はじめに
Feature Freezeとなり、5月のbeta版リリースに向けて着々と開発中の、PostgreSQL 10!
今日はちょっとマイナーなネタですが、ハッシュインデックスについて書いてみますよ。
ハッシュインデックスって何よ?
ハッシュインデックスはキー値に対してハッシュ関数を実行して得られた結果の、ハッシュ値によって索引付けをするというものです(大雑把)。
PostgreSQLでは通常のインデックス(B-Treeインデックス)の他にも様々なタイプのインデックスをサポートしてますが、ハッシュインデックスもかなり古くからサポートされています。
サポートはされていましたが・・・
(PostgreSQL 9.6.2文書 11.2. インデックスの種類 から引用)
現在ハッシュインデックス操作はWALに記録されません。 そのため、データベースクラッシュの後、書き込まれていない変更があるなら、ハッシュインデックスをREINDEXで再構築しなければならない可能性があります。 また、最初のバックアップを取得した後は、ストリーミングレプリケーションやファイルベースのレプリケーションでは変更が反映されないため、その後ハッシュインデックスを使う問い合わせは誤った結果を返します。 これらの理由により、ハッシュインデックスの使用は現在お勧めできません。
といった具合に、お勧めできない機能と位置づけられてます。(´・ω・`)
このように、長い間、黒歴史扱いになっていたハッシュインデックスですが、PostgreSQL 10になって、ようやく復権の兆しが見えてきました。
要するにハッシュインデックスがWALに対応するようになったよ、ということでリカバリに対応できたり、レプリケーションに対応できるようになるなど、やっと実運用でも使えそうになってきました。
が、そもそも、今までハッシュインデックス使ったことないから、どんな特性なのかあまり良く分かっていない・・・。なので、今回はB-treeインデックスと色々比較してみたいと思います。
B-tree vs ハッシュ
機能面
インデックスの機能を示す一つの指標としては対応する演算子の種類の多さがあるでしょう。
これは一目瞭然、B-Treeのほうが圧倒的に対応する演算子が多い。
| 演算子 | B-Tree | ハッシュ |
|---|---|---|
| < | ○ | ✗ |
| <= | ○ | ✗ |
| = | ○ | ○ |
| >= | ○ | ✗ |
| > | ○ | ✗ |
ハッシュインデックスの場合、等号による比較しかできず、大小比較や範囲などの比較ができないという特徴があります。
インデックス登録時間
B-Treeインデックスとハッシュインデックスのインデックス作成時間を比較するために、以下のような検証をやってみた。
まず、こんなテーブルを定義する。
CREATE UNLOGGED TABLE test (id int, uuid text, data text);
uuid列には、PostgreSQLのuuid生成関数で値を設定し、data列にはダミーデータとして32文字のランダムな文字列を設定するようなレコードを合計1000万件生成する。
INSERT INTO test VALUES (generate_series(1, 2500000), gen_random_uuid(), repeat(md5(clock_timestamp()::text), 2));
INSERT INTO test VALUES (generate_series(2500001, 5000000), gen_random_uuid(), repeat(md5(clock_timestamp()::text), 2));
INSERT INTO test VALUES (generate_series(5000001, 7500000), gen_random_uuid(), repeat(md5(clock_timestamp()::text), 2));
INSERT INTO test VALUES (generate_series(7500001, 10000000), gen_random_uuid(), repeat(md5(clock_timestamp()::text), 2));
- 一気に1000万件生成しようとすると、うちのVM環境ではメモリ不足で大変なことになるので、250万件ずつ4回に分けてロードした。
- ロード後のtestテーブルのサイズは、約1.32GB。
このテーブルのid列(int), uuid列(text, 36文字)に対して、それぞれB-treeインデックスとハッシュインデックスを作成する時間をざっくり(\timingで)測ってみた。
| 列 | B-Tree(ms) | ハッシュ(ms) |
|---|---|---|
| id列(int) | 5239.871 | 13673.197 |
| uuid列(text, 36文字) | 11634.230 | 13755.488 |
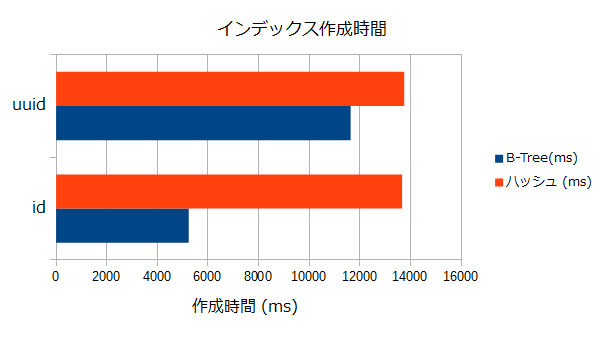
結果から、以下のことが考えられる。
- 全般に、B-Treeインデックスよりハッシュインデックスのほうが生成時間がかかる傾向にある。
- ハッシュ値の計算のコストが結構高いのだろうか?
インデックスサイズ
生成直後のインデックスサイズを確認する。
| 列 | B-Tree(MB) | ハッシュ(MB) |
|---|---|---|
| id列(int) | 214.13 | 256.02 |
| uuid列(text, 36文字) | 563.18 | 256.02 |
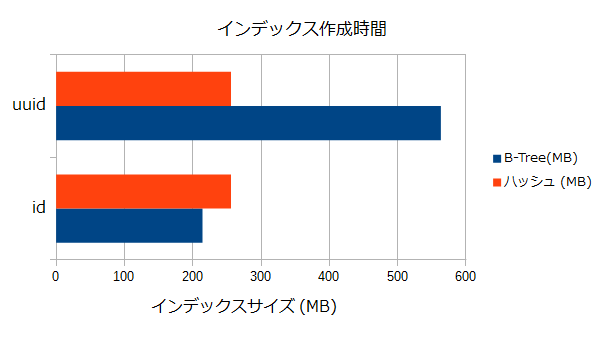
結果から、以下のことが考えられる。
- ハッシュインデックスは対象列のデータ型/データ長に関わらず一定のサイズになる。
- uuidのようにある程度の長いデータを対象とする場合、B-Treeインデックスよりもハッシュインデックスのほうがインデックスサイズは小さくなる。
- 逆にint型のような短いデータを対象とする場合には、ハッシュインデクスは無駄にディスクを使うことになるかも。
= 演算子による検索時間
B-Treeインデックスまたはハッシュインデックスを設定したid列およびuuid列に対して"="比較演算を行ったときの実行計画をEXPLAIN ANALYZEで取得し、それぞれのIndexScan(実際にはBitmap IndexScan)のactual timeを見てみる。
| 列 | B-Tree(ms) | ハッシュ(ms) |
|---|---|---|
| id列(int) | 0.007 | 0.003 |
| uuid列(text, 36文字) | 0.009 | 0.003 |
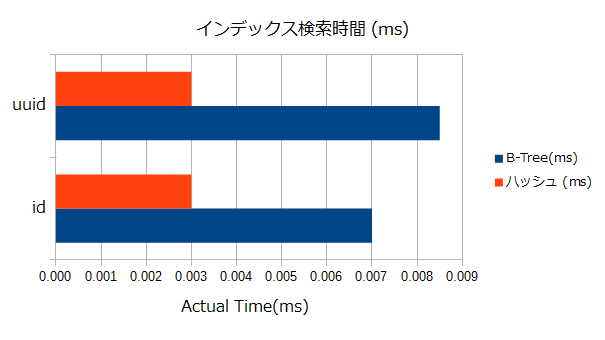
- id列のような短いデータ、uuidのような長いデータのいずれもハッシュインデックス処理のほうが高速であった。
結局、どこで使えばいいのだろう?
まあ、大体の場合、B-Treeで代替できるケースが多いので、なかなかハッシュを使いケースって思いつかないのだけど、全くないわけでもなさそう。
まずは、uuidをキーとして検索させたい場合なんかは良さそうですね。uuidの性質上、比較演算や範囲比較は無意味で、等値比較しかできないので、そういうデータでインデックス検索をかけたい場合には、ハッシュインデックスというのは有効そうな気がします。
手元の環境で測定したときにも、インデックスサイズはB-treeよりは小さくなるし、=比較したときにも僅かではありますが、ハッシュインデックスよりは良い性能になっていると思うし。
他のケースだと、=比較演算しかできないデータタイプで使うくらいかなあ。
例えば、PostgreSQLの暗号化ソリューションとして、NEC社が公開しているtdeforpgが提供している、暗号化データ型(ENCRYPT_TEXT, ENCRYPT_BYTEA)などは、ハッシュインデックスしか対応していない(= 以外の比較演算をサポートしていないから)ので、こういうケースでは、ハッシュを使わざると得ない。
おわりに
とりあえず検証してみて分かったこと。
- ハッシュインデックスはB-Treeインデックスほどの汎用性はないが、使い所によっては、B-Treeインデックスよりもインデックスサイズや、検索性能での優位性がある。
- ただし、インデックス作成時間に関してはB-Treeインデックスよりもハッシュインデックスが長くなるケースが多そう。
- uuidのようなデータを"="比較したい場合には、ハッシュインデックスが有用そう。
ハッシュインデックスもPostgreSQL 10になって、実用的に使えるようになったので、PostgreSQL 10以降のインデックス設計のときには、考慮してもいいかもね、という話でした。おしまい。