奈川県' AND name='ラーメン二郎' AND status = 'open'
)
SELECT
t1.branch src,
t2.branch dest,
round(ST_distance(t1.geography, t2.geography)) dist
FROM t t1 JOIN t t2 ON (true)
\crosstabview src dest dist
src | 相模大野店 | 横浜関内店 | 京急川崎店 | 湘南藤沢店 | 中山駅前店
------------+------------+------------+------------+------------+------------
相模大野店 | 0 | 20434 | 24698 | 21211 | 9769
横浜関内店 | 20434 | 0 | 12331 | 17393 | 11496
京急川崎店 | 24698 | 12331 | 0 | 29378 | 15300
湘南藤沢店 | 21211 | 17393 | 29378 | 0 | 19546
中山駅前店 | 9769 | 11496 | 15300 | 19546 | 0
(5 rows)
ramendb=#
で、このデータを元に、巡回神奈川ジロリアン問題を、横浜関内店を始点/終点にして、頭の悪いSQLで書くとこんな感じになる。
ramendb=# WITH t AS (
SELECT s.sid, s.branch, slm.geography
FROM shops s JOIN shops_location_mv slm ON (s.sid = slm.sid)
WHERE pref='神奈川県' AND name='ラーメン二郎' AND status = 'open'
)
SELECT
(
t1.branch || '->' ||
t2.branch || '->' ||
t3.branch || '->' ||
t4.branch || '->' ||
t5.branch || '->' ||
t6.branch
) path,
round(
ST_distance(t1.geography, t2.geography) +
ST_distance(t2.geography, t3.geography) +
ST_distance(t3.geography, t4.geography) +
ST_distance(t4.geography, t5.geography) +
ST_distance(t5.geography, t6.geography)
) total
FROM t t1, t t2, t t3, t t4, t t5, t t6
WHERE
t1.branch = '横浜関内店' AND
(t2.sid <> t1.sid) AND
(t3.sid <> t1.sid AND t3.sid <> t2.sid) AND
(t4.sid <> t1.sid AND t4.sid <> t2.sid AND t4.sid <> t3.sid) AND
(t5.sid <> t1.sid AND t5.sid <> t2.sid AND t5.sid <> t3.sid AND t5.sid <> t4.sid) AND
t6.branch = '横浜関内店'
ORDER BY total ASC LIMIT 1;
path | total
------------------------------------------------------------------------+-------
横浜関内店->湘南藤沢店->相模大野店->中山駅前店->京急川崎店->横浜関内店 | 76004
(1 row)
ramendb=#
横浜関内店を始点に時計回りで、神奈川県内の二郎を巡回するイメージだ(逆ルートでもいいけど)。
距離は76Km。自転車で回るといい腹ごなしになるかも。
この例だと5ノードしかないから、こんなベタなクエリ書いてもなんとかなるけど、
とかになると、もうSQLでは無理そうな気がする・・・。
量子コンピュータとかいうやつでなんとかしてー!

おわりに
PostgreSQLは基本機能だけでもパワフルなんですが、これに拡張機能を追加することで更に色々な使い方ができます。こういう拡張性の高さもPostgreSQLの良いところですね。
明日は @U_ikki さんの記事です。今年は何を書いてくれるかなー。
きっと自分の期待を裏切らない凄いなんかを書いてくれるに違いない。