量子ニューラルネット
PennyLaneを用いて量子ニューラルネットワークを学習させた際の計算時間を考えます。
学習には非勾配最適化(e.g. Nelder-Mead)と、勾配最適化(e.g. Adam)があります。
古典ニューラルネットワーク機械学習では、常識的に、勾配最適化のほうが速いとされます。
量子の場合もそうなのでしょうか?
PennyLaneは勾配降下が出来ることを売りにしていますが、本当に有用なのでしょうか?
非勾配vs勾配のフェアな比較は、ほとんど見られなかったので、やってみました。
非勾配vs勾配 の比較条件
- 非勾配はscipy.optimize.minimize
- 学ぶ対象はsin(x)
- 学習対象のデータセット、ニューラルネットワークモデルは同一とする。
- Optimizerには、勾配はAdam、非勾配はNelder-Meadとする。
- iteration回数は揃える。ただし非勾配については、必ずしもiteration回数=パラメータupdate回数にはならないよう。
- optimizerのハイパラは、収束コストが両者でだいたい等しくなる程度に設定する。
厳密に出来ていない箇所もありますが、ご容赦ください。
コード
勾配降下
import pennylane as qml
from pennylane import numpy as np
from matplotlib import pyplot as plt
num_of_data = 64
X = np.random.uniform(high=2 * np.pi, size=(num_of_data,1))
Y = np.sin(X[:,0])
######## パラメータ #############
n_qubits = 2 ## qubitの数
n_layers = 2 # q_layer
dev = qml.device("lightning.qubit", wires=n_qubits, shots=None) # define a device
# Initial circuit parameters
var_init = np.random.uniform(high=2 * np.pi, size=(n_layers, n_qubits, 3))
@qml.qnode(dev, diff_method='adjoint')
def quantum_neural_net(var, x):
qml.templates.AngleEmbedding(x, wires=range(n_qubits))
qml.templates.StronglyEntanglingLayers(var, wires=range(n_qubits))
return qml.expval(qml.PauliZ(0))
def square_loss(desired, predictions):
loss = 0
for l, p in zip(desired, predictions):
loss = loss + (l - p) ** 2
loss = loss / len(desired)
return loss
def cost(var, features, desired):
preds = [quantum_neural_net(var, x) for x in features]
return square_loss(desired, preds)
opt = qml.AdamOptimizer(0.1)
import time
hist_cost = []
var = var_init
for it in range(50):
t1 = time.time()
var, _cost = opt.step_and_cost(lambda v: cost(v, X, Y), var)
t2 = time.time()
elapsed_time = t2-t1
print("Iter:"+str(it)+", cost="+str(_cost.numpy()))
print(f"Time:{elapsed_time}")
hist_cost.append(_cost)
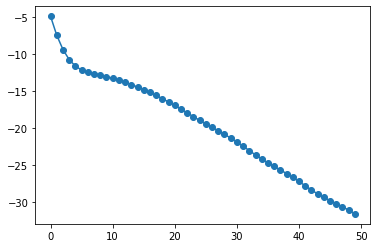
plt.plot(10*np.log10(hist_cost),'o-')
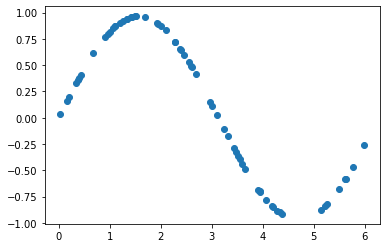
Y_pred = [quantum_neural_net(var, x) for x in X]
plt.plot(X[:,0],Y_pred,'o')
Iter:0, cost=0.32403188045966985 Time:0.4249999523162842 Iter:1, cost=0.17929298669460514 Time:0.38500022888183594 Iter:2, cost=0.11539541686157953 Time:0.38000011444091797
学習時間:0.4 x 50 = 20 sec
非勾配
ほぼ同じですが、scipy.optimize.minimize は1次元配列しか変数に取れないことに注意します。
(1次元で渡して、cost関数内部でrehshapeします)
# Initial circuit parameters
var_init = np.random.uniform(high=2 * np.pi, size=(n_layers*n_qubits*3)) # one-dimensional array
@qml.qnode(dev, diff_method='adjoint')
def quantum_neural_net(var, x):
var_3d_array = np.reshape(var,(n_layers,n_qubits,3))
qml.templates.AngleEmbedding(x, wires=range(n_qubits))
qml.templates.StronglyEntanglingLayers(var_3d_array, wires=range(n_qubits))
return qml.expval(qml.PauliZ(0))
from scipy.optimize import minimize
hist_cost = []
var = var_init
count = 0
def cbf(Xi):
global count
global hist_cost
count += 1
cost_now = cost(Xi,X,Y)
hist_cost.append(cost_now)
print('iter = '+str(count)+' | cost = '+str(cost_now))
result = minimize(fun=cost, x0=var_init, args=(X,Y) ,method='Nelder-Mead', callback=cbf, options={"maxiter":50})
t2 = time.time()
elapsed_time = t2-t1
print(f"Time:{elapsed_time}")
hist_cost.append(_cost)
print(f"Time per iteration : {elapsed_time/50}")
plt.plot(10*np.log10(hist_cost[1:len(hist_cost)-1]),'o-')
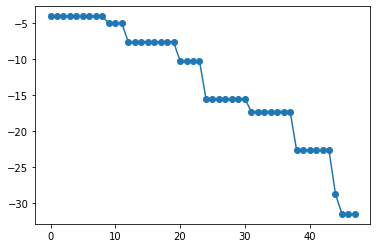
iter = 1 | cost = 0.3949460800587229 iter = 2 | cost = 0.3949460800587229 iter = 3 | cost = 0.3949460800587229 iter = 4 | cost = 0.3949460800587229
Time:41.019999980926514 Time per iteration : 0.8203999996185303
勾配降下の2倍の時間がかかりました。
思ったほど差がない・・と思いました。
では、パラメータ数が増えるとどうなるでしょうか。
n_layers = 2→6 にしてみます。(パラメータ数が3倍になります)
勾配では
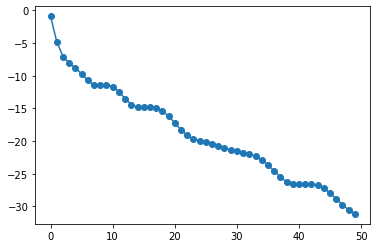
Iter:0, cost=0.8111990194081542 Time:0.940000057220459 Iter:1, cost=0.3314598963846486 Time:0.8700001239776611 Iter:2, cost=0.1956043243597784 Time:0.8700001239776611
非勾配では
iter = 1 | cost = 1.004932862586646 iter = 2 | cost = 1.004932862586646 iter = 3 | cost = 1.004932862586646 iter = 4 | cost = 1.004932862586646 iter = 5 | cost = 1.004932862586646 iter = 6 | cost = 1.004932862586646 iter = 7 | cost = 1.004932862586646
Time:98.82499980926514 Time per iteration : 1.9764999961853027

やはり速度差は2倍程度だったのですが、非勾配は全く収束していません。
非勾配の場合、パラメータ数が増えるとパラメータupdateに何度もiterationを必要とするようです。
iteration回数を4倍にしてみますと、
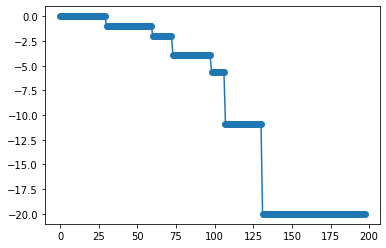
収束はしています。しかし計算時間は勾配法の8倍かかっていますし、まだ収束コストで負けています。
このように、勾配降下はパラメータ数が多いとアドバンテージが大きくなることがわかりました。
直感的にそうかもしれませんが、実際みてみると大変面白い結果ではないでしょうか。
まとめ
勾配降下はやっぱり速いのだ。