はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で Databricks や AWS を推進している nttd-saitouyun です。
今回は社内の勉強向けに作ったデモをご紹介します。
このデモは、Databricks のマーケットプレイスで公開される Shutterstock のデータ(非構造データを含む)を探索しながら以下の点を理解するものです。
- Databricks Marketplace の使い方【★】
- Shutterstock のデータの扱い方【★】
- 生成AIを活用したノーコードのデータ探索【★】
- 生成AIを活用したノーコードのデータエンジニアリング【◆】
- ベクトル検索によるあいまい検索
- 画像のデータ処理
本書では【◆】の項目について記載します。【★】の内容については以下の記事をご覧ください。
Databricks で自然言語でデータを加工する
Databricks Marketplace から Shutterstock のデータをさわってみる では マーケットプレイスからShutterstock のデータを取得し、データの中身を見てきました。
このノートブックでは、テーブル「set1_image_asset_metadata」「set1_image_file_metadata」とファイル「set1_image_files」をノーコードで加工していきます。
Databricks のノートブック/SQLエディタには以下の図の「水色」と「赤色」の2つの自然言語の機能があります。

水色はアシスタント機能でデータ処理全般を支援してくれます。一方、赤色は日本語で記載した処理の「コードの生成」を行ってくれます。本記事は赤色のコード生成機能を使ってデータ加工を行います。
水色の方は知っていたけど、赤色の方は気が付かなかったという人がチラホラいたので念のための説明でした!
自然言語でどのくらいの処理ができるのか知りたい方もぜひご覧ください。
データの読み込み・結合・書き込み
まず、「set1_image_asset_metadata」「set1_image_file_metadata」を結合してみましょう。
データ探索の結果から「set1_image_asset_metadata」(1000レコード)に対して「set1_image_file_metadata」(2200レコード)の「ASSET_FILE_SIZE」が「medium_jpg」であるレコード(1000レコード)が対応していることがわかりました。
結合後のデータは「image_metadata」テーブルとして「demo_saitouyun」カタログの「demo001」データベースに保存します。
データのロードを自然言語で行ってみましょう。片方のテーブルは必要なレコードのみ抽出します。以下の文言からコードを生成してみましょう。
shutterstock_free_sample_dataset_1000_high_resolution_images_metadata.sample_datasets.set1_image_asset_metadataを読み込んでください。
また、shutterstock_free_sample_dataset_1000_high_resolution_images_metadata.sample_datasets.set1_image_file_metadataを読み込んで、「ASSET_FILE_SIZE」が「medium_jpg」であるレコードのみ抽出してください。
ここで少し補足です。
shutterstock_free_sample_dataset_1000_high_resolution_images_metadata.sample_datasets.set1_image_asset_metadataのようなテーブル名の長いフルネームはカタログからコピペします。

それではコードの生成結果を見てみましょう。うまく生成されているようです。条件句も想定通りに生成されています。

実行してみました。意図した通りデータが読み込まれています。件数も想定通りです。

続いて、読み込んだデータを結合してみましょう。
df_asset_metadata と df_filtered_file_metadata を結合してください。
結合キーすら指定していませんが、しっかりコードを生成してくれました。コード生成時にデータ構造やカタログの情報を参照してくれるようです。

今回は同じカラム名が両方のデータフレームにあり、わかりやすいので結合条件を生成できていますが、もちろん、結合キーが複数ある場合など複雑な場合は自分で指定した方が正確にコードを生成してくれます。
実行してみます。コードは問題なく動きました。

これで、ファイルの説明のメタデータとファイル自体のメタデータが一覧で見られるようになりました。
最後にデータをテーブルとして保存します。
df_joinedを「joined_image_metadata」テーブルとして「demo_saitouyun」カタログの「demo001」データベースに保存してください。
こちらも正しくコードが生成されています。保存方法は指定しませんでしたが、上書き(overwrite)になっています。正確なコードを生成するためには「上書き」か「追記」かは指定しておいた方がよさそうです。

カタログエクスプローラからテーブルが作成されていることを確認できます。

カラムの削除
次に不要なカラムが含まれているため、カラムを削除してみましょう。
以下の文章からコードを生成してみます。
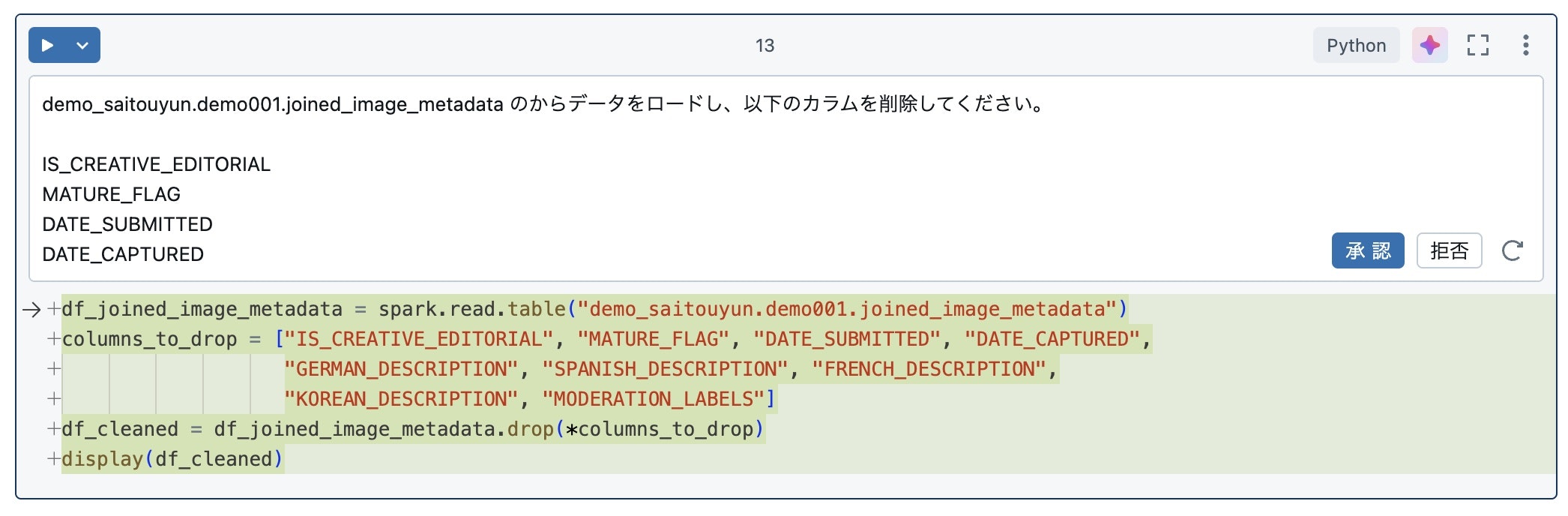
demo_saitouyun.demo001.joined_image_metadata のからデータをロードし、以下のカラムを削除してください。
- IS_CREATIVE_EDITORIAL
- MATURE_FLAG
- DATE_SUBMITTED
- DATE_CAPTURED
- GERMAN_DESCRIPTION
- SPANISH_DESCRIPTION
- FRENCH_DESCRIPTION
- KOREAN_DESCRIPTION
- MODERATION_LABELS
はい、こちらも問題なくコードの生成ができています。実行も問題ありません。
集計と可視化
画像のカテゴリの種類を調べてみます。
df_cleanedの「PRIMARY_CATEGORY」の種類と数を教えてください。
「種類と数を教えて」とお願いすると group by の集計処理を作ってくれます。

実行結果は以下のようになりました。

集計値を直感的に理解するためにグラフ化してみます。「+」から「可視化」からクリックだけでデータの可視化ができます。

人と飲食物の画像が多いことがわかりますね。
コード生成もグラフ化もとても簡単にできるので生産性がとても高まります。
(逆にコードが書けなくなりそうでエンジニア的には怖いですが😅)
データ加工処理
このテーブルの各レコードとボリューム上の画像ファイルをパスで紐付けてみます。
カタログエクスプローラから確認すると、ボリュームのパスは以下の通りになっています。ASSET_ID はレコードごとに変わります。
/Volumes/shutterstock_free_sample_dataset_1000_high_resolution_images_metadata/sample_datasets/set1_image_files/medium/[ASSET_ID].jpg となっています。
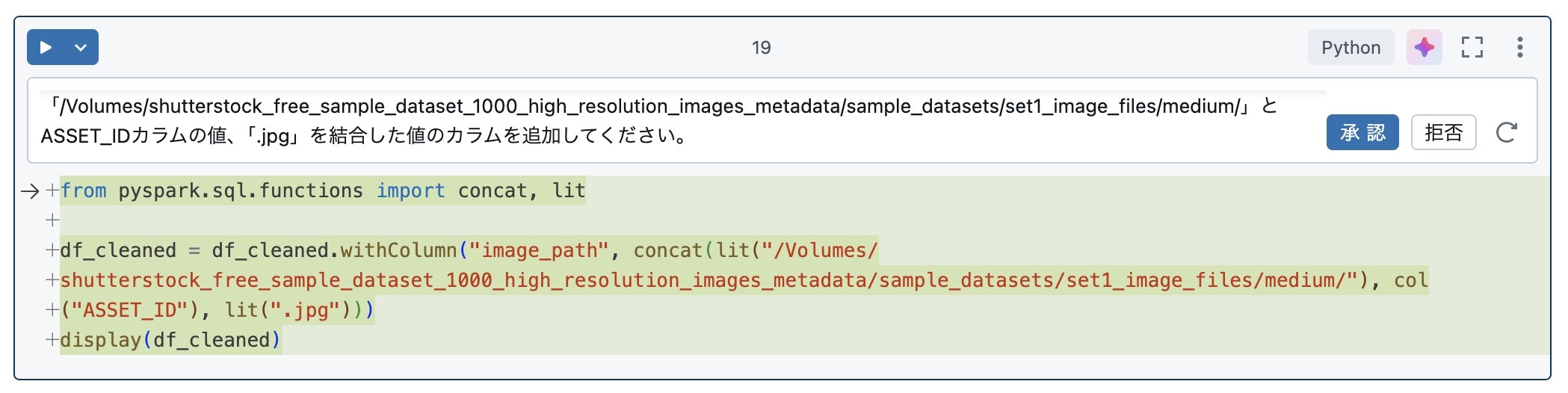
上記のパスの値を持つカラムを作ってみましょう。日本語は以下の通りです。
df_cleanedに「/Volumes/shutterstock_free_sample_dataset_1000_high_resolution_images_metadata/sample_datasets/set1_image_files/medium/」とASSET_IDカラムの値、「.jpg」を結合した値のカラムを追加してください。
コードは以下の通りです。「image_path」とカラム名も適切なものを選んでくれています。固定文字列とカラム含まれる値の文字列の結合処理を正しく生成できています。
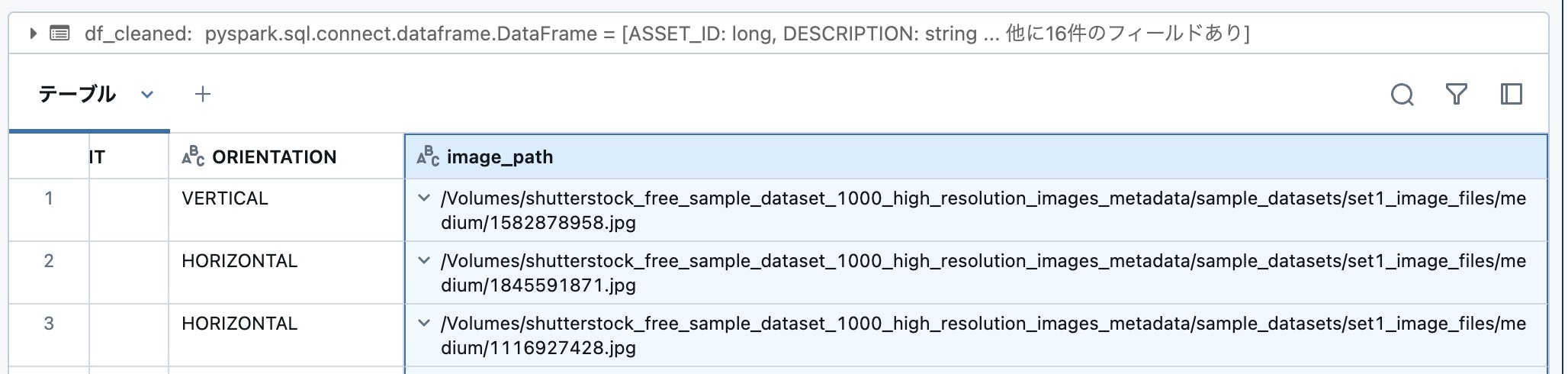
実行してみると、意図した通りに値が作成できています。
最後に加工したデータをテーブルとして保存しましょう。
df_cleanedを「cleaned_image_metadata」として「demo_saitouyun」カタログの「demo001」データベースに保存してください。
先ほどと同様です。

画像の表示
Databricks のボリュームに保存されている非構造化データは Pythonのライブラリから参照可能です。Pythonで画像処理によく使われる PIL を使って画像を表示してみます。
ASSET_ID が 1933559771 の画像を表示したい。df_cleanedのレコードの image_path に画像が保存されているボリュームのパスが記載されています。画像はPILを使って表示してください。
やや複雑な処理なのでプロンプトを丁寧に書く必要がありましたが、Spark / Databricks だけでなくPythonのコードも生成できました。

実行すると画像を表示することができました!

これで、画像のメタデータから参照したいファイルを見つけて画像を表示することができました。
(おまけ) ボリューム上の画像データのテーブル化
画像データのフォルダパスを指定し、フォーマットに「image」を指定することで画像をサムネイル表示することができます。データを一覧で確認したい時に便利です。

画像を含むデータもDatabricksではテーブルとして保存することも可能です。
image_df.write.format("delta").mode("overwrite").saveAsTable("demo_saitouyun.demo001.image_data")
おわりに
このノートブックでは、取り込んだデータをノーコードで加工しました。データの読み取り、フィルタ、結合、カラムの削除、集計、新しい列の追加、書き出しの一通りの操作がノーコードでできることがわかったと思います。
Databricksではコーディングスキルに自信がない人もデータエンジニアリングが簡単にできます!
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。