・現時点、MCDに限りですが、資格のトレーニングや試験問題が日本語化され、無料で受講・受験できます。※資格受験は、期間限定で無料の様です。無料バウチャー発行には一定条件があります。(随時変わるよう。)
・以下Webトレーニング受講と、Workshopの参加(=毎月やっている?)が、受験において、大変効果的でした。
Anypoint Platform Development: Fundamentals (開発: 基礎) (Mule 4)
その他、便利なリンク
https://quip.com/JBhRAIbXU9VO
https://qiita.com/nkitaarashi/items/08cb3499aa2091e5da72
以下、勉強用メモ。記載中。(※試験に特化してるわけでない。)
1 - アプリケーションネットワークとAPI主導の接続性
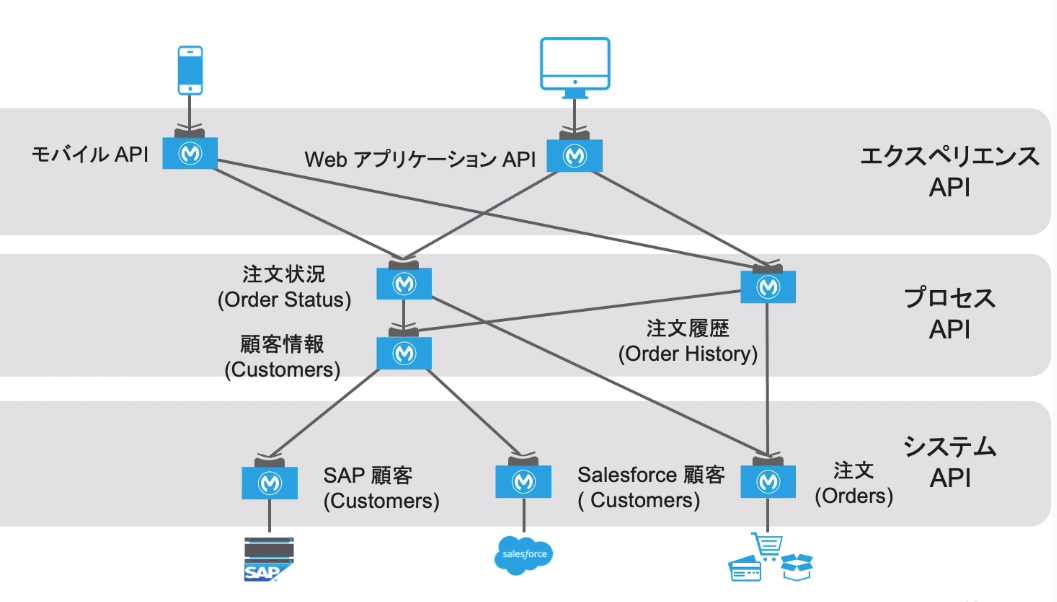
・いままでPoint to pointで作ってましたが、拡張性がよろしくないので、Muleを使って疎結合でやりましょう。以下3階層で定義。
・C4Eを設立しましょう
→センター・フォー・イネーブルメント
※イネーブルメント:実施可能?使用可能?
→C4Eは、アセットのコンシューム(どれだけIT資産・資源)が再利用されたかが評価となる。
→役割:事業部門の開発者がコンシューム(呼び出し)できる、発見・再利用可能なアセットを生成し、管理する。
・アプリケーションネットワーク
→セルフサービスによりボトムアップで出現
→他の組織からもコンシューム(活用)できるように設計された再利用可能なIT資産・アセットを生成する。
・モダンAPI
→再利用可能、扱いやすい・管理しやすい設計
→API仕様を使ってAPIを設計し、迅速にフィードバックを得る、という特徴
・SOAP Webサービス
→従来のWebサービス
→XML形式でWSDLファイルで定義
・REST Webサービス
→モダン、より扱いやすい、軽量
→JSON形式
→通信プロトコルはHTTP
→HTTPプロトコルは以下5つの操作ができる。
POST→登録
GET→取得
DELETE→削除
PUT→更新
PATCH→部分的に更新
・ProgrammableWebには、19,000以上のAPIがある。
・RESTful API
→保護されていない unsecure API
→保護されている secure API
→ログイン情報やトークンが必要な可能性あり。
→OAuth, SAML, JWTなどでAPIを保護できる。
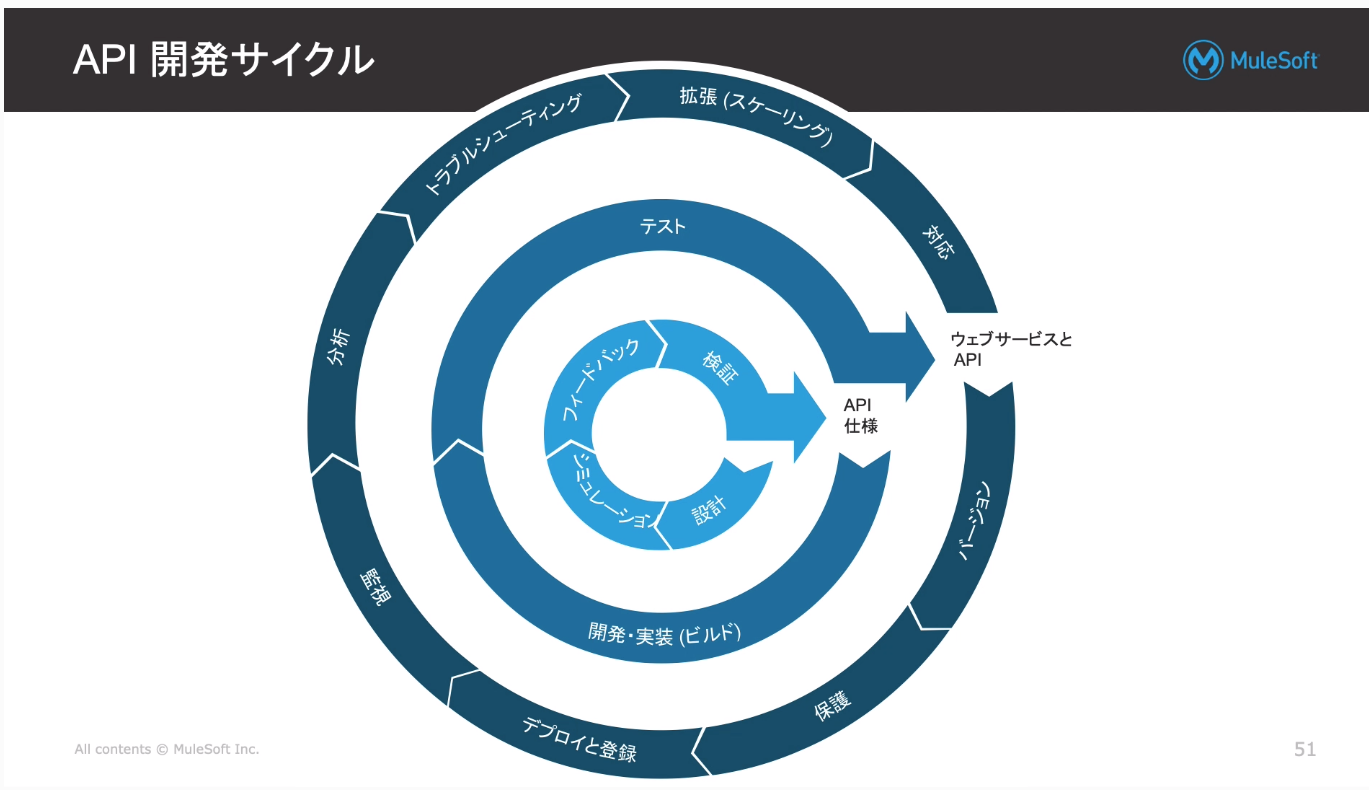
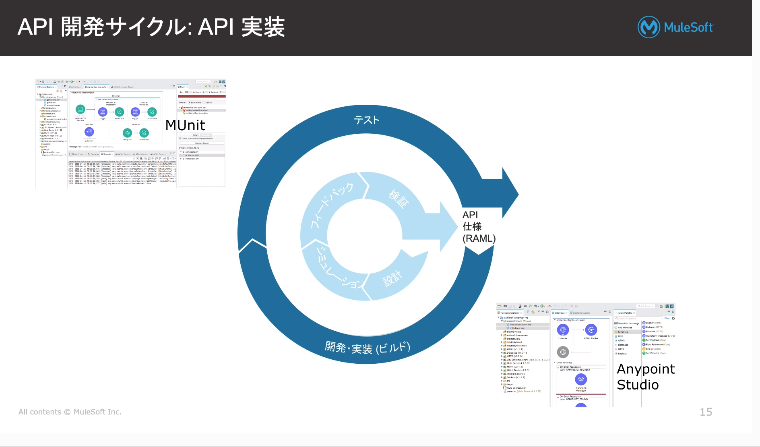
・API開発サイクル
①まず、APIの設計をしましょう(部品作成)
⇒Design CenterのFlow Designerを利用
②その後API仕様をフローに組み込みましょう、テストしましょう。(実装・テスト)
⇒AnypointoStudio(開発)、Restクライアント(テスト)
③運用しましょう。(監視したり、トラブル対応したり。
⇒API Manager
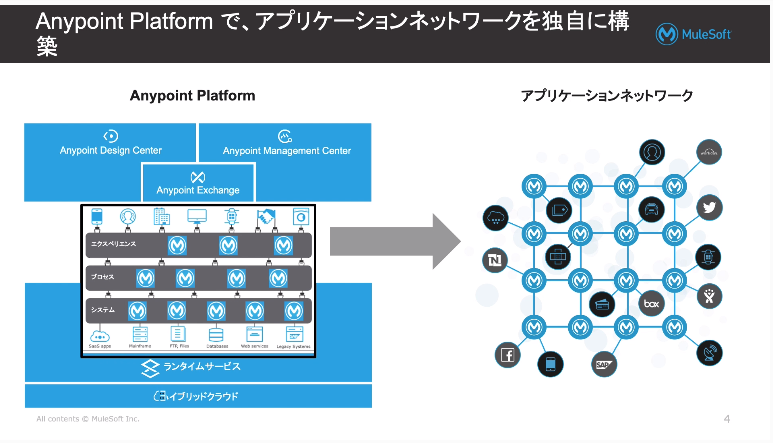
2 - Anypoint Platformの概要
・APIのライフサイクルに必要な機能は全部Anypoint上にあります。
【DesignCenter】APIを作る(迅速な開発)
https://docs.mulesoft.com/jp/design-center/
【Exchange】APIをセルフサービスで検索・公開(コラボレーション)
⇒REST APIがExchangeに追加されると、自動的に【API Portal】が生成されます。(APIportal⇒自動生成されたドキュメント、モッキングサービスなど)
⇒API portalは、内部(社内のみ)と外部(全体公開)の共有設定が可能。
【ManagementCenter】セキュリティ、拡張性、パフォーマンス管理(表示・制御)
【Mule】軽量で力強いランタイム・実行環境、アプリの実行するサーバー(Muleランタイムをホスト)
・設計/シミュレーション/フィードバック/検証を終えると、
API仕様書(RAML仕様書)が出来上がります。
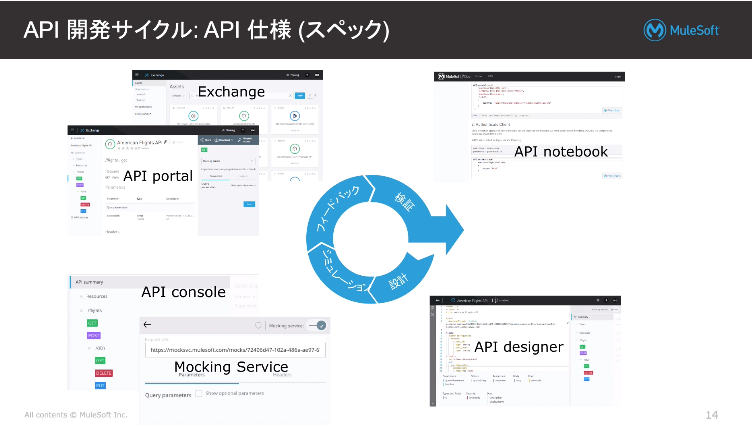
・API仕様書をインポートし、AnypointStudioで開発を行います。
・MUnitで、テストもできます。
⇒これでWebサービス/APIが構築されます。
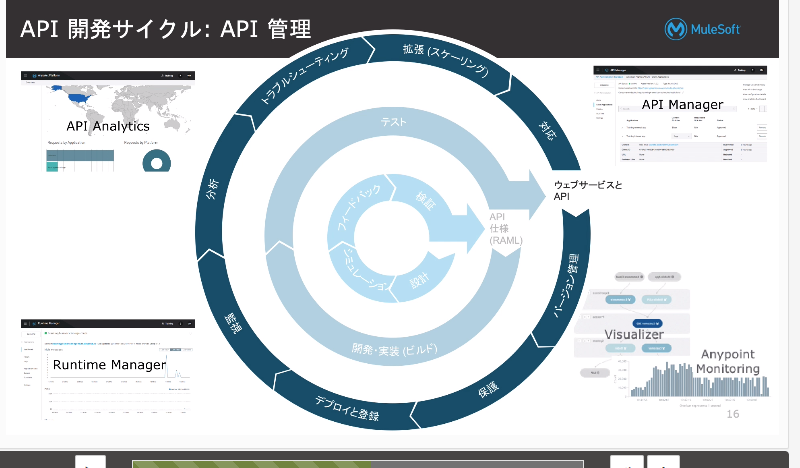
・API管理のフェーズでは、APIManagerを使います。
・RuntimeManagerでデプロイや監視(パフォーマンスのモニタリング)を行います。
・API Analyticsではどのように使われているか分析。
・コネクタ↓
・1度のAPIの設計で、様々な環境にデプロイできる。
(1)お客さんがHostする環境⇒オンプレ、PrivateCloud(AWSなど)
(2)CloudHub⇒Muleが完全に管理するIPaaS
・Muleアプリ
⇒XMLの集合体
⇒Muleのイベントプロセッサが、Flowで結合されている。
⇒Flowの構成は、イベントの開始条件、処理、エラーハンドリング
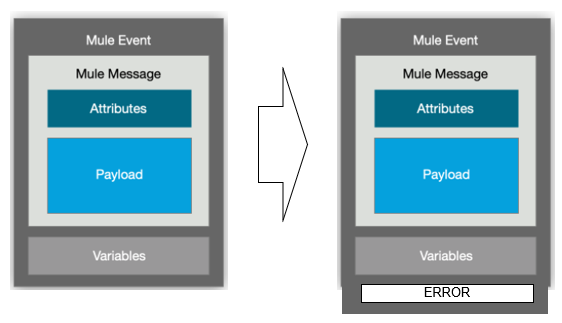
・Muleイベントデータの構成
⇒Muleアプリがトリガされた時に以下イベント発生
※Attribute(属性)は、parameterやヘッダーを保持
※Payload(本文)は、実際に処理されるデータ
※Variables(変数)は、プロセッサーを使って定義
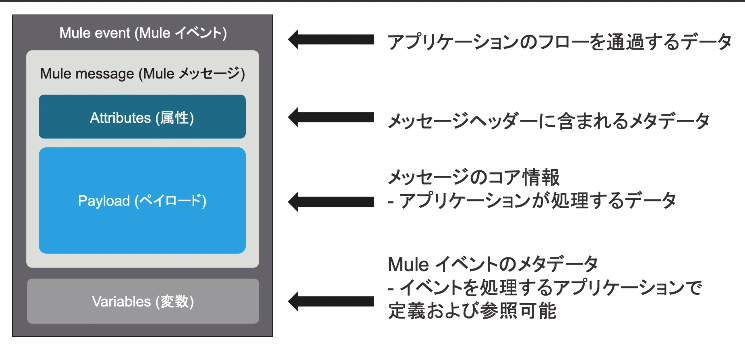
以下、Attribute
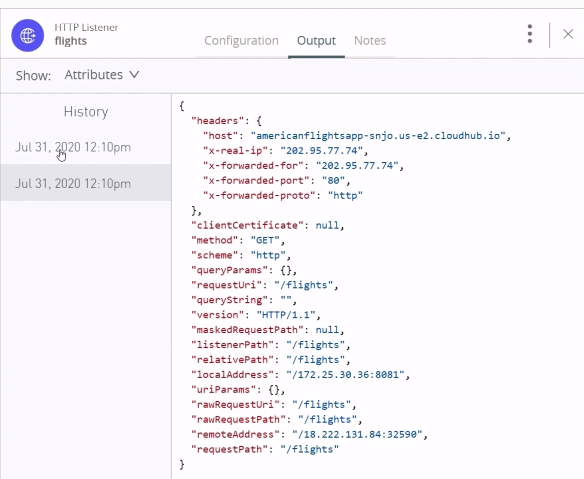
★「WT2-3 デモ - 任意(12:31)」が分かりやすいです。
⇒HTTP Listenerで受信→Flight情報を取得→Transformコンポーネントでマッピング定義やDataWeaveでの変換を行う流れの中で、AttributeやPayLoadの値がどうなるか説明
・DataWeave⇒Excelの関数みたいなもの。式言語。
・DataWeaveは #[]で記述し、設定は${}で記述する。
・Transformコンポーネント
⇒データのInputとOutputのマッピングを管理
・Mule4:「4」は、バージョンを指しているそうです。
3 - APIの設計
・APIを作るには以下手法があります。
→手動でガリガリコーディング
→RAML 等。
・RAMLとは?
→RESTful APIをシンプルに記述するための言語
→オープンソース
→RAMLを使うと、モックされたエンドポイントやドキュメントなど自動生成可能。
→YAMLやJSONをベース

・サンプルデータは以下2つのファセットを利用
exampleは単数、examplesは複数の時に利用
⇒記載中![]()
![]()
![]()
4 - APIの作成
・AnypointStudioを利用し、開発を行う。
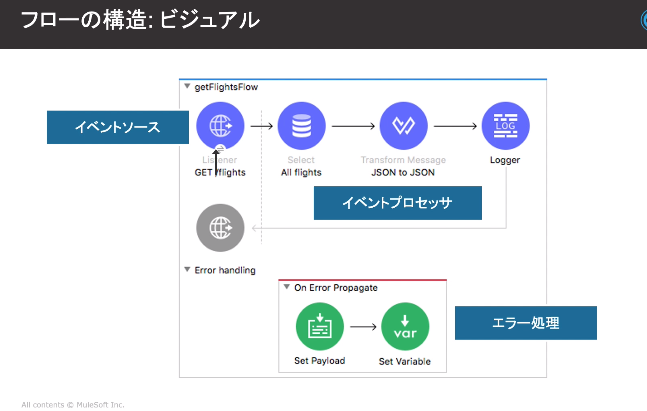
・以下フローの構造だが、イベントプロセッサは1つ以上必須。それ以外はなくても成立。
・イベントソース(リスナー)には、受信の定義を記載。ここを消すと、どこから呼び出す記述を記載しないとそのフローは呼ばれない。
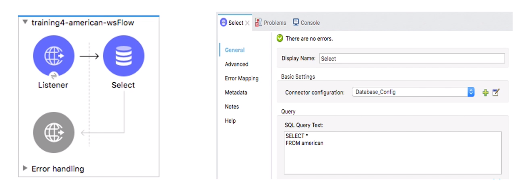
・データ接続
→Databaseコネクタを利用
これでほぼすべてのJDBCリレーショナルデータベースに接続可能。
→返り値は、Javaの配列。
・TransformMessageコンポーネント
DataWeaveを使い、データを変換するコンポーネント
※表記ゆれで混乱しますが、「WT2-3 デモ - 任意(12:31)」で出てきたTransformコンポーネントと同じです。
・SetPayload
→PayLoadに値をセット。
・HTTPリスナーから手動で作るのではなく、
ExchangeからAPIkitを取得し、RESTfulインターフェースを作ることも可能。
→api:routerとコンソールが自動生成される。
・FlowReferenceからフローを呼ぶことができる。
→親フローから子フローにイベントが渡される。
→フロー名を記載することにより、フローを呼べる(例:getFlightsなど)
・AnypointStudioからExchangeへAPIの仕様に対して更新をかけられる。
(逆にExchangeからAPIを落とすことも可能。)⇒API Sync
・Gitのようなインターフェースの利用が可能で、PushやPull、Mergeなど可能。競合したときにはコンフリクトエラーが出る。
5 - APIのデプロイと管理
・APIをデプロイするにあたり、以下3環境がある。
→ここの説明がよくわらない。![]()
![]()
![]()
→「2 - Anypoint Platformの概要」でもCloudHubの話が出てるが、関連性に関しては言及無しなので何がどれに対応するか不明。前に出てきた環境説明のどことMappingするか不明。
(1)CloudHub→Muleが管理する環境、IPaaS。オートスケーリングなども提供。デプロイ先のデータセンターを選べる。
(2)Muleランタイム→顧客ホストするサーバ上での稼働。サーバは顧客のものだが、管理はMule上で可能。1サーバに複数アプリ可能。
(3)AnypointラインタイムFabric→?
⇒記載中
6 - (未作成)Muleイベントに対するアクセスと変更
7 - (未作成)Muleアプリケーションの構造化
8 - (未作成)Webサービスのこんしゅーむ
9 - (未作成)イベントフローの制御
10 - エラー処理
↓こちらにもフローの例など掲載
https://qiita.com/nori83/items/4dc6c9546bdb09502c4e
・アプリ、フロー、プロセスの3段階のレベルでのエラーが起きる
※アプリのエラー⇒フロー外のGlobalError_Handler、フローにもプロセッサーにもエラーハンドラが設定されていない時のみ実行される。
・エラーメッセージは、Muleのデフォルトのものと、カスタムで定義したものがある。
https://docs.mulesoft.com/jp/mule-runtime/4.3/on-error-scope-concept
・Errorがスローされると、Errorオブジェクトが出来る。
・重要なのは以下。
error.description → 文字列
error.errortype
→ オブジェクト(例: VALIDATION:INVALID_BOOLEAN, HTTP:UNAUTHORIZEDなど)
→ 親をもっており、階層構造となっている。最上位はANY
・HTTPリスナから返される情報
★デフォルトの成功レスポンス
- payload ※エラーオブジェクトが出来ない。
- ステータスコード:200
★デフォルトのエラーレスポンス
- error.description ※エラーオブジェクトが出来る。
- ステータスコード:500
※値は上書き可能。
・Errorスコープは2種類ある。複数設定できる。また、Errorスコープに該当条件を指定することも可能。(Typeで対象エラーを選択するか、WhereにBooleanのDataWeave式で該当条件を記載。error.errortype.namespace == 'HTTP' )
どこにも該当しないとMuleのデフォルトのエラーハンドラに渡される。
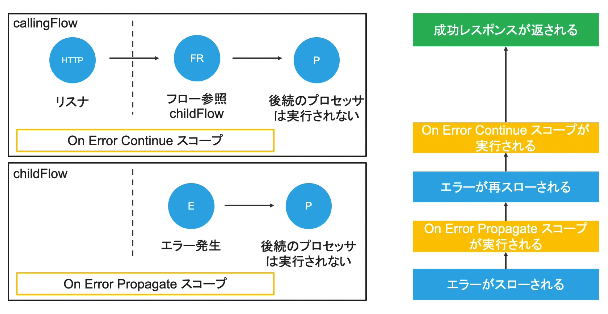
(1)On Error Propagate
(2)On Error Continue
以下、いずれも、エラースコープ処理内の全てのプロセッサが実行される。
(1)On Error Propagate
→Errorオブジェクトが生成される。
→エラーが起きると、エラーをスローした後、残りのフローは実行されない。
→HTTPリスナは、エラーを返す。
(2)On Error Continue(成功したかのように見せかける)
→エラーが起きると、エラーをスローしない。
→HTTPリスナは、成功を返す。
※デフォルトでは、「On Error Propagate」で処理が行われるため、エラーが返ってきて、後続処理が止まる。
親フローからChildFlowを呼んだ時にEでエラーが発生した場合。
ChildFlowではOnErrorPropagateなのでエラーを親フローに返すが、親フロー側がOnErrorContinue(=エラー発生時に処理を止めてエラーを出さないもの)なので、成功としてレスポンスが返される。
・サブフローにはイベントの取得元やエラースコープ定義がない。
(前のフローの説明でchildFlowにErrorスコープを定義している図があったが、ChildFlowはサブフローではなく、個別フローということか・・?![]() 謎)
謎)
https://docs.mulesoft.com/jp/mule-runtime/4.3/about-flows
<模擬試験に関する参考サイト>
https://help.mulesoft.com/s/question/0D52T00004mXUBOSA4/explanation-to-question-of-selfassesment-quiz-module-10-question-2
⇒記載中
11 - DataWrave変換の記述

・生成されたデータは、以下3つの異なる型で構成可能。
①Object → キーと値のペアが、集合している状態
②Array → カンマ区切り値のシーケンス
③Simple Literals(リテラル)→???![]()
![]()
![]()
https://wa3.i-3-i.info/word15346.html
・DataWeave変換式
JSONで入ってきたのを、XMLに変換の場合
★入力(JSON)
{ "firstname":"Suzuki",
"lastname":"Hanako" }
★変換(JSON→XML)
%dw 2.0
output application/xml ←どう出力するか表現。ここではXML形式で吐きたい。
--- ←この線で(↑)Headerと(↓)Bodyを区切る。
{
user:{
fname:payload.firstname, ←これをDataWeave式っていう。
lname:payload.lastname
}
}
★出力(XML)
< user>
< fname>Suzuki< /fname>
< lname>Hanako< /lname>
< /user>
・出力形式(MIME)は色々指定可能。
application/json, application/xml, application/java, text/plain,
application/dw, application/csv
・DataWeaveのエラー
application/dwを使って変換し、エラーを検知する。
以下2タイプある。
(1)スクリプトエラー ⇒構文ミス
(2)フォーマットエラー ⇒データ変換時の問題。例えば、XML形式に変換したいのに、元のデータがそれを満たしてない。
application/dwでエラーが出たら(1)、でなければ(2)となる。
・コメントの書き方
// コメント
/**
複数行コメント
*/
11.基本的なデータ構造の変換
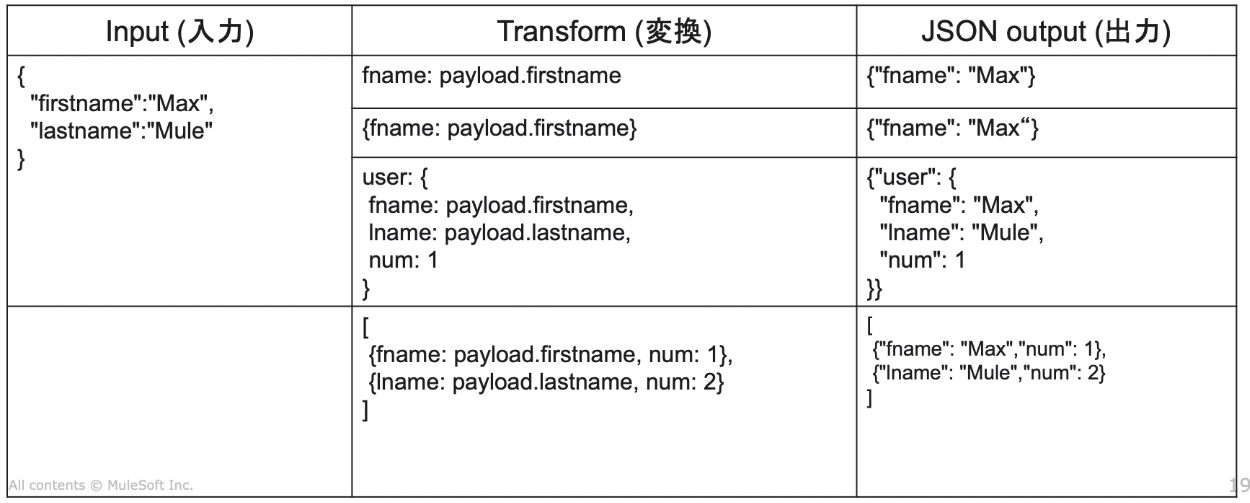
・オブジェクト
user:{
fname:payload.firestname,
lname:payload.lastname,
num:1
}
・配列
{
{fname: payload.firstname, num:1},
{lname: payload.lastname, num:2}
}
・属性(attribute)を設定するには、 @(attName: attValue)を使用
★入力(JSON)
{ "firstname":"Suzuki",
"lastname":"Hanako" }
★変換(JSON→XML)
%dw 2.0
output application/xml
user:{
user @(fname:payload.firstname, ←カンマで区切って属性(Attribute)を2つ指定
lname:payload.lastname):{
lname:payload.lastname
}
}
★出力
< user fname="Suzuki" lname="Hanako">
< lname>Hanako lname>
< /user>

ポイント:XMLからJSONへの変換の際には、要素( < lastname>Mule< /lastname>)だけ変換され、属性(Attribute,ここだと<userの中の属性)は変換されない。
ポイント:属性をとってきたい場合、@を付ける。
・変換関数(map関数 → 配列を返す )
★$$→配列の何番目なのか示す。$(index)でも同じ結果
★map→この形式に変換したい!というとき。
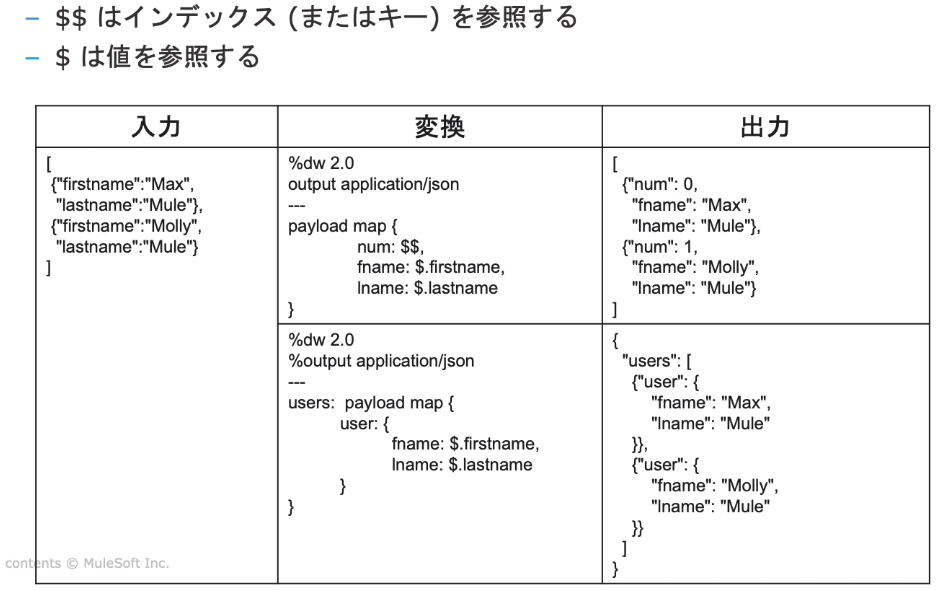
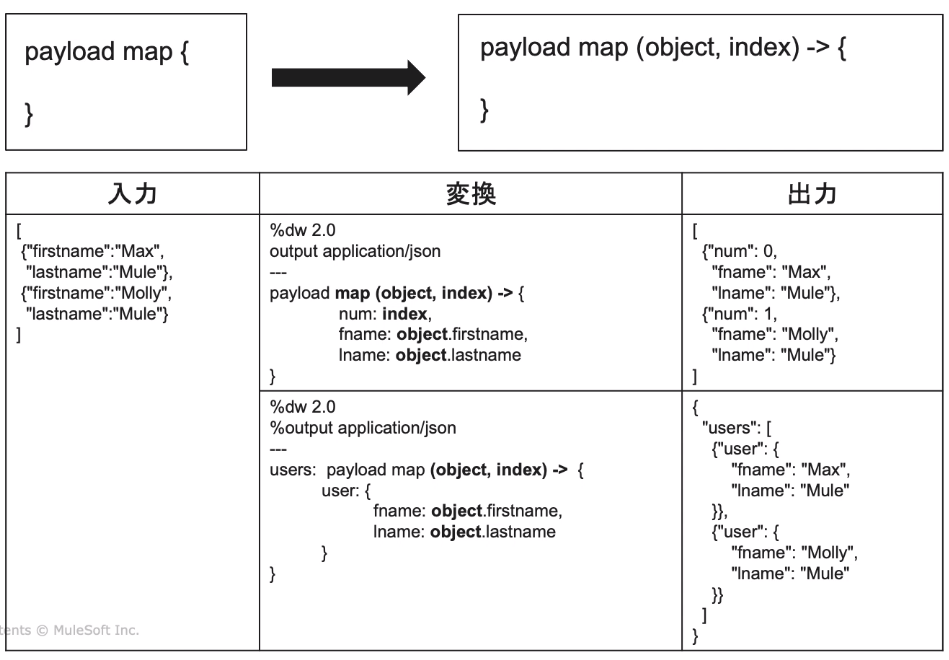
<メモ>
・payload[0].price → 199
・payload.price → [199,450]
・[payload.price,payload.test] → [[199, 450],[0, 24]]
・変数 aaaに値を設定したが、その値を呼び出したいとき。
→ #[var.aaa]
・XMLは配列をサポートしていない。
なので、map操作を{(・・・)}で囲むことにより、key-valueペアに変換できる。
※{}はオブジェクト定義、() は配列の各要素をkey-valueペアとして変換
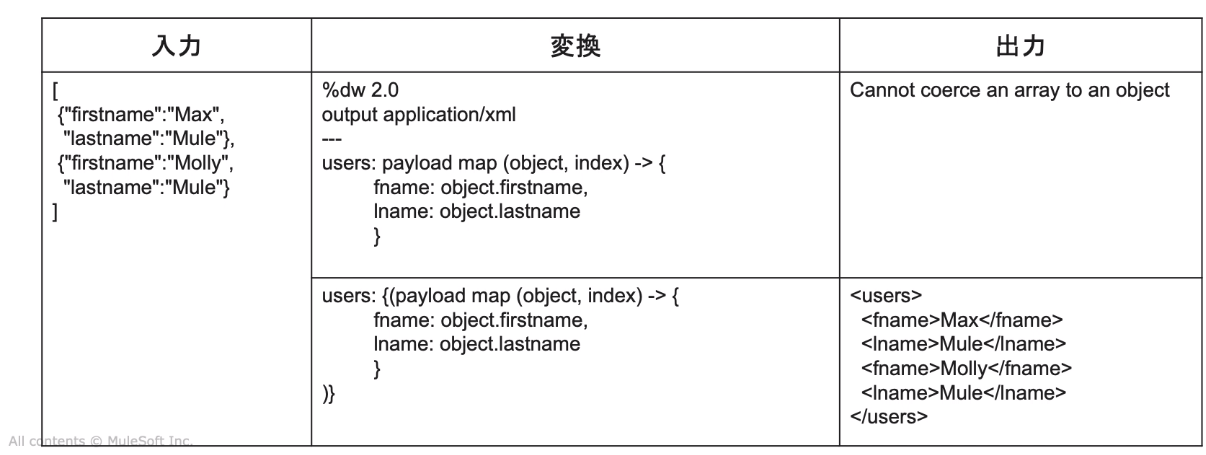
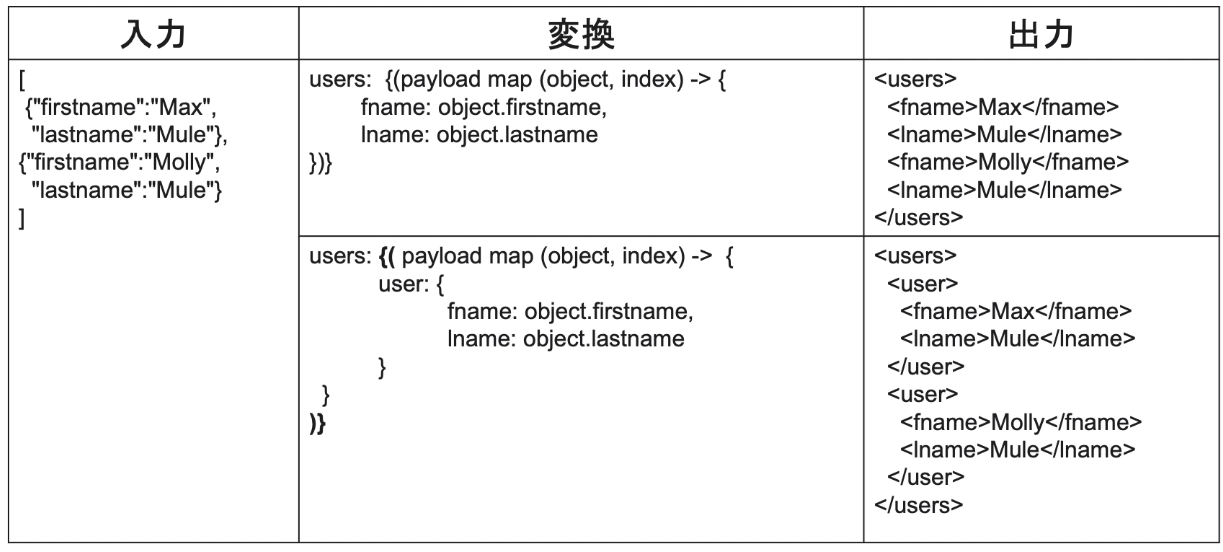
・ヘッダーに、「var」を使い、変数の定義・使用が可能。
以下は、varディレクティブに対して、定数、もしくはラムダ式を割り当てしている場合。
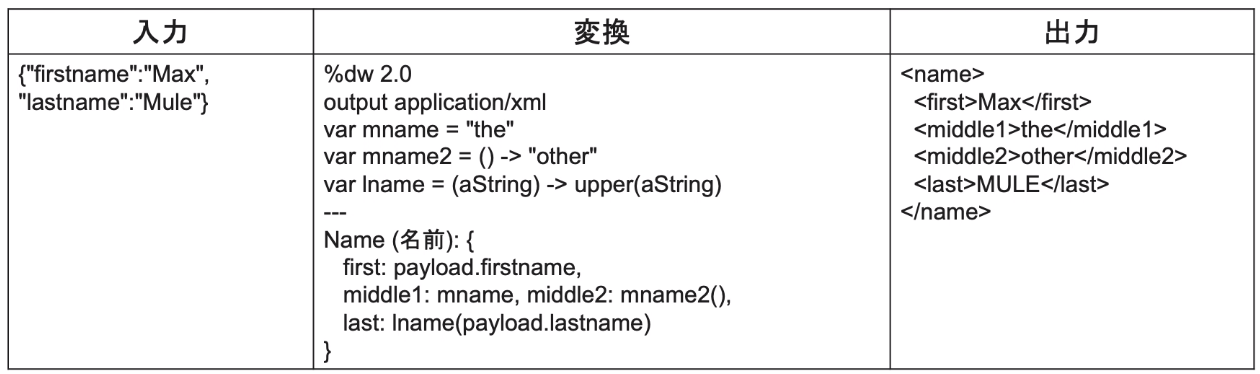
関数としても書ける。
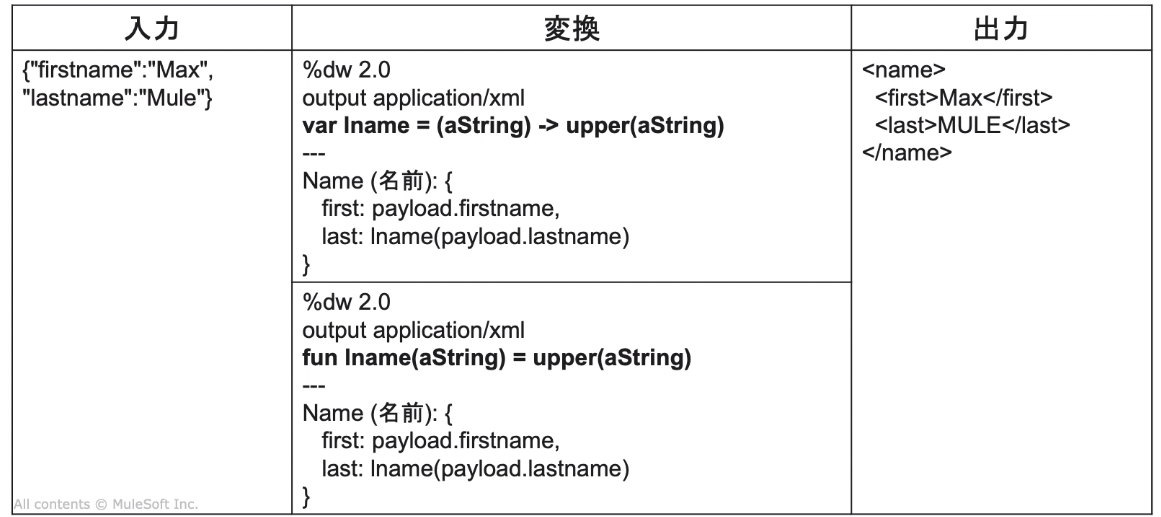
・do → ローカル変数の初期化
![]()
![]()
![]() ここよくわからなかった。(※11-4の動画)
ここよくわからなかった。(※11-4の動画)
・as → 型変換 (例: as Number、as Boolean とか)
・format → そのまま。日付などの書式・フォーマット変換
someDate as DataTime { format: "yyyyMMddHHmm"}
・カスタムのデータ型を作ることも可能
typeを使う。
★変換
%dw 2.0
output application/json ←JSON形式で吐く
type Hensuumei = DataTime {format: "yyyyMMddHHmm"} ←Hensuumeiの定義
--- ←上がヘッダー、下がボディ
someDate : payload.departureDate as Hennsuumei ←someDateに、入力値のdeparturedDateの値を、Hensuumeiの形式で変換
・複数関数を組み合わせる場合、左から実行されます。
flights orderBy $.price filter ($.availableSeats > 30)
⇒ソートし、そのあとフィルタする
・コアな関数は上記の通り、何もせずとも普通に使えます。(containとか、isEmptyとか、mapとか)
それ以外は、関数もしくはモジュールを、Importして使う必要があります。
%dw 2.0
output application/xml
inport dw::core::Strings ←こんな感じでInport
・DataWeaveからフローをコール
→lookupを使います。
{a: lookup("フロー名"), {b:"Hello"}) } ← Helloは、フローに渡すPayload
※制約:サブフローはCallできない。
・DataWeaveのコードは、DWLファイルか、関数のモジュールにインライン記述可能。
・typeOf関数は、型を返却する。
例) typeOf({a:1}) → Object
例) typeOf([1,2]) → Array
<模擬試験に関する参考サイト>
・groupByをしてしまうと、配列になってしまうため、orderByできず、
なので、GroupByは最後になります。
https://help.mulesoft.com/s/question/0D52T000054n8hJSAQ/module-11-quiz-question-1-please-explain-how-to-arrive-at-the-dataweave-expression
12 - フローのトリガー
・ファイルやフォルダ操作のコネクタは以下4種
File(ローカルのファイル)、FTP、FTPS、SFTP
・以下をサポート
ファイルの一致、ロック、上書き、内容追加、新規ファイル生成など
・<前準備>Fileモジュールの追加⇒グローバル要素として作業ディレクトリを追加する。
(1) CloudHub ⇒コネクタはtmpフォルダでしか利用不可。
(2) Customer-Hosted(顧客がホスト) ⇒Muleを実行するアカウントが、指定ディレクトリへの読み書き権限を持っている必要あり。
・Schedulerコンポーネント
→特定の日時や頻度でフローを実行するためのコンポーネント
・On New or Updated Fileリスナ
ディレクトリに定期的にポーリングをし、新規・更新されたファイルを探索。見つかったファイルに対して1つメッセージ生成

ファイルが新規か否かの判定は、ファイル名の変更や作成日時を持つなど。
・ウォーターマーク
⇒データがどのような状態にあったか記録(同期時に再取得する際に比較されるタイムスタンプ)
⇒データストア間でデータを同期させるときに使用
①自動ウォーターマーク ⇒ 作成日など(CREATED_TIMESTAMP, MODIFIED_TIMESTAMP)
②手動ウォーターマーク ⇒ 複雑な場合に個別定義
・DBコネクタのOn Table Rowオペレーションを使えば、DBにレコード追加のタイミングでフローをTrigger可能。

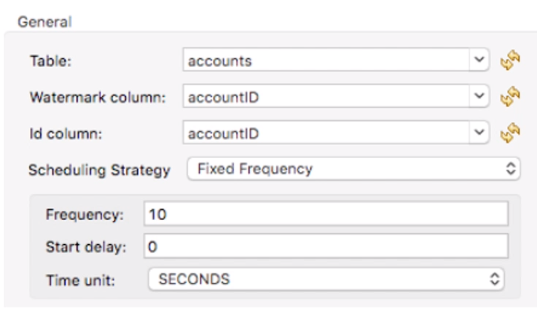
→ SELECT * FROM tabke WHERE TIMESTAMP >: watermark
・重複レコードの防止
→IDカラムを指定して、重複してないか確認
・<自動ウォーターマーク>
ObjectStoreコンポーネントを利用し、シンプルなキー/値のペアを保存する。
→ウォーターマークなどの同期情報、アクセストークンなどの一時的な情報、ユーザ情報など
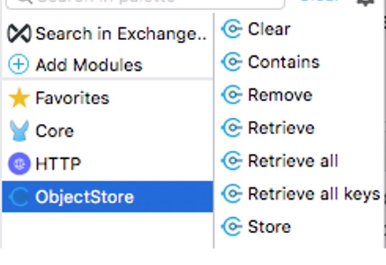
・JMS(java Messaging Service)
→メッセージ交換の通信において広く利用されているAPI
・2つのメッセージングモデルをサポート
①キュー(1対1)
⇒キューにメッセージが送信されると、1つ1人の受信者がキューからメッセージを出す。
⇒受信者がキューをリスンしてる必要なし
②トピック(パブサブ、1対N)
⇒送信者はTopicへPush、トピックから購読者へメッセージが飛ぶ
⇒受信者がTopicをリスンしてないとダメ。
・システム間でのメッセージはJMSコンポーネント
<模擬試験に関する参考サイト>
payloadを変更したくない時に、「targetValue」を利用します。
今回、ChiledFlowの「targetValue」属性にpayloadを指定してます。
なので、今回、Muleの元のPayloadの値は、変わってないわけです。(つまりJSONのまま。)
https://help.mulesoft.com/s/question/0D52T00004mXSCjSAO/mulesoftu-development-fundamentals-mule4-assessment-quiz-module-12-question-1-answer
https://docs.mulesoft.com/mule-runtime/4.1/target-variables
ちなみにここの問題、動画の中で解説されてなくない・・・?と議論になってます、が、デモの中で触れていたようです。↓
https://help.mulesoft.com/s/question/0D52T00004uuoyiSAA/is-it-just-me-or-are-the-endofmodule-quiz-questions-sometimes-unrelated-to-not-covered-in-the-corresponding-module
13 - レコードの処理
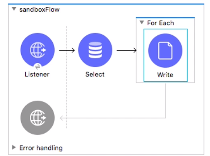
・For each
→配列のみ入力可能。それ以外が入ってきたら、エラーはでないが0となる。
→順次処理(シングルスレッド)
→イベントのコレクション(配列)を分割し、個々のデータを処理する。
★ポイント:”コレクション”がインプットであること。
→なんか起きたらFor eachは処理を停止し、エラーへ進む。
・Parallel for eachの利用も可能。
→複数のスレッドで並列処理をする。
→分割したイベントの1つでエラーが発生しても、そのほかの正常なイベントは影響なくすすむ。
・Batch Job(※ EnterpriseEditionのみ利用可能。 )
→配列のみ入力可能。それ以外が入ってきたら、エラーはでないが0となる。 →一括処理(マルチスレッド)
→大きなメッセージをレコードのブロックに分割し、非同期で処理。
→処理した結果を他システムやキューに渡すことも可能。
→大量データ、ほぼリアルタイム、ETLとしての機能
例)クラウド間の連絡先情報の連携、CSVをHadoopにアップロード、
API実行からレガシーシステムに送信される大量データの処理など
・バッチサイズ1 → [1] [2] [3]
・バッチサイズ2 → [1,2] [3]
・バッチサイズ3 → [1,2,3]
バッチジョブは、順々に処理されるバッチステップを含む。(必ず1以上)
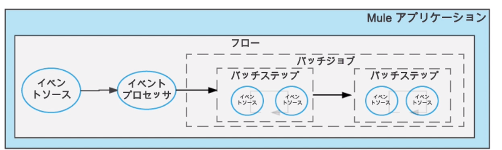
バッチジョブの3つのフェーズ
①Load and Dispatch
・Payloadの読み込み
・コレクションを個別のレコードに分割し、キューに入れる。
→パフォーマンス考慮し、デフォルト100レコードずつの処理になっている。(変更可能)
→スレッドプールのサイズは、Muleランタイムで自動決定。(変更可能?不明![]() )
)
②Process
・バッチステップの中で、非同期で処理を実行する。
→キューの各レコードが、バッチステップに送られる。
レコードは、処理されるとキューに戻され、次のStepの処理を待つ。
レコードは、どのStepまで処理されたか値を持っている。
非同期なので、前のレコードの順番待たずに処理を進むことがある。
→すべてのレコードが全バッチStepを処理するまで続く。
③On Complete
・処理結果のレポートを作る。
→バッチ処理が行われる前の変数を含んだ元々のイベントを返す。
Batch Jobの前に定義した変数は、後続のすべてのバッチStepで利用可能。
Stepの中でも変数変えたり、変数追加することも可能。
(★ただし、Batch Job外では利用できない。何を入れてもnullで吐かれる。)
→バッチスコープの各レコードで”のみ”利用可能。
・バッチ処理のエラー時の対応は以下3つの設定が可能。
以下該当すると、バッチ処理を止め、OnCompleteに進む。
(1)1つでもエラー発生(N>0) ★デフォルト設定
→1つでもエラーが発生したら全部処理止めてOnCompleteへ。
(2)N件以上(N>1)
→特定件数以上発生したら処理を止める。
(3)止めない
→何件エラーが発生しても処理を止めない。
OnComplete側で失敗したレコードの処理をどうするか定義必要。
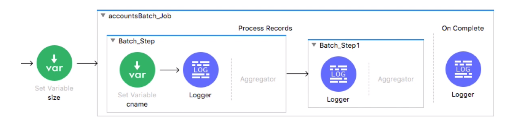
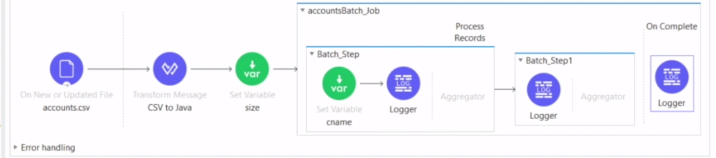
以下、CSVファイルを読み込み、Java形式へ変換。
まずはCSVのサイズをセットする、SetVariableをBatch Job外に定義。
そのあと1つ目のBatch Stepの中にpayload.NameのSetValiableを定義。
各Loggerの値を確認する。
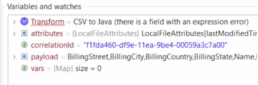
・Transform Messageコンポーネントの変換前
まだCSVの状況(カンマ区切り)
・Payloadにコレクションごとのサイズが明記
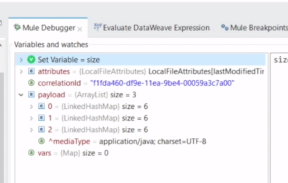
・バッチ処理を行うCSVの行数が3つ
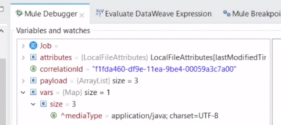
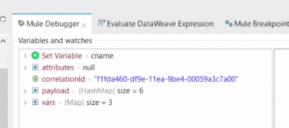
・1個目のLoggar、Cnameに顧客の名前が入ってる。
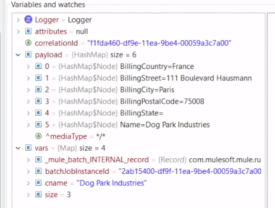
・バッチStepごとにログが吐かれる。(DogParkは2個目のレコード)
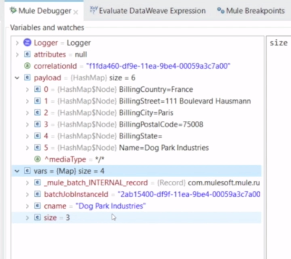
・OnCompleteでは、SuceessとErrorのサマリ結果がでる。
==②Processの深堀↓==
・バッチStepには、処理するレコードを絞り込むための以下2方式がある。クエリに以下属性がある。
(1)Accept Expression
→関数でエラー定義できる。
(2)Accept Policy
→先行のレコードにエラーが起きたらSkipするなど
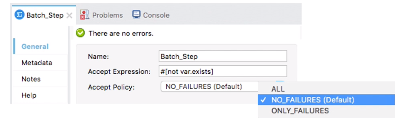
・Batch Aggregatorを使い、一括処理が可能。
→1回1回APIコールするのではなく、100件ごとに、一括でアップロード処理をするなど。
<Batch Jobを使い、DatabaseのレコードとSFDCとの連携を実施>
(1)まず、SFDCにレコードが存在しているか確認
(2)存在するならフラグを立てる。
(3)Batch Aggregatorでフラグが立っていないレコードを集約し、SFDCへInsert
存在するレコードはexist=trueで表現
(Batch Job開始前に定義し、処理が進む中で随時値が変わる。クエリのAccept Expression属性に、このexistフラグがFalseかの指定も可能。()重複レコードを弾く意図。)
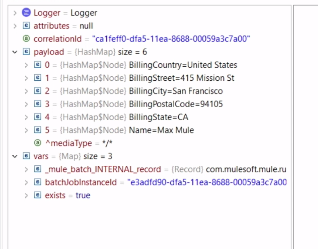
・デバッグは、セーブポイントついているコンポーネントの、処理の「前」でまずは止まる。
<模擬試験に関する参考URL>
・Q1
ForEachはコレクション(配列)を分割し、順次処理します。
問題文には、コレクションでないと書いており、Inputの形式があってない。ので0。もしコレクションだったら、2ファイルがOutput(3件データいるが、バッチサイズ2のため。)
https://help.mulesoft.com/s/question/0D52T000052JPBSSA4/is-answer-of-question-1-of-module-13-quiz-correct
・Q2
一見、[11,12,13]が回答な気もしますが、BatchJobは1個1個分割して処理されるので、その結果11→12→13の順にログが吐かれ、最後のログは13となります。
https://help.mulesoft.com/s/question/0D52T00004mXSK3SAO/module-13-quiz-question-2-please-kindly-explain-why-this-is-incorrect
・Q3とQ4:
ポイントは、変数がバッチStepの中で定義されているという点です。
バッチStep内で定義された変数は、バッチStep内の固有になります。
なので、CompleteフェーズやBatchJob外で、元の変数に戻ります。
バッチStep内で作成された変数も固有なので、バッチStep外で利用できません。
・counter→BatchStep外で1を定義してたため、1で出力(counter to 1)フローのどこからでも呼び出して使えます。
・stepVar→BatchStep内での変数定義なのでBatchStep外で使えない、つまりnull
https://help.mulesoft.com/s/question/0D52T00004sPn0u/quiz-13-que-3-please-explain-the-logic-for-d-as-answer
・Q6:
AcceptExpressionで、3で割った時に余りが0でないものが通過するので、1と3が該当。そしてAggregateで、バッチサイズが2であることから、2件ずつ処理するので出力は[.333,1]
https://help.mulesoft.com/s/question/0D52T00004mXSK4SAO/module-13-quiz-question-6-please-kindly-explain-why-option-quotaquot-is-the-correct-answer