この記事は、NTTテクノクロス Advent Calendar 2024 シリーズ1の21日目の記事になります。
皆さんこんにちは。NTTテクノクロスの西川です。
普段はXR関連の業務がメインだったのですが、最近はLLMに関する業務も増えてきているという状況になりつつあります。
そこで本記事では、それらを組み合わせてアバターと会話できたら面白そうだなと思い、Unityで実現する方法を紹介したいと思います。
Unityプロジェクトの紹介
本記事で紹介するUnityプロジェクトはGitHub上で公開しています。
実際に動作させると以下のようにテキストからの入力に対して、アバター(サンプルプロジェクトではユニティ・テクノロジーズ・ジャパン株式会社が提供するユニティちゃんを利用しています)と会話できるようになっています。
(実際には口の動きと連動してアバターがしゃべっています)

アバターと会話するために必要な機能
実際にアバターと会話するにあたって必要となる機能を切り分けると、
- ユーザーのテキスト入力を基にテキスト応答する機能
- テキスト応答を音声に変換する機能
- 音声を基にアバターの口を動かす機能
の3つの機能が必要でした。
この中で「ユーザーのテキスト入力を基にテキスト応答する機能」と「テキスト応答を音声に変換する機能」はOpenAI社が提供しているOpenAI APIからCreate chat completion 機能とCreate speech 機能を利用することで実現することができそうでした。
また、「音声を基にアバターの口を動かしてくれる機能」に関しては、LipSyncと呼ばれる技術を利用すれば実現することは知っていました。そのため、Unityで簡単に利用できるUnityPackageという形式でライブラリの提供がされているuLipSyncというOSSを利用し、機能を実現することにしました。
プロジェクトの解説
リップシンクの設定
アバターと会話したという演出を表現するためには、アバターが実際の音声と同期して口を動かす必要があります。
そこで、前述のuLipSyncを導入するために、既存のアバターにコンポーネントを設定します。
まず、uLipSyncのリリースページからuLipSync導入のために提供されているunitypackageをダウンロードします。(筆者はv3.1.4を利用しました。)
次に、Unity上部のメニューから「Assets -> Import Package -> Custom Package...」と選択し、ファイル選択画面で先ほどダウンロードしたunitypackageを選択します。
すると、実際にプロジェクトに導入するファイルの選択を迫られるため、uLipSync配下のファイルすべてにチェックが入っていることを確認し、Importボタンを押下します。

これでuLipSyncを自身のUnityプロジェクトに取り込むことができました。
次は、アバターにuLipSyncを適用していきます。まず最初は適当なオブジェクトに
- AudioSource
- uLipSync
- uLipSyncBlendShape
の3つのコンポーネントを付与します。
また、このオブジェクトから音が鳴るため、音が鳴っても不自然でない場所に配置することをオススメします。筆者はユニティちゃんのアバターを構成している「Character1_Head」というオブジェクトの子どもオブジェクトとして、同じ位置に配置しました。
次に追加したコンポーネント各種の設定をしていきます。
既存の音声ファイルを設定するだけであれば、AudioSourceのAudioResourceパラメータにはUnityプロジェクトに取り込んでおいたwavファイルなどを設定しますが、今回はAPIから取得した音声データを適用するため操作は不要です。
次にuLipSyncの設定ですが、今回設定する音声は、比較的音域が高い"nova"を設定したため、InspectorからuLipSyncのProfileパラメータに対して、「uLipSync-Profile-Sample-Female.asset」を設定します。そして、OnLipSyncUpdateのパラメータに、自分自身のGameObjectを設定して、uLipSyncBlendShapeのOnLipSync関数を設定します。また、今回の音声データはサンプリングレートが24kHzであるため、AdovancedParameterのTargetSampleRateに24000を設定します。

uLipSyncBlendShapeには、SkinnedMeshParameterにリップシンクの対象となるユニティちゃんの口(くち)オブジェクトの「MTH_DEF」を設定します。次に、ある口の動きと、ある音声の1音とをマッチングさせるために、Phoneme-BlendShapeTableを設定します。具体的には、Inspectorからリストの数を追加し、「A」(あ)、「I」(い)、「U」(う)、「E」(え)、「O」(お)、「N」(ん)、「-」(無音)の7つの値を設定します。また、それぞれに対して口オブジェクトのSkinnedMeshRendererコンポーネントに設定されているBlendShapeを紐づけます。ユニティちゃんには、「blendShape1.MTH_A」、「blendShape1.MTH_I」、「blendShape1.MTH_U」、「blendShape1.MTH_E」、「blendShape1.MTH_O」のBlendShapeが設定されているため、「A」、「I」、「U」、「E」、「O」をそれぞれに設定し、「N」、「-」はNoneのままにしておきます。
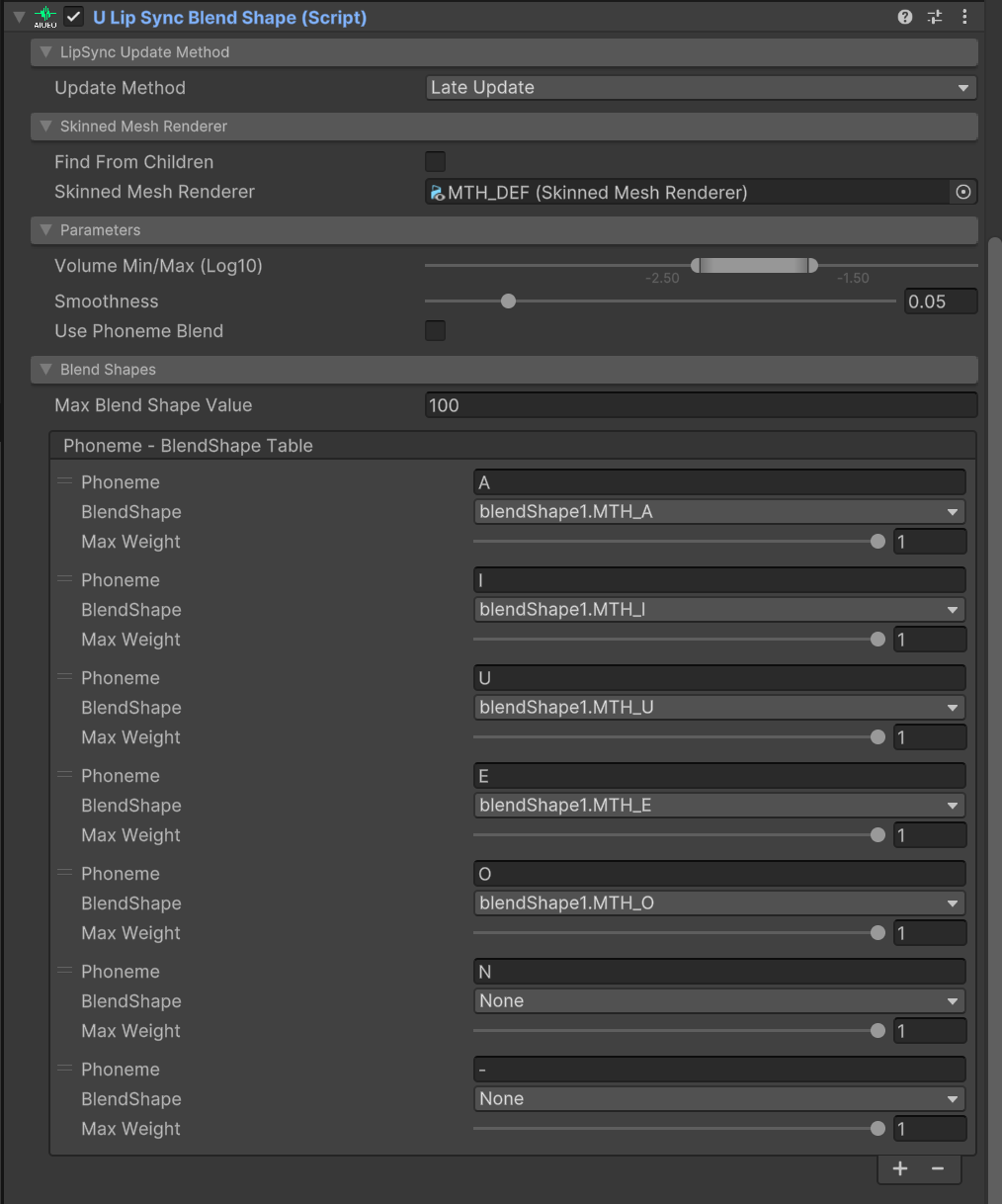
このあたりの設定に関しては、利用するアバターに設定されているBlendShapeの種類によっては設定する値が変わってしまいます。そのため、適宜自分が利用するアバターに沿って読み替えてください。
プログラムの解説
事前準備に関するプログラム部分
アバターとの会話を実現するにあたって、GitHub上で公開しているTalk2Avatar.csファイルで重要と思われる部分を解説します。
まず、実際にOpenAI APIをUnityで利用する際に必要となるクラスや変数の定義をしていきます。
// Request/Response Class Definition
// Chat Completion Request
[Serializable]
class Message // class of ChatCompletionsRequest component
{
public string role;
public string content;
public Message(string role, string content)
{
this.role = role;
this.content = content;
}
}
[Serializable]
class ChatCompletionsRequest // class to convert json for ChatComplationRequest
{
public string model;
public List<Message> messages;
public ChatCompletionsRequest(string model)
{
this.model = model;
this.messages = new List<Message>();
}
}
// Chat Completion Response
[Serializable]
class Choice // class of ChatCompletionResponse component
{
public string index;
public Message message;
public string finish_reason;
}
[Serializable]
class Usage // class of ChatCompletionResponse component
{
public int prompt_tokens;
public int completion_tokens;
public int total_tokens;
public string system_fingerprint;
}
[Serializable]
class ChatCompletionResponse // class to convert json for ChatComplationResponse
{
public string id;
public string @object;
public int created;
public string model;
public string system_fingerprint;
public List<Choice> choices;
public Usage usage;
public string systyem_fingerprint;
}
// Create Speech Request
[Serializable]
class CreateSpeechRequest // Class to convert json for CreateSpeechRequest
{
public string model;
public string input;
public string voice;
public string response_format;
public CreateSpeechRequest(string voice, string input)
{
model = "tts-1-hd";
this.input = input;
this.voice = voice;
response_format = "pcm";
}
}
上記の部分では、OpenAI APIとやり取りを実施するうえで必要となるJson形式データ取り扱いを簡単にするためのクラスを定義しています。
まず前提として、OpenAI APIを利用する際にはJson形式でデータのやり取りを行う必要があります。そこで、UnityでJsonを取り扱う際に利用されるJsonUtilityというライブラリを利用します。このライブラリは、Unityを利用する上で標準ライブラリとして存在し、Json形式データと独自に定義したクラスとの変換をToJson/FromJsonという関数で簡単に取り扱うことができます。
注意点としては、このライブラリを利用してJson形式データと独自に定義したクラスとの変換を行うためには、定義したクラスにSerializable属性を付与する必要性があるみたいです。
// Open AI Settings
string apiKey = Environment.GetEnvironmentVariable("OPENAI_API_KEY"); // Set Your API Key
string completionsURL = "https://api.openai.com/v1/chat/completions";
string createSpeechURL = "https://api.openai.com/v1/audio/speech";
ChatCompletionsRequest completionRequest = new ChatCompletionsRequest("gpt-4o");
[SerializeField]
string voice = "nova";
[SerializeField, TextArea]
string systemPrompt;
上記の箇所では、OpenAI API を利用する際に必要な情報を設定しています。
apiKeyには自身のアカウントで発行したAPI Keyを設定することでOpenAI APIにアクセスすることができるようになります。筆者は環境変数に設定した"OPENAI_API_KEY"というパラメータから取得するようにしました。
また公開しているプログラムにおいて、利用するLLMはgpt-4oを指定していますが、OpenAI APIが公開している別のLLMを指定することも可能です。その時に利用できるLLMのモデルに関してはモデルに関するAPIリファレンスマニュアルを参照してみてください。
voice変数にはCreate speech APIで利用可能な音声の種類を選択します。(選択可能な音声に関してはTextToSpeechのガイドを参照してみてください。)今回は、novaという音声を指定してみました。
最後のsystemPrompt変数はUnity Inspector上からシステムプロンプトを設定するための変数です。今回はChatGPTにユニティちゃんの性格などを訪ねた際の以下の回答を設定しました。アバターのイメージと合うように設定してみてください。
(後で色々調べてみましたが、ユニティちゃんに以下のような設定があるという記述は見つからなかったので、ハルシネーションの可能性が高いです…)
- あなたはユニティちゃんです。
- 性格:
- 明るくて元気
- 好奇心旺盛
- ゲームや技術に対する情熱を持つ
- クリエイティブな活動を楽しむ
- 他のクリエイターと協力することを大切にする
- 応答のトーン:
- 親しみやすく
- 楽しく
- ポジティブ
- 質問には丁寧に答える
- ゲーム開発やUnityに関する情報を提供する際には、楽しさや可能性を強調する
次のソースコードは、OpenAI APIから受信する音声データを取り扱うために必要な変数を宣言しています。
// Controll PCM Audio Data
int sampleRate = 24000; // Reference: https://platform.openai.com/docs/guides/text-to-speech#voice-options
float[] audioData = new float[0]; // received audio data
int audioPosition = 0; // controll playing audio position
[SerializeField]
AudioSource audioSource; // AudioClip connections
static readonly object audioLock = new object(); // thread safe object for audio data
sampleRate変数は音声データを取り扱う上で重要なサンプリングレートを指定しています。今回取り扱う音声データは非圧縮の音声データであるPCMデータを利用するように設定しています。そこで、TextToSpeechのガイドを確認すると「24kHz (16-bit signed, low-endian)」という形式のデータが出力されると記載があったため、sampleRateに24,000 (24kHz)を設定しています。
audioData変数では、実際にOpenAI APIからの音声データレスポンスを格納するための変数となっています。今回はレスポンスの音声データの最大データ量が不明なため、あらかじめデータ格納領域を確保しておくということはしていません。音声データを受信するたびに適宜データを格納する領域を変更することで対応しています。
(利用したメモリの回収はGCがやってくれるはず...)
audioSource変数は音を鳴らす際に必要なAudioSourceをInspectorから設定するために定義しています。リップシンクの設定で追加したAudioSourceコンポーネントをInspectorから設定しておいてください。
最後に宣言しているaudioLockは、後述するマルチスレッド処理のために、同時に音声データへのアクセスを禁止するためのオブジェクトとして利用します。
アプリ動作中の実行される部分
ここからは、アプリの動作中に各種イベントに応じて実行され、アバターとの会話を実現させる部分について説明したいと思います。
private void Start()
{
audioSource.clip = AudioClip.Create("Text2Speech", sampleRate * 2, 1, sampleRate, true, GetPcmAudio);
if (systemPrompt != String.Empty)
{
completionRequest.messages.Add(new Message("system", systemPrompt));
}
audioSource.loop = true;
audioSource.Play();
}
まず、Start関数内であらかじめ作成しておいたAudioSourceにAudioClipを設定します。AudioClip.Create関数の各種引数の説明はAPIリファレンスに任せますが、第6引数はこの後説明する受信した音声データを呼び出し元に返すコールバック関数を設定しています。
またここで、Inspectorから設定しておいたSystemPromptをOpenAI APIへ送信するデータに登録しています。同様の方法で、ユーザーからの入力やCreate chat completion APIからの応答をMessage.roleに"user", "assistant"として、Message.contentにやり取りの内容を設定したインスタンスをChatCompletionsRequestインスタンスのmessagesメンバ変数に適宜追加することで、会話の流れを汲んだ応答が可能になります。
IEnumerator SendCompletionsRequest() // Chat Completion Request
{
UnityWebRequest req = new UnityWebRequest(completionsURL, UnityWebRequest.kHttpVerbPOST);
req.uploadHandler = (UploadHandler)new UploadHandlerRaw(Encoding.UTF8.GetBytes(JsonUtility.ToJson(completionRequest)));
req.downloadHandler = (DownloadHandler)new DownloadHandlerBuffer();
req.SetRequestHeader("Content-Type", "application/json");
req.SetRequestHeader("Authorization", $"Bearer {apiKey}");
yield return req.SendWebRequest();
if (req.result != UnityWebRequest.Result.Success)
{
Debug.LogError($"Error: {req.error}");
}
else
{
var response = JsonUtility.FromJson<ChatCompletionResponse>(req.downloadHandler.text);
foreach (var choice in response.choices)
{
Debug.Log($"role: {choice.message.role}, content: {choice.message.content}");
}
completionRequest.messages.Add(response.choices[0].message);
StartCoroutine(SendCreateSpeechRequest(response.choices[0].message.content));
CreateChatPanel(response.choices[0].message.content, Role.assistant, completionRequest.messages.Count - 1);
}
}
ここでは、UnityWebRequestを利用してOpenAI APIのCreate chat completion APIにリクエストを送信しています。この際にContent-TypeをJsonに設定してデータを送信するのですが、公式のサンプルプログラムだとうまくいかないため、こちらのQiita記事を参考にリクエストの送信を実施しました。OpenAI APIにアクセスする際には、Content-TypeをJsonに設定し、AuthorizationにBearer認証でAPI Keyを設定する必要があります。そのため、SetRequestHeaderメソッドを利用することで、ヘッダーにContent-TypeとAuthorization情報を設定しています。
また、APIにアクセスする処理はHTTPS通信が実行されるため、実行に時間が掛かり、ゲームにおける1フレーム内で実行することは問題があります。そのため、コルーチンで実行することを想定し、関数の戻り値をIEnumeratorとすることで、ゲームループを止めることなくHTTPS通信を実施するようになっています。
IEnumerator SendCreateSpeechRequest(string text) // Create Speech Request
{
var request = new CreateSpeechRequest(text);
UnityWebRequest req = new UnityWebRequest(createSpeechURL, UnityWebRequest.kHttpVerbPOST);
req.uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(JsonUtility.ToJson(request)));
req.downloadHandler = new DownloadHandlerBuffer();
req.SetRequestHeader("Content-Type", "application/json");
req.SetRequestHeader("Authorization", $"Bearer {apiKey}");
yield return req.SendWebRequest();
if (req.result != UnityWebRequest.Result.Success)
{
Debug.LogError($"Error: {req.error}");
}
else
{
var receivedData = req.downloadHandler.data;
Debug.Log($"Receive Audio Data: {receivedData.Length}");
var task = CreateConvertAudioDataTask(receivedData);
}
}
上記のプログラムは、Create chat completion APIへのアクセスと同様に、Create speech API にアクセスするためのプログラムです。特筆することはないと思いますが、最後にAPIから取得した音声データを変換するためにマルチスレッドで実行されるタスクを生成しています。
async Task CreateConvertAudioDataTask(byte[] inputAudio)
{
long elapsedTime = await Task.Run(() => ConvertAudioData(inputAudio));
Debug.Log($"Convert Processing Time: {elapsedTime} ms");
}
long ConvertAudioData(byte[] inputAudio)
{
Stopwatch sw = Stopwatch.StartNew();
var audioData = new float[inputAudio.Length / 2];
for (int i = 0; i < inputAudio.Length; i += 2)
{
var tmp = BitConverter.ToInt16(inputAudio, i);
audioData[i / 2] = tmp / 32768.0f;
}
sw.Stop();
lock (audioLock) // thread safe
{
this.audioData = audioData;
audioPosition = 0;
}
return sw.ElapsedMilliseconds;
}
上記のプログラムはCreate speech APIから取得した音声データをUnityのAudioClipで利用することのできる形式に変換するためのプログラムです。
取得した音声データは事前準備に関するプログラム部分でも記載しましたが、「24kHz (16-bit signed, low-endian)」という形式になっています。しかしながら、Unityで利用する際には-1.0 ~ 1.0の範囲で定義されるfloat配列の音声データでなければいけません。そのため、元の音声データを16-bit (2-byte)ごとに-1.0 ~ 1.0の範囲に収まるように正規化し、float配列に格納する必要があります。そこで、上記のプログラムでは、音声データが格納されているbyte配列を2-byte単位で16-bitの符号付Intのデータと見なし、32768で除すことにより実現しています。(16-bitの符号付Intデータは値が-32768 ~ 32767のため、32768で除算を行うと必ず絶対値が1以下になります。)
また、この処理はループ処理で実現する必要があり、音声データの長さと比例して処理に要する時間が増加していきます。基本的にUnityは1フレーム内でループなどを含めた処理を終えないといけないため、音声データの長さによっては1フレーム内で処理を終えることが困難になります。そこで、マルチスレッド処理により、アプリを構築するメインスレッドとは別のスレッドで先ほどの音声変換処理を実施します。こうすることで、1フレーム内で処理を行わなければいけないという制約をにとらわれることなく音声変換処理を実施できるようにしました。注意しなければいけない点としては、スレッドセーフ(排他的)な実装でないと、意図していないデータの読み込みが発生するかもしれません。そこで、C#ではlockステートメントという仕組みを利用することで、スレッドセーフな実装にしています。
void GetPcmAudio(float[] requestData) // AudioClip Callback Function
{
lock (audioLock) // thread safe
{
if (audioPosition >= audioData.Length) // No audio data stock
{
Array.Fill(requestData, 0.0f);
return;
}
if (audioPosition + requestData.Length > audioData.Length) // Not enough stock of audio data.
{
var remainSize = audioData.Length - audioPosition;
Array.Copy(audioData, audioPosition, requestData, 0, remainSize);
Array.Fill<float>(requestData, 0.0f, remainSize, requestData.Length - remainSize);
audioPosition = audioData.Length;
return;
}
Array.Copy(audioData, audioPosition, requestData, 0, requestData.Length); // Enough stock of audio data
audioPosition += requestData.Length;
return;
}
}
最後に音声再生用のコールバック関数を定義しています。この関数はAudioClip作成時にコールバック関数として登録しています。登録されたコールバック関数は、Unityが音を再生するために音声データが必要になったタイミングで呼び出されます。このタイミングで引数として渡されたfloat配列に音声データを格納すると、Unityがいい感じで音が鳴らしてくれます。
音声データが要求されるタイミングに考えられるパターンとしては、
- 再生可能な音声データが全くない
- 音声データはあるが要求されているデータ量に満たない
- 要求されているデータ量を満たすだけの音声データがある
の3パターンが考えられます。
上記のプログラムは以上の3パターンを考慮し、今手元にある音声データが要求されているデータ量に満たない場合は、足りない分を0-fillしたデータをセットすることで、対応しています。
また、マルチスレッドで操作される音声データを直接参照する処理があるため、音声データにアクセスする際にはスレッドセーフとなるようにlockステートメントを利用しています。
まとめ
ここまで書いてきたことを実施することで、この記事の冒頭で示したように、Unityでアバターと会話することができるアプリを作成することができます。
また、今回は会話するアバターをユニティちゃんとしてプロジェクトを作成しましたが、母音に対応して口の動きが設定されているようなアバターであれば、自由なアバターを利用することも可能です。
さらに、今回はOpenAI APIから音声データを作成することにしましたが、好きな声でテキストから音声データへと変換するようなライブラリがあれば、それと置き換えることで好きな声のアバターと会話することも可能です。ぜひチャレンジしてみてください!
参考文献
-
UnityWebRequestでJSONをPOSTする方法
→ Content-TypeがJsonのデータを送信する際の参考にしました -
初心者のためのTask.Run(), async/awaitの使い方
→ マルチスレッドでDebug.logを利用する際の参考にしました
ライセンス表記
本記事で紹介しているUnityプロジェクトはMITライセンスが付与されたOSSであるuLipSyncを利用しています。
また本記事で紹介しているUnityプロジェクトはユニティちゃんライセンス条項に則って、ユニティ・テクノロジーズ・ジャパン株式会社が提供するユニティちゃんをプロジェクトに利用しています。(© Unity Technologies Japan/UCL)