このサンプルを動かすには Conversation Transcription Service の Private Preview Key が必要です。
はじめに
多くの AI 分野で Transformer ベースのニューラルモデルが当たり前になってきています。ここ数年の間に Azure Cognitive Services の Speech Services や Language Services ではそれぞれを構成するモデルが Microsoft Turing のテクノロジーを継承する XYZ-CODE によって驚くほど高性能になってきました。その Microsoft Turing は Open AI の GPT-3 が登場するまではパラメタ数で最大を誇っていた巨大モデルです。
ここでは Speech Services の中から会話の文字起こしを紹介して、カスタムテキスト分類と組合せることで AI アシスタントのプロトタイプを作ってみたいと思います。
シナリオ
ブラウザに話しかけることによって文字起こしと同時に話者を分離し、あらかじめ決めておいたトピックが会話の中に登場すると、そのトピックの識別をおこないます。ここで紹介するサンプルコードではトピックが特定されたあとのアクションまで実装しませんが、ドキュメント検索やレコメンデーションを返すようにすることもできます。
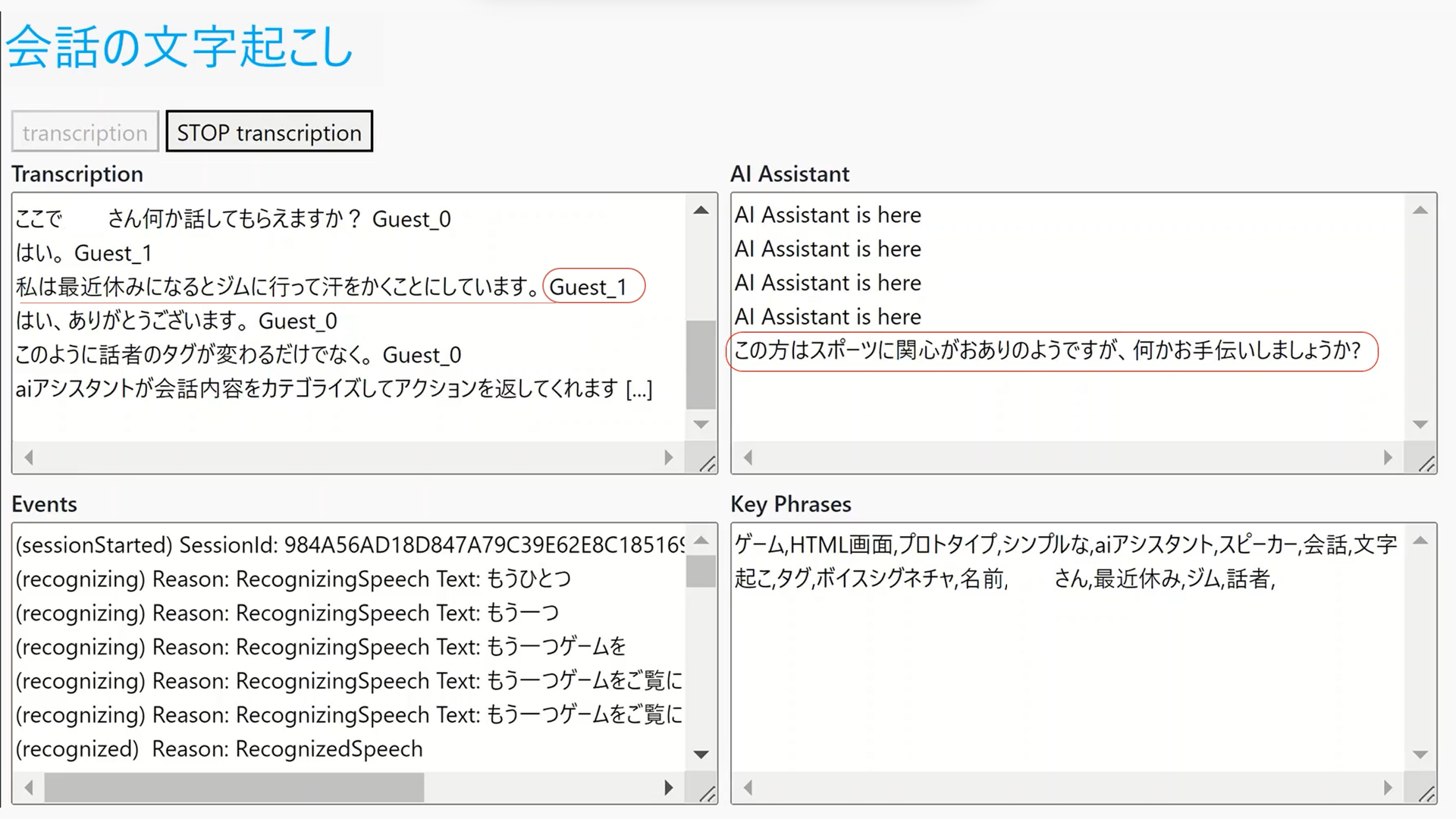
下のスクリーンショットはここで紹介するサンプルコードを実行したときのイメージです。
「私は最近休みになるとジムへ行って汗をかくことにしています」と Guest_1 が話すと、その発話内容から AI Assistant がリアルタイムにテキスト分類を実行してスポーツのトピックを特定します。
技術要素
ここで使う技術要素です。
Azure Cognitive Services
- Speech To Text の中の一つ 会話の文字起こし という機能を使います。
- カスタムテキスト分類 によってテキスト分類をします。
- おまけで キーフレーズ抽出 も使ってみましょう。
今回「その1」では会話の文字起こしまでをあつかって、カスタムテキスト分類を使ったモデルの準備は「その2」へ回すことにします
前提と注意事項
ここでは Azure Cognitive Services の スピーチサービス と 言語サービスを利用しますが、それぞれのサービスのデプロイが完了していることを前提としています。
この記事の投稿時点では、会話の文字起こしを利用するために次のリージョンのいずれかでスピーチサービスをデプロイしている必要があります。
- Central US、East Asia、East Us、West Europe
同じように、言語サービスの中でもここで用いるカスタムテキスト分類は、次のリージョンのいずれかでデプロイされている必要があります。
- West US、East US、East US 2、West US 3、South Central US、West Europe、North Europe、UK south、Australia East
なお、ここで利用する会話の文字起こしの中で、モノラルマイク入力方式は現在プレビュー機能となってる点にご留意ください。
サンプルコード
ここで紹介するサンプルコードは一式 GitHub リポジトリ の sample_javascript フォルダにアップロードしているので、そのリポジトリをクローンしてください。
sample_javascript フォルダ内のファイルの用途は次のとおりです。
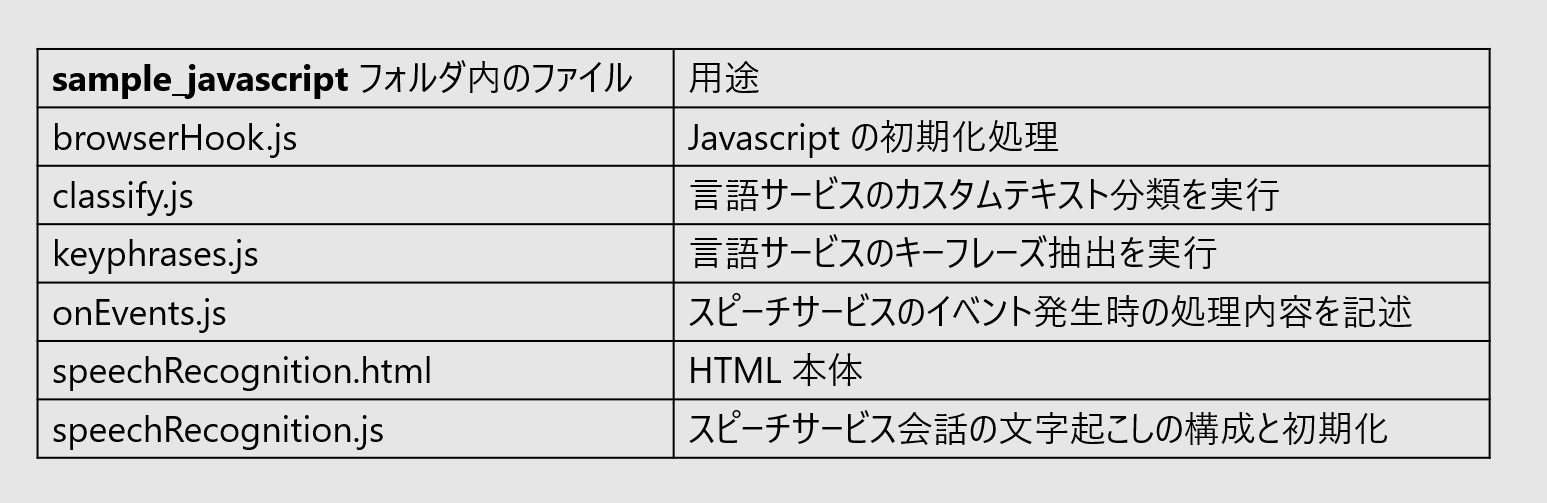
speechRecognition.html と browserHook.js は一般的な javascript の処理なので説明は割愛します。それ以外のファイルの処理内容について順にみていきたいと思います。
speechRecognition.js
会話の文字起こしの構成と初期化をします。会話の文字起こしでは通常の文字起こしと違って話者を分離してタグ付けすることができます。
まずこのファイルの始めにある speech-key と region 情報をご自身でデプロイしたサービスの情報で置き換えてください。
const speech_key = "<-- speech-key -->";
const regionOptions = "<-- region -->";
基本的には公式クイックスタートに記載されている内容なのですが、いくつか異なる点があります。
クイックスタートでは事前に声紋を登録する必要がありますがここでは不要です。その代わり話者は Guest_0、Guest_1 … というラベルになります。それに合わせてクイックスタートの javascript サンプルを書替える必要があります。
またクイックスタートでは入力がマルチチャネルオーディオファイルであることを想定していますが、ここではモノラルマイクを入力とします。このモノラルマイク入力方式(Property:TranscriptionService_SingleChannel)は現在プレビュー機能となってる点にご留意ください。これを利用するために Privaet Preview Key をセットする必要があります。
speechConfig.setProperty("<----- Private Preview Key ----->", "true");
speechConfig.setProperty("ConversationTranscriptionInRoomAndOnline", "true");
speechConfig.setProperty("DifferentiateGuestSpeakers", "true");
speechConfig.setProperty("TranscriptionService_SingleChannel", "true");
公式クイックスタートのコードサンプルにある user1、user2 を取り除くと、コードは次のようになります。
またイベント発生時の処理を別のファイル onEvents.js で行うために、ここでは関数名を記述するだけにしてシンプルにしています。
var conversation = SpeechSDK.Conversation.createConversationAsync(speechConfig, "myConversation");
transcriber = new SpeechSDK.ConversationTranscriber(audioConfig); // Global variable
// attach the transcriber to the conversation
transcriber.joinConversationAsync(conversation,
function () {
transcriber.transcribing = onRecognizing;
transcriber.transcribed = onRecognized;
transcriber.canceled = onCanceled;
transcriber.sessionStarted = onSessionStarted;
transcriber.sessionStopped = onSessionStopped;
// begin conversation transcription
transcriber.startTranscribingAsync(
function () { },
function (err) {
console.trace("err - starting transcription: " + err);
}
);
},
);
onEvents.js
このファイルは 6つの関数から構成されています。

それぞれの関数の処理内容の概要は上表のとおりですが、発話の結果が確定したときに呼出される onRecognized の処理内容について解説しましょう。
このサンプルコードでは発話内容が確定したとき、文字列長が 2 より大きい場合に次の処理をおこないます。
- ブラウザへの結果の書込み
- キーフレーズ抽出処理
文字列長の条件を入れるのは、「え?」であるとか、意味もなく表示される「?」のような文字をブラウザ表示させないためです。ノイズなどによって意味のない 1~2 文字の発話が返されることがあるため、このような簡単な後処理を挿入するようにしています。
const wordlength = 2; // threshold to invoke key phrase
const classlength = 20; // threshold to invoke key classification
さらに文字列長が 20 よりも大きいかったとき
- カスタムテキスト分類の呼出
をおこないます。確定した発話内容にカスタムテキスト分類処理をするに値するかどうかを、単純に文字列長で判断しています。
下のコードでは、getKeyphrases でキーフレーズ抽出処理を行い、getTopic でカスタムテキスト分類処理をおこないます。
function onRecognized(sender, recognitionEventArgs) {
let result = recognitionEventArgs.result;
if (result.text.length > wordlength) {
onRecognizedResult(result);
getKeyphrases(result.text);
if (result.text.length > classlength) {
getTopic(result.text);
}
}
//console.log("(transcribed) text: " + result.text);
//console.log("(transcribed) speakerId: " + result.speakerId);
}
keyphrases.js
キーフレーズ抽出をおこないます。Key Phrase ウインドへの書込みもここで処理します。
言語サービスの language-key と language endpoint をセットしてください。
const languageKey = '<-- language-key -->';
const languageEndpoint = 'https://<-- language endpoint -->/';
公式クイックスタートの SDK サンプルには JavaScript も用意されていますが、これは Node.js を想定しているようなので、ここでは REST API を使いました。REST API サンプルのとおりの作りにしていますので説明は割愛します。
classify.js
ここでも公式クイックスタート にならってコーディングしています。
JavaScript 用の SDK サンプルも用意されているように見受けられるのですが、テキスト分類のものが見当たらないので、ここでも REST API を利用しました。
まず言語サービスの language-key と language endpoint は キーフレーズ抽出の keyphrases.js の中で既に指定しているので、classify.js の中ではコメントアウトして使っていません。
// const languageKey = '<-- language-key -->>';
// const languageEndpoint = 'https://<-- language-endpoint -->/';
カスタムテキスト分類のモデルを呼出すためプロジェクト名とデプロイ名を指定します。ここでは projectName と deploymentName の両方で topic1 という名前をハードコードしています。
let payload = {
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
...
]
},
"tasks": [
{
"kind": "CustomSingleLabelClassification",
"taskName": "Single Classification Label",
"parameters": {
"projectName": "topic1",
"deploymentName": "topic1"
}
}
]
}
REST API ではテキスト分類するデータを POST すると、結果の URL が operation-location フィールドに返されます。この URL を operation_location 変数にストアして後続の getCategory 関数をコールします。
axios({
method: 'POST',
...
}).then(response => {
operation_location = response.headers['operation-location'];
getCategory(operation_location)
}
)
getCategory 関数では status が succeeded に代わるまで 200ms 毎に GET する処理を繰り返します。10 回ループしても status が succeeded に変わらなかったら、ここでは処理をあきらめて処理を終了するようにしています。これは文字起こしの処理を優先させ、カスタムテキスト分類はベストエフォートで処理しようとする設計です。
なお、カスタムテキスト分類は利用頻度が少ないと初回のコールで待たされる時間が長くなるようです。デモをする際には事前にウォームアップで呼出しておくと比較的良好なパフォーマンスで結果が返るように感じます。
async function getCategory(url) {
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
let status = "notStarted";
for (let j = 0; j < 10; j++) {
... //GET 処理
...
if (status == "succeeded"){
break; // don't have to wait if the status is "succeeded"
}
await sleep(200);
} //end of for loop
if (confidenceScore > 0.85) {
writeTopic(category);
}
};
10 回のループの間にカスタムテキスト分類が終了したら、confidenceScore を確認し 0.85 よりも高い confidenceore の場合には、カスタムテキスト分類のクラスカテゴリを category にセットして後続の writeTopic 関数を呼出します。
if ( status == "succeeded" ){
category = response.data.tasks.items[0].results.documents[0].class[0].category;
confidenceScore = response.data.tasks.items[0].results.documents[0].class[0].confidenceScore;
}
writeTopic 関数は非常にラフに作っています。
ここでは単純に category 変数の値に応じて AI Assistant ウインドへ書きだす文字列を変えているだけです。
function writeTopic(category) {
ClassDiv.scrollTop = ClassDiv.scrollHeight;
switch (category) {
case "medical":
ClassDiv.innerHTML += `このお客さまはヘルスケアの話をされていますが、お調べしましょうか?\r\n`;
break;
case "sports":
ClassDiv.innerHTML += `この方はスポーツに関心がおありのようですが、何かお手伝いしましょうか?\r\n`;
break;
case "legal":
ClassDiv.innerHTML += `この方は法律相談を希望されていますが、関係文書を探しましょうか?\r\n`;
break;
case "other":
ClassDiv.innerHTML += `AI Assistant is here\r\n`;
break;
}
}
おわりに
いかがでしたでしょうか。このサンプルをとおして複数の Cognitive Services を組合せることで AI アシスタントが現実のものとなる雰囲気を感じていただけると思います。
いっぽう、マルチスレッド化が難しい JavaScript でいくつもの処理を実装するのはパフォーマンスの観点で工夫が必要であることが分りました。とくにカスタムテキスト分類のように推論に時間がかかる処理をかませるには今回試したような工夫が必要です。
リアルタイム処理にこだわるようであればマルチスレッド化が可能なデスクトップアプリケーションの開発も考えられます。
いっぽうで会話の文字起こしには非同期処理をするオプションが提供されています。こういったオプションを利用して、例えば Azure Functions でバックグラウンド処理させる方法も考えられます。
ここで紹介したサンプルコードを動かすにはカスタムテキスト分類モデルが完成している必要がありますが、カスタムテキスト分類モデルの作成については別の記事にしたいと思います。
それまでの間、カスタムテキスト分類なしのサンプルコードも 同じ GutHub リポジトリの cts フォルダに用意しておいたので興味のある方は利用してください。
参考情報
カスタムテキスト分類モデルの作成はこちらの投稿をご覧ください。
会話の文字起こしと AI アシスタント (その2)