追記
CuPy v7でplanをcontext managerとして扱う機能が追加されたので、この記事の方法よりそちらを使う方がオススメです。
はじめに
CuPyにv4からFFTが追加されました。
これにより、NumPyと同じインターフェースでcuFFTを使うことができるようになりました。
しかし、NumPyとインターフェースを揃えるために、cuFFTの性能を使い切れていない場合があります。
この記事では、CuPyの内部実装を利用することによってFFTを更に高速化する方法を紹介します。
(注)この方法は仕様になっていない内部実装を利用するので、minor updateでも使えなくなる可能性があります。
環境
CPU: Intel Core i7-8700K
GPU: GeForce GTX 1080 Ti
CUDA: 9.1
NumPy: 1.15.2 (+MKL)
CuPy: 4.4.1
長さ1024の単精度の配列を100個ずつ100回FFTしたときの速度を計測します。
計測用ソースコードはこちら。
NumPy
100×1024のndarrayを作って、100回FFTします。
x_cpu = numpy.random.rand(100, 1024) + 1j * numpy.random.rand(100, 1024)
x_cpu = x_cpu.astype(numpy.complex64)
with timer('numpy.fft.fft'):
for i in range(100):
numpy.fft.fft(x_cpu)
numpy.fft.fft: 93.943119 ms
CuPy
CuPyはNumPyと同じインターフェースを持つので、基本的にnumpyをcupyに置換するだけでGPUを使うコードになります。
x_gpu = cupy.asarray(x_cpu)
with timer('cupy.fft.fft'):
for i in range(100):
cupy.fft.fft(x_gpu)
cupy.fft.fft: 24.476290 ms
すでにこの時点で4倍弱速くなっていますが、実はこのコードではcuFFTのplanを作る処理がボトルネックとなっています。
今回のように同じサイズのFFTを何回も行う場合はplanを使いまわした方が速くなります。
cupy.cuda.cufft.Plan1d
NumPyと同じインターフェースでplanを使い回すことはできないので、CuPyの内部実装でplanを管理しているクラスを使います。
with timer('cupy.cuda.cufft.Plan1d'):
plan = cufft.Plan1d(1024, cufft.CUFFT_C2C, 100)
for i in range(100):
y_gpu = plan.get_output_array(x_gpu)
plan.fft(x_gpu, y_gpu, cufft.CUFFT_FORWARD)
cupy.cuda.cufft.Plan1d: 1.344442 ms
さらに1桁速くなりました。
一方で、インターフェースはいろいろ引数が増えてわかりにくくなっています。
この例はまだマシな方で、直接Plan1dを呼ぶと実装がかなりややこしくなることがあります。
そういう場合でもcupy.fftは型やサイズや軸などをよしなに調整してくれるので便利です。
配列の長さを変えた場合
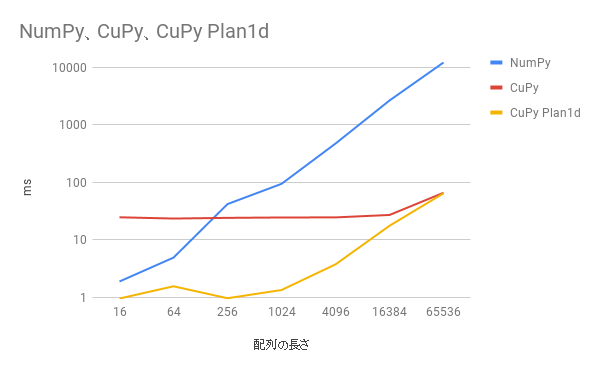
配列の長さが短い時に高速化されています。
データが大きくなるとFFTの実行の方が時間がかかるようになって、planを作るオーバーヘッドが見えなくなります。
まとめ
内部実装を利用してPlan1dを直接使ったほうが速くなる。
コードはややこしくなるし仕様になっている機能でもないので、速度をそれほど必要としないならcupy.fftを使ったほうが良い。