はじめに
株式会社NTTデータ テクノロジーコンサルティング事業本部の@nttd-kashiwabarayです。
AWS DeepRacerをAWSマネージメントコンソールから利用できるのも残り1か月間となりました。ぜひこれまで取り組んできた方もまだやったことがない方もぜひ残り1か月楽しんでいただけたらと思っています。
現在もPractice Raceが開催されており、世界のトップレーサーたちも参戦しておりますので、ぜひチャレンジしてみてください。
なお、5月に「AWS DeepRacerで学ぶ 強化学習」という本も出版されておりますので、合わせてご覧ください。
AWS DeepRacerで学ぶ 強化学習

本ブログでは、「概要編」、「AWSマネージメントコンソール編」、「ローカルトレーニング編」として3回に渡って、AWS DeepRacerの魅力、トレーニング方法などをお伝えします。
前回の「概要編」、「AWSマネージメントコンソール編」に続いて、「ローカルトレーニング編」をお届けします。
ローカルトレーニング環境のインストール
まずはローカルトレーニングを実施するにあたっては、環境の構築・インストールが必要となります。具体的な環境構築方法は書籍に載せておりますし、ネット上にも情報があるかと思いますので、調べていただきながら実施してください。書籍の中では、EC2起動テンプレートを活用して、EC2上に構築を実施しております。
なお、推奨スペックについては以下の通りとなります。EC2のインスタンスタイプはGPUを活用する場合はG3、G4、G5、P2、P3タイプといったGPUインスタンスの活用が必要で、g4dn.2xlargeが推奨されます。GPUを活用しない場合はC5もしくはM6タイプを選択します。c5.2xlargeが推奨となります。
OS:Ubuntu 20.04
OSディスク:40GB(最小30GB)
GPU:8GBRAM ※GPUで実行する場合
CPU:6vCPU以上
ローカルトレーニングのパラメータ
環境構築後は設定ファイル(system.envおよびrun.env)の各パラメータの設定を行います。以下はインストール時の設定ファイルの内容となります。
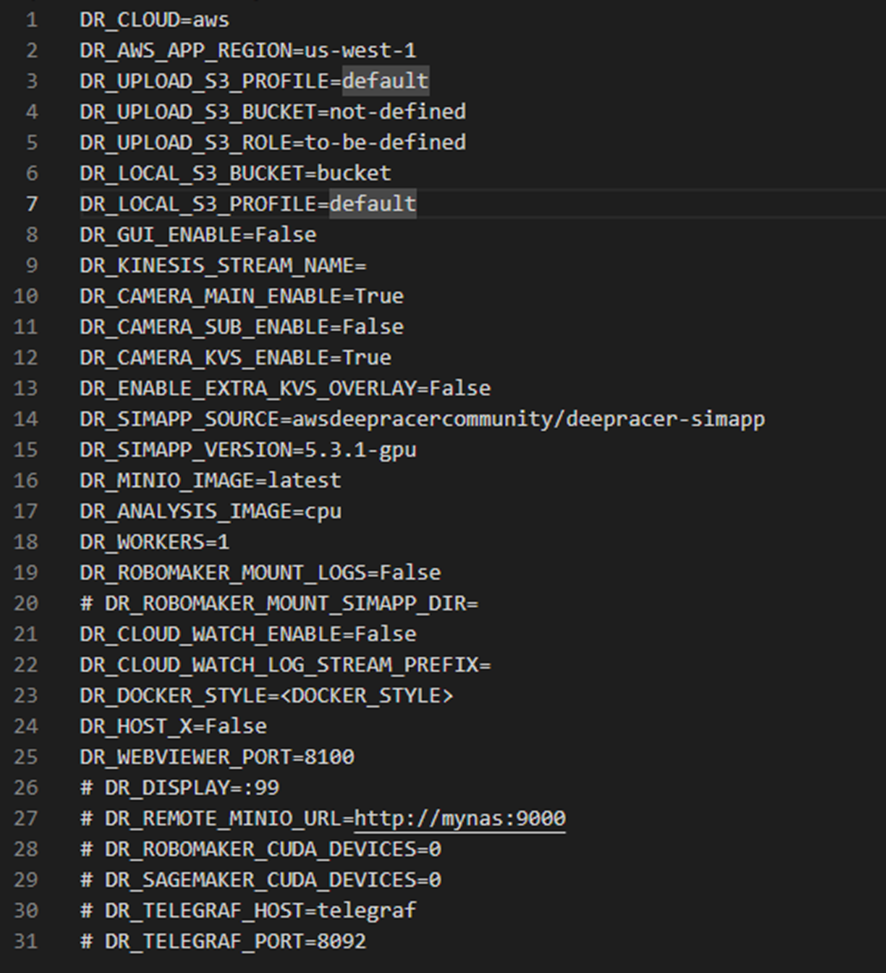
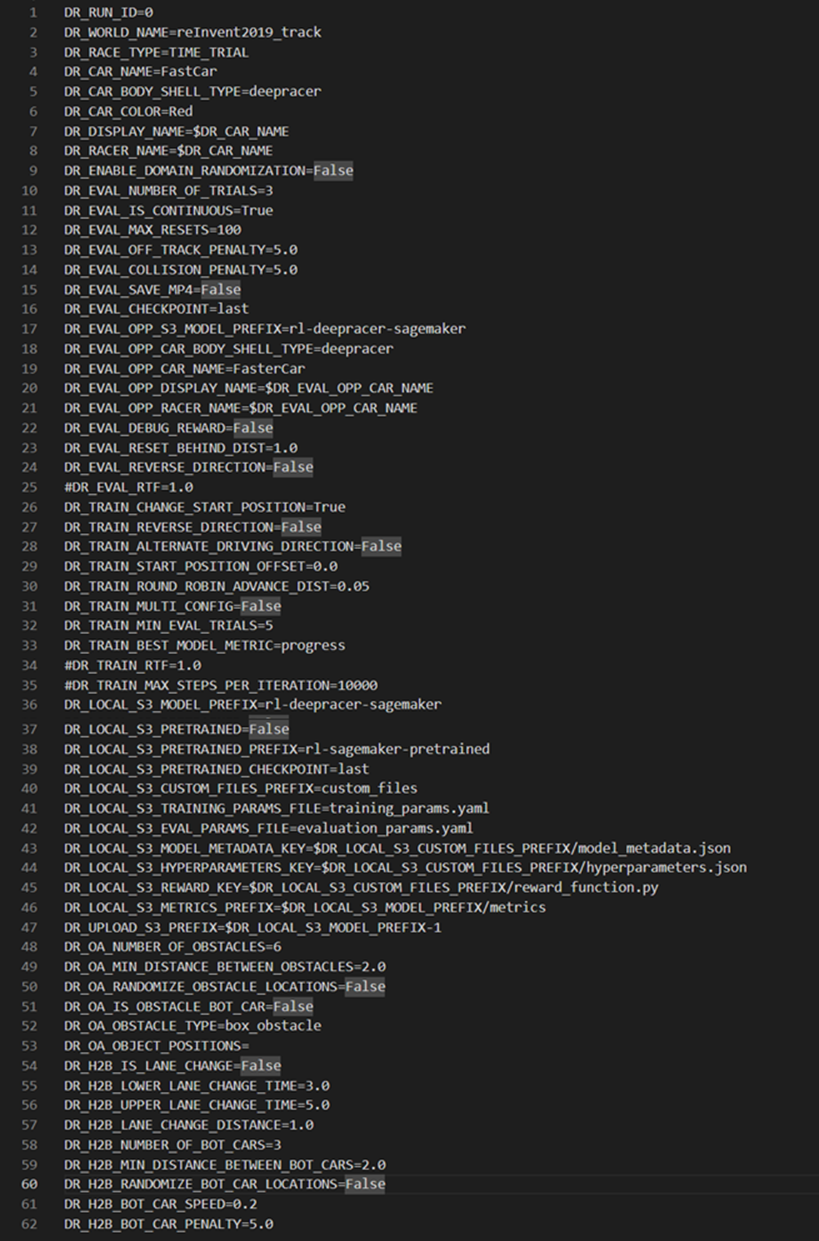
変更が必要もしくは重要なパラメータに絞って以下に説明します。各値については、どちらのファイルに記述されていても問題ありません。
■DR_WORKERS
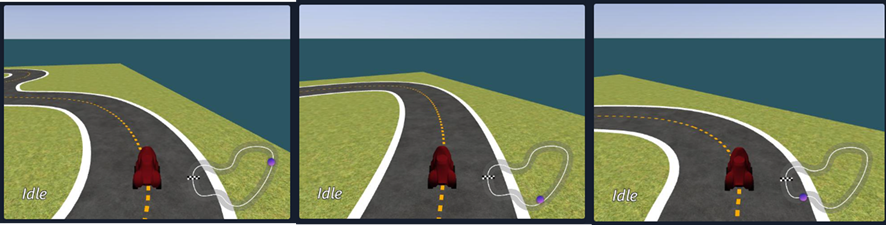
トレーニングに使用される Robomaker ワーカーの数を定義します。以下の画像はWorker数を5に設定した時のトレーニングの例となります。Worker数が多いほど、学習を早く進めることができますが、1つのRobomakerワーカーには2-4個のvCPUが必要となりますので、多くのリソースが必要となります。ご自身で設定したスペックに従ってワーカー数を設定してください。詳細はコミュニティページをご確認ください。

■DR_UPLOAD_S3_BUCKET
モデルがアップロードされるDeepRacerのバケット名を定義します。
■DR_SAGEMAKER_IMAGE、DR_ROBOMAKER_IMAGE
トレーニングに使用するSageMaker、RoboMakerのイメージを定義します。
■DR_WORLD_NAME
使用するトラックを定義します。例えば、Smile Speedwayのコースの場合は「reInvent2019_track」が設定値となります。
■DR_LOCAL_S3_MODEL_PREFIX、DR_LOCAL_S3_CUSTOM_FILES_PREFIX
それぞれ、モデルや設定ファイル(reward_function.py、hyperparameters.json、model_metadata.json)を格納するS3バケットを定義します。
■DR_LOCAL_S3_PRETRAINED
新規でモデルを作成するか、クローンでモデルを作成するかを定義します。「True」を選択した場合は、クローンでモデルを作成し、「False」を選択した場合は新規でモデルを作成します。
■DR_LOCAL_S3_PRETRAINED_PREFIX
クローンするモデルが格納されているプレフィックスを定義します。
※「DR_LOCAL_S3_PRETRAINED」で「True」を選択した場合に有効
■DR_TRAIN_BEST_MODEL_METRIC
学習時の評価として、「完走率」を重視するか、「報酬」を重視するかを定義します。「完走率」を選択した場合は完走率が高いモデルがBestモデルとして評価されます。逆に「報酬」を選択した場合は「報酬が高い」モデルがBestモデルとして評価されます。設定値は「progress」(完走率)もしくは「reward」(報酬)となります。
■DR_LOCAL_S3_PRETRAINED_CHECKPOINT
上述の「DR_LOCAL_S3_PRETRAINED」で「True」に設定した場合、クローンするモデルの「Best」モデルをクローンするのか、「Last」モデルをクローンするのかを定義します。「Best」モデルを選択した場合はクローンするモデルの学習の中で「Best」(報酬の場合は報酬が一番高かったモデル、完走率の場合は完走率が一番高かったモデル(完走率が同じモデルが複数ある場合はその中で最後のモデル))が選択されます。「Last」を選択した場合は、学習の終了時の最後のモデルが選択されます。
■DR_TRAIN_CHANGE_START_POSITION
トレーニング中のスタート地点をラウンドロビンさせるかどうかを定義します。「True」にした場合は開始位置を変化しながら学習が進みます。「False」にした場合は、トレーニング中のスタート地点は固定となります。
■DR_TRAIN_ROUND_ROBIN_ADVANCE_DISTANCE
ラウンドロビンでスタートラインを変更させる際に、エピソード毎にどの程度進めるかを定義します。設定値は0-1の間の値を設定します。例えば、「0.1」という値を設定した場合は、エピソード毎にトラックの10%ずつ開始位置が変更されます。
■DR_TRAIN_START_POSITION_OFFSET
エピソードの最初のスタートラインをどこに設定するかを定義します。「0」を設定した場合は、トラックのスタートラインから開始され、「0.1」を設定した場合は、トラックの10%進んだ場所がスタートラインとなります。
■DR_TRAIN_ALTERNATE_DRIVING_DIRECTION
エピソードごとに時計回りと反時計回りに交互に運転するかどうかを定義します。「True」を選択した場合は、エピソードごとに時計回りと反時計回りを交互に運転します。「False」を選択した場合は、トラックで選択した方向で固定となります。

■DR_ENABLE_DOMAIN_RANDOMIZATION
エピソードごとに異なる環境の色と照明を変更させるかを定義します。「True」に設定した場合、環境の色と照明が変更します。モデルをロバストにしたい場合に活用するケースが多いです。
■DR_RACE_TYPE
有効なオプションは、TIME_TRIAL、OBJECT_AVOIDANCE、および HEAD_TO_BOT です。タイムトライアルレースを選択したい場合はTIME_TRIALを選択します。
■DR_RUN_ID
単一の DRfC インスタンスのみに複数の独立したトレーニング ジョブがある場合に使用されます。 これは高度な設定なので、通常はデフォルトの 0 のままにしておきます。
■DR_CAR_COLOR
DeepRacerの車体の色を選択します。有効なオプションは、黒、グレー、青、赤、オレンジ、白、紫です。
■DR_CAR_NAME
DeepRacerの車両の表示名を設定します。アップロード時に Deepracer コンソールに表示されます。
■DR_EVAL_NUMBER_OF_TRIALS
後述する評価シミュレーションを実施する周回数を設定します。例えば「3」を設定した場合は、評価時に3周周回します。
■DR_EVAL_IS_CONTINUOUS
False の場合、車がコースから外れたり、衝突したりすると、評価トライアルは終了します。 True の場合、あなたの車はこれらのパラメータで設定されたペナルティタイムが発生した上で、トライアルの評価を続行します。
■DR_EVAL_OFF_TRACK_PENALTY
評価中にオフトラックに対して追加されるペナルティタイムの秒数を設定します。評価時にオフトラックした場合に設定した秒数分のペナルティが加算されて評価が実施されます。 DR_EVAL_IS_CONTINUOUS が True に設定されている場合にのみ有効です。
■DR_EVAL_COLLISION_PENALTY
評価中に衝突に対して追加されるペナルティ時間の秒数。評価時に衝突した場合に設定した秒数分のペナルティが加算されて評価が実施されます。DR_EVAL_IS_CONTINUOUS が True に設定されている場合にのみ有効です。
■DR_EVAL_SAVE_MP4
評価実行の MP4ファイル を保存する必要がある場合には、True を設定します。
■DR_EVAL_REVERSE_DIRECTION
評価実行時に車両がトラックを走行する方向を反転する必要がある場合には、True を設定します。Falseを設定した場合は走行する方向は一定です。
■DR_TRAIN_MULTI_CONFIG
マルチワーカートレーニング実行でワーカーごとに異なる run.env 構成を使用する場合に使用されます。この設定方法の詳細については、コミュニティページのマルチ構成のドキュメントを参照してください。
■DR_TRAIN_MIN_EVAL_TRIALS
各トレーニング反復間で実行される評価試行の最小数。 評価はポリシートレーニングが行われている限り継続され、この数値を超える場合があります。 これは最小値を確立し、特に GPU sagemaker コンテナを使用する場合にトレーニングを高速化したい場合に一般的に役立ちます。
ハイパーパラメータ・アクションスペース・報酬関数の設定
次にハイパーパラメータ(hyperparameters.json)、アクションスペース(model_metadata.json)、報酬関数(reward_function.py)の編集を行います。
■hyperparameters.json
以下図のhyperparameters.jsonの各パラメータに値を設定します。それぞれのパラメータについて以下に説明します。
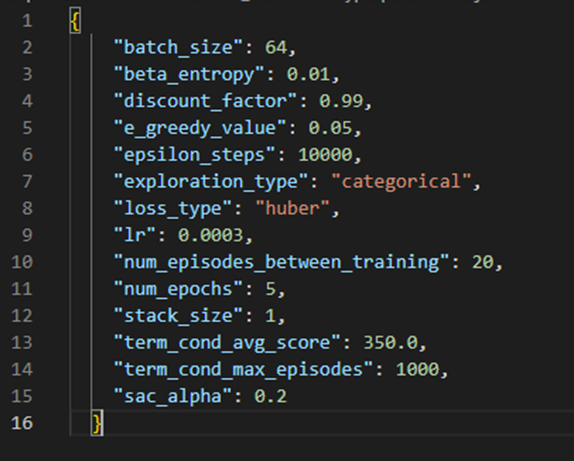
-batch_size
AWSマネージメントコンソールのGradient descent batch sizeに該当します。
-beta_entropy
AWSマネージメントコンソールのEntropyに該当します。
-discount_factor
AWSマネージメントコンソールのDiscount factorに該当します。
-e_greedy_value
e-greedyにおける探索と活用のバランスを制御するパラメータで、ランダムにアクションを選択する確率を表します。値が大きいと探索(ランダムなアクション選択)が大きく、低くすると活用(最適なアクション選択)が大きくなります。本パラメータは「exploration_type 」が「e-greedy」の時のみ使用されます。
-exploration_type
categoricalとe-greedyのいずれかを設定します。
e-greedyは行動選択の際に活用される探索戦略の1つで、エージェントがアクションを決定する際に、確率eでランダムなアクションとるようになります(確率(1-e)でモデルの出力をもとにアクションを採用するようになります)。
eが小さいと、ある程度学習が収束するとそれ以上学習が進まなくなりますが、eが大きいとその分、モデルの出力に関係ないランダムなアクションが採用される機会が増えるため、より広範囲な学習が可能になります。
理論的にはeが大きほど、最適なアクションに近づく可能性が高くなりますが、その分学習の安定性が失われたり、時間を要することになります。
-loss_type
Mean squared errorもしくはhuberを設定します。
-Ir
AWSマネージメントコンソールのLearning rateに該当します。
-num_episodes_between_training
AWSマネージメントコンソールのNumber of experience episodes between each policy-updating iterationに該当します。
-num_epochs
AWSマネージメントコンソールのNumber of epochsに該当します。
-stack_size
stack_sizeは、エージェントがトレーニング時に使用する画像のスタック数を指します。スタックは、連続したフレームを保持し、エージェントが過去の情報を利用できるようにします。これにより、より長期的な依存関係を考慮したアクションが可能になります。
値が高いほど、より多くの過去情報を保持することが可能ですが、多くの計算リソースが必要となります。
-term_cond_avg_score
学習が終了する条件で、エージェントの平均報酬が設定したパラメータを超えた場合に学習を終了します。
-term_cond_max_episodes
学習が終了する条件で、設定したパラメータ(エピソード数)に達した場合に学習を終了します。
-sac_alpha
SACアルゴリズムのEntropyを制御するパラメータです。Entropyはモデルがアクションを決定する際に、どの程度のランダム性を持たせるかを設定するパラメータとなります。
■model_metadata.json
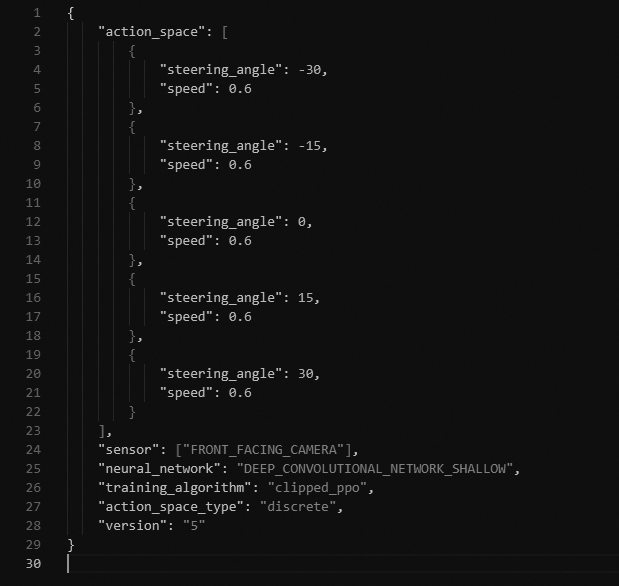
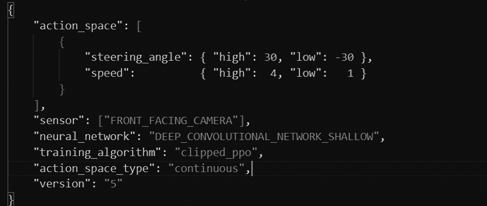
以下図のmodel_metadata.jsonにアクションスペース、トレーニングアルゴリズム、カメラの情報などを設定します。上図がDiscrete action space、下図がContinuous action spaceの設定例となります。Discrete action spaceの場合は図5-3-2の例のように前半にステアリング角とスピードの値のセットをアクションスペースの数だけ設定します。また、「action_space_type」の値を「discrete」に設定します。Continuous action spaceの場合は図5-3-3の例のようにステアリング角とスピードの最大値、最小値を設定します。また、「action_space_type」の値を「continuous」に設定します。
トレーニングアルゴリズムについては、「training_algorithm」に設定します。PPO を選択したい場合は「clipped_ppo」を、SAC を選択したい場合は「sac」を設定してください。
■reward_function.py
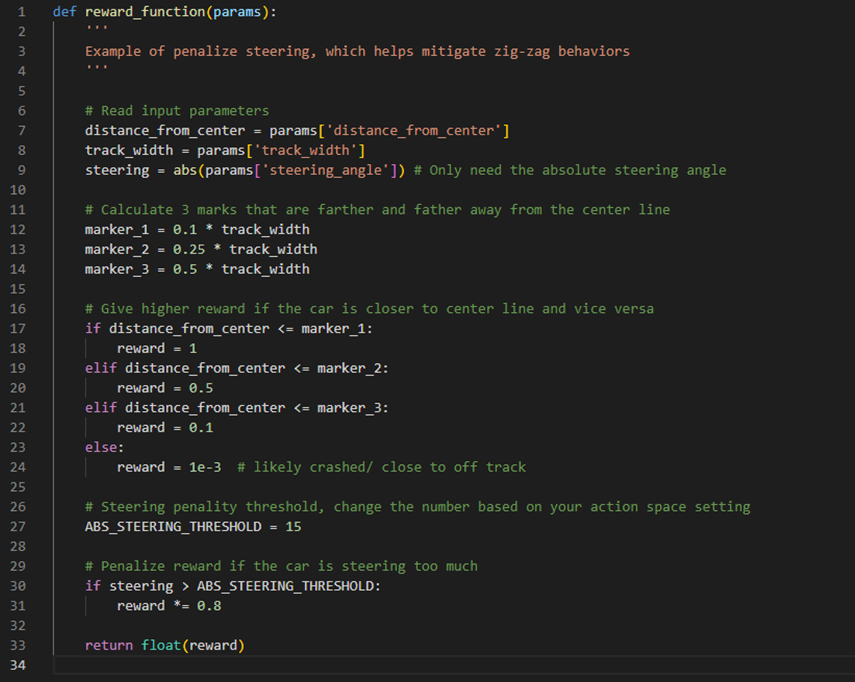
以下図のreward_function.pyに報酬関数を設定します。こちらはマネージメントコンソールと同様に、こちらのファイルに報酬関数を記載するだけで問題ありません。
学習の開始/終了
設定ファイルおよび報酬関数等の設定が完了したら、学習を開始します。学習を実施する際には以下のコマンドを実行します。まずは「deepracer-forcloud」にディレクトリを変更し、activate.sh を実行し環境を有効化します。
cd /home/ubuntu/deepracer-for-cloud
source ./bin/activate.sh
次に環境変数や設定ファイルを読み込み、設定したS3 へアップロードを実施し、学習を開始します。
dr-update-env
dr-upload-custom-files
dr-start-training
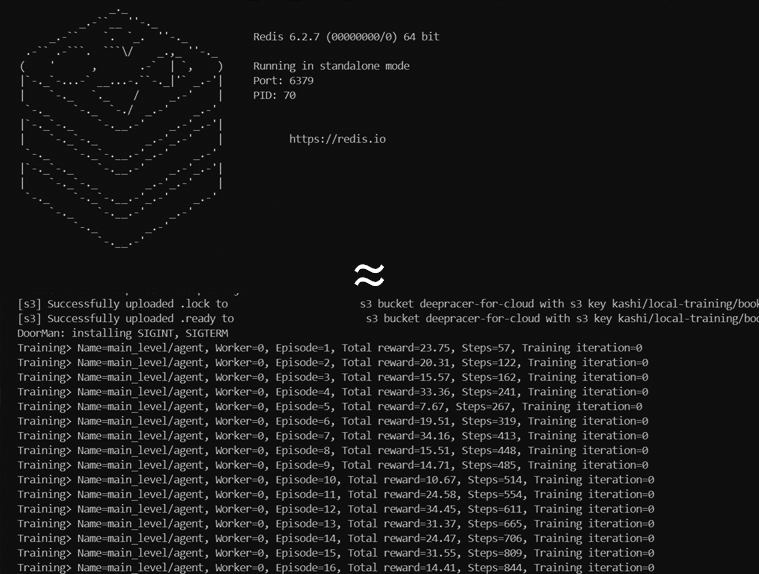
以下の図のように学習が開始され、各iteration におけるStep数や報酬が表示されます。
トレーニング中の走行を確認するためには以下のコマンドを入力し、http://IP アドレス:8100 でWeb コンソール上から走行を確認することが可能です。
dr-start-viewer
走行の確認が終わったら、以下のコマンドでviewerを停止してください。
dr-stop-viewer
プロンプト上で再度ログを表示させたい場合は以下のコマンドを実行します。
dr-logs-sagemaker
学習を終了させる場合は以下のコマンドを実行します。
dr-stop-training
再学習(クローン)の実施
再学習(クローン)を実施する際には、run.env(もしくはsystem.env)ファイルにある以下の設定を修正します。なお、モデルおよびCustom fileのアップロード先(DR_LOCAL_S3_MODEL_PREFIX、DR_LOCAL_S3_CUSTOM_FILES_PREFIX)についても、再学習をするモデルをアップロードする先へ変更してください。
「DR_LOCAL_S3_PRETRAINED」は、新規で学習する際にはFalse、再学習(クローン)を実施したい際にはTrue を設定します。「DR_LOCAL_S3_PRETRAINED_PREFIX」には再学習させたいモデルの格納パス(S3 URI)を設定します(5.3 節で説明したAWS マネジメントコンソールへインポートする際のパスと同様です)。「DR_LOCAL_S3_PRETRAINED_CHECKPOINT」は再学習させたいモデルのベストモデルを選択するかラストモデルを選択するかを決定します。
DR_LOCAL_S3_MODEL_PREFIX=”再学習するモデルのアップロード先”
DR_LOCAL_S3_CUSTOM_FILES_PREFIX=”再学習するCustom Fileのアップロード先”
DR_LOCAL_S3_PRETRAINED=True
DR_LOCAL_S3_PRETRAINED_PREFIX=”再学習したいモデルが格納されているS3 URI”
DR_LOCAL_S3_PRETRAINED_CHECKPOINT=”best or last”
設定が完了したら、再度以下のコマンドを実行し、学習を開始してください。5.3.2 項の説明と同様の流れで学習が開始されます。
まとめ
今回のブログでは前回の「概要編」、「AWSマネージメントコンソール編」に続き、「ローカルトレーニング編」をお届けしました。AWSマネージメントコンソールからはあと1か月でトレーニングが実施できなくなりますが、ローカルトレーニングは続けていけると思いますので、ぜひ興味のある方は試してみてください。
AWSマネージメントコンソールから触れる、公式のバーチャルレースが開催されるのはこれが一旦最後かと思いますが、ぜひ残り1か月間でお楽しみいただければと思います。
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDF-AM(Trusted Data FoundationⓇ - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。