めっちゃ嬉しい! PyTorch触り始めの時に書いた記事なので、少しUpdateしました.
Pytorchの文法まとめ
— I.T. (@_IT_MT) February 25, 2020
他記事と比較しても網羅性が高い上、非常に分かりやすい解説がされていました。
Pytorch初めて触る方にぜひオススメしたい記事です。https://t.co/8oXhyRtOTP
内容
今回は, Deep Learningのframeworkである"PyTorch"の入門を書いていきたいと思います.
TensorFlowの人気がまだ根強い感じが否めませんが, 徐々にPyTorchに移行している方が多い印象もまた否めません.
TensorFlowはtensorboardが使えることが強みですが, 最近PyTorchでも公式にサポートされるようになりました.
VISUALIZING MODELS, DATA, AND TRAINING WITH TENSORBOARD
使ってみた感想としては, 圧倒的にtensorflowより使いやすいです.
特にdefine by runな性質でdebugが非常にしやすいです.
それなのに何故か研究ではTensorFlowを使ってます(githubにあったのがTensorFlowで書いてあったので...)笑. 修士課程に入りPyTorchに完全に移行しました!
アメリカでのGoogleトレンド

日本でのGoogleトレンド
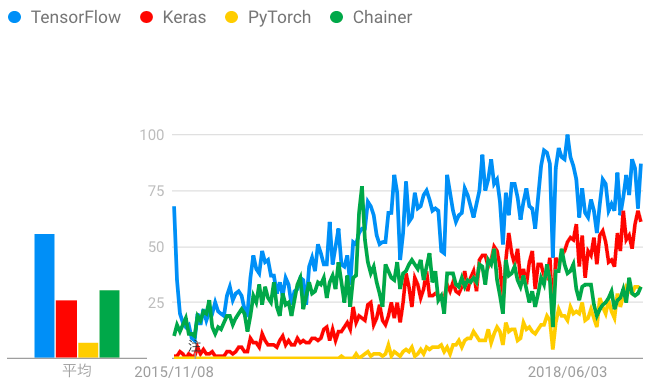
(PyTorch 入門!人気急上昇中のPyTorchで知っておくべき6つの基礎知識より)
すでに山ほど類似記事がありそうですが, 自分の頭の中の整理ということで書きます.
基本的にはDeep Learning with PyTorch: A 60 Minute Blitzを参考にしています.
適宜公式のdocumentを見てみたり, 実際に使用する中で感じたことや思ったこともまとめていきます.
誤り等ございましたら編集リクエストへお願い致します.
WARNINGS! : この記事はDeep Neural Networkを解説する記事ではありません.
ニューラルネットワークをライブラリなしで実装する [MNIST]という記事を書いているのでそちらも是非ご覧ください.
また, 著者は機械学習もライブラリも初心者です.
鵜呑みにしないようにしてください.
バージョンなどにより, 日々仕様が変わっていますし, optionなども見れるので, 是非公式のdocumentを読む癖をつけましょう.
$ python --version
Python 3.6.8 :: Anaconda, Inc.
$ pip show torch
(中略)
Version: 1.0.1.post2
(中略)
$ pip show numpy
(中略)
Version: 1.16.2
(中略)
WHAT IS PYTORCH?
それでは見ていきましょう.
It’s a Python-based scientific computing package targeted at two sets of audiences:
- A replacement for NumPy to use the power of GPUs
- a deep learning research platform that provides maximum flexibility and speed
numPyをGPUで使える形にする役割と, 柔軟性と速度を併せ持つdeep learningのplatformの役割を備えているようです.
Getting Started
Tensors
基本的には Tensor というものを計算していくことになります.
まずはTensorの作り方から. numpyとだいたい一緒といったところでしょうか?
empty, rand, zeros, randn_likeなどは見ればだいたい分かりそうなので解説は不要ですね.
# Construct a 5x3 matrix, uninitialized:
>>> x = torch.empty(5,3)
>>> x
tensor([[-1.3034e-05, 3.0792e-41, 6.0133e-01],
[ 3.5492e-01, 3.5542e-01, 4.0113e-01],
[ 4.7963e-01, 2.7178e-01, 1.0731e-01],
[ 1.1640e-01, 3.4136e-01, 1.1108e-01],
[ 2.2227e-01, 3.4427e-01, 8.7127e-01]])
# Construct a randomly initialized matrix:
>>> x = torch.rand(5,3)
>>> x
tensor([[0.1811, 0.8989, 0.2450],
[0.8190, 0.1191, 0.3347],
[0.9626, 0.5488, 0.7544],
[0.8444, 0.9541, 0.6652],
[0.1394, 0.8908, 0.6354]])
# Construct a matrix filled zeros and of dtype long:
>>> x = torch.zeros(5,3, dtype=torch.long)
>>> x
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
# Construct a tensor directly from data:
>>> x = torch.Tensor(5,3)
>>> x
tensor([[-1.3038e-05, 3.0792e-41, 2.4501e-01],
[ 8.1902e-01, 1.1915e-01, 3.3470e-01],
[ 9.6263e-01, 5.4881e-01, 7.5440e-01],
[ 8.4440e-01, 9.5411e-01, 6.6519e-01],
[ 1.3944e-01, 8.9084e-01, 6.3540e-01]])
# or create a tensor based on an existing tensor. These methods will reuse properties of the input tensor, e.g. dtype, unless new values are provided by user
>>> x = torch.Tensor([5.5, 3])
>>> x
tensor([5.5000, 3.0000])
>>> x = x.new_ones(5, 3, dtype=torch.double)
>>> x
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
>>> x = torch.randn_like(x, dtype=torch.double)
>>> x
tensor([[ 0.1804, 0.5438, 0.2560],
[-0.9047, -0.3714, -0.7198],
[-1.8642, -0.3904, 1.0680],
[ 0.4988, 0.7488, -1.1682],
[ 0.3947, 0.5058, 1.7056]], dtype=torch.float64)
基本的にはtorch.Tensorをよく使うような気がします. ということでtorch.Tensorについてもう少し詳しく見てみましょう.
tensorにはdatatypeが複数あります.
よく使うのは, torch.long(64bitのint型)とtorch.float(32bitのfloat)です.
torch.Tensor(sequence, dtype=torch.long/float)のように設定します.
あるいは, torch.LongTensor(sequence), torch.FloatTensor(sequence)のようにも出来ます.
torch.Tensor is an alias for the default tensor type (torch.FloatTensor).
とあるので, 特にdtypeを指定しない限り, float型になります. intで計算したいのに設定しないでfloatになっていた!なんてことは自分はよくあるので気をつけたいところです.
上記でdtypeを書いていないものがfloatになっていましたね.

numpyでも形状は非常に大事でした. それはtensorになっても変わりません.
pytorchではshapeでもsizeでも同じ結果になります.
>>> x
tensor([[ 0.1804, 0.5438, 0.2560],
[-0.9047, -0.3714, -0.7198],
[-1.8642, -0.3904, 1.0680],
[ 0.4988, 0.7488, -1.1682],
[ 0.3947, 0.5058, 1.7056]], dtype=torch.float64)
>>> x.shape
torch.Size([5, 3])
>>> x.size()
torch.Size([5, 3])
Operations
基本的には, numpyのように計算できますし, torchメソッドを使っても出来ます.
>>> x
tensor([[ 0.6955, 0.2636, -0.0984],
[ 0.3125, -0.2799, -1.9001],
[-1.4041, 0.0215, 2.6158],
[ 0.1253, 0.3179, -0.1846],
[ 0.4611, -1.5148, -0.2699]])
>>> y = torch.rand(5, 3)
>>> y
tensor([[0.9034, 0.8075, 0.1443],
[0.7220, 0.3641, 0.4566],
[0.8272, 0.7389, 0.4603],
[0.3441, 0.9204, 0.3187],
[0.8507, 0.2455, 0.7189]])
>>> torch.add(x, y)
tensor([[ 1.5989, 1.0711, 0.0458],
[ 1.0345, 0.0843, -1.4435],
[-0.5769, 0.7604, 3.0761],
[ 0.4695, 1.2383, 0.1341],
[ 1.3118, -1.2694, 0.4490]])
>>> x+y
tensor([[ 1.5989, 1.0711, 0.0458],
[ 1.0345, 0.0843, -1.4435],
[-0.5769, 0.7604, 3.0761],
[ 0.4695, 1.2383, 0.1341],
[ 1.3118, -1.2694, 0.4490]])
ここまでは非破壊操作です.
out=で出力先を指定するか, add_()メソッドを使っても出来ます. またはy = x + yのように安直に計算してもできます. 適当にやればできる感じです.
>>> result = torch.empty(5, 3)
>>> torch.add(x, y, out=result)
>>> result
tensor([[ 1.5989, 1.0711, 0.0458],
[ 1.0345, 0.0843, -1.4435],
[-0.5769, 0.7604, 3.0761],
[ 0.4695, 1.2383, 0.1341],
[ 1.3118, -1.2694, 0.4490]])
>>> y.add_(x)
>>> y
tensor([[ 1.5989, 1.0711, 0.0458],
[ 1.0345, 0.0843, -1.4435],
[-0.5769, 0.7604, 3.0761],
[ 0.4695, 1.2383, 0.1341],
[ 1.3118, -1.2694, 0.4490]])
基本はnumpy likeなのでスライシングも同じようにできます.
>>> x
tensor([[ 0.6955, 0.2636, -0.0984],
[ 0.3125, -0.2799, -1.9001],
[-1.4041, 0.0215, 2.6158],
[ 0.1253, 0.3179, -0.1846],
[ 0.4611, -1.5148, -0.2699]])
>>> x[:, 1]
tensor([ 0.2636, -0.2799, 0.0215, 0.3179, -1.5148])
one-hotベクトルにしたり, ベクトルを1行の行列にしたり, という作業はよくやりますね. このあたりに関しては, .view(,) が使えます.
>>> x = torch.randn(4, 4)
>>> x
tensor([[-1.5152, -0.0182, -1.1180, -0.9048],
[-0.7187, 1.3185, -1.5836, -0.6032],
[ 0.0673, 0.9009, 0.2790, -0.4238],
[ 1.1689, -0.7668, 0.9765, 1.3840]])
>>> y = x.view(16)
>>> y
tensor([-1.5152, -0.0182, -1.1180, -0.9048, -0.7187, 1.3185, -1.5836, -0.6032,
0.0673, 0.9009, 0.2790, -0.4238, 1.1689, -0.7668, 0.9765, 1.3840])
>>> z = x.view(-1, 8)
>>> z
tensor([[-1.5152, -0.0182, -1.1180, -0.9048, -0.7187, 1.3185, -1.5836, -0.6032],
[ 0.0673, 0.9009, 0.2790, -0.4238, 1.1689, -0.7668, 0.9765, 1.3840]])
そろそろtensorに飽きてきました笑. tensorではなく, 普通の数字として扱いたいですね.
そんなときは, .item()が使えます.
>>> x = torch.randn(1)
>>> x
tensor([0.6574])
>>> x.item()
0.6574012041091919
しかしこれ,
If you have a one element tensor, use .item() to get the value as a Python number
とあるように, tensorに要素が1つしかないときしか使えないんです.
>>> x = torch.randn(4, 4)
>>> x
tensor([[-0.5195, 0.1055, 0.1312, -0.0954],
[-1.0027, -0.8331, -0.3065, -0.4124],
[-0.3655, 0.0969, 1.1048, -0.0528],
[ 0.2131, -0.6035, -0.7309, -0.6538]])
>>> x.item()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: only one element tensors can be converted to Python scalars
え, では, こういうときどうするんでしょう.
>>> for row in x:
... for element in row:
... print(element)
...
tensor(-0.5195)
tensor(0.1055)
tensor(0.1312)
tensor(-0.0954)
tensor(-1.0027)
tensor(-0.8331)
tensor(-0.3065)
tensor(-0.4124)
tensor(-0.3655)
tensor(0.0969)
tensor(1.1048)
tensor(-0.0528)
tensor(0.2131)
tensor(-0.6035)
tensor(-0.7309)
tensor(-0.6538)
ただ, 行列計算することで計算を高速化しているのにfor文を使うこと自体矛盾している気もしますし, あまり使う機会はないかと思います.
NumPy Bridge
pytorchを使うからといって全くnumpyを使わなくなるわけではありません. numpyとpytorchをリンクできなければいけないことも多いでしょう.
tensorからnumpyは, .numpy()メソッドが,
numpyからtensorは, .from_numpy()メソッドがあります.
Converting a Torch Tensor to a NumPy Array
>>> a = torch.ones(5)
>>> a
tensor([1., 1., 1., 1., 1.])
>>> b = a.numpy()
>>> b
array([1., 1., 1., 1., 1.], dtype=float32)
>>> a.add_(1)
>>> a
tensor([2., 2., 2., 2., 2.])
>>> b
array([2., 2., 2., 2., 2.], dtype=float32)
ここで後半に注目しましょう. aから作成したbは, aを変更すると一緒に変更されいます. 参照渡しということです.
これ結構大事なことです.
なんでTensor更新されないの?
なんて場合は, 大抵は値渡しのつもりでプログラムを書いたけど実は参照渡しで書き換えられていた...なんてこと(僕は未熟なので)結構あります. そしてこれがなかなか気づかなくて時間が無限に溶ける...orz
ではでは, 値渡ししたい場合はどうすればいいか. それは簡単、.clone() を使えばOK!
Converting NumPy Array to Torch Tensor
>>> import numpy as np
>>> a = np.ones(5)
>>> a
array([1., 1., 1., 1., 1.])
>>> b = torch.from_numpy(a)
>>> np.add(a, 1, out=a)
array([2., 2., 2., 2., 2.])
こちらも同じく参照渡しです.
CUDA Tensors
cudaを使って計算する場合にやることが簡単です.
tensorを作成するときに, device=で指定するか, .to(device)にするだけです.
# let us run this cell only if CUDA is available
# We will use ``torch.device`` objects to move tensors in and out of GPU
if torch.cuda.is_available():
device = torch.device("cuda") # a CUDA device object
y = torch.ones_like(x, device=device) # directly create a tensor on GPU
x = x.to(device) # or just use strings ``.to("cuda")``
z = x + y
print(z)
print(z.to("cpu", torch.double)) # ``.to`` can also change dtype together!
AUTOGRAD: AUTOMATIC DIFFERENTIATION
ニューラルネットワークの基本はBP(逆誤差伝播)です.
すなわち, 微分操作が必要不可欠です.
この章ではその微分操作を自動に行ってくれるAUTOGRADについて見ていきましょう.
Tensor
torch.Tensor is the central class of the package. If you set its attribute .requires_grad as True, it starts to track all operations on it. When you finish your computation you can call .backward() and have all the gradients computed automatically. The gradient for this tensor will be accumulated into .grad attribute.
torch.Tensorには, .require_grad, **.grad**というattributeが, **.backward()というメソッドを持っています.
この.require_grad**をTrueに設定すれば, このtensorに与えられる演算を全て記憶し, **.backward()**により, 勾配を計算してくれます. その勾配の計算結果は, **.grad**が保持しています.
計算グラフを構築するということでしょうか.
To stop a tensor from tracking history, you can call .detach() to detach it from the computation history, and to prevent future computation from being tracked.
モデルのテスト時などの勾配計算が必要ないときは, **.detach()**メソッドにより解除できます.
To prevent tracking history (and using memory), you can also wrap the code block in with torch.no_grad():. This can be particularly helpful when evaluating a model because the model may have trainable parameters with requires_grad=True, but for which we don’t need the gradients.
これは, **with torch.no_grad()**のブロック文のなかで記述しても可能です. メモリの節約にもなります.
Tensor and Function are interconnected and build up an acyclic graph, that encodes a complete history of computation. Each tensor has a .grad_fn attribute that references a Function that has created the Tensor (except for Tensors created by the user - their grad_fn is None).
**.grad_fn**は, 勾配計算のために, 演算に用いた関数を示してくれます.
と書いてみましたが, やってみないとよくわかりませんね.
やってみましょう.
>>> import torch
>>> x = torch.ones(2, 2, requires_grad=True)
>>> x
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
>>> y = x + 2
>>> y
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
# 入力xのrequires_gradをTrueにしたので, yもTrueになっている
>>> y.requires_grad
True
>>> y.grad_fn
<AddBackward0 object at 0x7fa49e83cfd0>
>>> z = y * y * 3
>>> z
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>)
>>> out = z.mean()
>>> out
tensor(27., grad_fn=<MeanBackward1>)
ところで, 基本的にはdefaultでは.requires_gradはFalseです.
>>> a = torch.randn(2, 2)
>>> a
tensor([[-1.0330, 1.7042],
[ 1.0986, 0.6040]])
>>> a = ((a * 3) / (a - 1))
>>> a
tensor([[ 1.5244, 7.2600],
[33.4126, -4.5753]])
# defaultではFalseになる
>>> print(a.requires_grad)
False
>>> a.requires_grad_(True)
tensor([[ 1.5244, 7.2600],
[33.4126, -4.5753]], requires_grad=True)
>>> b = (a * a).sum()
# 設定すればTrueになる
>>> print(b.grad_fn)
<SumBackward0 object at 0x7fa49e83cfd0>
Gradients
それでは勾配を見ていきましょう. 先程の続きです.
参考にどんな計算式だったか載せておきます.
\begin{equation}
x =
\begin{pmatrix}
1 & 1 \\
1 & 1 \\
\end{pmatrix}
\\
y = x + 2 =
\begin{pmatrix}
3 & 3 \\
3 & 3 \\
\end{pmatrix}
\\
z = y * y * 3 =
\begin{pmatrix}
27 & 27 \\
27 & 27 \\
\end{pmatrix}
\\
out = E[z] = 27
\end{equation}
>>> out.backward()
>>> x.grad
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
なぜ, このような値になったのでしょうか?
計算してみましょう.
out = \sum_{i=1}^{4} z_i
\\
z_i = 3(x_i+2)^2
\\
z_i|_{x_i=1} = 27
\\
\text{したがって,}
\\
\frac{\partial out}{\partial x_i} = \frac{\partial }{\partial x_i}\frac{3(x_i+2)^2}{4} = \frac{3}{2}(x_i + 2)
\\
x_i\text{には最初に}1\text{を代入したから,}
\\
\frac{\partial out}{\partial x_i}|_{x_i=1} = \frac{9}{2} = 4.5
< もっと簡単な例 >
Tutorialの例は少し煩雑なので, もう少し簡単な例で見てみましょうか.
\begin{cases}
y=e^{x}
\\
\displaystyle\frac{d y}{d x}=e^{x}
\end{cases}
これに, $x=2$を代入したときの$x$の勾配を見てみましょう.
>>> x = torch.tensor(2.0, requires_grad=True)
>>> x
tensor(2., requires_grad=True)
>>> y = torch.exp(x)
>>> y
tensor(7.3891, grad_fn=<ExpBackward>)
>>> y.backward()
# expは微分しても変化しないので, x=yになる
>>> x.grad
tensor(7.3891)
簡単ですね.
しかし, 当たり前といえば当たり前ですが, 一つ注意があります.
それは, 計算グラフを構築するときは全てpytorchの関数を使わなければならないということです.
以下のように途中で(この場合はすべてで使っていますが), numpyを使うとErrorが出ます.
>>> import numpy as np
>>> x = 2
>>> y = np.exp(x)
>>> y.backward()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'numpy.float64' object has no attribute 'backward'
ただし, +, -, *, /といった四則演算などの基本的な演算はオーバーライドされているので気にしなくても大丈夫です.
もちろん, .add()などの専用の関数を用いても大丈夫です.
微分操作をしない場合は, with torch.no_grad()を使いましょう.
推論時には不要でメモリの無駄遣いになります.
また, 使い方によっては, 推論しながら訓練もする, といった際には必ず必要です. 訓練時に勾配計算する際に, 推論時の計算グラフも残ってしまうので.
>>> print(x.requires_grad)
>>> True
>>> print((x ** 2).requires_grad)
>>> True
>>> with torch.no_grad():
print((x ** 2).requires_grad)
>>> False
でも, trainとevalとで勾配保存するか否かしか変わらないのに書き分けるのって何かセンスなくないですか?そう、そんな人には torch.set_grad_enabled(). これで引数にTrue/Falseを入れてあげればよいわけです. 例えば, phaseという変数を用意しておいて、torch.set_grad_enabled(phase == 'train') とすれば済むのです.
ちなみに, model.eval()とよく混同されがちですが少し意味合いが異なります. こちらはphaseによって異なるオペレーションが必要なBatchNormなどの切り替えに使うものです. 多分勾配は残ってしまうのではないかな.
Jacobianの部分は当分必要なさそうなので一旦飛ばします.
なお, Variable (deprecated)は廃止予定のものらしいので割愛します.
Neural Networks

それでは簡単にNeural Networksの実装方法を見ていきましょう.
A typical training procedure for a neural network is as follows:
-Define the neural network that has some learnable parameters (or weights)
-Iterate over a dataset of inputs
-Process input through the network
-Compute the loss (how far is the output from being correct)
-Propagate gradients back into the network’s parameters
-Update the weights of the network, typically using a simple update rule: weight = weight - learning_rate * gradient
簡潔ですね. これ通り順に作って見ましょう.
なお, この方法で作成したobjectは特別なことをしなくても, autogradに依存した形で記述されいるため, 先のような手続きを踏むことなく自動微分が出来ます.
Define the network
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
基本的に, nn.Moduleというクラスを継承する形で作成していきます.
まずは, __init__()でLayerをメンバ変数に格納していきます.
よく使うLayerとしては, Affine変換の nn.Linear(in_features, out_features, bias=True), 畳み込みのConv1d(in_channels, out_channels, kernel_size), Conv2d(in_channels, out_channels, kernel_size), PooingのMaxPool1d(kernel_size), MaxPool2d(kernel_size), 活性化関数のReLU(), DropoutのDropout(), Dropout2d などでしょうか.
詳しくは, torch.nnの公式documentを参考にLayerを構成していきましょう.
その後は, forward()で順伝播の計算グラフを作成します. この辺りも見たまんまの感じです.
以上はクラスとしてモデルを作成するやり方でした. ですが, 他にも作成する方法があります.
nn.Sequential()を用いる方法です.
net = nn.Sequential()
net.add_module('Conv1',nn.Conv2d(1, 6, 3))
net.add_moduke('Conv2', nn.Conv2d(6, 16, 3))
net.add_module('fc1', nn.Linear(16 * 6 * 6, 120))
net.add_module('fc2', nn.Linear(120, 84))
net.add_module('fc3', nn.Linear(84, 10))
まずSequence型のobjectを作成してしまい, そこにLayerをadd_module()で格納していく考えです.
この方法では, forwardを呼び出さすに, model(in_features)とすることで順伝播することができます.
では, 結局どの方法がいいの?って声が聞こえそうです. 好き好きだし場合に依るとは思うけれど, 上記のハイブリッドが個人的には好きです.
例としてVAEのモデルを見てみてしょう.
self.encoder = nn.Sequential(
nn.Conv2d(input_channels, 32, kernel_size=4, stride=2),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=4, stride=2),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=4, stride=2),
nn.ReLU(inplace=True),
Flatten()
)
self.decoder = nn.Sequential(
UnFlatten(),
nn.ConvTranspose2d(h_dim, 128, kernel_size=5, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, kernel_size=5, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(64, 32, kernel_size=6, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(
32, image_channels, kernel_size=6, stride=2),
nn.Sigmoid()
)
この方法のメリットはカタマリごとに変数を作れるところです.
なお, print(net)でもネットワーク構造は表示できますが, もっと多くの情報を出すには,
$ pip install torchsummary
でinstallし,
from torchsummary import summary
summary(your_model, input_size=(channels, H, W))
とすることで, 出来ます.
さっそく先のtutorialのモデルでやってみましょう. sumarry(net, (1, 32, 32))とすればOKです.
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 30, 30] 60
Conv2d-2 [-1, 16, 13, 13] 880
Linear-3 [-1, 120] 69,240
Linear-4 [-1, 84] 10,164
Linear-5 [-1, 10] 850
================================================================
Total params: 81,194
Trainable params: 81,194
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.31
Estimated Total Size (MB): 0.38
----------------------------------------------------------------
のような表示が可能です.
パラメータに関しては, .parameters()で取り出すことができます.
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
それではデータを入力してみましょう.
input = torch.randn(1, 1, 32, 32)
out = net(input)
# tensor([[ 0.0595, 0.0830, 0.1917, -0.0108, 0.0329, 0.0732, -0.1207, -0.0133, 0.0689, 0.1912]], grad_fn=<AddmmBackward>)
今回は1chの画像を1枚入力しましょう. input = torch.randn(N, C, H, W)です. ここはモデルにより異なるところで, 例えば音声など1次元のデータの場合はinput = torch.randn(N, L)などになります.
なぜここで4次元のtensorを入力したのでしょうか? input = torch.randn(1, 32, 32)では駄目なのでしょうか?
それはこの文面を見ればわかります.
torch.nn only supports mini-batches. The entire torch.nn package only supports inputs that are a mini-batch of samples, and not a single sample.
For example, nn.Conv2d will take in a 4D Tensor of nSamples x nChannels x Height x Width.
If you have a single sample, just use input.unsqueeze(0) to add a fake batch dimension.
つまり, torch.nnはbatch処理しか受け付けないということです.
なので, fakeとしてN=1でいいのでbatchの形にしてね, と書いてあります.
その後は, 勾配を初期化し, 逆誤差伝播します.
.backward()メソッドを呼び出すことで, その変数のgradに勾配が格納されます.
net.zero_grad()
out.backward(torch.randn(1, 10))
まだ損失関数をこの段階では定義していないので, これを計算しても(Errorは出ませんが), 返り値はNoneになります.
Loss Function
それでは勾配を計算できるように損失関数を定義してみましょう.
pytorchでは, torch.nnかtorch.nn.functionalにある損失関数を使うのが一般的です.
ここでは単純に2乗誤差であるMSEを使ってみましょう.
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
# tensor(1.4625, grad_fn=<MseLossBackward>)
あとは自作のLossを使いたい時ありますよね.
この辺りは別途記事にしようかと思いますが, そのときには勾配が爆発しないようにしたりと工夫しないといけませんね.
例えば log を使うときは要注意ですね. log 0 は発散してしまいますから...
Backprop
特に言及することはないですね.
一応, 勾配が計算されているか確認してみましょう.
net.zero_grad() # zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
# conv1.bias.grad before backward
# tensor([0., 0., 0., 0., 0., 0.])
# conv1.bias.grad after backward
# tensor([-0.0060, 0.0266, 0.0337, -0.0046, 0.0068, 0.0114])
Update the weights
勾配を計算しただけで満足してはNeural Networkは学習しません. updateしましょう.
パラメータの更新方法には, SGD, Adam, Momentumなど複数ありますね.
pytorchでは, torch.optimを使って更新を行うobjectを生成し, optimizer.step()で更新を実行します.
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
また, 訓練時とテスト時でDropoutなどでは挙動が異なります.
訓練時にdropoutして計算した重みはその分だけ重みが大きくなります. このままテスト時に適用すると正しい計算が出来ません.
Hiltonはdropoout率を計算することを提案しました.
こちらがその論文です.
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
そのため, 実際には,
# 訓練時
net.train()
# テスト時
net.eval()
としてモードを切り替える必要があります.
TRAINING A CLASSIFIER

What about data?
For images, packages such as Pillow, OpenCV are useful
For audio, packages such as scipy and librosa
For text, either raw Python or Cython based loading, or NLTK and SpaCy are useful
それぞれのお得意ライブラリが記載されいます.
特にpytorchでは, 画像処理のために, torchvisionというpackageが用意されています.
今回はCIFAR10というdatasetで学習していきましょう.
- label
- ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’
- size
- 3x32x32 (channel, height, width)
Training an image classifier
We will do the following steps in order:
- Load and normalizing the CIFAR10 training and test datasets using torchvision
- Define a Convolutional Neural Network
- Define a loss function
- Train the network on the training data
- Test the network on the test data
この通り順にやっていきましょう.
1. Loading and normalizing CIFAR10
transformには前処理の内容を記述しておきます. それをtorchvision.datasets.CIFAR10により読み込む際に渡すことで自分が望むような前処理を行ってくれます.
num_workersというのは,
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
つまり, コア数です.
では, その前処理の記述の仕方です.
transforms.Compose()内にlist形式で記述していきます.
transforms.ToTensor()でtensor形式に, transforms.Normalize((μ), (σ))で標準化します.
この他にも, transforms.Lambda(lambda x: x.view(height*width))でflatten処理を行ったりもします.
trainのdatasetは学習の安定のためにshuffleする必要がありますが, test時には関係ないのでshuffleはFalseにしています.
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz Files already downloaded and verified
このtrainloaderをiter()に渡すことで, 順々にデータを取り出すことが出来るobjectを得ることが出来ます.
このdataiter.next()はバッチ単位で出力してくれます.
先程, バッチサイズは4にしたので4つ分出力されています.
なお, 通常利用する場合はイテレータなので, for data in dataloaderで処理してOKです.
それでは可視化してみましょう. RGBの順番を変えないといけないことに気をつけましょう. matplotlibやopencvではBGRの順ですが, pytorchではRGBです. これは歴史的な背景があるようです.
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
# horse dog frog plane

torchvision.utils.make_grid()は, 4枚の画像をまとめて1枚にしてくれるものです.
さて, CIFAR10の場合はできましたが, 自作データセットの場合はどうすればいいの?
それは自身でtorchvision.datasets.CIFAR10に代わるものを作るわけです. 難しくないです.
class MyDataset(torch.utils.data.Dataset):
def __init__(self, *args):
def __len__(self):
def __getitem__(self, idx):
最低限上記のメソッドを持つclassを定義すればいいのです. これすら書きたくないという方は, torchvision.datasets.DatasetFolderなど確立されたものもありますからそちらを検討してみましょう.
2. Define a Convolutional Neural Network
それではNeural Networkを作成しましょう.
といっても, 既に勉強したnn.Moduleを継承するだけです.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
3. Define a Loss function and optimizer
次に損失関数と最適化関数の作成です.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
4. Train the network
お待ちかねの学習になります.
大まかな流れは,
- 勾配を初期化する
- 順伝播する
- lossを計算する
- 逆誤差伝播する
- パラメータを更新する
という感じです.
公式のサイトには,enumerate(trainloader, 0)となっていますが, enumerateはdefaultで開始位置が0なので0を書く必要はありません.
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
5. Test the network on the test data
それではテストしていきましょう.
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# GroundTruth: cat ship ship plane

この辺りは最初と同じです.
それではNeural Networkがどの程度推定できるか確認しましょう.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
# Accuracy of the network on the 10000 test images: 54 %
今, 計算グラフを保持する必要はないですし, メモリの無駄なので, with torch.no_grad()を使いましょう.
outputにはNeural Networkが出力した各ラベルの確率が出ています. 正確には, pytorchではLossにsoftmax関数が組み込まれているので, 確率ではないです. ですが, 欲しいのは確率の大小なので, softmaxを使わずとも推論だけなら可能です. もちろん学習時には必要ですが. そういう思考のもとでpytorchは作られているようです.
torch.maxは
out (tuple, optional) – the result tuple of two output tensors (max, max_indices)
となっているので, 最大値とそのindexを返します. 今最大値自体には興味がなく, そのindex(ラベル)に興味があるのでそれだけを取り出しています.
2つ目の引数の1はdimの指定です.
最後に, どの種類の画像が精度がよく, あるいは精度が悪いのか調べてみましょう.
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
これを解説します.
先頭2行は0で初期化したリストを作成しています.
>>> class_correct = list(0. for i in range(10))
>>> class_correct
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
batchサイズが4なので, 1回のfor文で4つデータを処理する必要があります. それが, for i in range(4):の内部です.
Training on GPU
Convを使い出すと一気に計算時間がかかります. 同じフィルタを使ってズラしながら計算するわけですからそりゃ計算時間増えますよね. GPUを使うと早くなります. PyTorchでGPUを使うのはめっちゃ簡単です.
>>> device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
>>> print(device)
cuda:0
上記をプログラムの始めに定義しておいて, tensor.to(device)とmodel.to(device)すればOKです.
cuda:0の0はGPUの番号で複数GPUを持っている場合は値を変えることで使用GPUを変更できます.
やり方自体は難しくないのですが, to.(device)し忘れて, RuntimeError: Expected object of type torch.cuda.FloatTensor but found type torch.FloatTensorとよく怒られちゃいます私は(笑). あのtensorと同じデバイスに載せたいんだよな!って場合は.to(tensor.device)するといいでしょう.