こちらの記事は公式チュートリアルを参考にkiroとチャットした会話をまとめた記事になります。
Amazon Bedrock AgentCore とは
Amazon Bedrock AgentCoreはPoCレベルで開発していたエージェントをaws環境に簡単にリリース、管理できるマネージドサービスです。
AgentCore全体アーキテクチャ

6つの核心コンポーネント
| コンポーネント | 本質的な価値 | 解決する課題 |
|---|---|---|
| Runtime | サーバーレスエージェント実行基盤 | コンテナ管理の複雑性排除 |
| Gateway | 外部リソースのエージェント互換化 | API統合の標準化 |
| Memory | エージェントの状態・パーソナライゼーション管理 | 文脈保持とカスタマイズ |
| Identity | マルチサービス横断の統一認証 | アイデンティティ管理の統合 |
| Tools | セキュアなCode実行 + Web操作 | エージェント能力の安全な拡張 |
| Observability | エージェント動作の透明化 | トレース・デバッグの統一化 |
📍 本記事の位置づけ
この記事では、Memoryに焦点を当て、文脈保持やエージェント間の記憶共有について詳しく解説します。
🧠 概要
AgentCore Memoryは、AI エージェントに人間のような記憶能力を提供する管理型サービスです。従来のLLMが持つ「会話が終わると全て忘れる」という制約を解決し、継続的な学習と個人化を実現します。
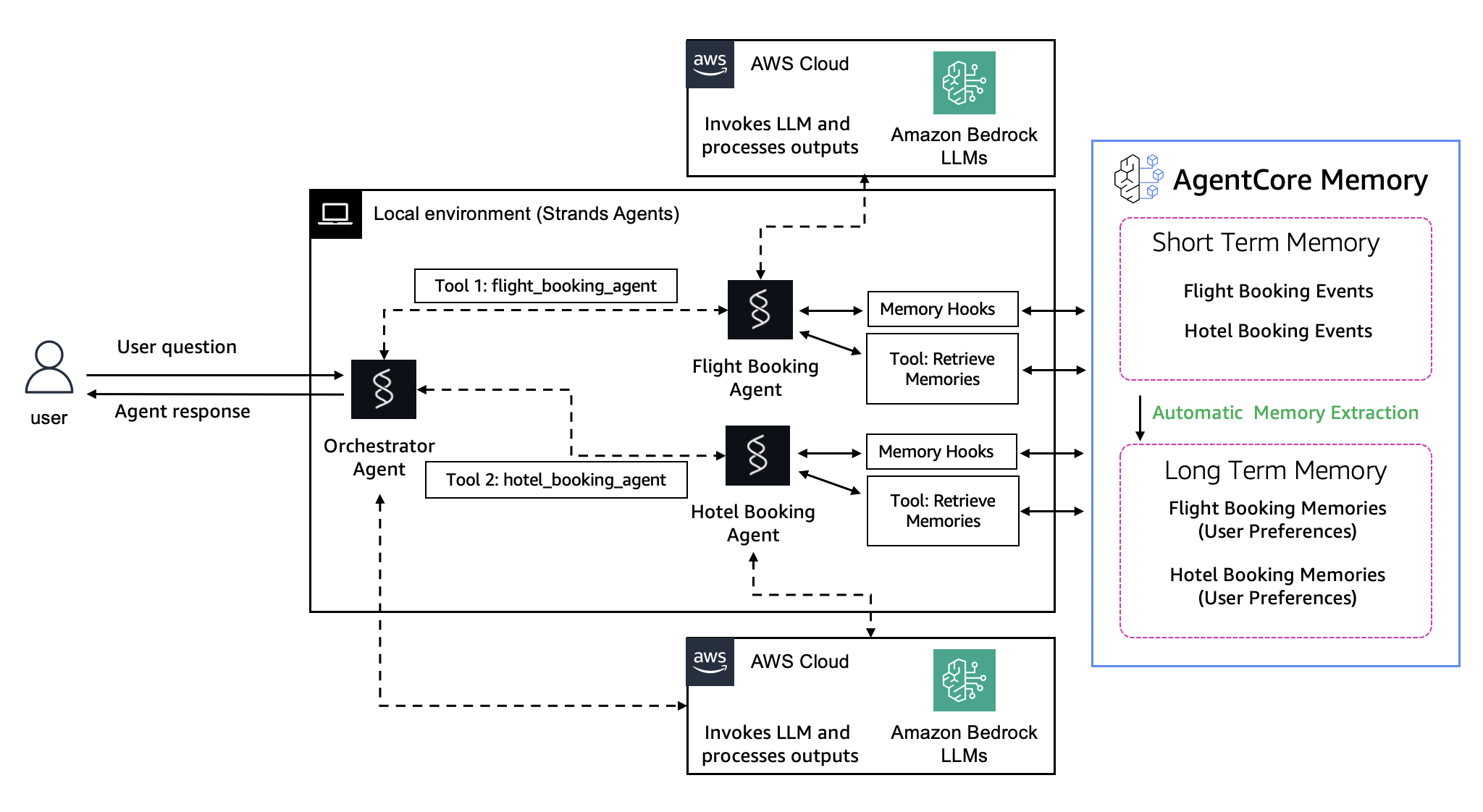
核心的な価値提案
AgentCore Memoryは2つの記憶タイプと4つの記憶戦略を組み合わせることで、人間の記憶メカニズムを模倣した知的なメモリシステムを構築します。
🔄 Short-term Memory: 会話の継続性を実現する即時記憶
一般ユースケース例
ケース: 長い会話での文脈維持
従来: 長い会話が続くと、AIエージェントは序盤の重要な情報を忘れてしまい、「先ほどお話しいただいた件について」と言われても何を指しているのか理解できませんでした。特に複数のトピックが混在する会話では、ユーザーが前に言った名前や好み、具体的な要求を覚えておくことができず、会話の途中で「もう一度お名前を教えてください」「どのような件でしたっけ?」と聞き直す必要がありました。
AgentCore導入後: Short-term Memoryにより、エージェントは会話の開始時に直近の会話ターンを自動的に読み込み、「Alexさん、AIについて学習されたいとのことでしたが、特に機械学習の応用分野に関心をお持ちでしたね」といった形で、会話全体の文脈を理解した応答ができるようになりました。get_last_k_turnsで開発者が記憶するターン数を調整でき、会話の長さに応じて適切なコンテキスト量を設定できます。
💭 コメント
ターン数の調整(k=3〜15)でトークン消費量とコンテキストの豊富さをバランスできるのが実用的です。
実装例:パーソナルエージェント
# 直近5ターンの会話を自動取得
recent_turns = client.get_last_k_turns(
memory_id=memory_id,
actor_id=actor_id,
session_id=session_id,
k=5 # 開発者が調整可能
)
# エージェント初期化時に自動でコンテキスト注入
class MemoryHookProvider(HookProvider):
def on_agent_initialized(self, event: AgentInitializedEvent):
if recent_turns:
context = "\n".join([f"{msg['role']}: {msg['content']['text']}"
for turn in recent_turns for msg in turn])
event.agent.system_prompt += f"\n\nRecent conversation:\n{context}"
🧠 Long-term Memory: AIによる知的情報抽出システム
Long-term Memoryは、人間の記憶メカニズムを模倣し、重要な情報を自動的に抽出・構造化・永続保存するシステムです。会話から価値ある知識を抽出し、セマンティック検索で関連情報を発見できます。
💭 コメント
人間の記憶を模倣しているってのはおもしろいですね。まさに学習して成長するパーソナルエージェントって感じで、AIが勝手に情報を分析・抽出・構造化してくれるのが革新的です。
自動処理の流れ
Long-term Memoryは、保存された会話データをバックグラウンドで自動的に分析し、設定された戦略に基づいて重要な情報を抽出・構造化します。この処理は通常約1分程度で完了し、開発者が追加のコードを書く必要はありません。Foundation Modelが会話の文脈を理解し、各戦略の目的に応じた情報を自動的に抽出・統合・保存することで、次回の検索時にセマンティック検索で関連情報を発見できるようになります。
📊 SEMANTIC Memory Strategy: 事実記憶の専門家
一般ユースケース例
ケース: カスタマーサポートでの製品・購入履歴管理
従来: 顧客からの問い合わせ時に、過去の購入製品や技術的問題の詳細を毎回聞き直す必要がありました。「以前購入されたのはどの製品でしたか?」「同様の問題は過去にありましたか?」といった基本的な事実確認に時間を要し、顧客は同じ説明を繰り返すストレスを感じていました。また、製品仕様や技術的詳細が分散して保存されており、一貫した情報提供が困難でした。
AgentCore導入後: SEMANTIC戦略により、顧客との会話から製品名・購入日・仕様・技術的問題などの事実情報が自動的に抽出され、構造化されて保存されます。次回の問い合わせ時には「iPhone 15 Pro(6月1日購入)のバッテリー過熱問題の件ですね」といった具体的な事実に基づいた応対が即座に可能になり、顧客は詳細な説明を繰り返す必要がなくなります。
実装例:製品情報の自動抽出
{
"semanticMemoryStrategy": {
"name": "ProductKnowledge",
"description": "製品情報と購入履歴の事実を抽出",
"namespaces": ["support/customer/{actorId}/purchases"]
}
}
# 抽出される情報例
# 入力: "先月新しいMacBook Pro M3を購入して、メモリは32GBにしました"
# 抽出結果: {
# "product": "MacBook Pro M3",
# "purchase_time": "先月",
# "specifications": "メモリ32GB",
# "action": "購入"
# }
💭 コメント
ユーザーが具体的な数字や事実を聞いてきたときに威力を発揮しそうです。「何が起こったか」を理解して記録してくれるのが便利ですね。
🎭 USER_PREFERENCE Memory Strategy: 好み記憶の専門家
一般ユースケース例
ケース: 旅行予約システムでのパーソナライゼーション
従来: 旅行予約の際、顧客は毎回「直行便希望」「朝の便が好み」「ホテルは市内中心部」といった同じ好みを説明する必要がありました。過去の選択履歴や嗜好パターンが活用されず、毎回ゼロからの提案になるため、顧客にとって時間がかかり、サービス提供者にとっても効率的でない状況が続いていました。また、顧客の好みの変化や学習による最適化も行われていませんでした。
AgentCore導入後: USER_PREFERENCE戦略により、「ThinkPadが好み」「キーボードの打鍵感重視」「連絡は夕方6時以降は避ける」といった顧客の好みや設定が自動的に学習・記録されます。次回のサービス利用時には、これらの嗜好を踏まえた個別最適化された提案が自動的に行われ、顧客は改めて好みを説明することなく、パーソナライズされたサービスを受けられます。
実装例:旅行好みの学習
{
"userPreferenceMemoryStrategy": {
"name": "TravelPreferences",
"description": "旅行に関する好みと設定を学習",
"namespaces": ["travel/{actorId}/preferences"]
}
}
# 抽出される好み例
# 入力: "直行便希望で、朝の便が好みです。イベリア航空をよく使います"
# 抽出結果: {
# "flight_preference": {
# "route_type": "直行便",
# "time_preference": "朝",
# "airline_preference": "イベリア航空"
# }
# }
💭 コメント
ユーザーごとのペルソナ設定に使えそうですね。出力形式の設定にも活用できて、「簡潔な回答が好み、専門用語は避けて、箇条書きで」といった情報を記憶して、次回から自動的にその形式で回答するのが画期的です。
📝 SUMMARY Memory Strategy: 文脈記憶の専門家
一般ユースケース例
ケース: 長期プロジェクトでの進捗管理
従来: 数週間や数ヶ月にわたるプロジェクトでは、過去の議論内容や決定事項、課題の経緯を正確に把握することが困難でした。「前回何を話しましたっけ?」「どこまで進んでいましたか?」といった確認に時間を要し、重要な文脈が失われることで意思決定の品質が低下していました。また、チームメンバーの交代や長期間の中断後の再開時に、プロジェクトの全体像を把握するのに膨大な時間がかかっていました。
AgentCore導入後: SUMMARY戦略により、長い技術ディスカッションや複数回にわたる問題解決プロセスが自動的に要約され、「WiFi接続問題を段階的に診断、最終的にルーター再起動で解決。今後同様の問題では最初にルーター確認を推奨」といった実用的な要約が生成されます。プロジェクト再開時や新メンバー参加時に、効率的に文脈を理解し、適切な継続が可能になります。
実装例:問題解決履歴の要約
{
"summaryMemoryStrategy": {
"name": "ProjectSummary",
"description": "プロジェクト進捗と課題解決の要約",
"namespaces": ["project/session/{sessionId}/summary"]
}
}
# 生成される要約例
# 入力: 20ターンのトラブルシューティング会話
# 要約結果: "ユーザーのWiFi接続が不安定。
# 段階的診断: 1)デバイス再起動→効果なし
# 2)設定確認→問題なし
# 3)ルーター再起動→解決
# 今後の参考: 同様の問題では最初にルーター確認を推奨"
💭 コメント
ざっくりとこんな会話履歴を捉えるときに便利そうです。長い会話から本質的なポイントを抽出して、次の会話で効率的に参照できるのが実用的ですね。
🛠️ CUSTOM Memory Strategy: ドメイン特化記憶の専門家
一般ユースケース例
ケース: 医療診断支援システムでの専門情報抽出
従来: 医療分野では症状・既往歴・薬物アレルギー・生活習慣など、一般的なビジネス情報とは異なる専門的な情報の正確な抽出が必要ですが、汎用的な情報抽出システムでは医療用語の理解や重要度の判定が適切に行われませんでした。「頭痛」と「片頭痛」の区別や、薬物相互作用の重要性といった医療特有の文脈が考慮されず、診断支援に必要な精度の情報整理ができていませんでした。
AgentCore導入後: CUSTOM戦略により、医療分野に特化した情報抽出ルールを定義できます。「症状と発症時期」「既往歴と薬物アレルギー」「現在の服薬状況」「生活習慣(運動、食事、睡眠)」といった医療診断に必要な観点で情報を構造化し、「最近頭痛が続いて、以前から高血圧の薬を飲んでいます」から「current_symptoms: [頭痛(継続中)]、medical_history: [高血圧]、medications: [降圧薬]」といった診断支援に直接活用できる形式で情報を抽出できます。
実装例:医療情報の特化抽出
{
"customMemoryStrategy": {
"name": "MedicalRecords",
"description": "医療情報の専門的抽出",
"namespaces": ["healthcare/patient/{actorId}/records"],
"configuration": {
"semanticOverride": {
"extraction": {
"appendToPrompt": """
以下の医療情報を正確に抽出せよ:
1. 症状と発症時期・程度
2. 既往歴と薬物アレルギー
3. 現在の服薬状況・用法用量
4. 生活習慣(運動、食事、睡眠、喫煙・飲酒)
5. 家族歴・遺伝的要因
""",
"modelId": "anthropic.claude-3-sonnet-20240229-v1:0"
}
}
}
}
}
💭 コメント
マニュアルで記憶保持の設定を作成することもできるんですね。特定ドメインのエージェント用にカスタマイズすることはできて強力なんだろうけど、できるだけ用意されているものを利用したいですね。
🗂️ Namespace設計: エレガントな情報組織化システム
Namespaceは、メモリの「住所体系」として機能し、情報の効率的な整理・検索・権限制御を実現する設計パターンです。Unix/Linuxのディレクトリ構造と同様の階層設計により、大規模なメモリシステムでも情報を体系的に管理できます。
基本構造とパターン
# 基本的な階層構造
"domain/entity/{variable}/category"
# 動的変数の活用
利用可能な変数:
├── {actorId} : エージェント・ユーザーの識別子
├── {sessionId} : 会話セッションの識別子
└── {memoryId} : メモリリソースの識別子
設計パターン別アプローチ
パターン1: ユーザー中心設計
適用場面: パーソナルアシスタント、個人向けサービス
user_centric_design = {
"personal_info": "user/{actorId}/personal", # 個人情報
"preferences": "user/{actorId}/preferences", # 設定・好み
"interaction_history": "user/{actorId}/history", # 行動履歴
"learning_progress": "user/{actorId}/progress" # 学習進捗
}
# メリット: ユーザー単位での情報一元化、プライバシー管理の容易さ
# 用途: 教育プラットフォーム、ヘルスケアアプリ、個人秘書システム
パターン2: 機能中心設計
適用場面: エンタープライズシステム、部門別運用
function_centric_design = {
"customer_support": "support/customer/{actorId}", # サポート関連
"sales_management": "sales/lead/{actorId}", # 営業関連
"billing_system": "billing/account/{actorId}", # 請求関連
"hr_system": "hr/employee/{actorId}" # 人事関連
}
# メリット: 機能別チームでの情報分離、責任境界の明確化
# 用途: 大企業システム、部門横断プロジェクト、コンプライアンス重視環境
パターン3: マルチエージェント設計
適用場面: 専門エージェント協調システム
multi_agent_design = {
"flight_specialist": "travel/flight-agent/{actorId}/expertise",
"hotel_specialist": "travel/hotel-agent/{actorId}/expertise",
"coordinator": "travel/coordinator/{actorId}/orchestration",
"shared_context": "travel/session/{sessionId}/shared"
}
# メリット: エージェント間の専門性分離と協調、拡張性
# 用途: 旅行予約システム、医療診断支援、複合的コンサルティング
💭 コメント
エレガントな設計ですね。ユーザー、部署、エージェントといった異なる粒度でメモリーを分離して管理できる点が非常に実用的ですね。
特に興味深いのは、利用する部署ごとにメモリを分けるアプローチです。例えばCognitoのグループ機能を活用して部署ごとに質問のネームスペースを分離すれば、同じエージェントを使っていても、営業部には営業寄りの回答、技術部には技術寄りの回答というように、部署の特性に合わせた調整が可能になりそう。
時系列・成長管理の設計
ユーザー成長の追跡パターン
従来の課題: ユーザーのスキルレベルや能力の変化を継続的に追跡することが困難で、過去の成長履歴と現在の状態を両方管理する仕組みがありませんでした。
AgentCore解決策: 時系列情報をNamespaceとメタデータで効率的に管理できます。
# パターンA: 時系列Namespace分割
temporal_separation = {
"beginner_phase": "learning/student/{actorId}/2024/beginner",
"intermediate_phase": "learning/student/{actorId}/2024/intermediate",
"expert_phase": "learning/student/{actorId}/2025/expert"
}
# パターンB: 統合Namespace + メタデータ管理
unified_with_metadata = {
"current_state": "learning/student/{actorId}/progress",
"metadata": {
"skill_level": "expert",
"progression_history": [
{"level": "beginner", "date": "2024-01", "evidence": "基本概念学習"},
{"level": "expert", "date": "2024-12", "evidence": "複雑課題解決"}
]
}
}
# パターンC: 定期評価スナップショット
snapshot_approach = {
"Q1_assessment": "assessment/{actorId}/2024-Q1",
"Q2_assessment": "assessment/{actorId}/2024-Q2",
"Q3_assessment": "assessment/{actorId}/2024-Q3"
}
💭 コメント
時系列のほうはネームスペースに時系列やメタデータ付きバージョニングを入れることでユーザーの成長をもとにメモリーを更新することができます。1年前は新人だったけど、今では一人前のユーザーみたいな変化も追跡できますね。
検索効率への影響
Namespaceの設計は検索パフォーマンスに直接的な影響を与えます。適切に設計されたNamespaceでは、検索対象を特定の範囲に絞り込むことで高速な検索と関連性の高い結果を得ることができます。例えばsupport/customer/customer_001/preferencesのように具体的なNamespaceを指定することで、全データベースを検索する必要がなくなり、レスポンス時間が大幅に短縮されます。
一方で、global_memoryのような広すぎるNamespaceを使用すると、大量の無関係な情報も検索対象となるため、処理時間が長くなり、ノイズの多い結果が返される可能性があります。適切なNamespace設計により、システム全体のパフォーマンスとユーザー体験の両方を最適化できます。
権限制御との統合
Namespace単位でのアクセス制御
# Cognitoグループとの連携例
def get_accessible_namespaces(user_group: str, user_id: str):
access_patterns = {
"support_team": [
f"support/customer/{user_id}/*",
"support/knowledge/*",
"public/*"
],
"sales_team": [
f"sales/lead/{user_id}/*",
"sales/materials/*",
"public/*"
],
"management": [
"support/*",
"sales/*",
"analytics/*",
"public/*"
]
}
return access_patterns.get(user_group, ["public/*"])
🔍 検索活用方法: 3つの統合パターン
AgentCore Memoryは、Hooks・Tools・直接APIの3つの統合方法を提供し、用途に応じた柔軟な実装が可能です。
💭 コメント
メモリーもツール化してるってイメージですね。3つの方法で利用することができて、それぞれに特徴があります。
統合パターン比較表
| 統合方法 | 自動化レベル | 制御粒度 | 実装複雑度 | エラー処理 | 適用場面 | サンプル |
|---|---|---|---|---|---|---|
| Hooks | 完全自動 | 低 | 簡単 | フレームワーク任せ | 一般的な記憶管理 | Personal Agent, Customer Support |
| Tools | エージェント判断 | 中 | 中程度 | エージェント依存 | 専門エージェント協調 | Travel Booking, Multi-agent |
| 直接API | 手動制御 | 高 | 複雑 | 開発者実装 | 複雑なロジック・カスタム処理 | Enterprise Integration |
利用方法概要
# パターン1: Hooks - 自動メモリ管理
class AutoMemoryHook(HookProvider):
def on_agent_initialized(self, event):
# エージェント起動時に自動でコンテキスト読み込み
recent_context = self.load_recent_context()
event.agent.system_prompt += recent_context
def on_message_added(self, event):
# 新しいメッセージを自動保存
self.save_conversation_automatically()
# パターン2: Tools - エージェント判断による検索
@tool
def memory_search_tool(query: str) -> str:
provider = AgentCoreMemoryToolProvider(
memory_id=memory_id,
actor_id=actor_id,
namespace=namespace
)
return agent_with_memory_tools(query)
# パターン3: 直接API - 詳細制御
memories = client.retrieve_memories(
memory_id=memory_id,
namespace="custom/analysis/{actorId}",
query=processed_query,
top_k=calculate_optimal_k(context)
)
🤝 マルチエージェント記憶共有: 論理的セッション連携
一般ユースケース例
ケース: 病院での診療支援システム
従来: 病院では受付・問診・診察・薬剤指導と複数の担当者が関わりますが、それぞれが独立したシステムを使用し、患者は毎回同じ基本情報(既往歴・アレルギー・現在の症状)を説明する必要がありました。担当者間での情報共有は手動で行われ、重要な情報の見落としや重複検査のリスクがありました。また、各専門分野の知識と患者の個別情報を組み合わせた総合的な判断が困難でした。
AgentCore導入後: 論理的なセッションIDを共有することで、受付エージェントが収集した基本情報、問診エージェントが聞き取った症状詳細、専門医エージェントの診断結果、薬剤師エージェントの服薬歴がシームレスに連携されます。各エージェントは独自のactor_idで専門知識を蓄積しながら、同一session_idで患者の情報を共有し、「高血圧治療中の頭痛」といった複合的な文脈を理解した一貫したケアを提供できます。
💭 コメント
論理的なセッションIDを渡すことでエージェント間の連携をするんですね。ユーザーごとの重要な事実や会話の流れをエージェント間で共有しあうってことで、各エージェントが専門性を保ちながら協調できます。
共有戦略のパターン
実装パターン:情報共有レベルの設計
# 共有設定の基本構造
sharing_config = {
"memory_resource": "同一リソースで基盤共有",
"session_id": "会話グループの共有",
"actor_id": "エージェント別の専門知識分離"
}
# 具体例:旅行システム
travel_system = {
"shared_elements": {
"memory_id": "TravelAgent_SharedMemory",
"session_id": "travel-session-20241215"
},
"separated_elements": {
"flight_actor": "flight-user-20241215",
"hotel_actor": "hotel-user-20241215",
"coordinator_actor": "coordinator-20241215"
}
}
# 結果として得られる情報分離
# - 共有: 会話の流れ、顧客の基本要求
# - 分離: フライト専門知識、ホテル専門知識、統括判断履歴
📊 Performance Monitoring: データドリブンな継続的改善
一般ユースケース例
ケース: 大規模カスタマーサポートでの品質管理
従来: AIエージェントのパフォーマンスは主観的な評価に依存し、「なんとなく応答品質が下がった気がする」「検索が遅い」といった感覚的な問題把握しかできませんでした。記憶抽出の精度や検索性能の定量化ができないため、改善すべき箇所の特定や効果測定が困難で、試行錯誤による非効率な運用改善が続いていました。また、大量のユーザーからのフィードバックを体系的に分析する仕組みもありませんでした。
AgentCore導入後: 抽出品質(precision/recall)、検索性能(レスポンス時間、関連度)、処理効率(バックグラウンド処理時間)、システム健全性(エラー率、可用性)の4つの観点で定量的な監視が可能になります。AI評価による大規模自動評価と人間評価による品質保証を組み合わせ、リアルタイムでの性能劣化検知とアラート、A/Bテストによる戦略最適化を通じて、データドリブンなPDCAサイクルを実現できます。
💭 コメント
メモリー機能の定量評価もできるようになっているのがアツいですね。しかも評価が人間/AI(オンライン/オフライン)の評価ができるようになっているので、開発者はこの辺の情報を参考にしてPDCAを回して最良のメモリー戦略を作っていけます。
監視指標とPDCAサイクル
# Plan: 初期戦略の設計と成功指標設定
target_metrics = {
"extraction_accuracy": 0.85, # 85%以上の抽出精度
"search_latency": 1500, # 1.5秒以下のレスポンス
"user_satisfaction": 4.0 # 5段階評価で4.0以上
}
# Do: 本番環境での運用と自然な学習・蓄積
# Check: ハイブリッド評価による定量測定
performance_data = {
# AI評価(スケール・速度・一貫性)
"real_time_accuracy": ai_evaluator.measure_quality(),
# 人間評価(品質・ニュアンス・ビジネス価値)
"expert_review_score": human_evaluator.review_samples(),
# システムメトリクス
"search_latency_p95": monitor.track_response_time(),
"error_rate": health_monitor.analyze_logs()
}
# Act: データドリブンな戦略調整
if performance_data["extraction_accuracy"] < target_metrics["extraction_accuracy"]:
improved_strategy = optimize_extraction_prompts()
ab_test_results = run_strategy_comparison(current, improved)
まとめ
個人的に一番アツい機能でした🔥
ユーザーの好みやペルソナを更新していってどんどん賢くなっていく点、記憶の粒度を設定してパフォーマンスとのトレードオフを取っている点が秀逸です。
最近だとコンテキストエンジニアリングというワードがホットですが、評価も含めた運用を考えると非常に大変そうでした。
そんな課題をAgent Coreを利用することで簡単に実現できるようになりましたね!
📊 シリーズ進捗状況
| # | コンポーネント | リンク |
|---|---|---|
| ① | Runtime(実行基盤) | 公式サンプルを参考にAgentCoreへDeepDive(Runtime) |
| ② | Gateway(統合レイヤー) | 公式サンプルを参考にAgentCoreへDeepDive(Gateway) |
| ③ | Memory(状態管理) | 👉 本記事 |
| ④ | Identity(認証) | 準備中 |
| ⑤ | Tools(実行ツール群) | 準備中 |
| ⑥ | Observability(可観測性) | 準備中 |
🔗 参考
チュートリアル
https://github.com/awslabs/amazon-bedrock-agentcore-samples/