つづき
前回の 会話の文字起こしと AI アシスタント(その1) では 会話の文字起こし を使って発話内容を文字起こしして、その内容からトピックを分類する内容をご紹介しました。
今回は前回説明ができていたかった カスタムテキスト分類 のモデル作成について手順を見ていくことにします。
基本的な作業の流れは 公式クイックスタート に紹介されている手順ですが、少し簡素化する方法も織り込みたいと思います。
Azure Gognitive Services の 言語サービスのデプロイ方法については説明を割愛させていただきますので、Language Studio の使用を開始する をご覧ください。
準備
カスタムテキスト分類モデルを作成する際、データのラベル付けの作業量が大きくなりがちです。この作業を簡素化するために、いくつかの準備をしたいともいます。
Azure Storage Explorer
デスクトップアプリケーションの Azure Storage Explorer をインストールすることでデータのアップロード作業が簡単になります。Azure Storage Explorer は macOS や Linux バージョンも用意されています。
こちらからインストーラーをダウンロード して Azure Storage Explorer をインストールしてください。
Azure にサインイン すると、言語サービスをデプロイした際に指定した ストレージアカウント も見つけられる はずです。そのストレージアカウント を見つけたら blob container を作成 しておきます。
データの準備
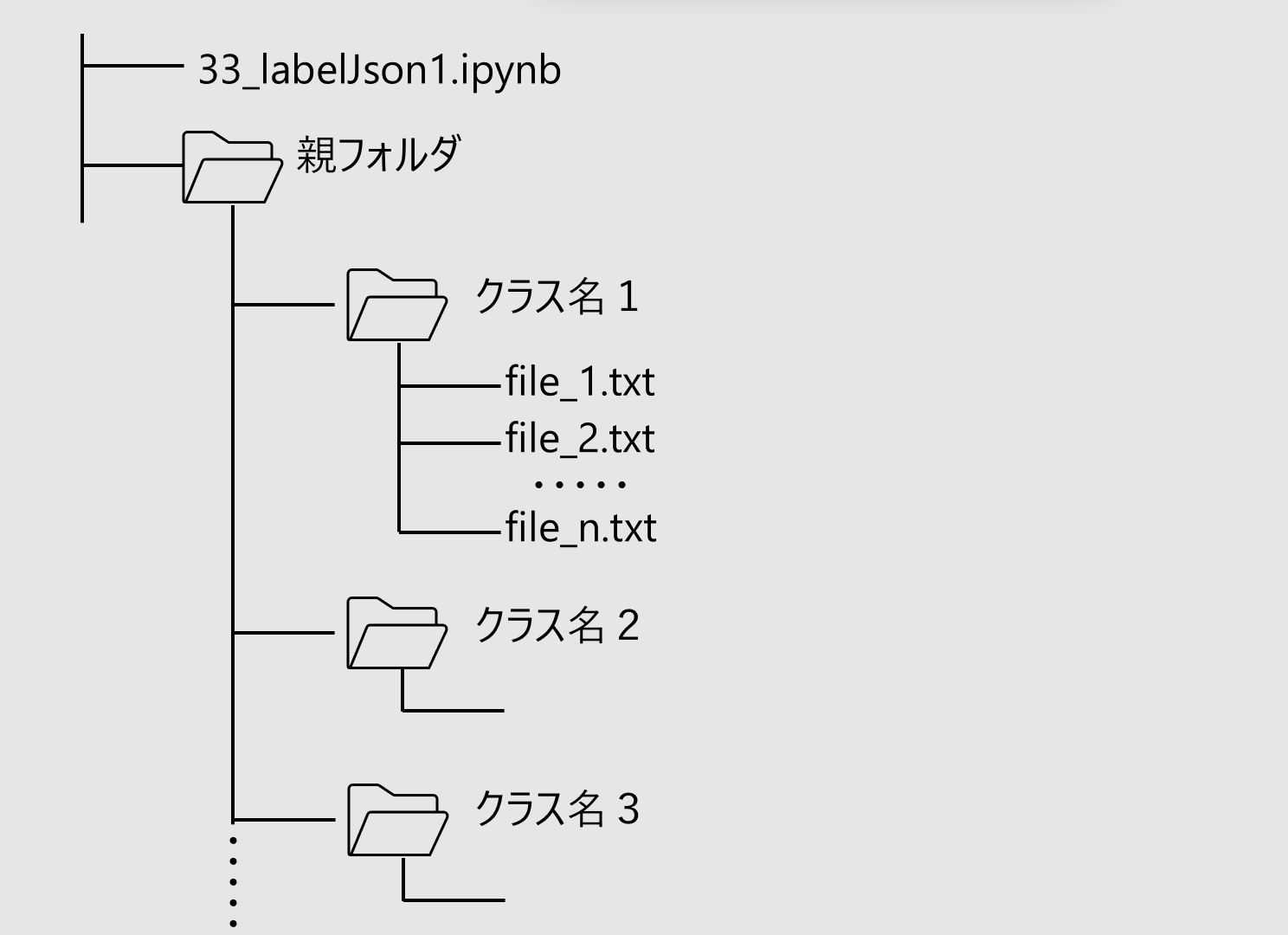
ローカルファイルとして図のようなフォルダ構造にトレーニングデータを作成します。
親フォルダの名前は任意の名前で結構です。
子フォルダの名前はカスタムテキスト分類のラベル名(クラス名)にしてください。そのフォルダ内にテキストファイル(UTF-8/BOM なし)として分類したい発話内容に関連するテキストを用意します。
各々のファイル名は任意で結構です。
今回の例では medical、sports、legal の3つのトピックを適当にネット上からコピーして用意しました。同じものをここでご紹介すると著作権に問題があるので差し控えます。
また4つ目のクラスとして other を用意し、日常会話に登場しそうな発話データを用意します。
用意するクラスの数(子フォルダの数)も任意で結構です。
1つのクラス当たり最低 20くらい用意してください。多ければ多いほど精度の向上が期待できます。
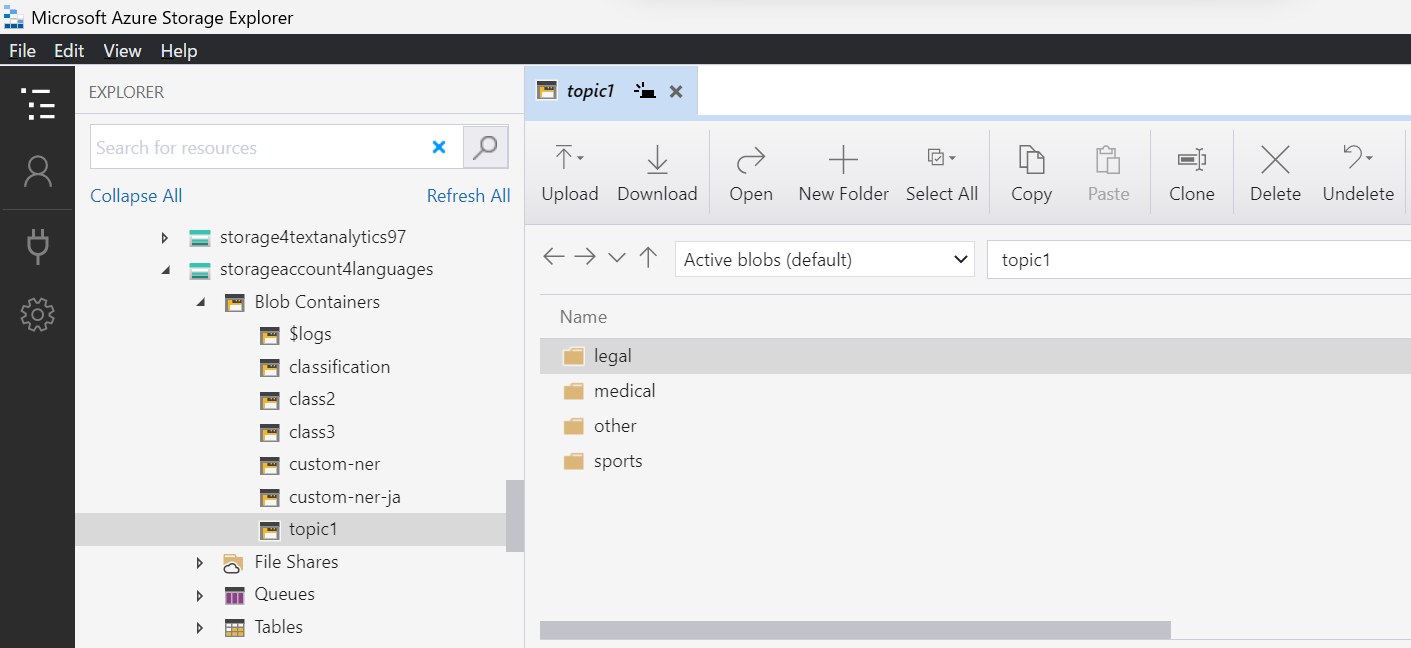
データの準備が終わったら Azure Storage Explorer で作成したコンテナを開き、子フォルダ (クラス名をフォルダ名にしたフォルダ群) をドラッグアンドドロップしてください。
ドラッグアンドドロップするとこんな感じになると思います。(コンテナ topic1 にドラッグアンドドロップしたイメージ)
プロジェクトジョブの作成
プロジェクトジョブはプロジェクト情報とラベル付けメタデータを含みます。
こちらの python notebook をダウンロードして、データ構造の図にあるとおり親フォルダと同じパスに配置してください。
notebook を開いたら変数をセットして実行してください。
DATA_DIR = "temp" # input directory
OUTPUT_FILE = "testjpn3.json" # output json file name
CONTAINER_NAME = "class2" # Blob container name
PROJECT_NAME = "testjpn3" # Project Name
Project_description = "text classification demo" # optional description
LANGUAGE_CODE = "ja-jp"
API_VERSION = "2022-05-01"
- DATA_DIR は親フォルダのフォルダ名です
- OUTPUT_FILE はプロジェクトジョブの JSON ファイル名で、この notebook を実行すると同じパスに出力されます
- CONTAINER_NAME はストレージアカウントに作成した container 名に変えてください
- PROJECT_NAME はプロジェクトの名前です。任意の名前を付けることができますが、会話の文字起こしと AI アシスタント(その1) の設定をそのまま利用する場合は topic1 にします。
- Project_description はオプションで説明をつけます
- LANGUAGE_CODE はテキストデータの言語です。ここでは日本語です。
- API_VERSION は変更せずこのままにします(その時点の最新のものに置き換えてもかまいません)
プロジェクトのインポート
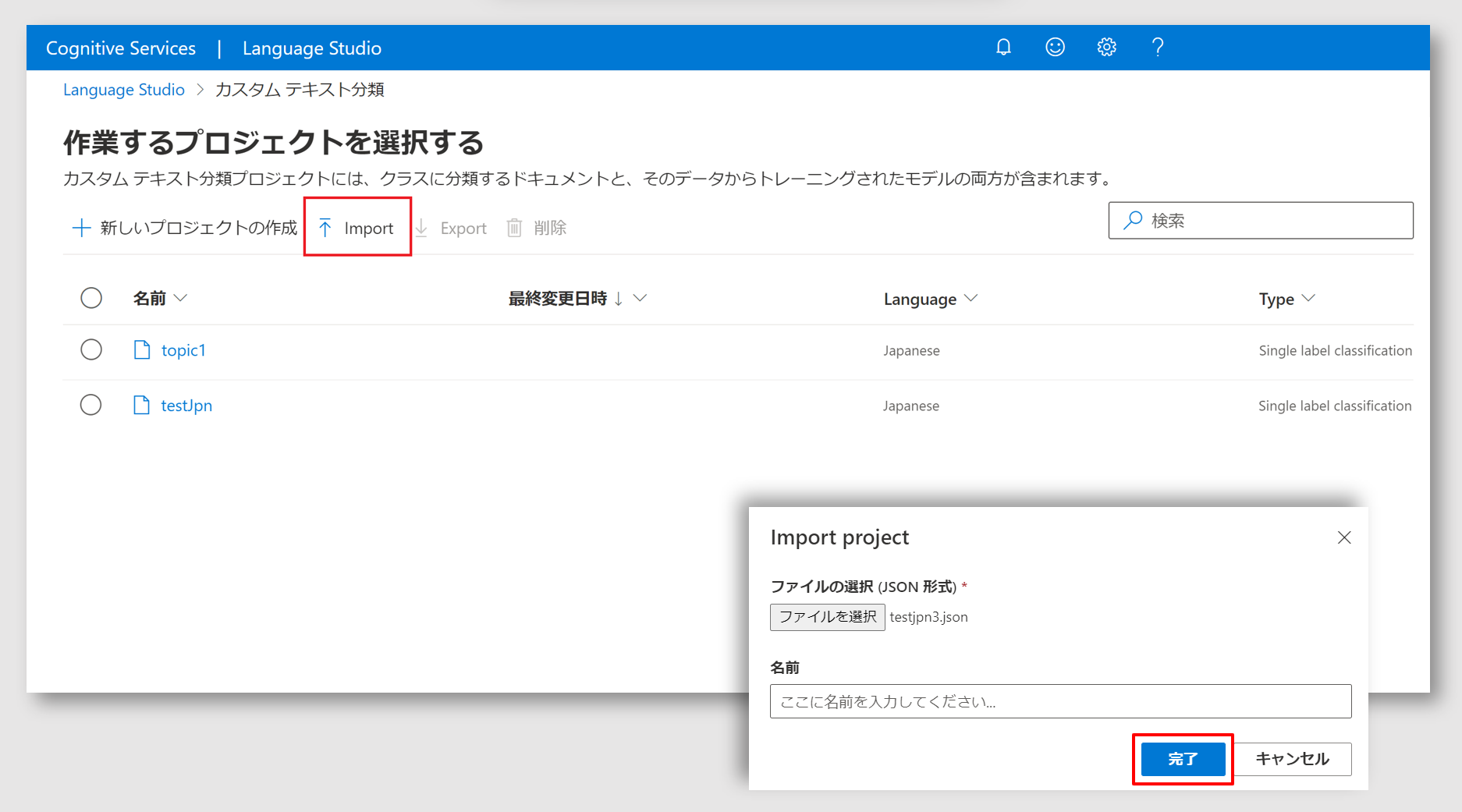
前ステップで作成したプロジェクトジョブの JSON ファイルをカスタムテキスト分類にインポートします。Cognitive Services for Langueage の Language Studio を開き、カスタムテキスト分類のタイルを選択します。
赤枠で示した import をクリックして、前ステップで作成した JSON ファイルを指定します。
名前はブランクのまま 完了ボタンをクリックします。
モデルのトレーニングとデプロイ
ここまでのステップでデータのラベリングまで完了しているので、かなりの作業量が省力化された状況です。残りはモデルトレーニングとデプロイですが、これ以降は 公式クイックスタート のとおりの流れになります。
トレーニング
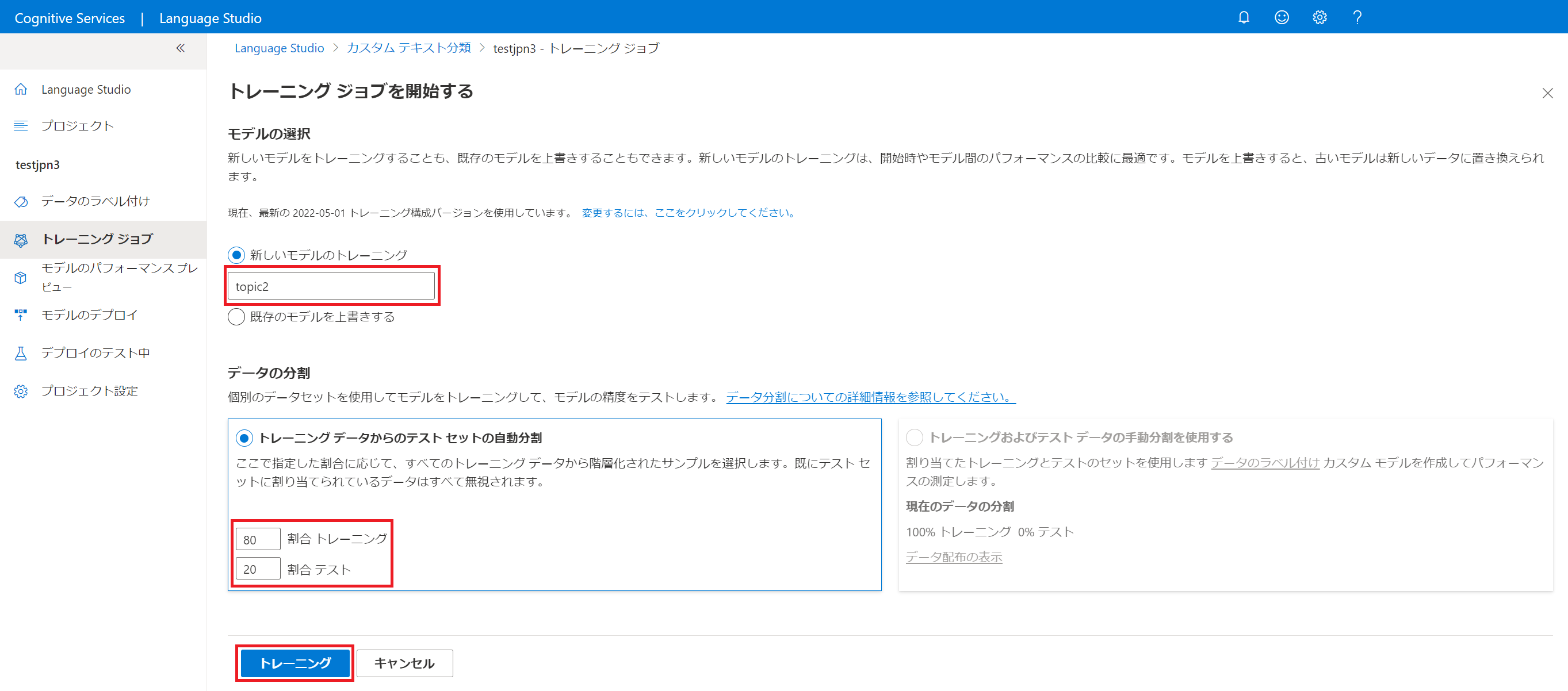
トレーニングジョブの画面で新しいモデルのトレーニング欄に任意のモデル名を指定します。データの分割は既定のままにして、トレーニングボタンをクリックします。
データ量が各クラス 20 テキスト程度だと数分でトレーニングが完了しますが、トレーニング開始までに時間がかかる傾向があるようです。結果的に 10分くらい待たされます。
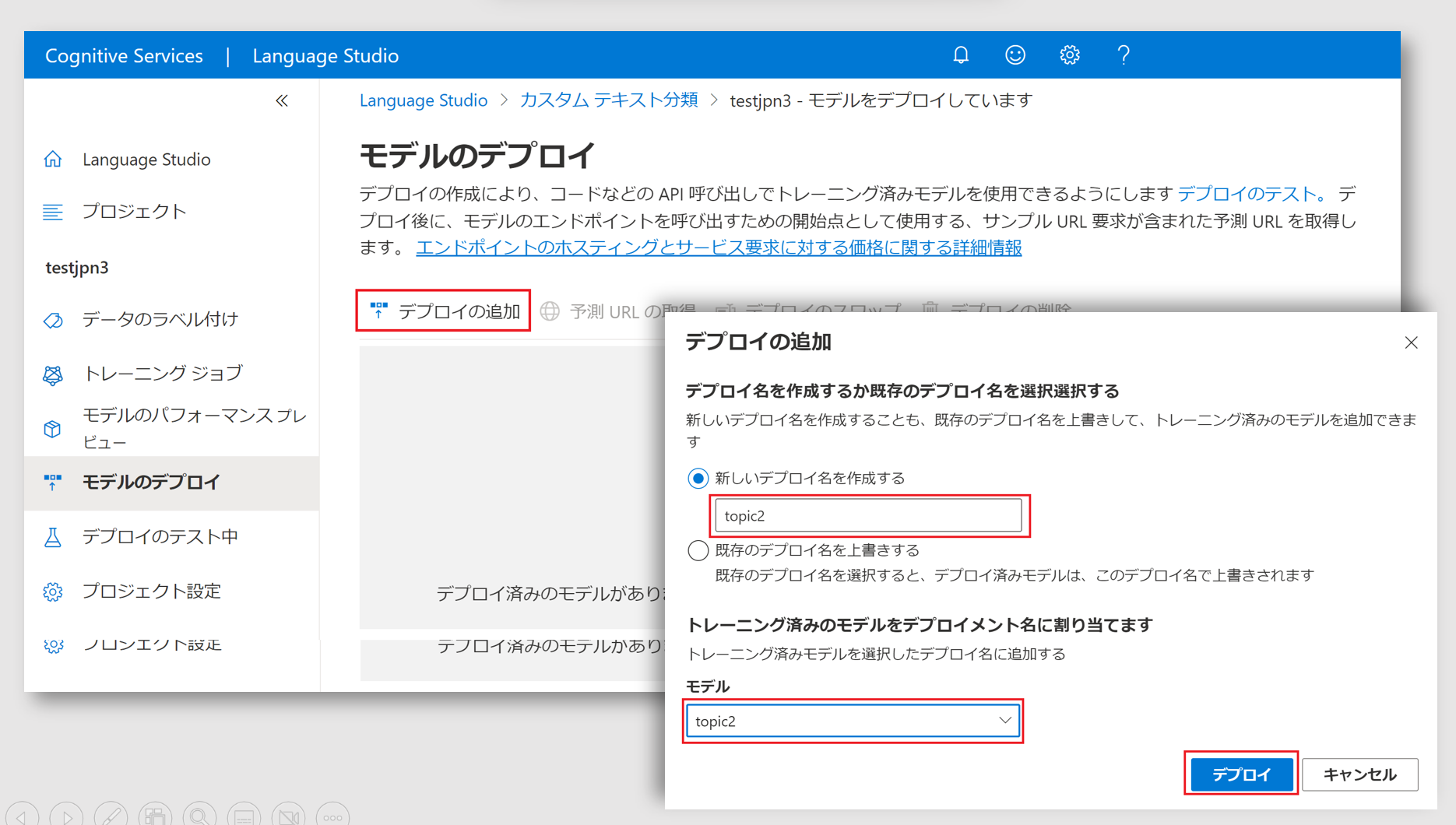
デプロイ
最後にモデルをデプロイします。モデルのデプロイ画面で新しいモデルのトレーニング欄にデプロイ名を指定します。名前は任意ですが、会話の文字起こしと AI アシスタント(その1) の設定をそのまま利用する場合は topic1 にします。
モデル(赤枠)欄はプルダウン可能になっているので、前のステップで作成したモデルを選択します。
デプロイしたら モデルのテスト をしてみましょう。
満足いく結果が得られなかったら、トレーニングに使ったテキストデータを変更したり追加したりしてトレーニングを繰り返します。
おわりに
いかがでしたでしょうか。データの収集は骨が折れる作業ですが、そのあとのラベル付けやカスタムテキスト分類モデルの作成は簡単にすすめることができることを体感いただけたと思います。
なお classify.js の中の writeTopic 関数では分類されたクラスを受け取ったらその値に応じて文字列を出す操作をしました。この部分はご自身の分類トピックに応じて書き替える必要があるのでリマインドいたします。
参考情報
すでに何等かの方法でテキストのラベル付けが CSV ファイルとして完了している場合のために、CSV ファイルから データの準備 のセクションで前提としたフォルダー構造を作成する python notebook スクリプト を用意しました。
入力とする CSV ファイルは text と label をヘッダー行としてもつ 2列の CSV ファイルです。UTF-8 でエンコードしてください。
INPUT_FILE = "test_data.csv" # input file name : UTF-8, with a header line of 1st column as "text" and 2nd as "label"
DATA_DIR = "temp2" # output directory
- INPUT_FILE: 入力とする CSV ファイル名です。このスクリプトファイルと同じパス上にある必要があります。
- DATA_DIR: アウトプットのフォルダ/ファイルが保存される親フォルダ名です。スクリプトの中で作成されるので、あらかじめ作成しておく必要はありません。