はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 の nttd-saitouyun です。
AWS Summit Japan で発表された Amazon Bedrock の Claude 3.5 Sonnet が先日、東京リージョンで利用可能になり、大きな盛り上がりを見せています。
今回は、Databricks の Mosaic AI Model Serving Endpoint から Amazon Bedrock の Claude 3.5 Sonnet を利用してみます。
Databricks が目指す 生成AI の世界観
本章は筆者の解釈が含まれる点、ご了承ください。
Databricks では「Compund AI Systems(複合AIシステム)」という考えを発表しています。

これは、様々なタスクに対して1つのモノリシックなAIモデルだけを使うのではなく、タスク1つ1つに対して AIモデル、データ、プログラムなどの組み合わせながら適したものを選択することで、精度、コスト、システムの柔軟性などを向上させる考え方です。

DATA + AI Summit 2024 では、FACTSET社が、Fine-Turning + OSSモデル、RAG + Commercialモデルなどを組み合わせることで精度を高めた事例を発表しています。

Data + AI Summit Keynote Day 1 - Full より
現在、生成AIの活用には以下の例にあるように様々な選択肢が生まれています。
- 大規模・汎用のモデル / 小規模・特化のモデル
- Proprietary、Commercial(GPT、Claudeなど) / Open-Source(Llama、Mistral、DBRXなど)
- RAG / Fine-Turning
-
利用(SaaSとして利用) / 所有(自社環境でホスト)
・・・
Databricks では特定のモデルにロックインをするわけではなく、これらのような選択肢に対して包括的なLLMの活用(LLMOps)機能を提供しています。今回紹介する Mosaic AI Model Serving Endpoint もそのうちの一つです。
参考:
Mosaic AI Model Serving
それでは本題に入ります。
Mosaic AI Model Serving は、AIモデルをサーバレスの環境にデプロイし、APIで利用可能とする機能です。
さらに、今回の Amazon Bedrock のように Databricks の外部のモデルに対しては、外部モデルとのエンドポイントとして機能し、Databricks 内のモデルと同じように外部モデルを集中管理することができます。
Mosaic AI Model Serving Endpoint の作成
左のメニューから「サービング」を選択し、画面右上の「サービングエンドポイントを作成する」をクリックします。

任意の名前を入れます。

続いて、「サービングエンティティを選択」から「外部モデル」を選択し、「プロバイダー」から 「Amazon Bedrock」を選択します。
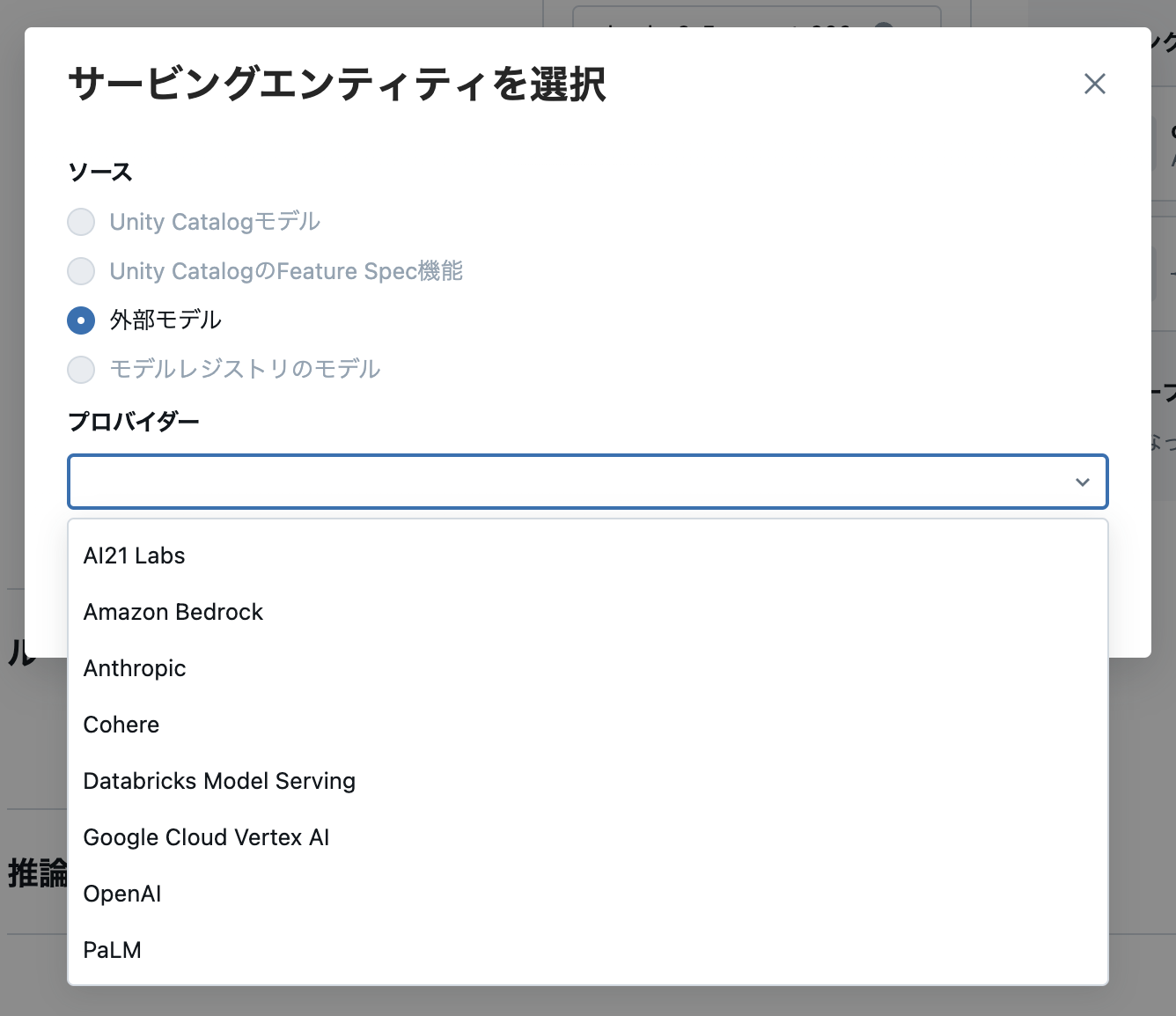
リストにある通り、Azure Open AI、Google Cloud Vertex AI など様々なLLMを選択できます。
リージョンや認証情報、どのモデルを使うか(Bedrockプロバイダー、タスク、外部モデル名)を入力します。

※今回は簡単な検証なので、認証情報をプレーンテキストで保存していますが、本来は Databricks Secret(AWS Secrets Manager 的なサービス)で管理すべきです。
※利用できるモデルはこちらのページです。
設定は以上です。とても簡単です。

Mosaic AI Model Serving Endpoint の動作確認
では、正しく設定できているか動作確認してみましょう。上の図の右上「Query」からサンプルクエリを実行できます。
リクエストはあらかじめテンプレートが埋まっています。疎通するだけであればそのまま「リクエストを送信」をクリックします。レスポンスが正しく返ってくればOKです。

「What is Databricks?」に対して、「Databricks is a cloud-based....」とちゃんと返答が返ってきています!
Mosaic AI Model Serving Endpoint を使いこなす
Mosaic AI Model Serving Endpoint には他にも高度な機能がありますので、紹介します。全てGUIで簡単に設定できます。
権限管理
エンドポイントにクエリできる・できないなどの権限管理を Unity Catalog に統合できます。Amazon Bedrock と Azure Open AI、OSS など複数の LLM を組み合わせながら利用する場合には認証情報や権限を複数プラットフォームにまたがって管理するのは煩雑です。これをDatabricks 上で一元管理することができます。
また、Unity Catalog に統合されているということは、LLM だけでなく、従来の機械学習モデル、データ、ダッシュボードなどを含めて一元管理可能です。

タグ
タグ(属性)をつけてエンドポイントをわかりやすく管理することもできます。
このタグを使って、このエンドポイントのコストを追跡することもできますし、他のエンドポイントをコストをグループ化することもできます。

レート制限
エンドポイントに対するレート管理もできます。この設定を入れておくことで急激な利用による高スト増加を防ぐことができます。

トラフィック制御
実はこのエンドポイントですが、複数のLLMを含めることができ、各LLMへ流すトラフィックの割合を設定することもできます。

例えば、Claude に新しいバージョンがリリースされたとして、エンドポイント自体は変更せず、新しいバージョンをサービングエンティティとして追加して、トラフィックを切り替えてあげれば、プログラムに修正をしないで透過的にバックエンドのLLMを切り替えることもできます。
切り替え方も100:0 を 0:100 に一気に切り替えることもできますし、100:0、80:20、50:50、20:80、0:100 のように影響を見ながら徐々に切り替えることもできます。
商用利用を考えると、このような機能は必要になりますよね。
Mosaic AI Model Serving Endpoint から Amazon Bedrock の LLM を利用する
それでは、エンドポイントを使って色々試してみます。
Mosaic AI Playground で利用する
Mosaic AI Playground は、Databricks がホストする LLM とチャットすることができる機能です。詳しくは以下の記事をご覧ください。
Amazon Bedrock の LLM をエンドポイントに登録することで、Databricks がホストしているLLMと同様にチャットすることができます。
今回は、Meta Llama 3.1 405B、Claude 3 Sonnet、Claude 3.5 Sonnetとチャットしてみます。

以下のような結果になりました。残念ながら Llama の回答は不正解でしたが、Claude の回答は正解でした。Claude 3.5 Sonnet はより情報量多い感じがしますね。

新しくリリースされた LLM をプラットフォームを跨いですぐに比較できるのは便利です!
Databricks SQL AI Functions で利用する
Databricks では、SQL から LLM を呼び出しデータ処理に使うことができます。使い方は簡単で、エンドポイント名とプロンプトを与えるだけです。
SELECT ai_query("aws-tokyo-claude-3-5-sonnet", prompt)
それでは、SQL AI Functions を使ってみます。タスクはマスキングにします。
以下のような架空の個人情報を含む文(山田太郎は〜)を先ほどの Playground を使って生成しました。さらに、この文章の1行目にLLMに対する指示(次の文章の中で〜)を追加しています。
DECLARE OR REPLACE prompt STRING;
SET VAR prompt = "
次の文章の中で、個人情報を氏名であれば[氏名]と、住所であれば[住所]のような汎化した表現に置き換えてください。:
山田太郎は1990年4月1日に渋谷の桜丘町で生まれた。彼は幼い頃から音楽に興味があり、高校時代にはバンドを結成してライブハウスで演奏していた。大学卒業後、音楽の道を追求するためにロサンゼルスに移住し、現在はプロのミュージシャンとして活躍している。
彼の住所は現在、カリフォルニア州ロサンゼルス市ハリウッド区1234 Hollywood Blvd. です。彼は時々日本に戻り、故郷の渋谷区でライブを行っている。
"
結果は以下の通りになりました。意図したように動作しました!

大規模・汎用のLLM を簡単に呼び出せるので、データ処理の幅がグッと広がります。
Databricks SQL AI Functions について詳しく知りたい方は以下の記事もご覧ください。
おわりに
Mosaic AI Model Serving Endpoint を活用することで、Databricks から Amazon Bedrock 上の LLM が簡単に利用できることがわかったと思います。
今回は話題性で Amazon Bedrock Claude 3.5 Sonnet を選びましたが、Azure Open AI、Google Cloud Vertex AI も同様です。この機能はマルチクラウドでより真価を発揮するので今度試してみます。
Amazon Bedrock 自体にも LLMOps機能はありますが、Databricks と組み合わせることで、マルチクラウドを前提としたLLMの利活用環境の構築やモデルやアーキテクチャなど活用方法の選択肢の幅がより広がります!
この生成AI領域は最も勢いのある技術領域です。Databricks を利用し、選択肢や活用の幅を広げてみてはいかがでしょうか?
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。