はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 の nttd-saitouyun です。
今回は、DATA + AI Summit 2024 で発表された Databricks SQL の AI Functions を使って kaggle で公開されているデータを分析してみようと思います。
AI for SQL アナリスト
これまでSQLでAIを利用するには、データサイエンティストがAIモデルをAPI化し、データアナリストがSQLのUDFにAPIを登録をして呼び出すなど、一手間かかっており、データアナリティクス・BIとAIの間には壁がありました。
Databricksでは、AI Functions を活用することでシームレスにAIのパワーをデータアナリティクス・BIに活用することができます。

The Best Data Warehouse is a Lakehouse at DATA+AI Summit 2024
Databricks SQL AI Fuctions によるデータ分析
事前準備
kaggle が公開してる「PII | External Dataset」を活用して個人情報の抽出処理を行います。データはここから入手できます。
「pii_dataset.csv.zip」を解凍、アップロードし、テーブル化しておきます。
データの確認
データの中身を見てみます。textカラムに個人情報を含む長いテキストが含まれています。これらのテキストを識別する一意のIDがdocumentカラムに格納されています。
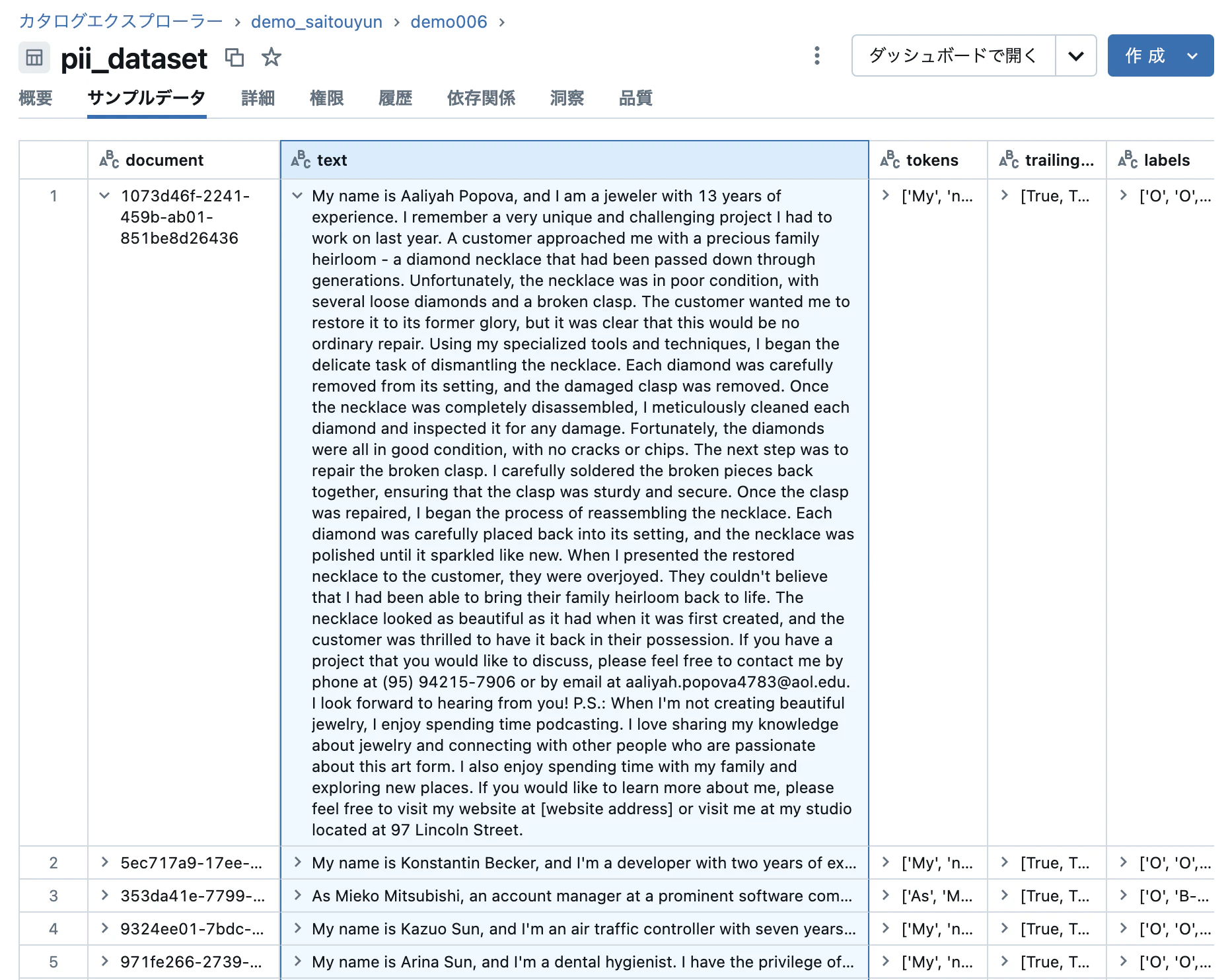
さらにカラムを見ていくと、textに含まれる氏名、メールアドレス、電話番号などの正解ラベルが含まれています。
レコード数は全体で4434ありますが、検証ですので100件に絞ってデータを扱います。
CREATE OR REPLACE TABLE pii_dataset_100 AS
SELECT * FROM pii_dataset LIMIT 100
ai_extract function を活用した情報抽出
ai_extract function を活用してtextカラムの文章から氏名、メールアドレス、電話番号などの情報を抽出してみようと思います。
CREATE OR REPLACE TABLE extract_pii_dataset AS
SELECT
document,
text,
ai_extract(text, array('person', 'email', 'phone', 'job', 'address', 'hobby')) AS extracted_text
FROM pii_dataset_100
データを見てみましょう。JSON形式になっていますが、情報抽出できていそうです。
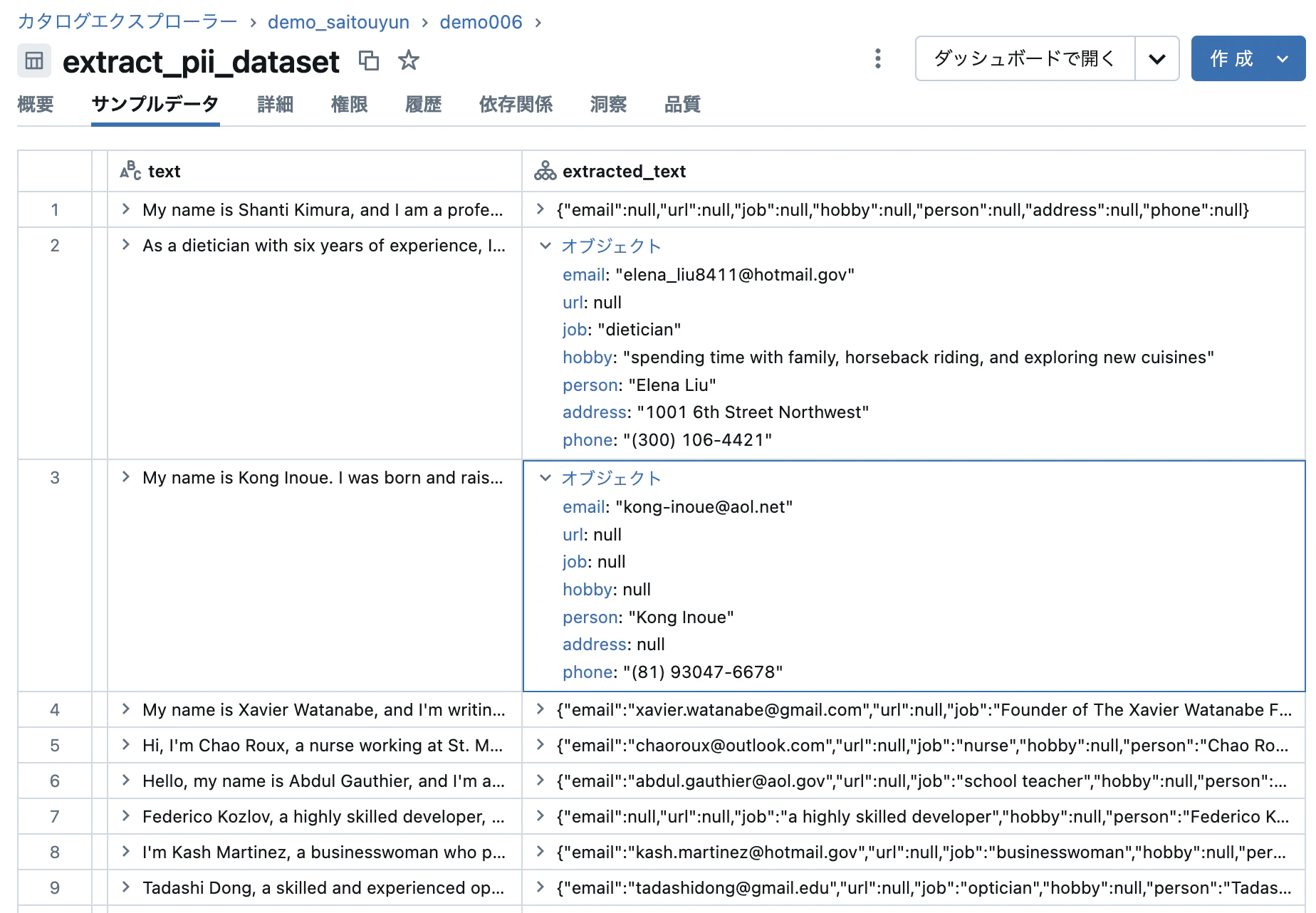
JSONのままだと扱いづらいのでフラット化しておきます。
CREATE OR REPLACE TABLE extract_pii_dataset_clean AS
SELECT
document,
text,
extracted_text.person AS extracted_person,
extracted_text.email AS extracted_email,
extracted_text.phone AS extracted_phone,
extracted_text.job AS extracted_job,
extracted_text.address AS extracted_address,
extracted_text.hobby AS extracted_hobby
FROM extract_pii_dataset
それでは正解ラベルと比較してみましょう。
元のテーブルと結合し、対応するカラムを並べてみます。
CREATE OR REPLACE TABLE compare_data AS
SELECT
p.document,
p.text,
e.extracted_person AS extracted_name,
p.name,
e.extracted_email,
p.email,
e.extracted_phone,
p.phone,
e.extracted_job,
p.job,
e.extracted_address,
p.address,
e.extracted_url,
p.url,
e.extracted_hobby,
p.hobby
FROM pii_dataset_100 p
JOIN extract_pii_dataset_clean e ON p.document = e.document
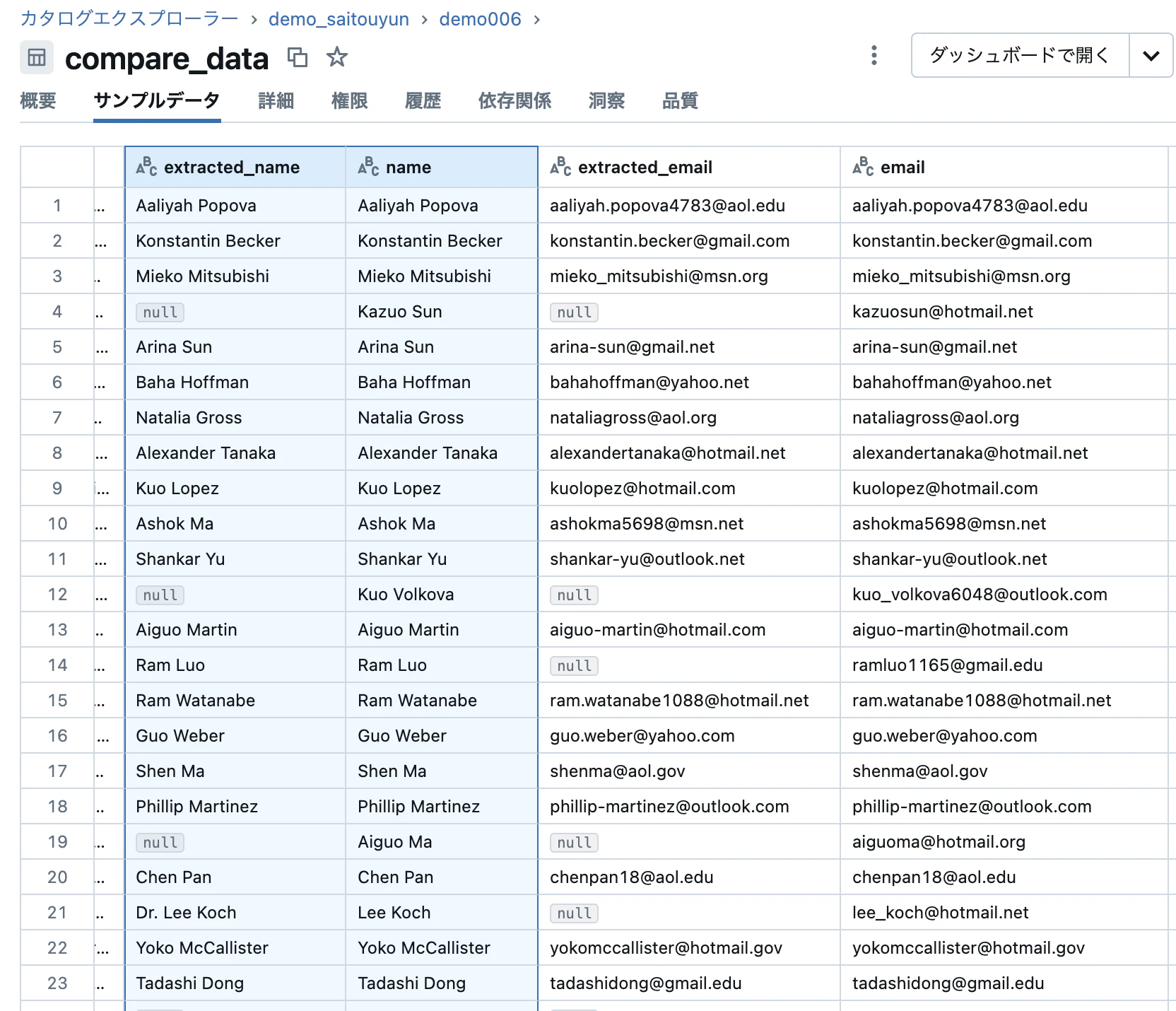
比較結果はこちらです。
うまく情報抽出できていそうですが、一部、nullになってしまい抽出に失敗しているケースもありそうです。
また、21行目のように「Dr.」が含まれてしまっているようなズレもあるようです。
ai_similarity function を活用した類似度の評価
単純なテキストの比較はできないようなので、ai_similarity function を活用し、文章の類似度を計算してみます。
CREATE OR REPLACE TABLE compare_name AS
SELECT
document,
name,
extracted_name,
ai_similarity(name, extracted_name) AS similarity_name
FROM compare_data
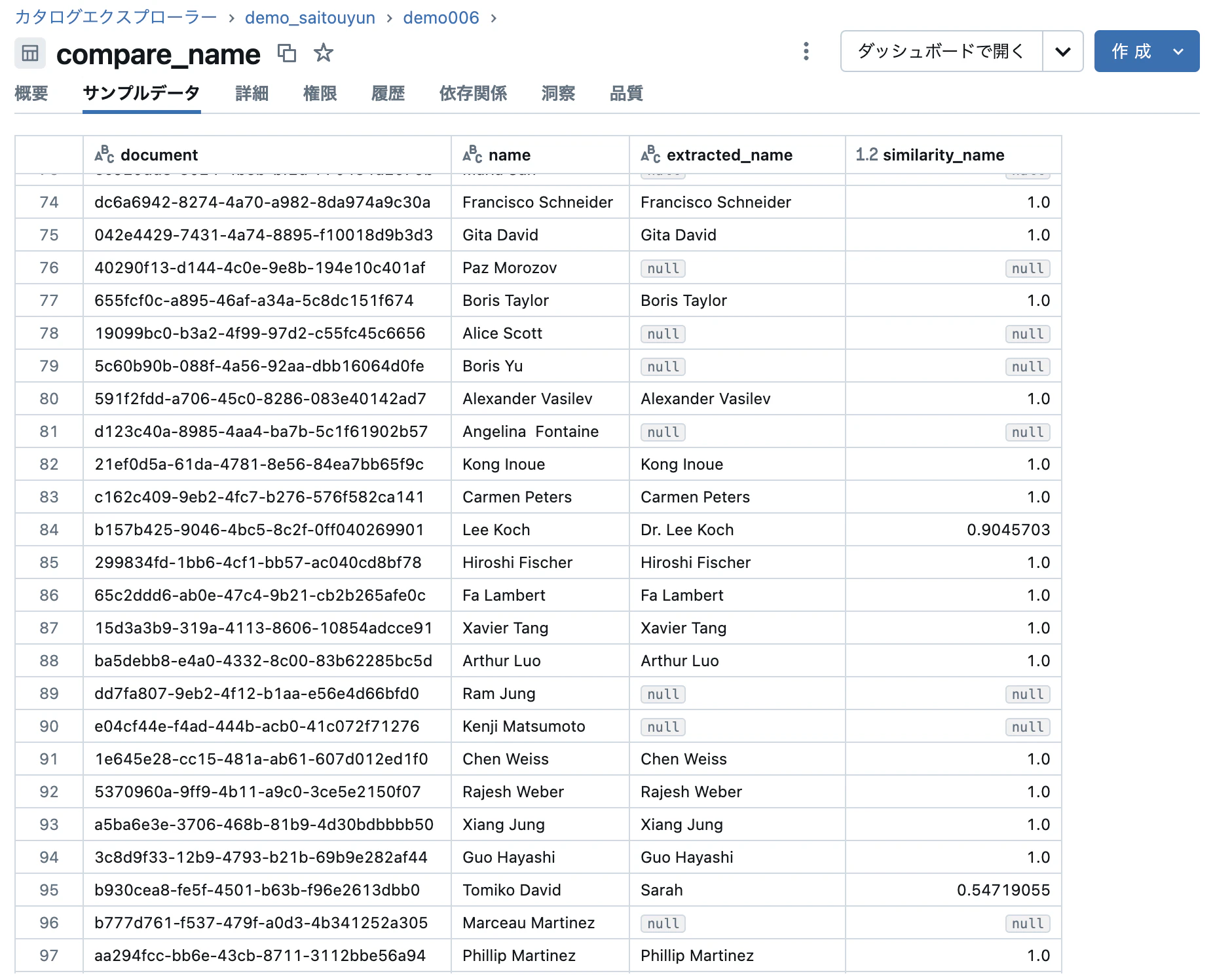
結果は以下のようになりました。文章が一致する場合は「1」に近づき、一致していないと「0」に近づきます。そもそも片方の値がない場合は「null」を取ります。
84行目のように「Dr.」の有無だけであれば、「0.9」とほぼ一致していると判断できそうです。
100レコードあたりで評価してみましょう。
ai_extract function で情報を抽出できたのは、81/100件でした(以下のSQLを実行)。
SELECT COUNT(*) FROM compare_name WHERE extracted_name IS NOT NULL
抽出した情報を ai_similarity function で類似度を計算し(情報を取得できなかった場合(null)は0に換算)、100レコードあたりの平均値を計算すると、0.78となりました(以下のSQLを実行)。
SELECT SUM(similarity_name) / COUNT(*) AS average_similarity FROM compare_name
ここまではnameカラムについて見てきましたが、その他のカラムについても計算すると以下のようになりました。
| カラム | 情報抽出できたレコード数/100件 | 類似度 |
|---|---|---|
| name | 81 | 0.78 |
| 71 | 0.71(抽出できた値は全て一致) | |
| phone | 52 | 0.50 |
| job | 74 | 0.67 |
| address | 63 | 0.61 |
| hobby | 39 | 0.30 |
情報抽出はカラムの内容によって得意・苦手がありそうです。抽出の精度(抽出した文章の類似度)はかなり高い結果になったのではないでしょうか。全体としては60〜80%くらいの正答率になりました。
ai_query function を活用した情報抽出
AI Functions には、ai_query function という基盤モデルにプロンプトを与えて回答を得るという汎用的な関数があります。この関数を使って情報抽出をやってみようと思います。
基盤モデルは最近リリースされた Meta Llama 3.1 405B Instruct を使ってみます。
CREATE OR REPLACE TABLE compare_name_aiquery AS
SELECT
document,
name,
extracted_name,
ai_query("databricks-meta-llama-3-1-405b-instruct", CONCAT('氏名を抽出してください。回答は英語で氏名のみを出力してください。:\n', text)) AS inferred_name,
ai_similarity(name, inferred_name) AS similarity_inferred_name,
ai_similarity(name, extracted_name) AS similarity_name
FROM compare_data
結果は以下の通りになっています。なんと、全てのデータで情報抽出できていました。類似度も基本的には上がっていそうです。(12行目のようにより多くの情報を取り込んでしまって類似度が下がっているケースも稀ながらありそうです。)
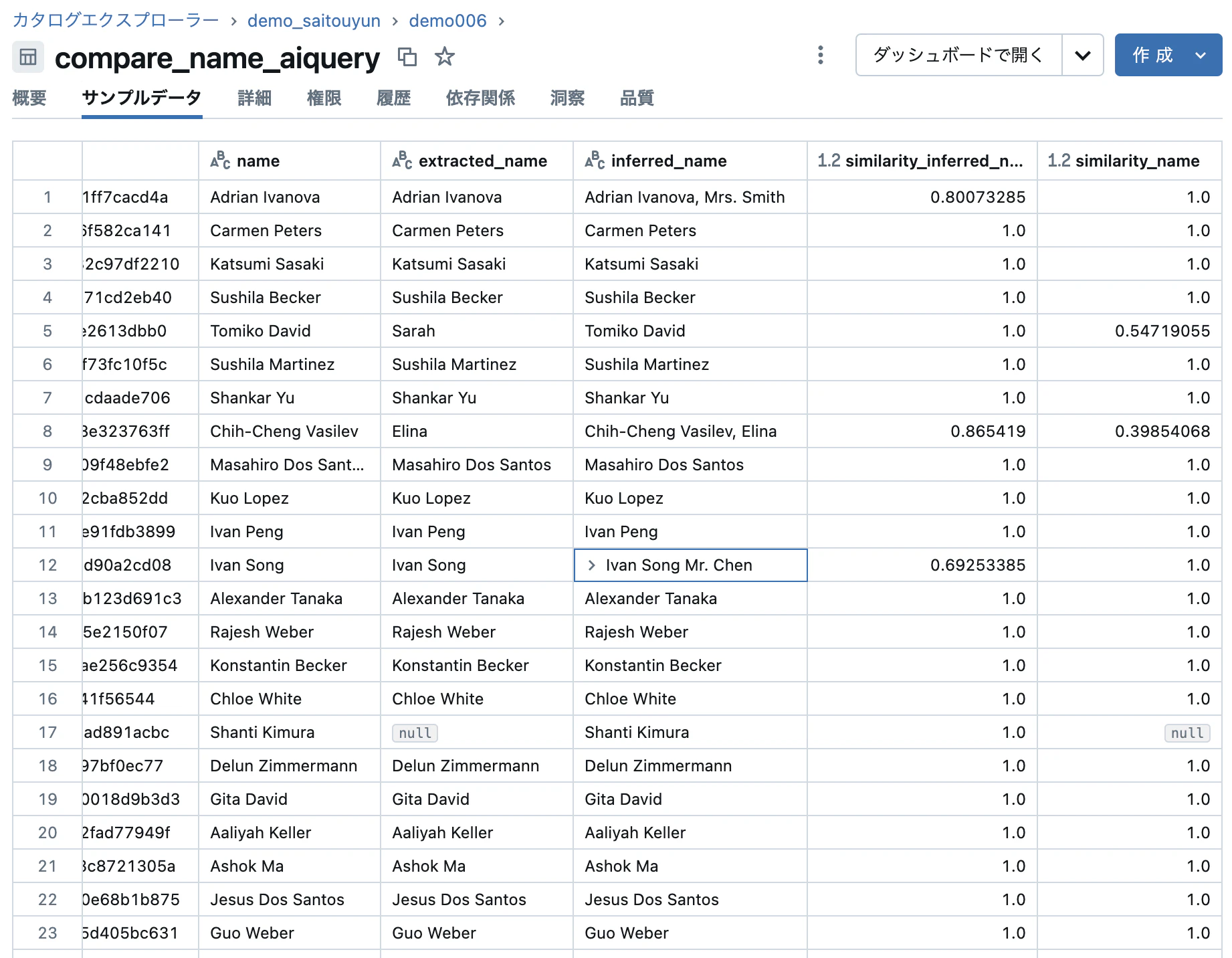
当たり前ですが、パラメータ数が大きい方が精度が高いという結果になりました。この点については、精度とコストのトレードオフを検討する必要がありそうです。
【nameカラムの情報抽出結果の比較】
| 利用したAI関数(LLM) | 情報抽出できたレコード数/100件 | 類似度 |
|---|---|---|
| ai_extract(Mixtral-8x7B Instruct) | 81 | 0.78 |
| ai_query(Meta Llama 3.1 405B Instruct) | 100 | 0.98 |
AI Function を利用する場合はバックエンドのLLMに何が使われているのかしっかり意識した方が良さそうです。マニュアルにも以下のように書いてありますので今後変わる可能性はあります。
Currently, Mixtral-8x7B Instruct is the underlying model that powers these AI functions.
勝手に変わってしまうと困るという話であれば ai_query で LLM を固定するのもありだと思います。
おわりに
いかがでしたでしょうか?
使い慣れたSQLからAIの力を利用することで、高度な分析がこんなに簡単にできることをご理解いただけたのではないかと思います!
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。