はじめに

にゃーん。趣味でポスグレをやっている者だ。
この記事はPostgreSQL アドベントカレンダー 2023の16日目の記事です。
昨日のアドベントカレンダーはjun2さんのpostgresqlに変えてから困ったことという記事でした。
今日のお題はPostgreSQLのbloomインデックスの話です。
PostgreSQLで使用可能なインデックス
PostgreSQLは様々な種類のインデックスが使えるのも特徴の一つです。
| インデックス種別 | 説明 |
|---|---|
| B-tree | 木構造の汎用インデックス。 PostgreSQLではこのインデックスがデフォルト。 |
| Hash | ハッシュコードによる単純な等比較用のインデックス。 PostgreSQL 10のときに少し調べたことがある。 →PostgreSQL 10がやってくる!(その6) 改めてハッシュインデックスを見直してみる |
| GiST, SP-GiST | 様々なインデックス作成用の基盤。 |
| GIN | 転置インデックス。 配列、JSON、全文検索等で使用する。 |
| BRIN | Block Range INdex。 2023-11-24のPostgreSQLカンファレンスでこのインデックスについて小講演しました。 → せっかくなのでBRINを使ってみよう! |
| bloom | 本記事で扱うインデックス。 本体機能ではなく拡張機能として提供されている。 |
それに加えて拡張機能としてインデックスメソッドを追加することができます。
本記事で紹介するbloomインデックスも拡張機能として実装され、PostgreSQLのcontribモジュールとして公開されています。
bloomインデックスの基本
概要
bloomインデックスは、その名前のとおり、ブルームフィルタを用いて、条件を満たさないタプルを高速に除外する(=条件を満たす「かもしれない」タプルを残す)ことが可能なインデックスメソッドです。
使用例
インストール
bloomインデックスを使うためには、まず拡張機能をサーバにインストールする必要があります。
postgresql11-contrib-xx.x-xPGDG.*.rpmのようなRPMをインストールする、あるいはソースからビルドして使う場合には、contrib/bloom ディレクトリ配下をmake && make installします。
データベースへの登録
使用したいデータベースにCREATE EXTENSIONコマンドを使ってbloomを登録します。
$ psql bloom -c "CREATE EXTENSION bloom"
Null display is "(null)".
CREATE EXTENSION
$ psql bloom -c "\dx bloom"
Null display is "(null)".
List of installed extensions
Name | Version | Schema | Description
-------+---------+--------+--------------------------------------------------
bloom | 1.0 | public | bloom access method - signature file based index
(1 row)
$
インデックス作成
bloomインデックスを作成する場合には、USING句にbloomを付与した、CREATE INDEXコマンドを実行します。
postgres@bloom=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | |
c2 | integer | | |
c3 | integer | | |
postgres@bloom=# CREATE INDEX c2_idx ON test USING bloom (c2);
CREATE INDEX
postgres@bloom=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | |
c2 | integer | | |
c3 | integer | | |
Indexes:
"c2_idx" bloom (c2)
postgres@bloom=#
bloomインデックス作成時に、ストレージオプションを設定することもできます。
オプションについては後で説明します。
利用可能なデータ型と演算子
bloomが利用可能なデータ型は、psqlの\dApメタコマンドで確認できます。
postgres@bloom=# \dAp bloom
List of support functions of operator families
AM | Operator family | Registered left type | Registered right type | Number | Function
-------+-----------------+----------------------+-----------------------+--------+----------
bloom | int4_ops | integer | integer | 1 | hashint4
bloom | text_ops | text | text | 1 | hashtext
(2 rows)
現状のbloomでは、int4型およびtext型のみ対応しています。
暗黙的なキャストがされそうな、int2(smallint)やint8(bigint)もbloomには使えません。
postgres@bloom=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+----------+-----------+----------+---------
i2 | smallint | | |
i4 | integer | | |
i8 | bigint | | |
Indexes:
"i4_idx" bloom (i4)
postgres@bloom=# CREATE TABLE test (i2 int2, i4 int4, i8 int8);
CREATE TABLE
postgres@bloom=# CREATE INDEX i4_idx ON test USING bloom (i4);
CREATE INDEX
postgres@bloom=# CREATE INDEX i2_idx ON test USING bloom (i2);
ERROR: data type smallint has no default operator class for access method "bloom"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
postgres@bloom=# CREATE INDEX i8_idx ON test USING bloom (i8);
ERROR: data type bigint has no default operator class for access method "bloom"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
postgres@bloom=#
どうしてもint2やint8でbloomを使いたい場合には、式インデックスとしてint4への明示的な型変換を指定します。
postgres@bloom=# CREATE INDEX i8_idx ON test USING bloom ((i8::int4));
CREATE INDEX
postgres@bloom=# CREATE INDEX i2_idx ON test USING bloom ((i2::int4));
CREATE INDEX
postgres@bloom=#
検索時の挙動
bloomインデックスを使った検索時の実行計画を見てみます。
例えば、以下のようなint4型カラムが3つ入ったテーブルがあります。
postgres@bloom=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | |
c2 | integer | | |
c3 | integer | | |
postgres@bloom=# TABLE test ORDER BY c1 LIMIT 5;
c1 | c2 | c3
----+------+---------
1 | 8512 | 1595475
2 | 4018 | 9532723
3 | 9923 | 1213529
4 | 6633 | 4181087
5 | 9927 | 87435
(5 rows)
このc2列にbloomインデックスを設定します。
postgres@bloom=# CREATE INDEX c2_idx ON test USING bloom (c2);
CREATE INDEX
postgres@bloom=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | |
c2 | integer | | |
c3 | integer | | |
Indexes:
"c2_idx" bloom (c2)
c2列を条件に設定したクエリを実行し、その実行計画を確認します。
postgres@bloom=# EXPLAIN SELECT * FROM test WHERE c2 = 5432;
QUERY PLAN
-------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=1542.00..1578.05 rows=10 width=12)
Recheck Cond: (c2 = 5432)
-> Bitmap Index Scan on c2_idx (cost=0.00..1542.00 rows=10 width=0)
Index Cond: (c2 = 5432)
(4 rows)
まず、bloomインデックスc2_idxによる検索が行われ、その後にRecheck処理が行われます。
bloomインデックスでは「確実に検索条件ではない行を排除する」までしか行わないため、その時点では「偽陽性」の結果も含んでいます。そのため、必ずRechek処理によって、bloomによってスキャンされたブロック内をRecheckして最終的な結果を抽出します。
EXPLAIN ANALYZEオプションをつけてもう少し詳細に見てみます。
postgres@bloom=# EXPLAIN ANALYZE SELECT * FROM test WHERE c2 = 5432;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=1542.00..1578.05 rows=10 width=12) (actual time=0.570..0.644 rows=10 loops=1)
Recheck Cond: (c2 = 5432)
Rows Removed by Index Recheck: 50
Heap Blocks: exact=59
-> Bitmap Index Scan on c2_idx (cost=0.00..1542.00 rows=10 width=0) (actual time=0.551..0.552 rows=60 loops=1)
Index Cond: (c2 = 5432)
Planning Time: 0.084 ms
Execution Time: 0.675 ms
(8 rows)
このクエリでは、まず、設定したc2_idxインデックスを用いてBitmap Index Scanを行い59ブロックを読み込みます。
更にRecheckをかけて実際に条件値にあうタプルを抽出して最終的に10件の結果を返却します。
同じデータに対してbloomインデックスを使わずにフルスキャンした場合と比較します。
postgres@bloom=# SET enable_bitmapscan = on;
SETpostgres@bloom=# EXPLAIN ANALYZE SELECT * FROM test WHERE c2 = 5432;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Seq Scan on test (cost=0.00..1791.00 rows=10 width=12) (actual time=0.041..6.011 rows=10 loops=1)
Filter: (c2 = 5432)
Rows Removed by Filter: 99990
Planning Time: 0.081 ms
Execution Time: 6.038 ms
(5 rows)
この例では6msかかる検索がbloomを使うことで1/10程度の処理時間になります。
対応する演算子
bloomで対応している演算子は等比較(=)のみです。他の比較演算子(<>, <, >, <=, >=, IN述語等)を指定した場合にはbloomインデックスは動作しません。
また、インデックスを設定した列に対する条件をORで接続した場合もbloomインデックスは動作しないようです・・・。
postgres@bloom=# EXPLAIN SELECT * FROM test WHERE c2 IN (0, 1);
QUERY PLAN
---------------------------------------------------------
Seq Scan on test (cost=0.00..1791.00 rows=20 width=12)
Filter: (c2 = ANY ('{0,1}'::integer[]))
(2 rows)
postgres@bloom=# EXPLAIN SELECT * FROM test WHERE c2 = 0 OR c2 = 1;
QUERY PLAN
---------------------------------------------------------
Seq Scan on test (cost=0.00..2041.00 rows=20 width=12)
Filter: ((c2 = 0) OR (c2 = 1))
(2 rows)
postgres@bloom=#
公式の日本語文書(PostgreSQL 15.4文書)を見ると
bloomアクセスメソッドはUNIQUEをサポートしていません。
bloomアクセスメソッドはNULL値の検索をサポートしていません。
といった制約もあります。なかなか制約が多いインデックスという感じですね。
bloomインデックスの使い所
さて、ここまでbloomインデックスの大まかな内容を紹介しましたが、これだけ見るとbloomインデックスを使うメリットって何?使いどころって何処?という疑問がでてくると思います。
ここからは他のインデックス種別と比較しながら使い所を探ってみます。
B-tree/Hashとの比較
PostgreSQLの標準的なインデックスとしてB-treeインデックスがあります。また、等比較のみ対応しているインデックスとしてHashインデックスがあります。
インデックスサイズや検索性能等を比較してbloomの良いとこ探しをしてみましょう。
まず単一の列(int4型、ある程度長いtext型)へのインデックスを設定して比較します。
サンプルデータ
int4型の列i4とtext型の列tを用意します。
i4にはrandom()で生成した乱数値を、tにはgen_random_uuid()で生成したUUIDを設定した行を100万件挿入します。
postgres@bloom=# CREATE TABLE test (id int4 primary key, i4 int4, t text);
CREATE TABLE
postgres@bloom=# INSERT INTO test VALUES (generate_series(1, 1000000), (random() * 10000000)::int, gen_random_uuid()::text);
INSERT 0 1000000
postgres@bloom=# TABLE test LIMIT 3;
id | i4 | t
----+---------+--------------------------------------
1 | 6140504 | 866c3c17-26ab-429c-aa87-29ed818b7c41
2 | 1239718 | 28c0ffaa-b3a7-4885-91cf-dbe926d5ffab
3 | 8522502 | 48cc7a7a-123b-4ff0-92ef-63f6b268ab34
(3 rows)
インデックスサイズと作成時間
i4列とt列に対してそれぞれB-Treeインデックス、Hashインデックス、bloomインデックスを作成し、そのインデックスサイズ(と参考情報としてインデックス作成時間)を見てみます。
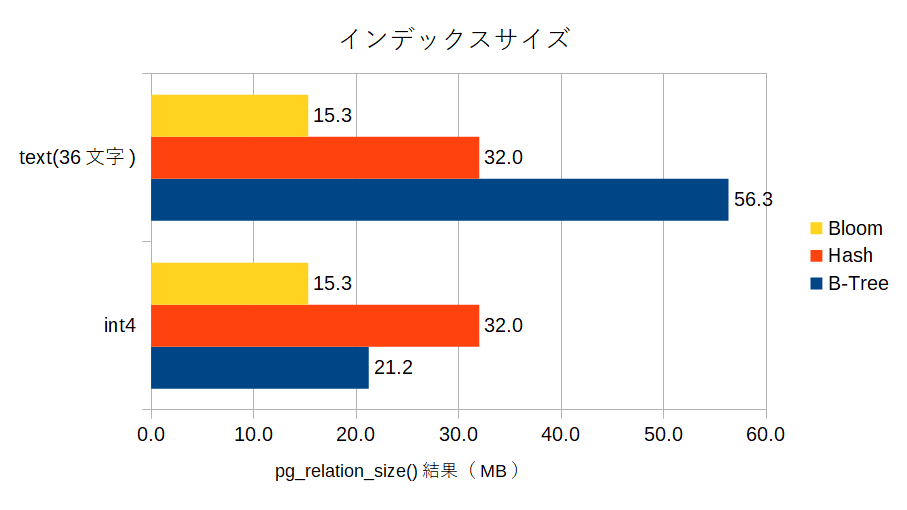
B-Treeインデックスの場合、データ型(データ長)によりインデックスサイズは変動しますが、Hashもbloomもインデックス対象列のデータ型によらずサイズが同一になっています。
Hashインデックスについてはハッシュ値の計算結果がインデックスになるので型によらず一定のサイズになるのは以前から調査済みでしたが、bloomインデックスもデータ型には依存しないのか・・・。
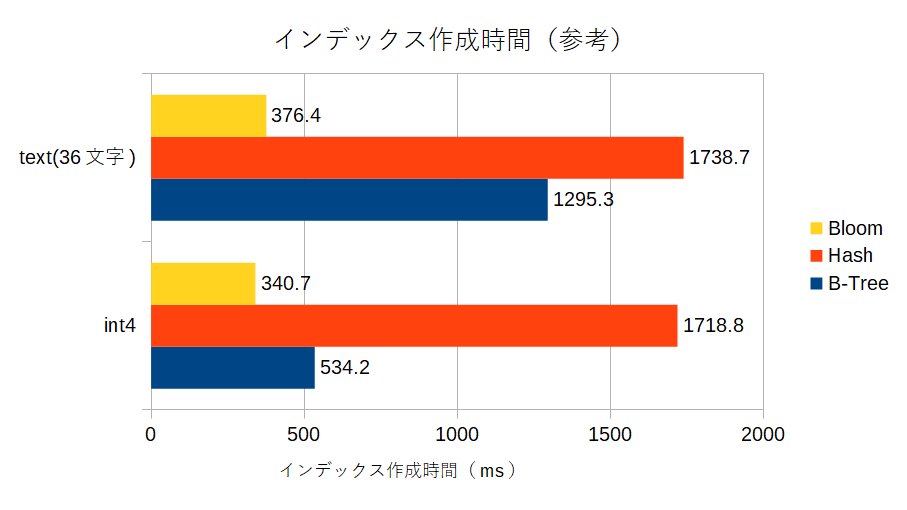
bloomインデックスの作成時間が一番短いという結果になりました。
(本題ではないけど、Hashインデックスって結構生成時間かかるんだな・・・)
検索時間とcost
次にインデックスを作成したそれぞれの列に対して、=条件のクエリをEXPLAIN ANALYZEで実行して、そのときのcost値と、Execution Timeを見てみます。
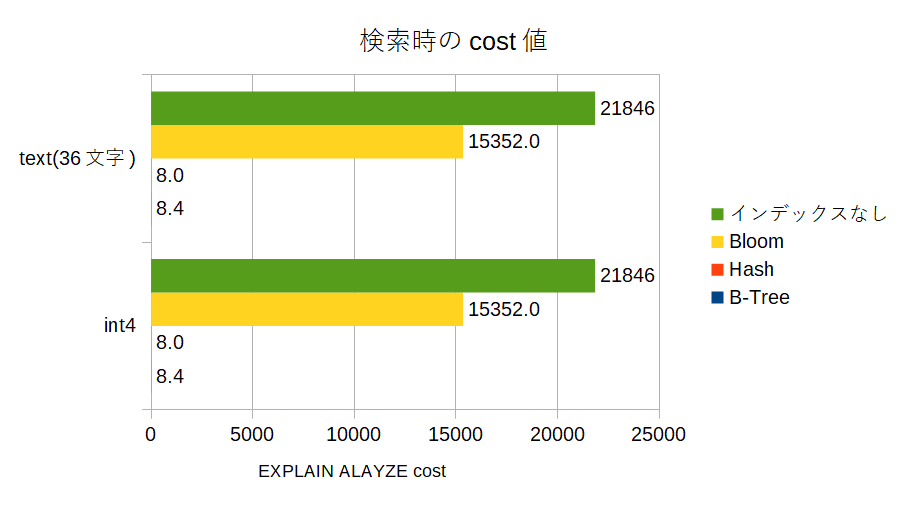
意外にbloomインデックスによる検索時のcostが高い・・・。
それは検索時間にも現れていて
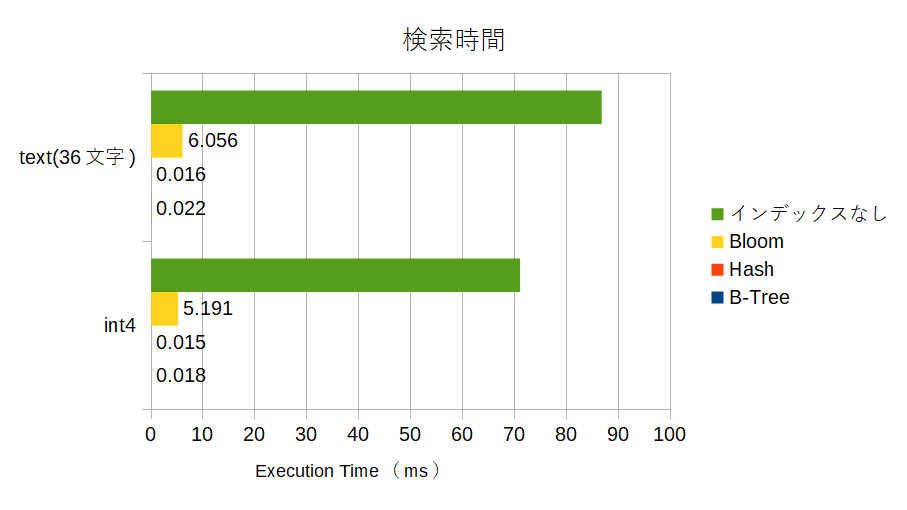
インデックスがないフルスキャンよりはbloomインデックスによる検索のほうが高速ではあるけど、B-TreeインデックスやHashインデックスと比べると、結構処理時間がかかっっています。
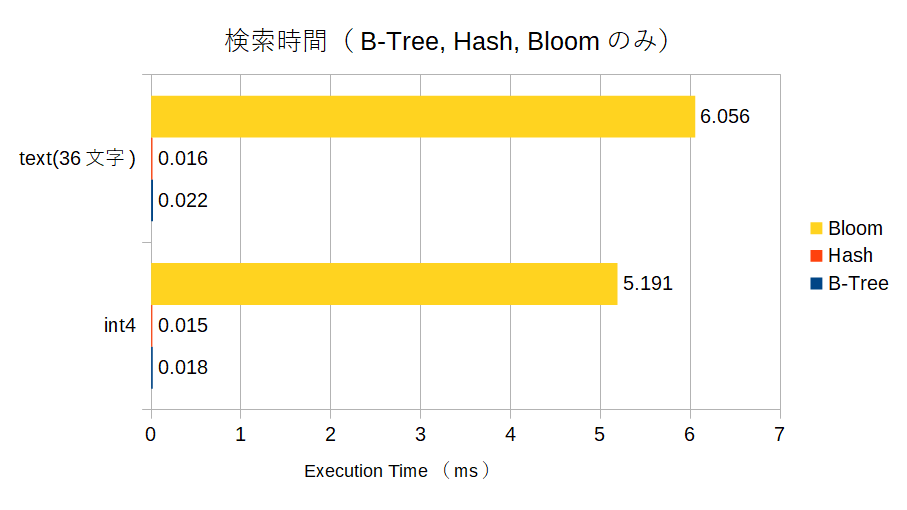
bloomインデックスもBRINと同様に「程々に速い検索ができるインデックス」という感じですね。
複数列に対するインデックス
ここまでは単一の列に対してインデックスを設定する例を示しましたが、bloomインデックスの本領は、複数列に対するインデックス設定をするときに発揮されます。
例えば、以下のようなテーブル定義のテーブルに100万件のデータが格納されているとケースを考えます。
postgres@bloom=# \d multi
Table "public.multi"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
i1 | integer | | |
i2 | integer | | |
i3 | integer | | |
i4 | integer | | |
i5 | integer | | |
Indexes:
"multi_pkey" PRIMARY KEY, btree (id)
SELECT * FROM multi WHERE id = 500000;
id | i1 | i2 | i3 | i4 | i5
--------+-----+------+------+-------+--------
500000 | 884 | 9552 | 1448 | 15725 | 910310
(1 row)
このテーブルにはid列の他に、i1~i5の列があります。
| 列名 | 値域 |
|---|---|
| i1 | 0~1000 |
| i2, i3 | 0~10000 |
| i4 | 0~100000 |
| i5 | 0~1000000 |
そして、i1~i5列のどれも検索条件として使われる可能性がある、というケースを考えます。
全ての列にインデックスを設定する
こうした時に、全ての列にB-TreeインデックスやHashインデックスを設定すれば、検索時にi1~i5列のどれが使われても、インデックス検索は可能です。
とはいえ、大量のインデックスを設定すると、このテーブルに対する更新が合った場合のインデックス更新のコストも高くなるし、インデックス全体のサイズも大きくなってしまいます。
i1~i5の各列にB-Tree, Hash, bloomの各インデックスを設定した場合のインデックスサイズは以下のようになります。
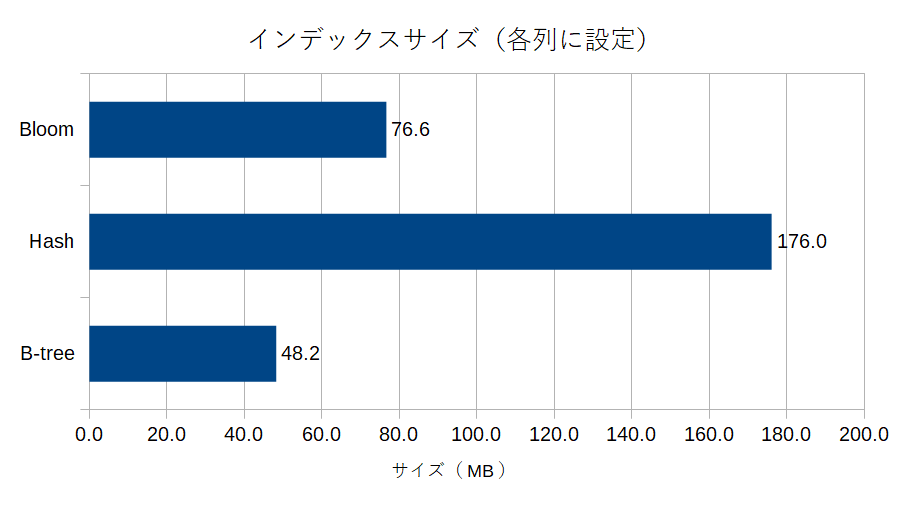
あらら、B-TreeよりもBloomのほうがトータルサイズ多くなっている・・・
複数列インデックス
インデックスは単一の列だけでなく、複数の列を指定して作成することができます。これを「複数列インデックス」と呼びます。複数列インデックスはB-Treeやbloomでは対応していますが、Hashは対応していません。
さっきの例のi1~i5に複数列インデックスを設定してみます。
B-Treeの場合
CREATE INDEX m_i1_5 ON multi USING btree(i1, i2, i3, i4, i5);
bloomの場合
CREATE INDEX m_i1_5 ON multi USING bloom (i1, i2, i3, i4, i5);
作成された複数列インデックスのサイズを比較します。
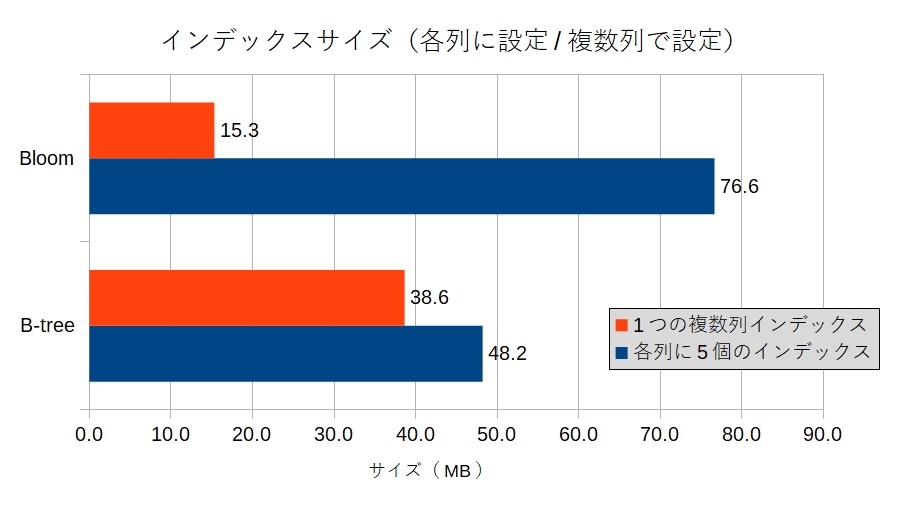
なかなか面白い結果になっています。
- bloomの場合、5つのインデックスを1つの複数列インデックスにまとめることで、トータルのサイズが約1/5になる。
- B-Treeの場合、5つのインデックスを1つの複数列インデックスにまとめても、トータルのサイズはほとんど変わらない。これはインデックス情報の大半をキー値の実体が占めているからだと思われる。
B-Tree複数列インデックスの問題点
さらに、B-Tree複数列インデックスには、以下のような問題があります。
- 定義時に指定した列の後ろ側の一部だけ条件値として使用された場合には、インデックス検索にならない。
i1~i5の列をまとめた複合列B-Trreインデックスの定義例
postgres@bloom=# \d m_i1_5
Index "public.m_i1_5"
Column | Type | Key? | Definition
--------+---------+------+------------
i1 | integer | yes | i1
i2 | integer | yes | i2
i3 | integer | yes | i3
i4 | integer | yes | i4
i5 | integer | yes | i5
btree, for table "public.multi"
i1列にを含む条件はインデックススキャンになりますが、
postgres@bloom=# EXPLAIN ANALYZE SELECT * FROM multi WHERE i1 = 10 AND i3 = 30 ;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Index Scan using m_i1_5 on multi (cost=0.42..34.39 rows=1 width=24) (actual time=0.119..0.120 rows=0 loops=1)
Index Cond: ((i1 = 10) AND (i3 = 30))
Planning Time: 0.125 ms
Execution Time: 0.144 ms
(4 rows)
i1列を含まない条件だとインデックスは使われません。
postgres@bloom=# EXPLAIN ANALYZE SELECT * FROM multi WHERE i2 = 10 AND i3 = 30 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------
Seq Scan on multi (cost=0.00..21370.00 rows=1 width=24) (actual time=80.541..80.542 rows=0 loops=1)
Filter: ((i2 = 10) AND (i3 = 30))
Rows Removed by Filter: 1000000
Planning Time: 0.098 ms
Execution Time: 80.568 ms
(5 rows)
どの列が条件値として使用されるかわからない時には、B-Treeの複合列インデックスはあまり意味がありません。
(個々の列にインデックスを設定するほうが良い・・・インデックスサイズも大きくなるし更新時のオーバーヘッドも心配になる)
bloom複合列インデックス
bloom複合列インデックスの場合は、定義した列の順序に関係なくインデックス検索→Birmap Scanになります。
B-Treeインデックスが使われるたケースと比べると検索時間は遅くなりますが、SeqScanほど遅くはないという検索時間になります。
i1~i5の列をまとめた複合列B-Trreインデックスの定義例
postgres@bloom=# \d m_i1_5
Index "public.m_i1_5"
Column | Type | Key? | Definition
--------+---------+------+------------
i1 | integer | yes | i1
i2 | integer | yes | i2
i3 | integer | yes | i3
i4 | integer | yes | i4
i5 | integer | yes | i5
bloom, for table "public.multi"
i1列にを含む条件もインデックススキャン→Bitmap Heap Scan
postgres@bloom=# EXPLAIN ANALYZE SELECT * FROM multi WHERE i1 = 10 AND i3 = 30 ;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on multi (cost=17848.00..17852.02 rows=1 width=24) (actual time=6.345..6.347 rows=0 loops=1)
Recheck Cond: ((i1 = 10) AND (i3 = 30))
Rows Removed by Index Recheck: 95
Heap Blocks: exact=93
-> Bitmap Index Scan on m_i1_5 (cost=0.00..17848.00 rows=1 width=0) (actual time=6.210..6.211 rows=95 loops=1)
Index Cond: ((i1 = 10) AND (i3 = 30))
Planning Time: 0.113 ms
Execution Time: 6.382 ms
(8 rows)
i1列を含まない条件もインデックススキャン→→Bitmap Heap Scan
postgres@bloom=# EXPLAIN ANALYZE SELECT * FROM multi WHERE i1 = 10 AND i3 = 30 ;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on multi (cost=17848.00..17852.02 rows=1 width=24) (actual time=6.345..6.347 rows=0 loops=1)
Recheck Cond: ((i1 = 10) AND (i3 = 30))
Rows Removed by Index Recheck: 95
Heap Blocks: exact=93
-> Bitmap Index Scan on m_i1_5 (cost=0.00..17848.00 rows=1 width=0) (actual time=6.210..6.211 rows=95 loops=1)
Index Cond: ((i1 = 10) AND (i3 = 30))
Planning Time: 0.113 ms
Execution Time: 6.382 ms
(8 rows)
になります。
検索条件列が不定のケースで、ほどほどに高速な検索を1つの複数列インデックスの定義で対応できる、というのがbloomの強みのようですね。
まとめ
- bloomインデックスは検索条件となりうる列が複数(多数)存在するときに、それを1つの複合列インデックスとして定義するだけで「小さなインデックスサイズ」で「ほどほどに高速な」検索ができる。
- 現状の実装では、型および演算子の制約が強いので、実用レベルで使用可能なケースは少ないかも。
まだ実験的な実装という位置づけなのか、コア機能としての提供ではなく、contribモジュールでの提供になっていますが、こういう特殊な用途のインデックスを作れるということが、PostgreSQLの良いところだな、と思います。
また、今回の記事では取り上げませんでしたが、bloomインデックスの長さをチューニングすることで、インデックスサイズと検索時間を調整することもできます。興味のある人は、bloomのチューニングによるインデックスサイズの大きさや検索時間を測定してみるのも面白いかもしれません。
おわりに
明日はdiscus_hamburgさんの記事です。
PostgreSQLアドベントカレンダーも残り9日、お楽しみに!