はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 の nttd-saitouyun です。
Databricks のリリースノートを振り返っていたところ、2024年7月に、何やらシステムテーブルがたくさんリリースされていました。今回は Node timeline システムテーブル を触ってみます。

他のテーブルについてはこちらです。
アップデート内容
アップデートは以下でした。
Node timeline system table is now available (Public Preview)
[July 23, 2024]
The system.compute schema now includes a node_timeline table. This table logs minute-by-minute utilization metrics for the all-purpose and jobs compute resources run in your account. See Node timeline table schema.
コンピュートシステムテーブルに新しく Node timeline テーブルが追加されたようです。

コンピュートシステムテーブル
あまり馴染みがないと思うので、一通りのテーブルの概要を見ておきます。
コンピュートシステムテーブルの情報は汎用コンピュート、ジョブコンピュートを対象としており、サーバレスやSQLウェアハウスの情報は載らないでご注意ください。
clusters テーブル
マニュアルには以下の通りの説明が載っています。
コンピュート設定をアカウントに記録します。
クラスタの定義情報が保存されているテーブルで、メニューバーの 「クラスター」から参照できる情報と同等のデータを保持しています。誰が、いつ、どのような定義のクラスターを作ったのかなどがわかります。
特徴としてはワークスペース横断でこれらの情報を参照することができます。
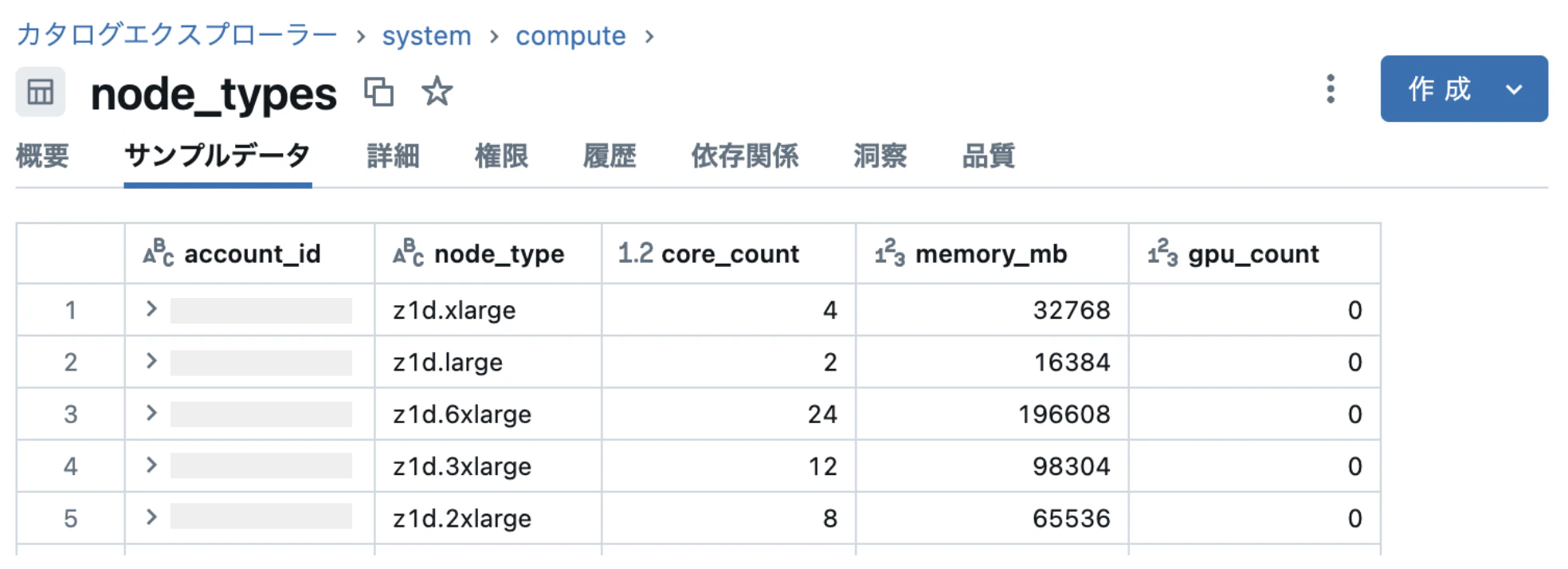
node_types テーブル
マニュアルには以下の通りの説明が載っています。
ハードウェア情報を含む、現在使用可能なノード タイプごとに 1 つのレコードが含まれます。
インスタンスタイプごとのコア数、メモリ量、GPU数などのノードのスペック表のようです。ユーザが設定するような内容は載っていません。
node_timeline テーブル
新しくリリースされたテーブルです。
マニュアルには以下の通りの説明が載っています。
コンピュートの使用状況メトリクスの分単位の記録が含まれます。
詳しくは次の章で見ていきます。
Node timeline システムテーブル(system.compute.node_timeline)
テーブルの詳細は以下のページにまとまっています。
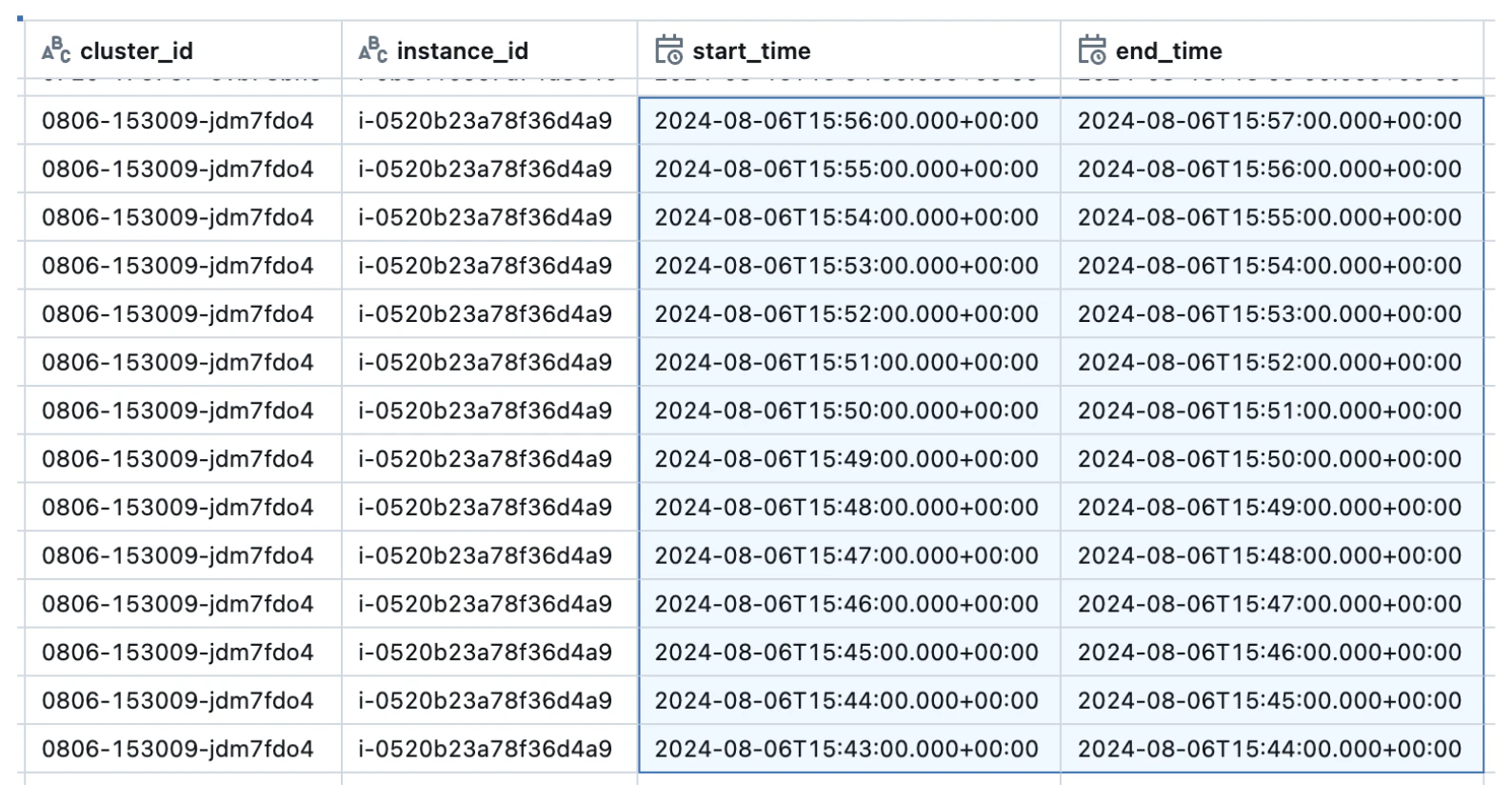
実テーブルのイメージは以下の通りです。クラスタを構成するインスタンスごとにCPU、メモリ、ネットワーク、ディスク容量などの使用量が記録されています。Linuxなどのコマンドでリソース使用量を見たことがある方であればすぐに内容がわかると思います。sar、vmstat、dfなどのコマンドの出力に似てますね。
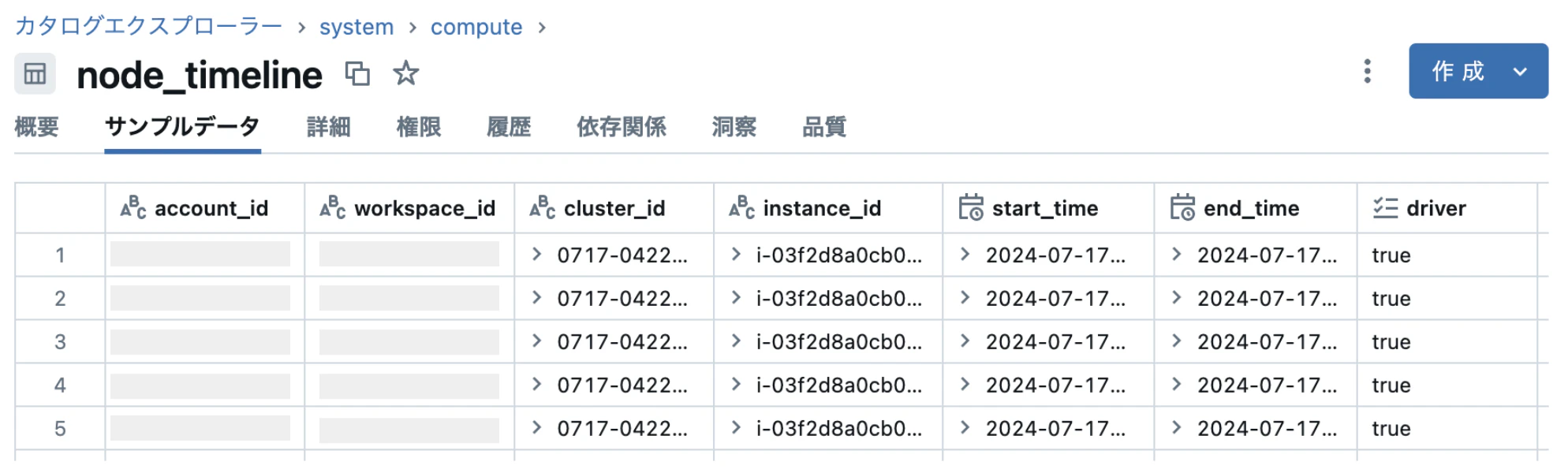
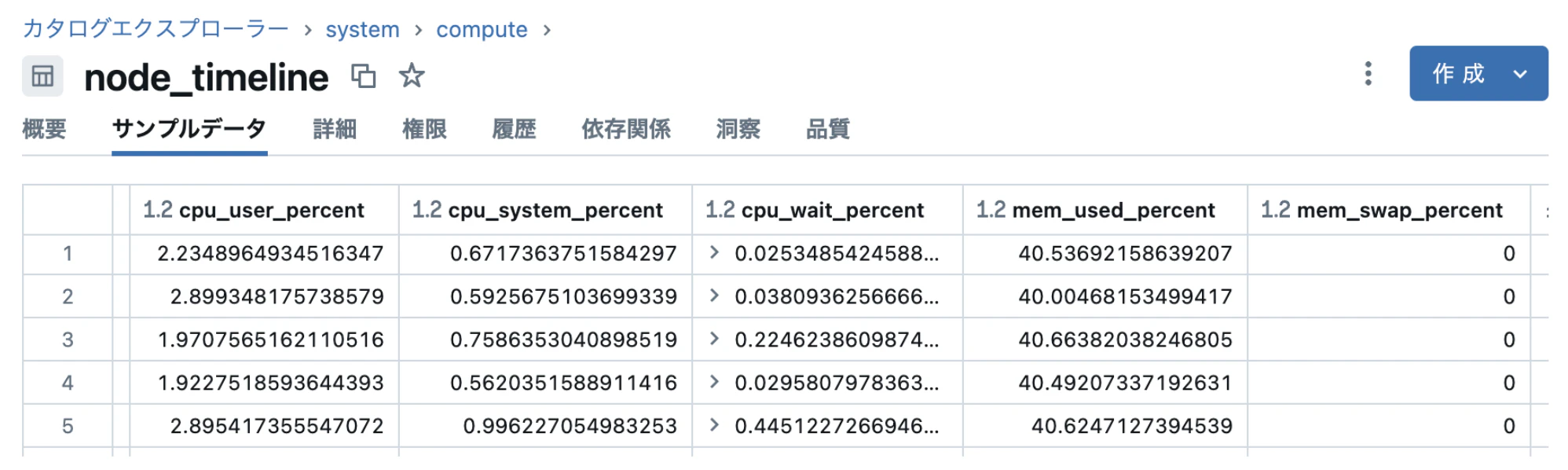
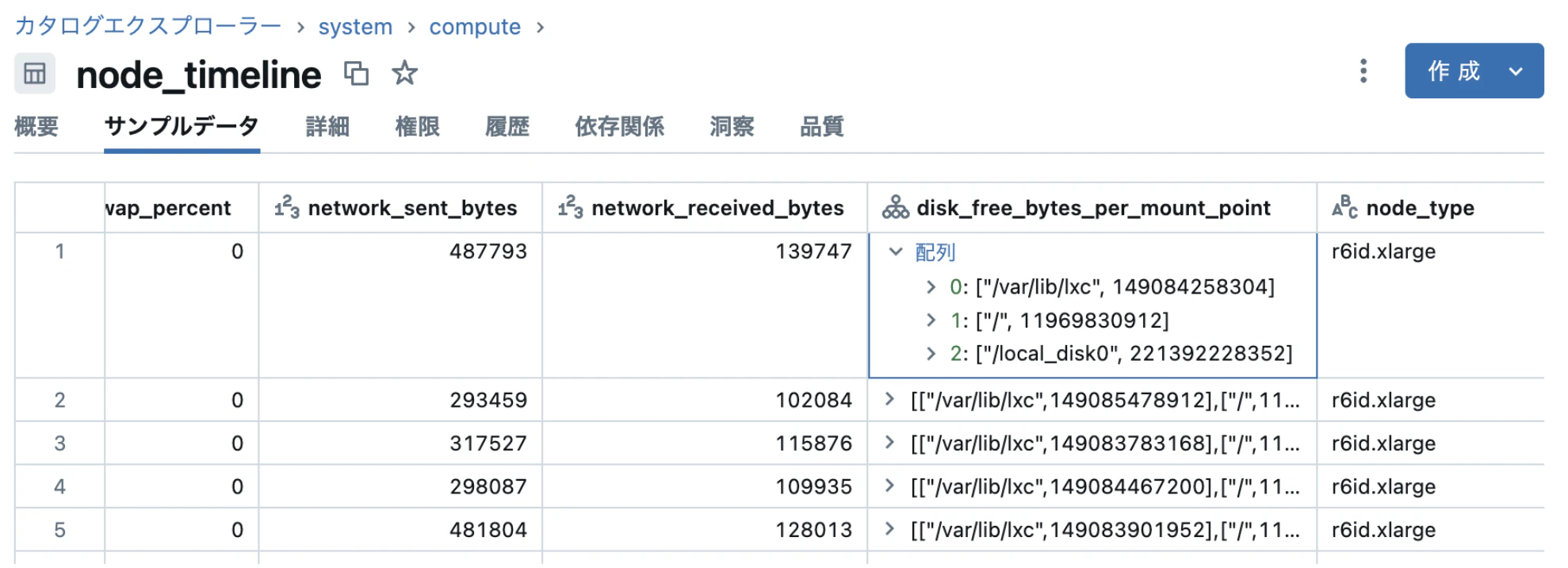
この情報は以下のように1分間隔で出力されているおり、時系列でリソースの推移を追うことができます。
各クラスタの「メトリクス」タブから同様の情報を参照することができます。こちらの方が情報量は多いです。
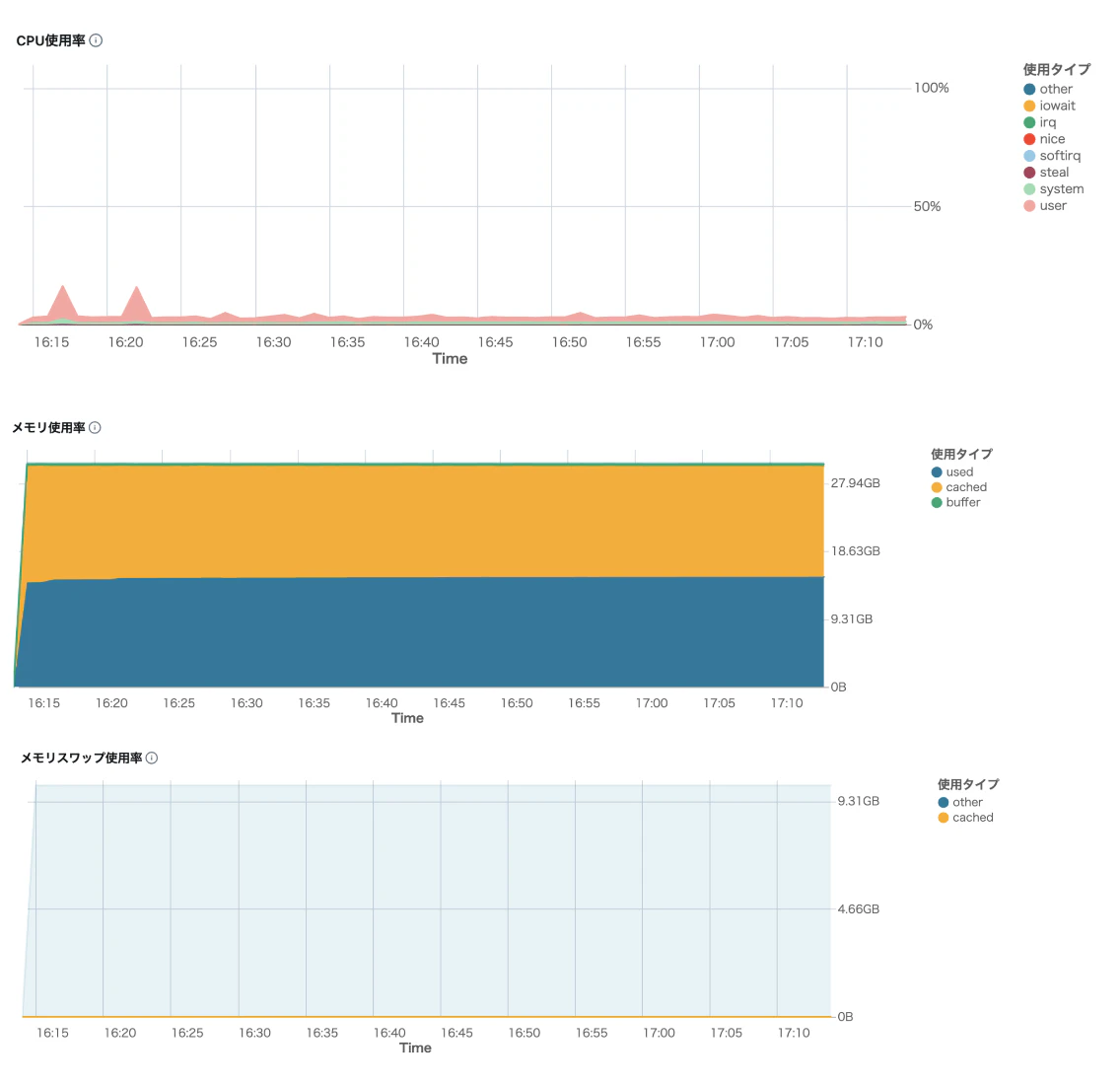
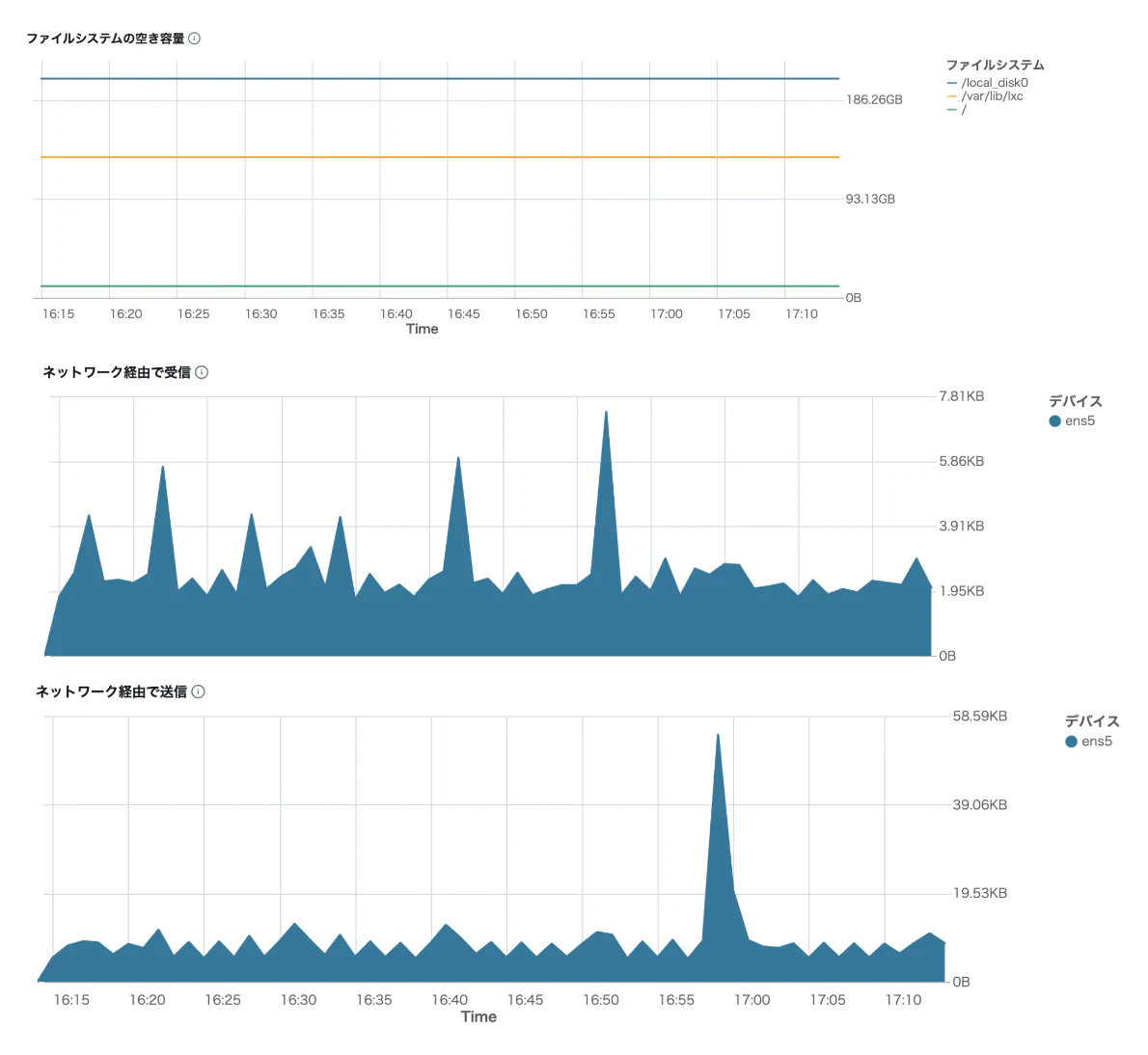
単純な障害解析はこちらの情報を見た方がグラフィカルなのでわかりやすいと思います。
一方で、Node timeline システムテーブルによって以下のことができるようになったのではないかと思います。
【カスタム監視】
リソース情報のデータが入手できるようになったので、上記のようなダッシュボードを自身でカスタマイズして作ることができます。
【複数クラスタの比較】
メトリクスタブは対象のクラスタの情報のみしか表示できません。複数クラスタの情報を1つグラフで表現する場合は本テーブルを活用する必要があります。
【過去データの分析】
メトリクスタブの情報は30日しか参照できないため、長期的に各クラスタ/ノードのリソースを分析したい場合には役立ちそうです。コンピュートシステムテーブルは保持期間が無期限なのでいつでも過去の情報に遡ることができます。
利用上の注意点
-
タイムゾーン
日付カラムのタイムゾーンは UTC なので、JST として表示するためには、+9 時間を忘れないようにしましょう。 -
データの取得条件
以下の点マニュアルに記載がありました。ノードの起動時間が短いとデータが取得されないようです。
実行時間が 10 分未満のノードは、 node_timelineテーブルに表示されない可能性があります。
Node timeline システムテーブル を触ってみる
それでは、Node timeline システムテーブルを触ってみます。
まずデータを読み込んでみます。
node_timeline_df = spark.read.table("system.compute.node_timeline")
display(node_timeline_df)
実行結果は以下の通りです。
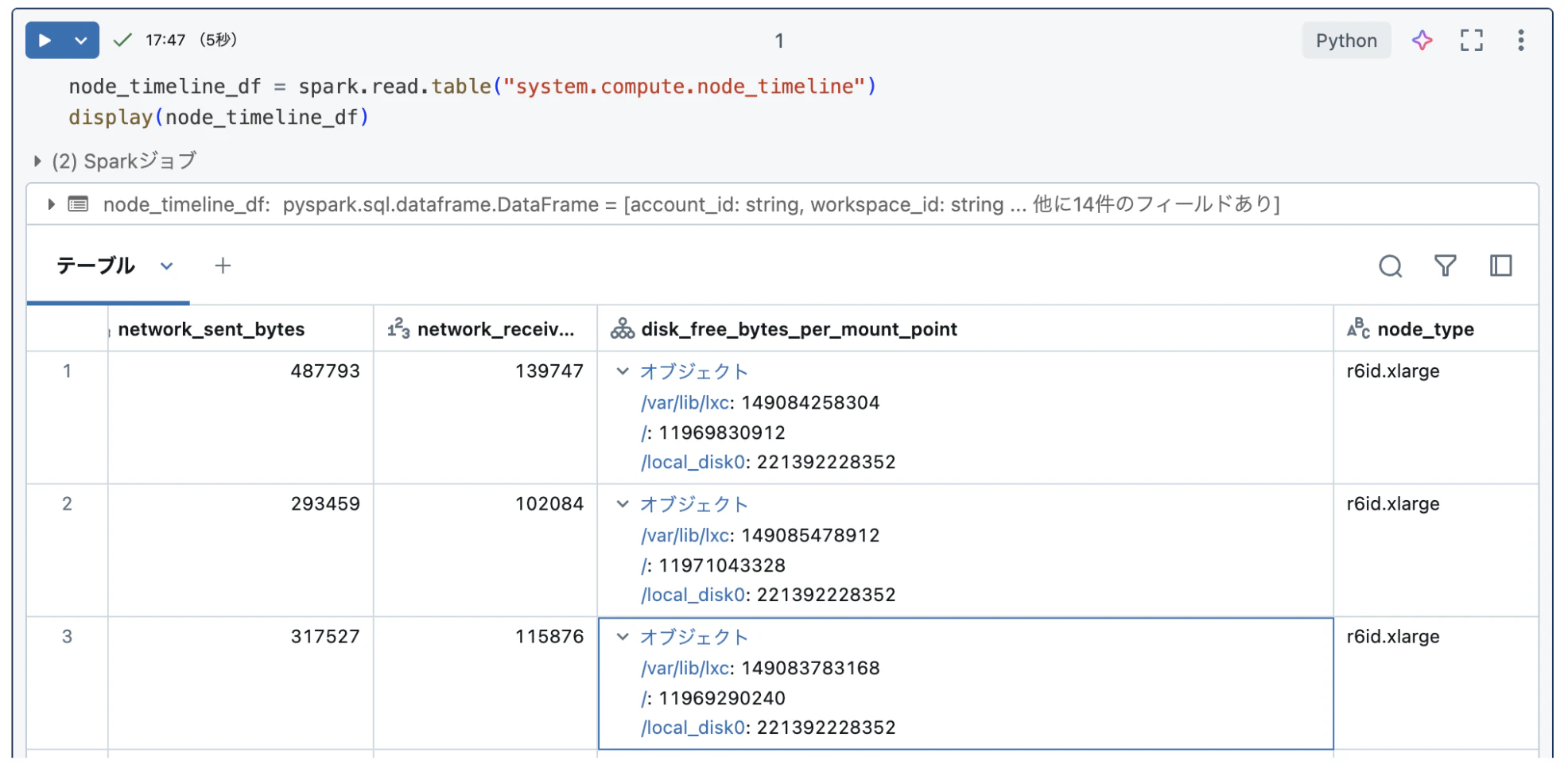
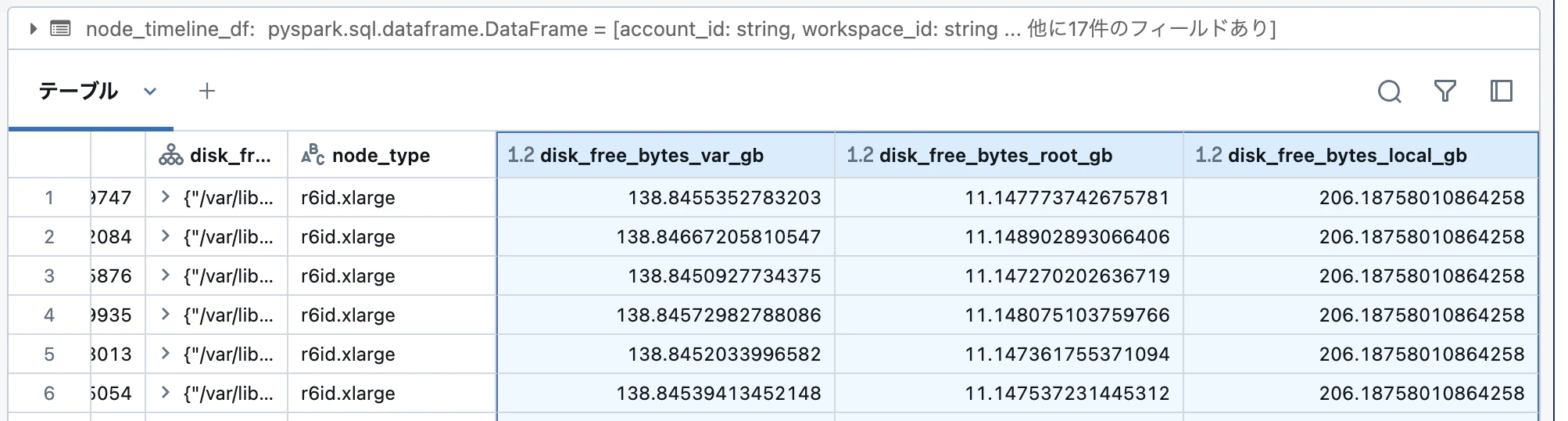
読み込めましたが、ディスクの情報が配列になっているので展開しておきます。(ついてで単位をByteからGBに変換しておきます。)
node_timeline_df = ( node_timeline_df
.withColumn("disk_free_bytes_var_gb", node_timeline_df.disk_free_bytes_per_mount_point["/var/lib/lxc"] / (1024 ** 3))
.withColumn("disk_free_bytes_root_gb", node_timeline_df.disk_free_bytes_per_mount_point["/"] / (1024 ** 3))
.withColumn("disk_free_bytes_local_gb", node_timeline_df.disk_free_bytes_per_mount_point["/local_disk0"] / (1024 ** 3))
)
display(node_timeline_df)
無事に以下のように展開できました。
Node timeline システムテーブルだけだと、クラスタに関する情報が少ない(クラスタ名や作成者の情報がない)ので、Clusters システムテーブルと結合しておきます。
Clusters システムテーブルを読み込んで、
clusters_df = spark.read.table("system.compute.clusters")
clusters_df = ( clusters_df
.withColumnRenamed("account_id", "account_id_cls")
.withColumnRenamed("workspace_id", "workspace_id_cls")
.withColumnRenamed("cluster_id", "cluster_id_cls")
)
ワークスペースIDとクラスタIDをキーに結合します。
joined_df = (
node_timeline_df.join(
clusters_df,
(node_timeline_df.workspace_id == clusters_df.workspace_id_cls) &
(node_timeline_df.cluster_id == clusters_df.cluster_id_cls),
"inner"
)
.drop("account_id_cls", "workspace_id_cls", "cluster_id_cls")
)
display(joined_df)
※現在は、Node timeline システムテーブルはリリースされたばかりでありデータ量が少ないですが、保存期間が無制限であるため、今後テーブルが巨大化することが予想されます。そのため、上記のように条件指定なしに結合すると大規模な処理になる可能性がある点ご注意ください。
結合できたので、ユーザ名で自分が所有者のクラスタの情報を絞ったりすることができます。では、やってみます。
demo_user_df = joined_df.filter(joined_df.owned_by == "demo.saitouyun@gmail.com")
自分がどのようにクラスタを使っているのかを見てみます。
display(demo_user_df.groupBy("cluster_id", "instance_id").count())
以下のような結果になりました。
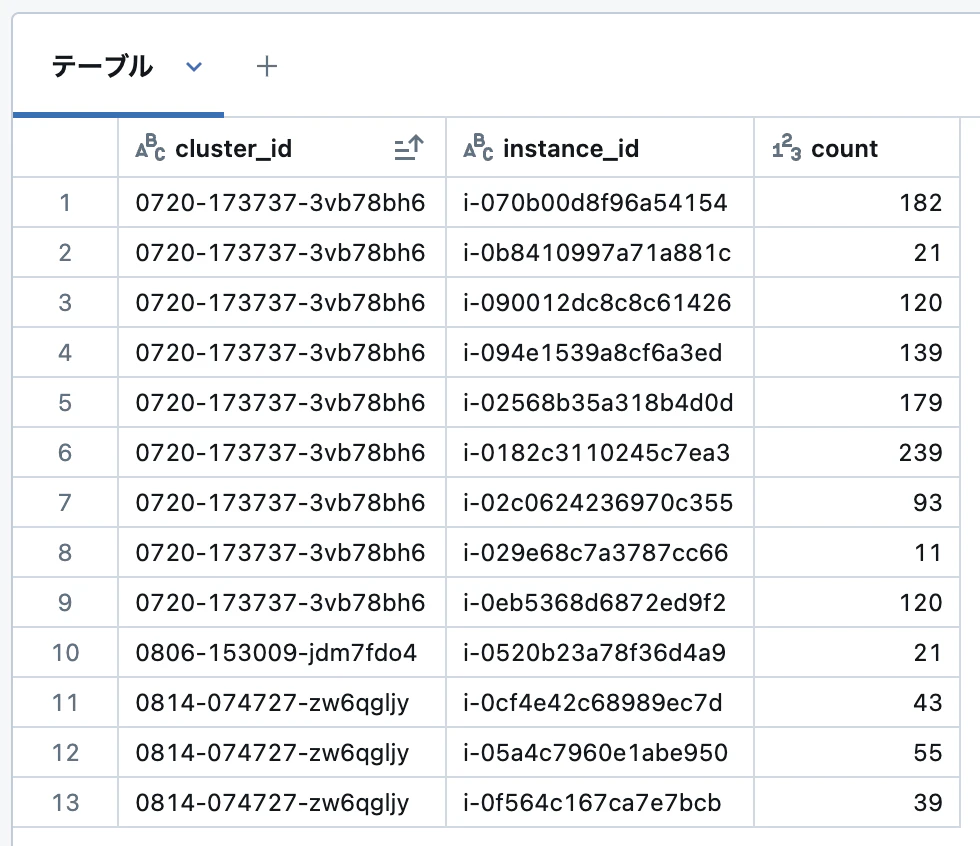
- 3種類のクラスタを使っていること(cluster_id の数)
- 1番上のクラスタを9回、2番目のクラスタを1回、3番目のクラスタを3回使っている(instance_id の数)
- 1回の起動で4時間以下の利用をしている(1レコード=1分なのでレコード数のカウントで大体の稼働時間がわかる)
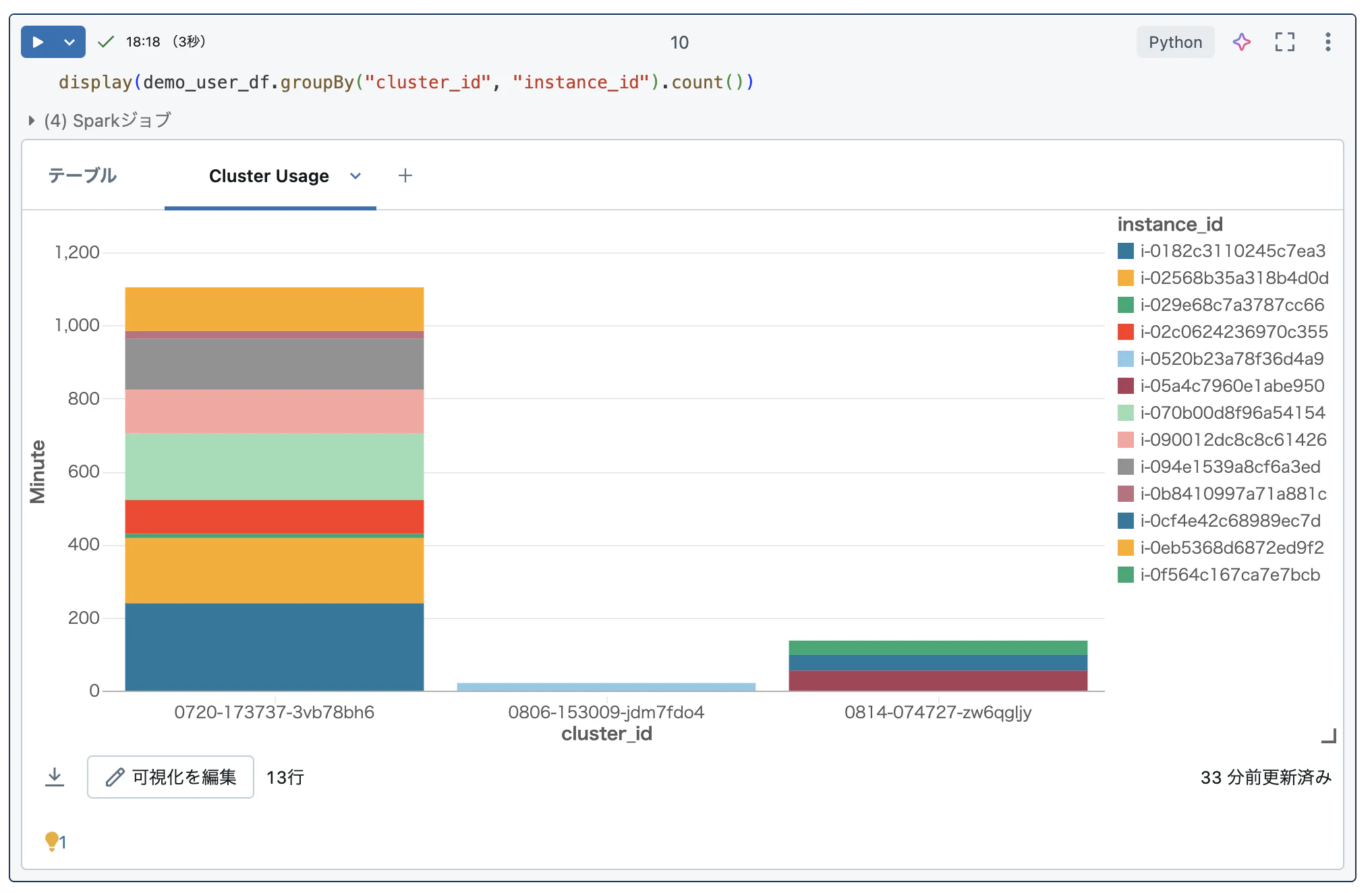
ということがわかりました。グラフ化してみるとよりわかりやすいです(↓)。
次に特定のクラスタの情報を見てみます。
display(demo_user_df.filter(
(demo_user_df.cluster_id == "0720-173737-3vb78bh6") &
(demo_user_df.instance_id == "i-070b00d8f96a54154")
)
)
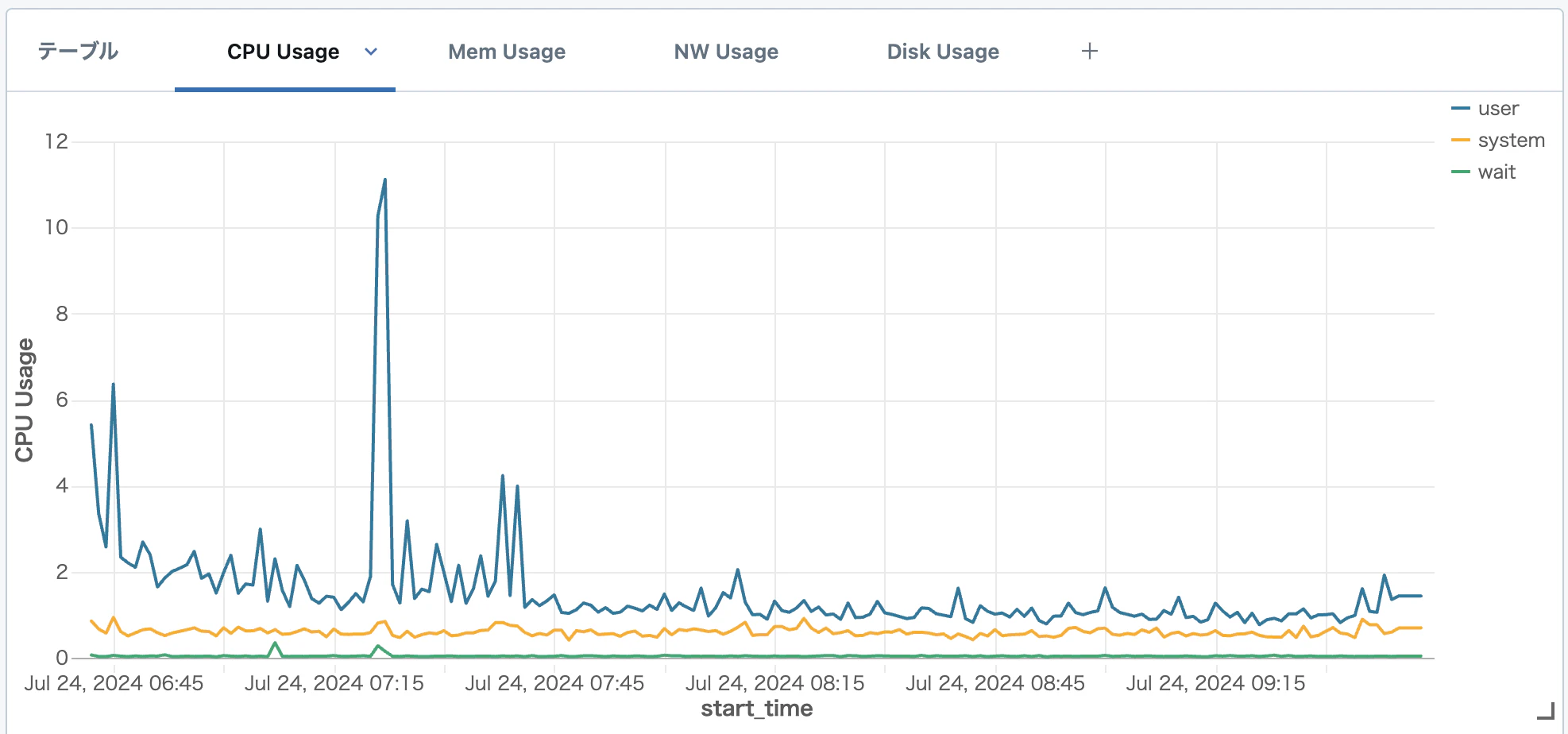
以下のような形で、クラスターのメトリクスタブと同等のダッシュボードを簡単に作ることができました。(デモを作ったり行っている環境なので面白グラフにはなりませんでしたが)
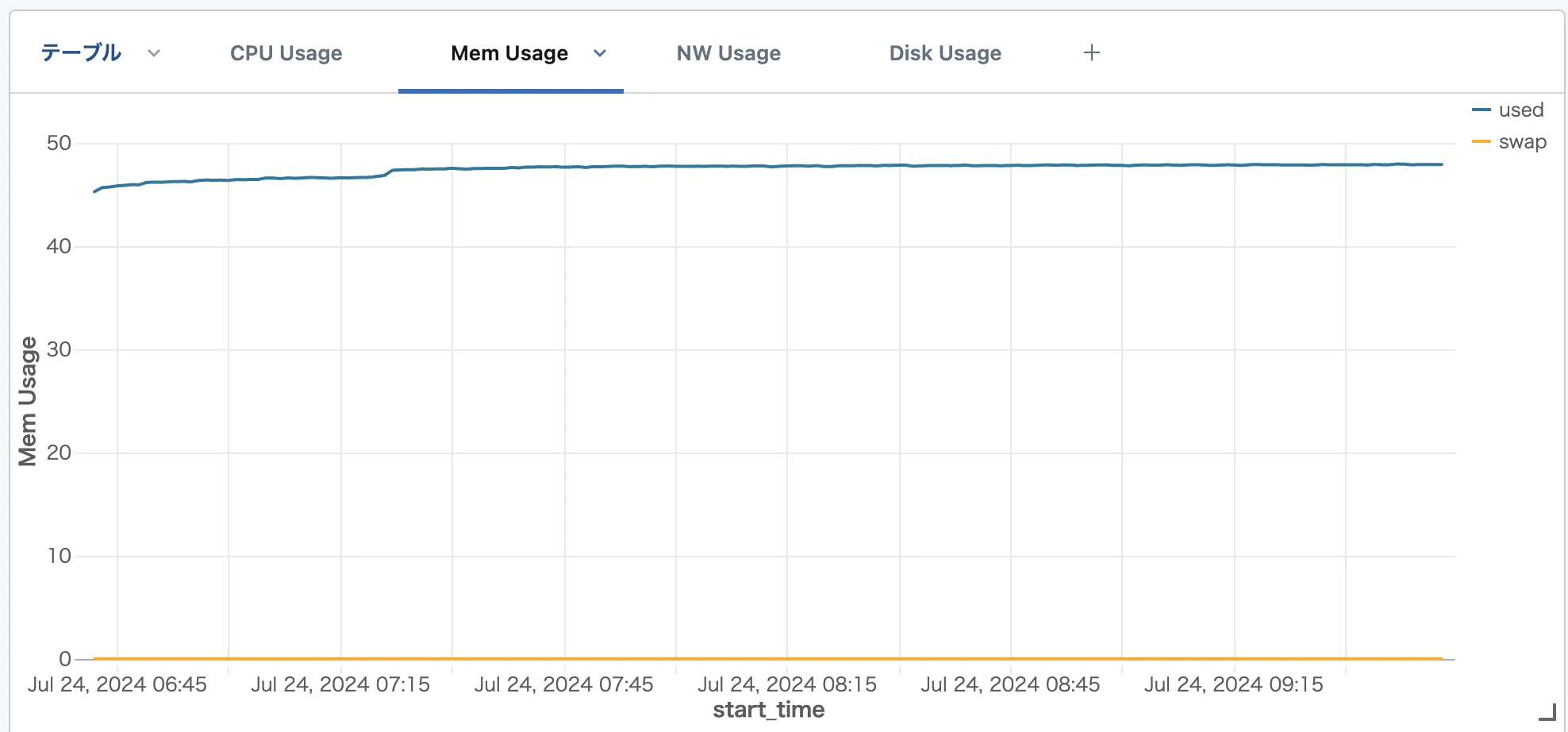
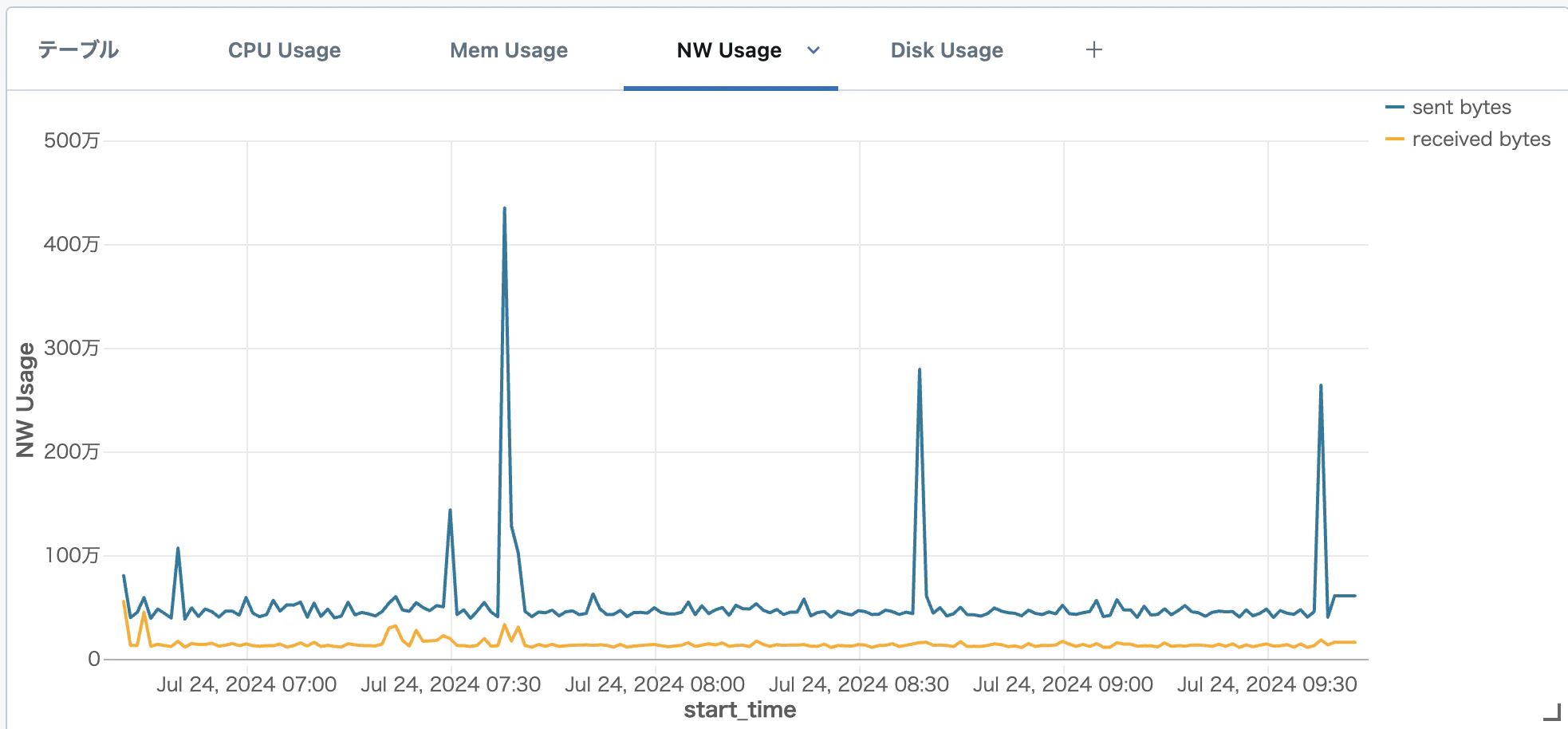
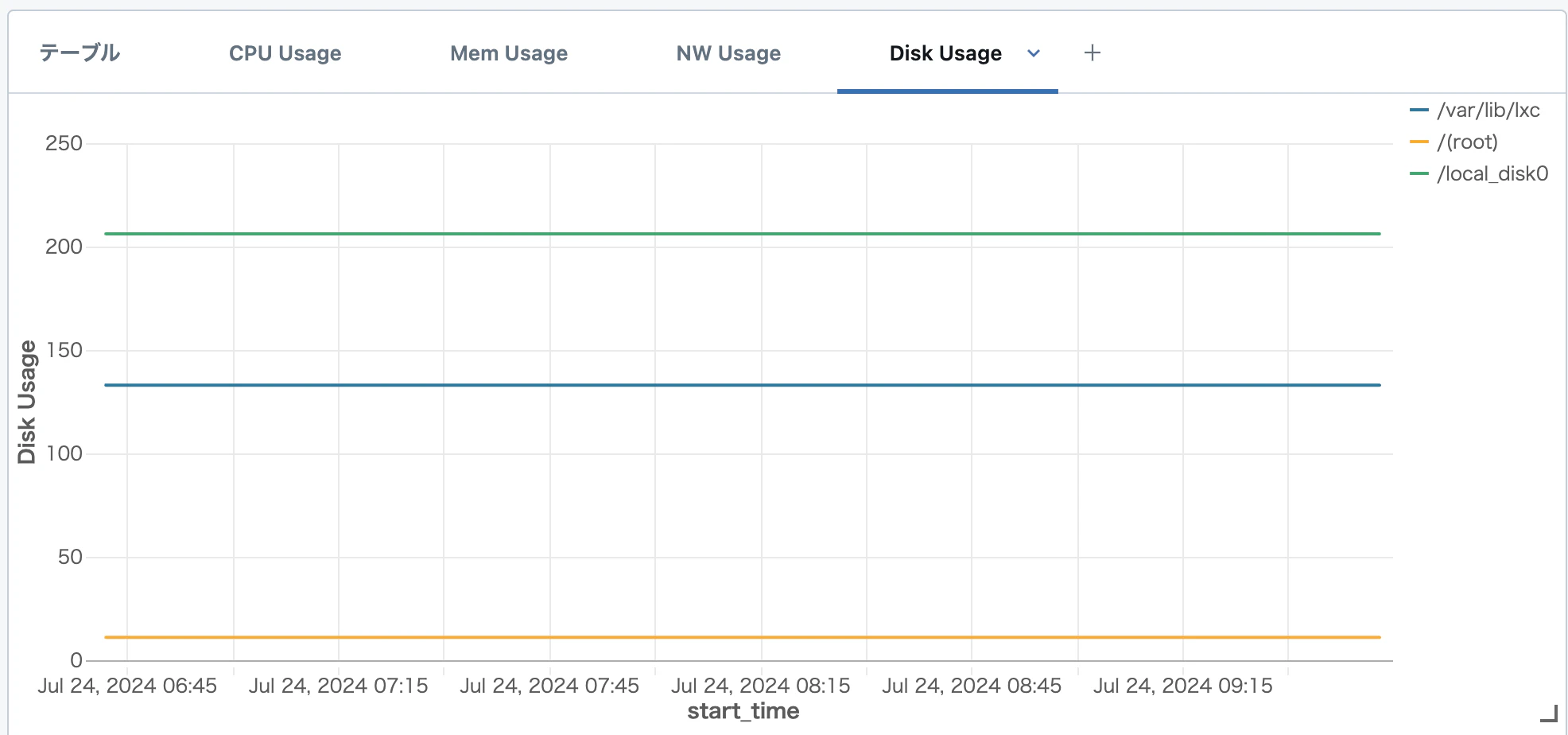
最後に複数クラスタにまたがったグラフを作ってみます。
display(demo_user_df)
で自分のクラスタのデータを表示して、cluster_id でグループ化して、メモリの使用量をグラフ化してみました。
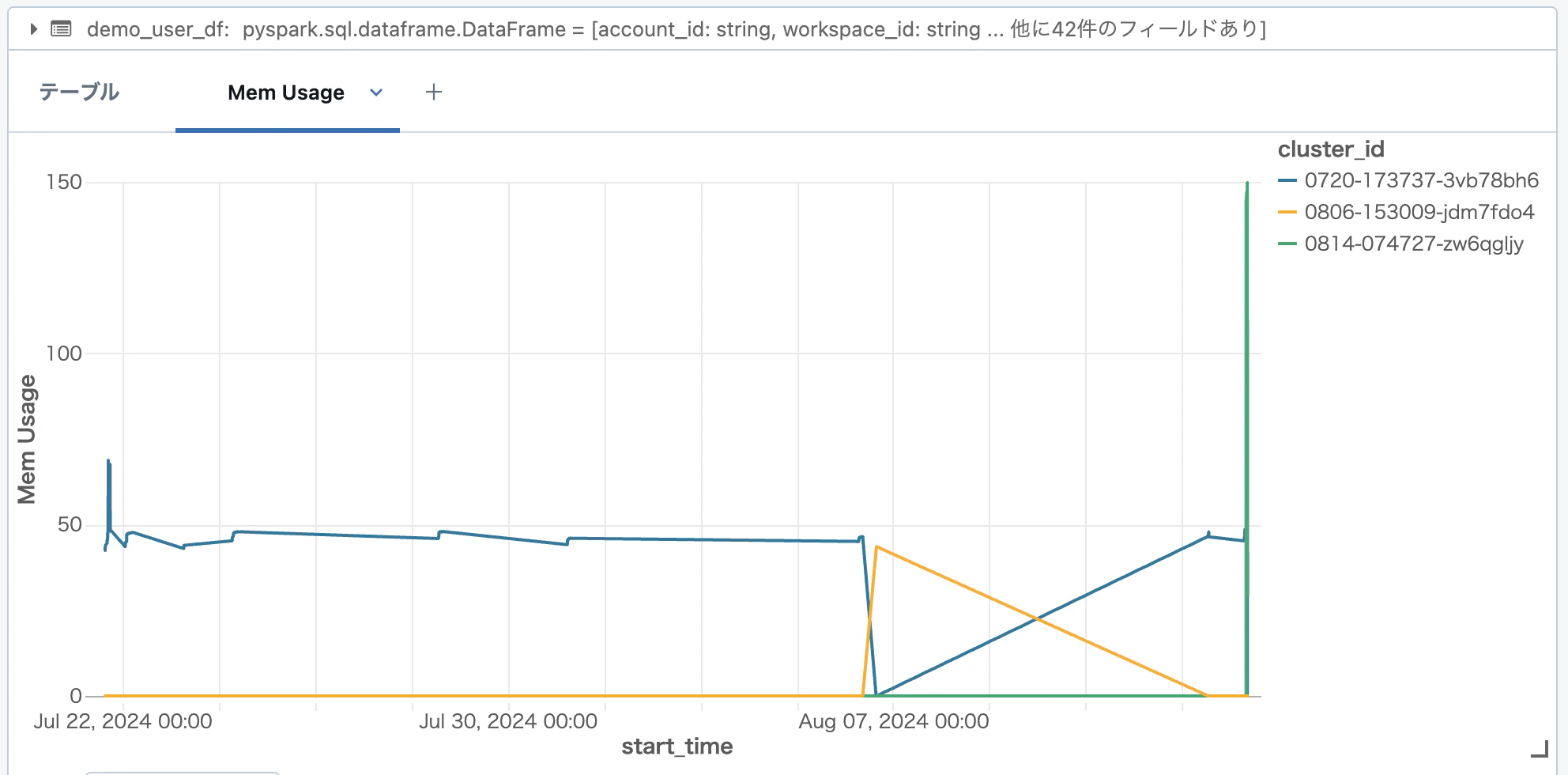
複数クラスタで同時に処理をしているわけではないので「いい感じ」のグラフではないのですが、いつどのクラスタを使っていたのかはパッとわかります。
おわりに
Node timeline システムテーブル とその使い方についてみてきました。
クラスタの利用状況を分析するためには有用なシステムテーブルでした。
データ分析環境の利用状況の把握はデータの利活用において重要です。本書がその一助になれば幸いです。
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。