はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で Databricks や AWS を推進している nttd-saitouyun です。
今回は社内の勉強向けに作ったデモをご紹介します。
このデモは、Databricks のマーケットプレイスで公開される Shutterstock のデータ(非構造データを含む)を探索しながら以下の点を理解するものです。
- Databricks Marketplace の使い方【★】
- Shutterstock のデータの扱い方【★】
- 生成AIを活用したノーコードのデータ探索【★】
- 生成AIを活用したノーコードのデータエンジニアリング【★】
- ベクトル検索によるあいまい検索【◆】
- 画像のデータ処理
本書では【◆】の項目について記載します。【★】の内容については以下の記事をご覧ください。
Databricks でベクトル検索(あいまい検索)をする
Databricks で Shutterstock のデータを自然言語で処理する ではノーコードでデータ加工をしました。
このノートブックでは、テキストをベクトル化しあいまい検索をすることで探したい画像を見つけます。
ベクトル検索の準備-その1
テキストをベクトル化(Embedding)するためにLLMを利用します。
左のペインから「クラスター」を選択し、以下の画像にあるようにベクトル検索を行うためもコンピューティングリソースを立ち上げます。
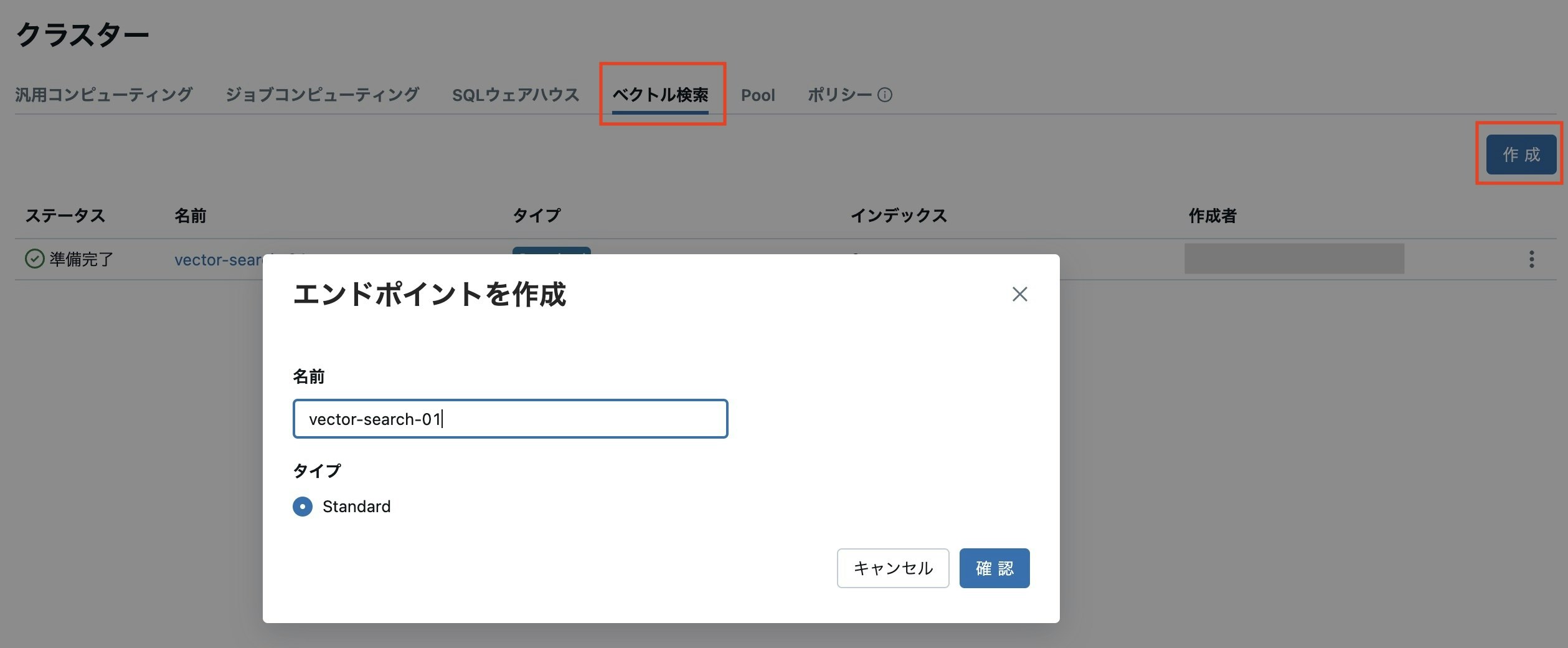
ベクトル検索の準備-その2
ベクトル検索で利用するライブラリをインストールしておきます。
%pip install databricks-vectorsearch
dbutils.library.restartPython()
ベクトル検索の準備-その3
ベクトル化するテーブルはチェンジデータフィード(テーブルの変更情報を連携する機能)を有効化するあるため、以下のコードを実行します。(今回は利用しませんが、データに更新があった場合に変更データに対してベクトル化を実行するのに必要になります。)
ALTER TABLE `demo_saitouyun`.`demo001`.`cleaned_image_metadata` SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
カタログエクスプローラから処理対象のテーブル「cleaned_image_metadata」を選択します。「作成」を押し、「ベクトル検索インデックス」を選択します。

ベクトル検索のインデックス作成ページが開いきますので、名前や主キーなどの情報を入力します。エンドポイントには準備で作成したコンピューティングリソース(vector-search-01)を指定します。
埋め込みソース列はベクトル化したいカラム(Keywords)を指定します。埋め込みモデルはEmbeddingを行う生成AI(LLM)を選択します。今回はデフォルトで利用可能なものを選択しますが、AWSであればAmazon Bedrock、AzureであればOpenAIのLLMを呼び出すことも可能です。

インデックスが作成されるとカタログエクスプローラに表示されます。もちろん、このインデックスもテーブル同様のアクセス制御などを行うことができます。

ベクトル検索であいまい検索してみる
いよいよ本題のあいまい検索です。
まずはKEYWORDS列にどのようなデータは入っているか確認してみます。
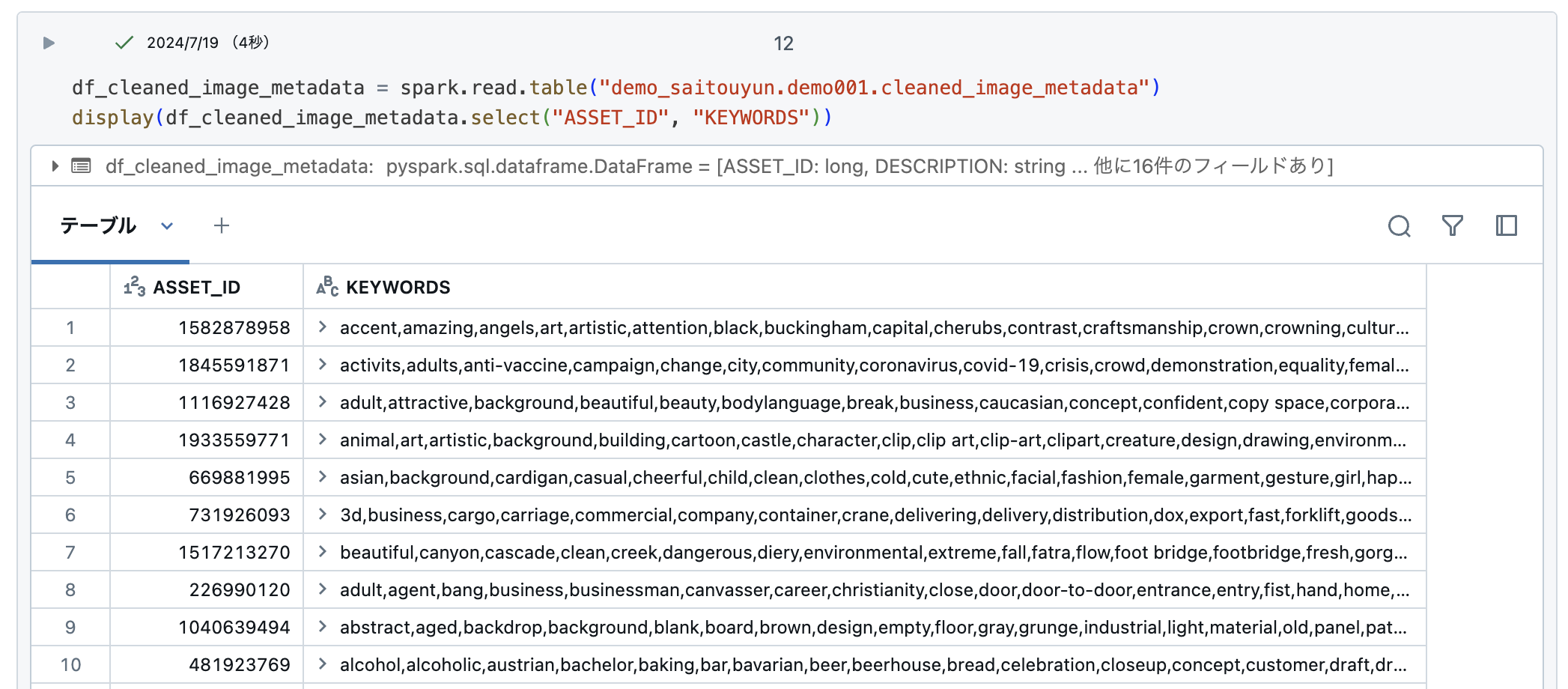
画像に関するキーワードがカンマ区切りで羅列されています。これをSQLなどで検索するのは難しそうですね。
実ユースケースでも、SNSのタグや商品名(○○コーヒー、○○コーヒー 500ml 12本入り、○○コーヒー 1ダース)、企業名(前株、後株、略称)など、データ分析の中であいまい検索したいケースは多いのではないでしょうか?
では、実際にあいまい検索をしてみましょう。
まずは、エンドポイントと先ほど作成したインデックスから検索用のオブジェクトを作成します。
endpoint_name = "vector-search-01"
index_name = "demo_saitouyun.demo001.index_keyward_image_metadata"
from databricks.vector_search.client import VectorSearchClient
client = VectorSearchClient()
index = client.get_index(endpoint_name=endpoint_name, index_name=index_name)
以下のコードであいまい検索ができます。キーワードは「japanese food」で一致度が上位10件のデータを取得します。
results = index.similarity_search(
query_text="japanese food",
columns=["ASSET_ID", "KEYWORDS", "JAPANESE_DESCRIPTION"],
num_results=10
)
結果を見てみましょう。
target_asset_file_path = []
image_dir_path = "dbfs:/Volumes/shutterstock_free_sample_dataset_1000_high_resolution_images_metadata/sample_datasets/set1_image_files/medium/"
print('----------------------------------------')
for i in range(results['result']['row_count']):
print(' ASSET_ID: '+ str(results['result']['data_array'][i][0]))
print(' JAPANESE_DESCRIPTION: '+ str(results['result']['data_array'][i][2]))
print(' KEYWORDS: '+ str(results['result']['data_array'][i][1]))
print(' score: '+ str(results['result']['data_array'][i][3]))
print('----------------------------------------')
asset_id = int(results['result']['data_array'][i][0])
image_file_path = image_dir_path + str(asset_id) + ".jpg"
target_asset_file_path.append(image_file_path)
----------------------------------------
ASSET_ID: 1101947432.0
JAPANESE_DESCRIPTION: N/A
KEYWORDS: asia,asian,background,bar,card,cartoon,character,collection,color,comic,concept,cuisine,delicious,design,dinner,drawing,east,element,face,fish,flat,food,fresh,graphic,icon,illustration,isolated,japan,japanese,lunch,meal,menu,oriental,poster,retro,rice,roll,salmon,sashimi,seafood,set,shrimp,sign,style,sushi,symbol,traditional,tuna,vintage
score: 0.0032143143
----------------------------------------
ASSET_ID: 1890038536.0
JAPANESE_DESCRIPTION: 黒い背景にポルトベロ・キノコ、焼き上げ、チェダー・チーズ、チェリー・トマト、セージを詰めたもの
KEYWORDS: asian,baked,boneless top chuck steak,brown,caps,cheese,chinese,cooking,copy space,cultivated mushroom,edible,edible mushroom,food,fungi,fungus,gourmet,green,harvest,herbs,ingredient,ingredients,japanese,leaf,metal background,mushroom,mushrooms,nobody,noodles,organic,plant,portabello,portobello,portobello mushrooms,raw,sage,shiitake,shiitake mushroom,shitake,stipe,stuffed,tasty,tomato,uncooked,vegetable,whole
score: 0.0032120633
----------------------------------------
ASSET_ID: 155154827.0
JAPANESE_DESCRIPTION: テーブルの上に麺とトマトを入れたきのこ汁
KEYWORDS: carrots,cooking,cuisine,dish,first course,food,forest,fresh,mushrooms,national,noodles,organic,parsley,plate,russian,soup,spoon,table,tomatoes,wood
score: 0.0030425899
----------------------------------------
ASSET_ID: 1328658620.0
JAPANESE_DESCRIPTION: ラーメン – 麺類、野菜類、鶏肉のスープ
KEYWORDS: background,boiled,bowl,broth,carrot,carrots,chicken,chinese,cooking,cuisine,cutting,delicious,diet,dining,dinner,dish,eat,egg,eggs,food,fresh,garlic,gourmet,healthy,herbs,ingredients,leaves,lettuce,lunch,meal,noodles,nutrition,onion,overhead,pasta,plate,prepare,ramen,restaurant,seasonings,soup,spaghetti,spices,stew,table,vegetable,vegetables,vegetarian,vertical,view
score: 0.00294285
----------------------------------------
ASSET_ID: 1469988896.0
JAPANESE_DESCRIPTION: 魚料理 – 魚のすり身と野菜の揚げ物
KEYWORDS: appetizer,asparagus,background,baked,cod,dine,dining,dinner,dish,eating,filet,fillet,fillets,fish,flatfish,flounder,food,fried,garnish,grill,grilled,healthy,horizontal,lemon,lunch,meal,meat,nutrient,nutrition,omega3,paper,parsley,plate,portion,prepared,roast,roasted,salad,seafood,sole,steak,vegetable,vegetables,white,wooden,wooden background
score: 0.0028900427
----------------------------------------
ASSET_ID: 365239061.0
JAPANESE_DESCRIPTION: 金属錫の中に塩を入れた赤いキャビア。黒いテーブルの塩に。テキストの空き領域。
KEYWORDS: appetizer,background,black,can,canned,caviar,caviare,circle,conserve,copyspace,cuisine,delicious,dinner,fish,food,gourmet,healthy,ingredient,luxurious,luxury,meal,metal,orange,prepared,raw,red,refreshment,roe,salmon,salt,salty,sea,seafood,snack,space,tasty,text,tin,tinned,wood,wooden
score: 0.0028792794
----------------------------------------
ASSET_ID: 1760122031.0
JAPANESE_DESCRIPTION: 木の板にレモンとローズマリーを乗せた蒸し鮭の切り身
KEYWORDS: appetizer,background,bar-b-q,barbecue,board,cooked,delicious,dinner,dish,eating,filet,fillet,fish,food,fresh,fried,garnish,grill,grilled,healthy,lemon,lunch,meal,meat,menu,nobody,nutrient,omega-3,omega3,plank,plate,prepared,roast,roasted,rosemary,salmon,seafood,steamed,table,timber,vegetable,wooden
score: 0.002852626
----------------------------------------
ASSET_ID: 1131405236.0
JAPANESE_DESCRIPTION: 白い背景に生の生の茶色のシイタケ2つの半分のグループ
KEYWORDS: 2,asian,background,beige,black,bright,bronze,brown,chinese,close,closeup,couple,creamy,dark,deep,edodes,firm,food,forest,fresh,fungi,fungus,gilled,golden,half,halved,isolated,japanese,large,meaty,medicinal,mushroom,oak,oakwood,oriental,pair,plump,raw,sawtooth,shii,shiitake,shitake,spongy,tan,texture,traditional,two,uncooked,white,winter
score: 0.002840009
----------------------------------------
ASSET_ID: 1816576133.0
JAPANESE_DESCRIPTION: 陶磁器の皿にシャンテレルを入れ、木のテーブルの上に生のキノコを入れたスープ
KEYWORDS: carrots,chanterelles,cooking,dish,first,food,forest,fresh,kitchen,mushroom,mushrooms,national,parsley,plate,russian,soup,spoon,table,wooden
score: 0.002833582
----------------------------------------
ASSET_ID: 1931144642.0
JAPANESE_DESCRIPTION: フライパンにシャンピニオンとホウレンソウを入れたリゾット
KEYWORDS: antipasti,appetizer,asian,background,broth,butter,champignon,chinese,cooked,cooking,cuisine,dinner,dish,edible,fast,fastfood,food,fried,gastronomy,italian,kitchen,lunch,meal,mushroom,pan,plate,pot,poultry,preparing,restaurant,rice,risotto,roast,roasted,spinach,spoon,thai,vegetable,vegetables,vine,white
score: 0.002832815
----------------------------------------
これだけだとよくわからないですよね。画像を実際に表示して意図した検索ができているか確認してみましょう。
前回の記事 で作成した画像を含むテーブル(image_data)に対して、対象のデータのみを抽出して表示してみます。
from pyspark.sql.functions import col
image_df = spark.read.table("demo_saitouyun.demo001.image_data")
filtered_image_df = image_df.filter(col("image.origin").isin(target_asset_file_path))
display(filtered_image_df)
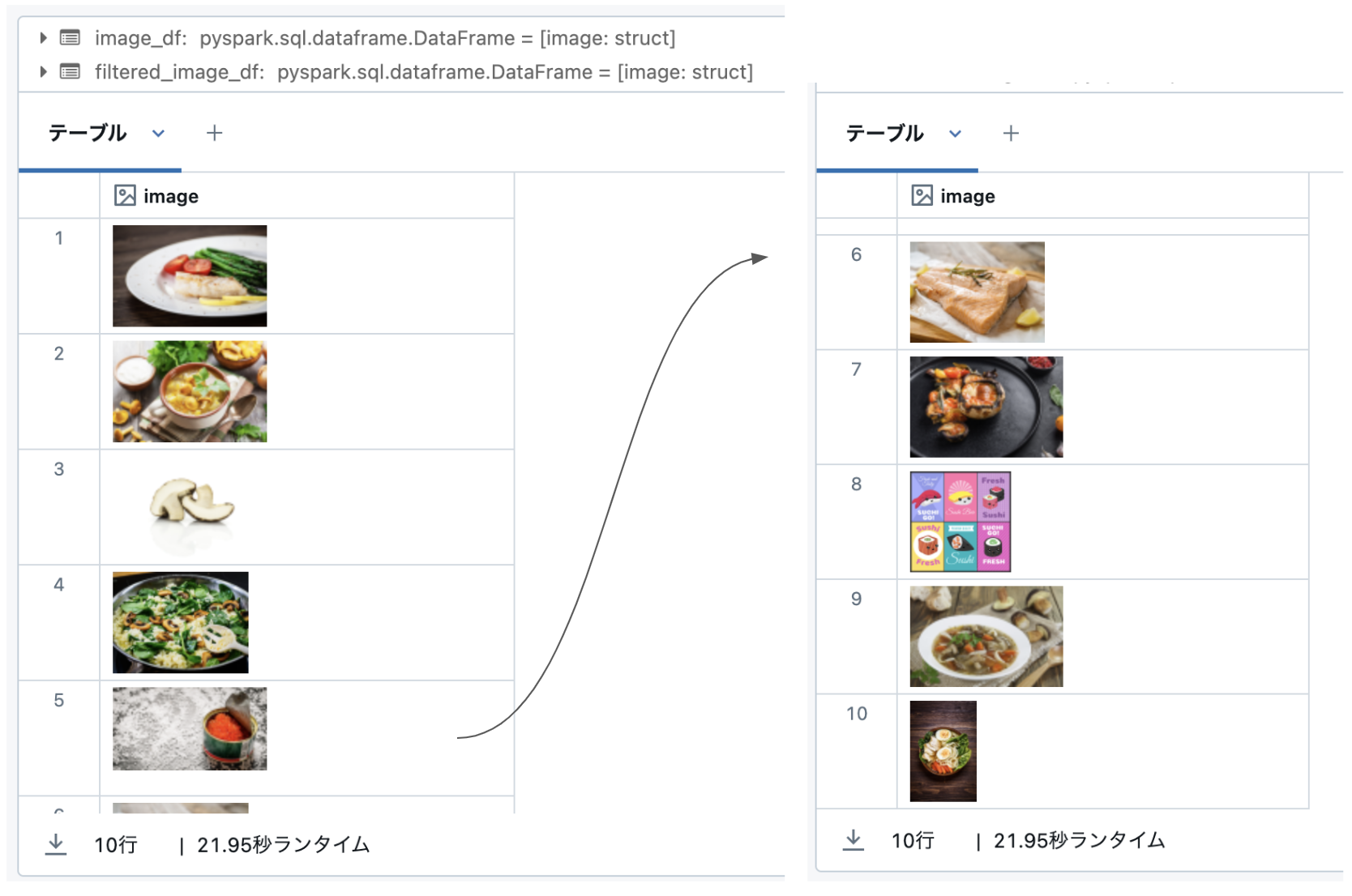
しいたけ、寿司、ラーメンなど確かに日本食っぽいデータが抽出できました。(もともとのスコア(一致度)がイマイチなのでそもそも日本食のデータが少ないかもしれません)
検索キーワードを「日本食」(日本語)に変更してみましょう。
results = index.similarity_search(
query_text="日本食",
columns=["ASSET_ID", "KEYWORDS", "JAPANESE_DESCRIPTION"],
num_results=10
)
以降の画像を表示するまでのコードは同じです。

どうでしょうか。やや日本語が減った気がしますね。
これはキーワードをベクトル化する際に使ったモデルが英語向けであるためです。
日本語での検索の精度を上げるためには、多言語対応しているモデルを利用することで実現できます。
おわりに
このノートブックでは、非構造データの活用をテーマにし、テキストデータの処理について扱いました。
テキストデータに対し、LLMを使い、ベクトル検索(あいまい検索)を行い、データを抽出しました。そして、対象のデータの画像を表示しました。
Databricksでは非構造データを簡単に管理し、様々な方法で活用できること、ご理解いただけましたら幸いです。
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。