はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で Databricks や AWS を推進している nttd-saitouyun です。
今回は社内の勉強向けに作ったデモをご紹介します。
このデモは、Databricks のマーケットプレイスで公開される Shutterstock のデータ(非構造データを含む)を探索しながら以下の点を理解するものです。
- Databricks Marketplace の使い方【★】
- Shutterstock のデータの扱い方【★】
- 生成AIを活用したノーコードのデータ探索【★】
- 生成AIを活用したノーコードのデータエンジニアリング【★】
- ベクトル検索によるあいまい検索【★】
- 画像のデータ処理【◆】
本書では【◆】の項目について記載します。【★】の内容については以下の記事をご覧ください。
- Databricks Marketplace から Shutterstock のデータをさわってみる
- Databricks で Shutterstock のデータを自然言語で処理する
- Databricks で Shutterstock のテキストデータをベクトル検索をする
Databricks で画像データを分散処理する
前回の記事にでは、非構造データとしてテキストを扱いました。
このノートブックでは、Shutterstock が提供する画像データをサイズを変えたり、色を変えたり、データ処理をします。また、処理は分散処理を行い、大量のデータを効率的に処理します。
Pythonによる画像処理
前回の記事で検索キーワードを「smile」にしてヒットした「笑顔の女性」の画像を加工していきます。

Pythonで実施できることはDatabricksでも実施できます。PIL(Python Imaging Library)を使って画像を操作してみます。PILはデフォルトでインストールされているのですぐに使うことができます。
まずは画像の表示をしてみます。元の画像が大きいのサイズを半分にして表示します。
from PIL import Image
image = Image.open("/Volumes/shutterstock_free_sample_dataset_1000_high_resolution_images_metadata/sample_datasets/set1_image_files/medium/1114624559.jpg")
(width, height) = (image.width // 2, image.height // 2)
image_resize = image.resize((width, height))
display(image_resize)
実行すると以下のようになります。

続いて、画像を回転させます。(45度回転)
image_rotate = image_resize.rotate(45)
display(image_rotate)

次は、グレースケールにしてみます。
image_gray = image_resize.convert('L')
display(image_gray)

このように画像を様々に加工できます。もちろん、加工したデータをボリューム(Databricksのファイルストレージ)に保存することも可能です。
Apache Spark による画像処理
機械学習の学習データやマルチモーダル生成AIのインプットデータなど、大量の画像データを処理するユースケースは増えています。
ここからは、Spark を使って先ほどの画像データ加工処理を分散処理してみます。といっても、今回扱う Shutterstock のサンプル画像データは1000件なのでそこまで大規模ではありませんがご容赦ください。
データ処理内容の関数化
まず先ほどの処理を関数化します。先ほどのコードと同様に、以下の処理を加えた9つの画像を保存しています。
- 半分にリサイズした画像
-
- ををグレースケールにした画像
-
- を45度ずつ回転させた7つの画像
import os
import socket
from PIL import Image
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
output_path = "/Volumes/demo_saitouyun/demo001/processed_image/"
@udf(returnType=StringType())
def process_image_udf(image_path: str) -> str:
image = Image.open(image_path)
(width, height) = (image.width // 2, image.height // 2)
image_resize = image.resize((width, height))
base, ext = os.path.splitext(os.path.basename(image_path))
# リサイズ
output_file_name = os.path.join(output_path, f"{base}{ext}")
image_resize.save(output_file_name)
# グレースケール
image_gray = image_resize.convert('L')
image_gray.save(os.path.join(output_path, f"{base}_gray{ext}"))
# 回転
rotations = [45, 90, 135, 180, 225, 270, 315]
for angle in rotations:
rotated_image = image_resize.rotate(angle)
rotated_image.save(os.path.join(output_path, f"{base}_r{angle}{ext}"))
hostname = socket.gethostname()
return hostname
戻り値として、この関数の処理を行ったノードのホスト名を返すようにしています。こちらは画像処理とは関係ありませんが、処理が分散して処理されていることを確認するために使います。
分散処理の実行
UDF を Spark データフレームに適用し、分散処理を行います。
from pyspark.sql.functions import col
df_processed = df_cleaned_image_metadata.withColumn(
"node_hostname",
process_image_udf(col("image_path"))
)
display(df_processed)
実行結果は「17.11分」でした。また、実行結果は以下の通りです。

画像データの出力先のボリュームを見てみるとファイルがしっかりと書き込まれていました。

画像を見てみました。想定通りに9パターンの画像が作成できています。

せっかく Apache Spark を使っているので分散処理しているのか見てみましょう。
処理ノードのホスト名で集計をしてみます。
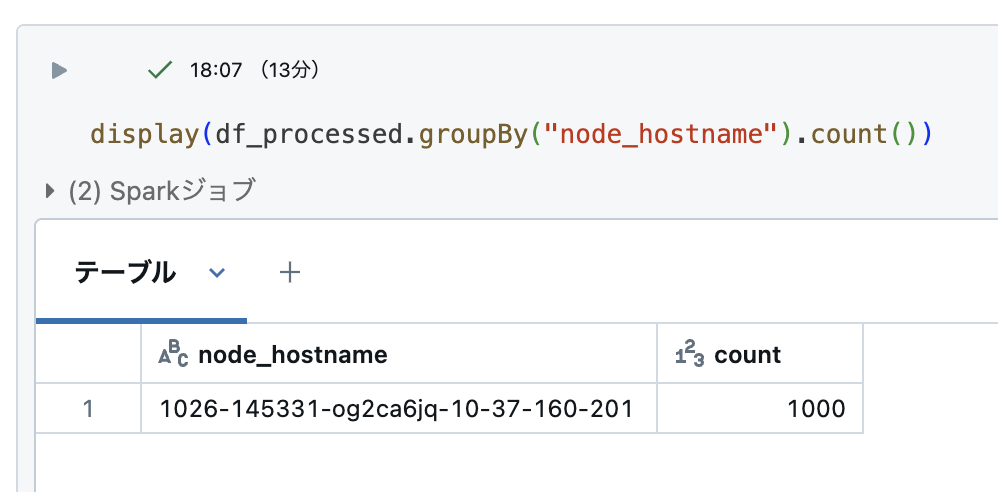
おっと!全て同じノードで処理されており分散していないようです。
Apache Spark は大量のデータをいくつかのパーティションに分割することで並列処理します。
今回はパーティションを切り忘れていました。パーティションを切り直して再度処理してみたいと思います。
分散処理の実行(Python UDF + パーティション)
以下のコマンドでデータを4つのパーティションに分割します。
df_cleaned_image_metadata_p4 = df_cleaned_image_metadata.repartition(4)
今回はワーカー数4のクラスタを使っているため、4つのパーティションに分けました。
一度、テーブルに保存しておき、再度データフレーム化します。
df_cleaned_image_metadata_p4.write.mode("overwrite").saveAsTable("demo_saitouyun.demo001.cleaned_image_metadata_4")
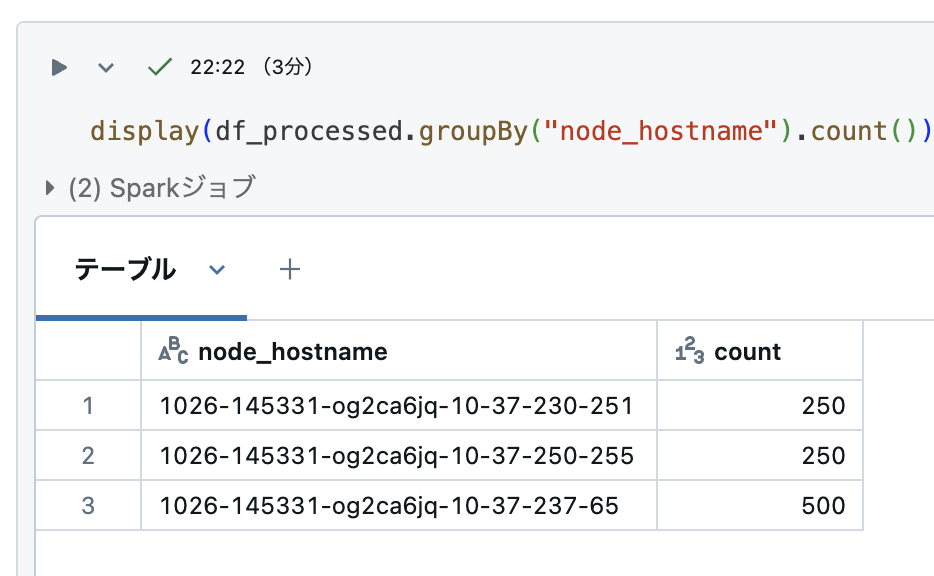
同様の処理を実行してみます。実行結果は「7.26分」になり、大幅に改善されました。

処理ノードのホスト名の集計値もみてみます。先ほどとは違い複数のノードに分散されて処理されていることがわかります。データは必ずしも 1000 ÷ 4 = 250 にぴったり分けられるわけではありませんので、若干偏っています。
十分処理時間が短くなりましたが、実はより速くすることも可能です。
分散処理の実行(Pandas UDF + パーティション)
pandas UDF(ベクトル化された UDF)を利用することでさらに処理時間を向上することも可能です。
pandas ユーザー定義関数 (UDF) (ベクトル化された UDF とも呼ばれます) は、 Apache Arrow を使用してデータを転送し、pandasを使用してデータを操作するユーザー定義関数です。 pandasの UDF ではベクトル化された操作が可能で、1度に1行ずつの Python UDF と比較してパフォーマンスを最大 100 倍向上させることができます。
Apache Arrow のパラメータを設定します。1000レコードを4ノードで処理するので、2つ目のパラメータを256にしておけば、1度で250レコードを読み込むことができ、データの読み込みを最小限にできます。
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "256")
また、UDFの関数も修正します。引数と戻り値を Pandas Series 型にします。その他の処理は同様です。
import os
import socket
import pandas as pd
from PIL import Image
from pyspark.sql.functions import col, pandas_udf
from pyspark.sql.types import ArrayType, StringType
output_path = "/Volumes/demo_saitouyun/demo001/processed_image/"
@pandas_udf(StringType())
def process_image_udf(image_path_pd: pd.Series) -> pd.Series:
processing_hosts = []
for image_path in image_path_pd:
image = Image.open(image_path)
(width, height) = (image.width // 2, image.height // 2)
image_resize = image.resize((width, height))
base, ext = os.path.splitext(os.path.basename(image_path))
# リサイズ
output_file_name = os.path.join(output_path, f"{base}{ext}")
image_resize.save(output_file_name)
# グレースケール
image_gray = image_resize.convert('L')
image_gray.save(os.path.join(output_path, f"{base}_gray{ext}"))
# 回転
rotations = [45, 90, 135, 180, 225, 270, 315]
for angle in rotations:
rotated_image = image_resize.rotate(angle)
rotated_image.save(os.path.join(output_path, f"{base}_r{angle}{ext}"))
host = socket.gethostname()
processing_hosts.append(host)
return pd.Series(processing_hosts)
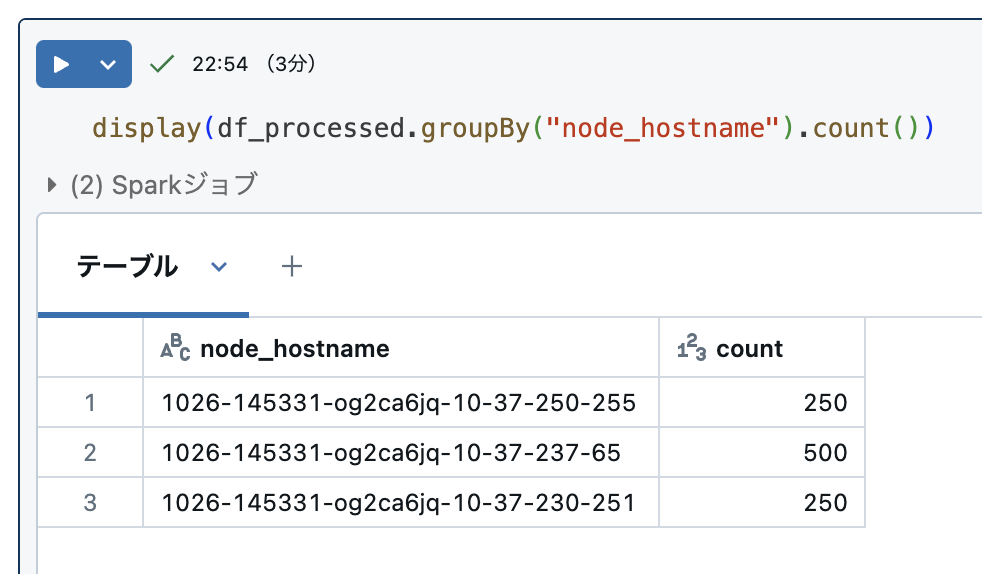
同様の処理を実行してみます。実行結果は「6.28分」になり、さらに速くなりました。

処理ノードのホスト名の集計値もみてみます。先ほどと同様に分散されて処理されています。
まとめ
以上のように、Databricks では Python の処理を UDF にすることで大量の非構造化データを容易に処理することができます。
| パーティション | UDF | 処理時間 |
|---|---|---|
| なし | Python UDF | 17.11 分 |
| あり | Python UDF | 7.26 分 |
| あり | Pandas UDF | 6.28 分 |
初期は慣れていたり情報の多い Python で非構造データ処理を記述し、データが大きくなったタイミングで、関数化することで、簡単に Apache Spark で分散処理させることができ、データの規模に対して柔軟な処理が可能できます。
おわりに
このノートブックでは、非構造データの活用をテーマにし、画像処理について扱いました。生成AIの台頭により今後、非構造データの活用がますます進むと予想されます。
Databricksを活用し、眠っているデータから新しい価値を生み出しましょう!
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。